Reconfigurable Computing for Digital Signal Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
COMBINATIONAL CIRCUITS Combinational Plds Basic Configuration of Three Plds (Programmable Logic Devices)
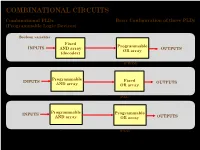
COMBINATIONAL CIRCUITS Combinational PLDs Basic Configuration of three PLDs (Programmable Logic Devices) Boolean variables Fixed Programmable INPUTS AND array OUTPUTS OR array (decoder) Programmable Read-Only Memory (PROM) Programmable INPUTS Fixed OUTPUTS AND array OR array Programmable Array Logic (PAL) Programmable INPUTS Programmable AND array OR array OUTPUTS (Field) Programmable Logic Array (PLA) 1 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Two-level AND-OR Arrays (Programmable Logic Devices) F (C,B, A) = CBA + CB A A AND B + V B C A C B F C F AND F + V 1 B OR C Multiple functions Simplified equivalent circuit for two-level AND-OR array 2 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Field-programmable AND and OR Arrays (Programmable Logic Devices) Field-programmable logic elements are devices that contain uncommitted AND/OR arrays that are (programmed) configured by the designer. + V + V A A F (C,B, A) F (C,B, A) = CBA B B C C Unprogrammed AND array Fuse can be "blown" by passing a high current through it. 3 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Field-programmable AND and OR Arrays (Programmable Logic Devices) F (P1 ,P2 ,P3 ) = P1 + P3 P1 P1 P2 P2 P3 P3 F F (P1 ,P2 ,P3 ) Unprogrammed OR array Programmed OR array P1 P2 P3 P1 + P3 4 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Output Polarity Options (Programmable Logic Devices) I1 Ik Active high Active low Complementary outputs Programmable polarity P P 1 m + V 5 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Bidirectional Pins and Feed back Lines (Programmable Logic Devices) I1 Ik Feedback IOm Three-state driver 6 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs PLA (Programmable Logic Array) (Programmable Logic Devices) If we use ROM to implement the Boolean function we will waste the silicon area. -

Reconfigurable Computing
Reconfigurable Computing: A Survey of Systems and Software KATHERINE COMPTON Northwestern University AND SCOTT HAUCK University of Washington Due to its potential to greatly accelerate a wide variety of applications, reconfigurable computing has become a subject of a great deal of research. Its key feature is the ability to perform computations in hardware to increase performance, while retaining much of the flexibility of a software solution. In this survey, we explore the hardware aspects of reconfigurable computing machines, from single chip architectures to multi-chip systems, including internal structures and external coupling. We also focus on the software that targets these machines, such as compilation tools that map high-level algorithms directly to the reconfigurable substrate. Finally, we consider the issues involved in run-time reconfigurable systems, which reuse the configurable hardware during program execution. Categories and Subject Descriptors: A.1 [Introductory and Survey]; B.6.1 [Logic Design]: Design Style—logic arrays; B.6.3 [Logic Design]: Design Aids; B.7.1 [Integrated Circuits]: Types and Design Styles—gate arrays General Terms: Design, Performance Additional Key Words and Phrases: Automatic design, field-programmable, FPGA, manual design, reconfigurable architectures, reconfigurable computing, reconfigurable systems 1. INTRODUCTION of algorithms. The first is to use hard- wired technology, either an Application There are two primary methods in con- Specific Integrated Circuit (ASIC) or a ventional computing for the execution group of individual components forming a This research was supported in part by Motorola, Inc., DARPA, and NSF. K. Compton was supported by an NSF fellowship. S. Hauck was supported in part by an NSF CAREER award and a Sloan Research Fellowship. -

VLSI Design: a New Approach
International Journal of Information Theory Volume 1, Issue 1, 2011, pp-01-04 Available online at: http://www.bioinfo.in/contents.php?id=103 VLSI Design: A New Approach M.B. Swami and V.P. Pawar Department of Physics/Electronics/Computer Science, Maharashtra Udyagiri Mahavidyalaya, Udgir, India e-mail: [email protected] Abstract—This paper presents the different • Cores such as PCI are available and able to Programmable Logic Array is an important building circuit integrate with relative ease Getting started in of VLSI chips and some of the FPGA architectures have FPGA design is easy. evolved from the basic Programmable Logic Array The tools are cheap (and sometimes free) for low- architectures. In this paper the new concepts of Verilog Hardware Description language is included in VLSI Design. end devices and affordable for the high end. Modern Keywords: Programmable Logic Array, FPGA, Verilog. HDL (hardware design language) environments are very powerful for creating and verifying a design. There I. INTRODUCTION is plenty of documentation available for using different vendor’s FPGA design tools and exploiting features of Very-large-scale integration (VLSI) is the process of different FPGAs. creating integrated circuits by combining thousands of Even with modern tools, the fundamentals of transistor-based circuits into a single chip. digital design still remain intact and must be Implementation is based on FPGA design flow with understood. If the fundamentals are ignored, there is a Xilinx tools which will help you to design complex good chance that your design will not work consistently digital systems using HDL and also to get experience of and will probably exhibit intermittent modes of processor and controller implementations on FPGAs. -

Syllabus: EEL4930/5934 Reconfigurable Computing
EEL4720/5721 Reconfigurable Computing (dual-listed course) Department of Electrical and Computer Engineering University of Florida Spring Semester 2019 Catalog Description: Prereq: EEL4712C or EEL5764 or consent of instructor. Fundamental concepts at advanced undergraduate level (EEL4720) and introductory graduate level (EEL5721) in reconfigurable computing (RC) based upon advanced technologies in field-programmable logic devices. Topics include general RC concepts, device architectures, design tools, metrics and kernels, system architectures, and application case studies. Credit Hours: 3 Prerequisites by Topic: Fundamentals of digital design including device technologies, design methodology and techniques, and design environments and tools; fundamentals of computer organization and architecture, including datapath and control structures, data formats, instruction-set principles, pipelining, instruction-level parallelism, memory hierarchy, and interconnects and interfacing. Instructor: Dr. Herman Lam Office: Benton Hall, Room 313 Office hours: TBA Telephone: (352) 392-2689 Email: [email protected] Teaching Assistant: Seyed Hashemi Office hours: TBA Email: [email protected] Class lectures: MWF 4th period, Larsen Hall 239 Required textbook: none References: . Reconfigurable Computing: The Theory and Practice of FPGA-Based Computation, edited by Scott Hauck and Andre DeHon, Elsevier, Inc. (Morgan Kaufmann Publishers), Amsterdam, 2008. ISBN: 978-0-12-370522-8 . C. Maxfield, The Design Warrior's Guide to FPGAs, Newnes, 2004, ISBN: 978-0750676045. -

Introduction to ASIC Design
’14EC770 : ASIC DESIGN’ An Introduction Application - Specific Integrated Circuit Dr.K.Kalyani AP, ECE, TCE. 1 VLSI COMPANIES IN INDIA • Motorola India – IC design center • Texas Instruments – IC design center in Bangalore • VLSI India – ASIC design and FPGA services • VLSI Software – Design of electronic design automation tools • Microchip Technology – Offers VLSI CMOS semiconductor components for embedded systems • Delsoft – Electronic design automation, digital video technology and VLSI design services • Horizon Semiconductors – ASIC, VLSI and IC design training • Bit Mapper – Design, development & training • Calorex Institute of Technology – Courses in VLSI chip design, DSP and Verilog HDL • ControlNet India – VLSI design, network monitoring products and services • E Infochips – ASIC chip design, embedded systems and software development • EDAIndia – Resource on VLSI design centres and tutorials • Cypress Semiconductor – US semiconductor major Cypress has set up a VLSI development center in Bangalore • VDAT 2000 – Info on VLSI design and test workshops 2 VLSI COMPANIES IN INDIA • Sandeepani – VLSI design training courses • Sanyo LSI Technology – Semiconductor design centre of Sanyo Electronics • Semiconductor Complex – Manufacturer of microelectronics equipment like VLSIs & VLSI based systems & sub systems • Sequence Design – Provider of electronic design automation tools • Trident Techlabs – Power systems analysis software and electrical machine design services • VEDA IIT – Offers courses & training in VLSI design & development • Zensonet Technologies – VLSI IC design firm eg3.com – Useful links for the design engineer • Analog Devices India Product Development Center – Designs DSPs in Bangalore • CG-CoreEl Programmable Solutions – Design services in telecommunications, networking and DSP 3 Physical Design, CAD Tools. • SiCore Systems Pvt. Ltd. 161, Greams Road, ... • Silicon Automation Systems (India) Pvt. Ltd. ( SASI) ... • Tata Elxsi Ltd. -

A MATLAB Compiler for Distributed, Heterogeneous, Reconfigurable
A MATLAB Compiler For Distributed, Heterogeneous, Reconfigurable Computing Systems P. Banerjee, N. Shenoy, A. Choudhary, S. Hauck, C. Bachmann, M. Haldar, P. Joisha, A. Jones, A. Kanhare A. Nayak, S. Periyacheri, M. Walkden, D. Zaretsky Electrical and Computer Engineering Northwestern University 2145 Sheridan Road Evanston, IL-60208 [email protected] Abstract capabilities and are coordinated to perform an application whose subtasks have diverse execution requirements. One Recently, high-level languages such as MATLAB have can visualize such systems to consist of embedded proces- become popular in prototyping algorithms in domains such sors, digital signal processors, specialized chips, and field- as signal and image processing. Many of these applications programmable gate arrays (FPGA) interconnected through whose subtasks have diverse execution requirements, often a high-speed interconnection network; several such systems employ distributed, heterogeneous, reconfigurable systems. have been described in [9]. These systems consist of an interconnected set of heteroge- A key question that needs to be addressed is how to map neous processing resources that provide a variety of archi- a given computation on such a heterogeneous architecture tectural capabilities. The objective of the MATCH (MATlab without expecting the application programmer to get into Compiler for Heterogeneous computing systems) compiler the low level details of the architecture or forcing him/her to project at Northwestern University is to make it easier for understand -

Architecture and Programming Model Support for Reconfigurable Accelerators in Multi-Core Embedded Systems »
THESE DE DOCTORAT DE L’UNIVERSITÉ BRETAGNE SUD COMUE UNIVERSITE BRETAGNE LOIRE ÉCOLE DOCTORALE N° 601 Mathématiques et Sciences et Technologies de l'Information et de la Communication Spécialité : Électronique Par « Satyajit DAS » « Architecture and Programming Model Support For Reconfigurable Accelerators in Multi-Core Embedded Systems » Thèse présentée et soutenue à Lorient, le 4 juin 2018 Unité de recherche : Lab-STICC Thèse N° : 491 Rapporteurs avant soutenance : Composition du Jury : Michael HÜBNER Professeur, Ruhr-Universität François PÊCHEUX Professeur, Sorbonne Université Bochum Président (à préciser après la soutenance) Jari NURMI Professeur, Tampere University of Angeliki KRITIKAKOU Maître de conférences, Université Technology Rennes 1 Davide ROSSI Assistant professor, Université de Bologna Kevin MARTIN Maître de conférences, Université Bretagne Sud Directeur de thèse Philippe COUSSY Professeur, Université Bretagne Sud Co-directeur de thèse Luca BENINI Professeur, Université de Bologna Architecture and Programming Model Support for Reconfigurable Accelerators in Multi-Core Embedded Systems Satyajit Das 2018 iii ABSTRACT Emerging trends in embedded systems and applications need high throughput and low power consumption. Due to the increasing demand for low power computing, and diminishing returns from technology scaling, industry and academia are turning with renewed interest toward energy efficient hardware accelerators. The main drawback of hardware accelerators is that they are not programmable. Therefore, their utilization can be low as they perform one specific function and increasing the number of the accelerators in a system onchip (SoC) causes scalability issues. Programmable accelerators provide flexibility and solve the scalability issues. Coarse-Grained Reconfigurable Array (CGRA) architecture consisting several processing elements with word level granularity is a promising choice for programmable accelerator. -

Hardware Platforms for Embedded Computing Graphics: © Alexandra Nolte, Gesine Marwedel, 2003 Universität Dortmund Importance of Energy Efficiency
Universität Dortmund Hardware Platforms for Embedded Computing Graphics: © Alexandra Nolte, Gesine Marwedel, 2003 Universität Dortmund Importance of Energy Efficiency Efficient software design needed, otherwise, the price for software flexibility cannot be paid. © Hugo De Man (IMEC) Philips, 2007 Universität Dortmund Embedded vs. general-purpose processors • Embedded processors may be optimized for a category of applications. – Customization may be narrow or broad. • We may judge embedded processors using different metrics: – Code size. – Memory system performance. – Preditability. • Disappearing distinction: embedded processors everywhere Universität Dortmund Microcontroller Architectures Memory 0 Address Bus Program + CPU Data Bus Data Von Neumann 2n Architecture Memory 0 Address Bus Program CPU Fetch Bus Harvard Address Bus 0 Architecture Data Bus Data Universität Dortmund RISC processors • RISC generally means highly-pipelinable, one instruction per cycle. • Pipelines of embedded RISC processors have grown over time: – ARM7 has 3-stage pipeline. – ARM9 has 5-stage pipeline. – ARM11 has eight-stage pipeline. ARM11 pipeline [ARM05]. Universität Dortmund ARM Cortex Based on ARMv7 Architecture & Thumb®-2 ISA – ARM Cortex A Series - Applications CPUs focused on the execution of complex OS and user applications • First Product: Cortex-A8 • Executes ARM, Thumb-2 instructions – ARM Cortex R Series - Deeply embedded processors focused on Real-time environments • First Product: Cortex-R4(F) • Executes ARM, Thumb-2 instructions – ARM Cortex M -

Reconfigurable Computing
Reconfigurable Computing David Boland1, Chung-Kuan Cheng2, Andrew B. Kahng2, Philip H.W. Leong1 1School of Electrical and Information Engineering, The University of Sydney, Australia 2006 2Dept. of Computer Science and Engineering, University of California, La Jolla, California Abstract: Reconfigurable computing is the application of adaptable fabrics to solve computational problems, often taking advantage of the flexibility available to produce problem-specific architectures that achieve high performance because of customization. Reconfigurable computing has been successfully applied to fields as diverse as digital signal processing, cryptography, bioinformatics, logic emulation, CAD tool acceleration, scientific computing, and rapid prototyping. Although Estrin-first proposed the idea of a reconfigurable system in the form of a fixed plus variable structure computer in 1960 [1] it has only been in recent years that reconfigurable fabrics, in the form of field-programmable gate arrays (FPGAs), have reached sufficient density to make them a compelling implementation platform for high performance applications and embedded systems. In this article, intended for the non-specialist, we describe some of the basic concepts, tools and architectures associated with reconfigurable computing. Keywords: reconfigurable computing; adaptable fabrics; application integrated circuits; field programmable gate arrays (FPGAs); system architecture; runtime 1 Introduction Although reconfigurable fabrics can in principle be constructed from any type of technology, in practice, most contemporary designs are made using commercial field programmable gate arrays (FPGAs). An FPGA is an integrated circuit containing an array of logic gates in which the connections can be configured by downloading a bitstream to its memory. FPGAs can also be embedded in integrated circuits as intellectual property cores. -

The Basics of Logic Design
C APPENDIX The Basics of Logic Design C.1 Introduction C-3 I always loved that C.2 Gates, Truth Tables, and Logic word, Boolean. Equations C-4 C.3 Combinational Logic C-9 Claude Shannon C.4 Using a Hardware Description IEEE Spectrum, April 1992 Language (Shannon’s master’s thesis showed that C-20 the algebra invented by George Boole in C.5 Constructing a Basic Arithmetic Logic the 1800s could represent the workings of Unit C-26 electrical switches.) C.6 Faster Addition: Carry Lookahead C-38 C.7 Clocks C-48 AAppendixC-9780123747501.inddppendixC-9780123747501.indd 2 226/07/116/07/11 66:28:28 PPMM C.8 Memory Elements: Flip-Flops, Latches, and Registers C-50 C.9 Memory Elements: SRAMs and DRAMs C-58 C.10 Finite-State Machines C-67 C.11 Timing Methodologies C-72 C.12 Field Programmable Devices C-78 C.13 Concluding Remarks C-79 C.14 Exercises C-80 C.1 Introduction This appendix provides a brief discussion of the basics of logic design. It does not replace a course in logic design, nor will it enable you to design signifi cant working logic systems. If you have little or no exposure to logic design, however, this appendix will provide suffi cient background to understand all the material in this book. In addition, if you are looking to understand some of the motivation behind how computers are implemented, this material will serve as a useful intro- duction. If your curiosity is aroused but not sated by this appendix, the references at the end provide several additional sources of information. -

RESEARCH INSIGHTS – Hardware Design: FPGA Security Risks
RESEARCH INSIGHTS Hardware Design: FPGA Security Risks www.nccgroup.trust CONTENTS Author 3 Introduction 4 FPGA History 6 FPGA Development 10 FPGA Security Assessment 12 Conclusion 17 Glossary 18 References & Further Reading 19 NCC Group Research Insights 2 All Rights Reserved. © NCC Group 2015 AUTHOR DUNCAN HURWOOD Duncan is a senior consultant at NCC Group, specialising in telecom, embedded systems and application review. He has over 18 years’ experience within the telecom and security industry performing almost every role within the software development cycle from design and development to integration and product release testing. A dedicated security assessor since 2010, his consultancy experience includes multiple technologies, languages and platforms from web and mobile applications, to consumer devices and high-end telecom hardware. NCC Group Research Insights 3 All Rights Reserved. © NCC Group 2015 GLOSSARY AES Advanced encryption standard, a cryptography OTP One time programmable, allowing write once cipher only ASIC Application-specific integrated circuit, non- PCB Printed circuit board programmable hardware logic chip PLA Programmable logic array, forerunner of FPGA Bitfile Binary instruction file used to program FPGAs technology CLB Configurable logic block, an internal part of an PUF Physically unclonable function FPGA POWF Physical one-way function CPLD Complex programmable logic device PSoC Programmable system on chip, an FPGA and EEPROM Electronically erasable programmable read- other hardware on a single chip only memory -

Full-Custom Ics Standard-Cell-Based
Full-Custom ICs Design a chip from scratch. Engineers design some or all of the logic cells, circuits, and the chip layout specifi- cally for a full-custom IC. Custom mask layers are created in order to fabricate a full-custom IC. Advantages: complete flexibility, high degree of optimization in performance and area. Disadvantages: large amount of design effort, expensive. 1 Standard-Cell-Based ICs Use predesigned, pretested and precharacterized logic cells from standard-cell li- brary as building blocks. The chip layout (defining the location of the building blocks and wiring between them) is customized. As in full-custom design, all mask layers need to be customized to fabricate a new chip. Advantages: save design time and money, reduce risk compared to full-custom design. Disadvantages: still incurs high non-recurring-engineering (NRE) cost and long manufacture time. 2 D A B C A B B D C D A A B B Cell A Cell B Cell C Cell D Feedthrough Cell Standard-cell-based IC design. 3 Gate-Array Parts of the chip are pre-fabricated, and other parts are custom fabricated for a particular customer’s circuit. Idential base cells are pre-fabricated in the form of a 2-D array on a gate-array (this partially finished chip is called gate-array template). The wires between the transistors inside the cells and between the cells are custom fabricated for each customer. Custom masks are made for the wiring only. Advantages: cost saving (fabrication cost of a large number of identical template wafers is amortized over different customers), shorter manufacture lead time.