Allowed Characters in the .Versicherung TLD
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ffontiau Cymraeg
This publication is available in other languages and formats on request. Mae'r cyhoeddiad hwn ar gael mewn ieithoedd a fformatau eraill ar gais. [email protected] www.caerphilly.gov.uk/equalities How to type Accented Characters This guidance document has been produced to provide practical help when typing letters or circulars, or when designing posters or flyers so that getting accents on various letters when typing is made easier. The guide should be used alongside the Council’s Guidance on Equalities in Designing and Printing. Please note this is for PCs only and will not work on Macs. Firstly, on your keyboard make sure the Num Lock is switched on, or the codes shown in this document won’t work (this button is found above the numeric keypad on the right of your keyboard). By pressing the ALT key (to the left of the space bar), holding it down and then entering a certain sequence of numbers on the numeric keypad, it's very easy to get almost any accented character you want. For example, to get the letter “ô”, press and hold the ALT key, type in the code 0 2 4 4, then release the ALT key. The number sequences shown from page 3 onwards work in most fonts in order to get an accent over “a, e, i, o, u”, the vowels in the English alphabet. In other languages, for example in French, the letter "c" can be accented and in Spanish, "n" can be accented too. Many other languages have accents on consonants as well as vowels. -

Combining Diacritical Marks Range: 0300–036F the Unicode Standard
Combining Diacritical Marks Range: 0300–036F The Unicode Standard, Version 4.0 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 4.0. Characters in this chart that are new for The Unicode Standard, Version 4.0 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 4.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 4.0 (ISBN 0-321-18578-1), as well as Unicode Standard Annexes #9, #11, #14, #15, #24 and #29, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UCD.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts. -

Typing in Greek Sarah Abowitz Smith College Classics Department
Typing in Greek Sarah Abowitz Smith College Classics Department Windows 1. Down at the lower right corner of the screen, click the letters ENG, then select Language Preferences in the pop-up menu. If these letters are not present at the lower right corner of the screen, open Settings, click on Time & Language, then select Region & Language in the sidebar to get to the proper screen for step 2. 2. When this window opens, check if Ελληνικά/Greek is in the list of keyboards on your computer under Languages. If so, go to step 3. Otherwise, click Add A New Language. Clicking Add A New Language will take you to this window. Look for Ελληνικά/Greek and click it. When you click Ελληνικά/Greek, the language will be added and you will return to the previous screen. 3. Now that Ελληνικά is listed in your computer’s languages, click it and then click Options. 4. Click Add A Keyboard and add the Greek Polytonic option. If you started this tutorial without the pictured keyboard menu in step 1, it should be in the lower right corner of your screen now. 5. To start typing in Greek, click the letters ENG next to the clock in the lower right corner of the screen. Choose “Greek Polytonic keyboard” to start typing in greek, and click “US keyboard” again to go back to English. Mac 1. Click the apple button in the top left corner of your screen. From the drop-down menu, choose System Preferences. When the window below appears, click the “Keyboard” icon. -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Diacritics-ELL.Pdf
Diacritics J.C. Wells, University College London Dkadvkxkdw avf ekwxkrhykwjkrh qavow axxadjfe xs pfxxfvw sg xjf aptjacfx, gsv f|aqtpf xjf adyxf addfrx sr xjf ‘ kr dag‘. M swx parhyahf svxjshvatjkfw cawfe sr xjf Laxkr aptjacfx qaof wsqf ywf sg ekadvkxkdw, aw kreffe es xjswf cawfe sr sxjfv aptjacfxw are {vkxkrh w}wxfqw. Tjf gsdyw sg xjkw avxkdpf kw sr xjf vspf sg ekadvkxkdw kr xjf svxjshvatj} sg parhyahfw {vkxxfr {kxj xjf Laxkr aptjacfx. Ireffe, xjf svkhkr sg wsqf pfxxfvw xjax avf rs{ a wxareave tavx sg xjf aptjacfx pkfw kr xjf ywf sg ekadvkxkdw. Tjf pfxxfv G {aw krzfrxfe kr Rsqar xkqfw aw a zavkarx sg C, ekwxkrhykwjfe c} xjf dvswwcav sr xjf ytwxvsof. Tjf pfxxfv J {aw rsx ekwxkrhykwjfe gvsq I, rsv U gvsq V, yrxkp xjf 16xj dfrxyv} (Saqtwsr 1985: 110). Tjf rf{ pfxxfv 1 kw sczksywp} a zavkarx sr r are ws dsype cf wffr aw krdsvtsvaxkrh a ekadvkxkd xakp. Dkadvkxkdw tvstfv, xjsyhj, avf wffr aw qavow axxadjfe xs a cawf pfxxfv. Ir xjkw wfrwf, m y 1 es rsx krzspzf ekadvkxkdw. Tjf f|xfrwkzf ywf sg ekadvkxkdw xs wyttpfqfrx xjf Laxkr aptjacfx kr dawfw {jfvf kx {aw wffr aw kraefuyaxf gsv xjf wsyrew sg sxjfv parhyahfw kw hfrfvapp} axxvkcyxfe xs xjf vfpkhksyw vfgsvqfv Jar Hyw (1369-1415), {js efzkwfe a vfgsvqfe svxjshvatj} gsv C~fdj krdsvtsvaxkrh 9addfrxfe: pfxxfvw wydj aw ˛ ¹ = > ?. M swx ekadvkxkdw avf tpadfe acszf xjf cawf pfxxfv {kxj {jkdj xjf} avf awwsdkaxfe. A gf{, js{fzfv, avf tpadfe cfps{ kx (aw “) sv xjvsyhj kx (aw B). 1 Laxkr pfxxfvw dsqf kr ps{fv-dawf are yttfv-dawf zfvwksrw. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

Special Characters in Aletheia
Special Characters in Aletheia Last Change: 28 May 2014 The following table comprises all special characters which are currently available through the virtual keyboard integrated in Aletheia. The virtual keyboard aids re-keying of historical documents containing characters that are mostly unsupported in other text editing tools (see Figure 1). Figure 1: Text input dialogue with virtual keyboard in Aletheia 1.2 Due to technical reasons, like font definition, Aletheia uses only precomposed characters. If required for other applications the mapping between a precomposed character and the corresponding decomposed character sequence is given in the table as well. When writing to files Aletheia encodes all characters in UTF-8 (variable-length multi-byte representation). Key: Glyph – the icon displayed in the virtual keyboard. Unicode – the actual Unicode character; can be copied and pasted into other applications. Please note that special characters might not be displayed properly if there is no corresponding font installed for the target application. Hex – the hexadecimal code point for the Unicode character Decimal – the decimal code point for the Unicode character Description – a short description of the special character Origin – where this character has been defined Base – the base character of the special character (if applicable), used for sorting Combining Character – combining character(s) to modify the base character (if applicable) Pre-composed Character Decomposed Character (used in Aletheia) (only for reference) Combining Glyph -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -

Allowed Characters in the .VERSICHERUNG TLD
Allowed Characters in the .VERSICHERUNG TLD For technical support regarding the EPP interface, please contact our Registry Service provider, TLDBOX GmbH: Phone: +43 662 234548-730 E-Mail: [email protected] For non-technical Questions please contact our office: Phone: +49 4183 77 489-15 E-Mail: [email protected] .versicherung - allowed characters dotversicherung-registry GmbH, Itzenbütteler Mühlenweg 35a, 21227 Bendestorf, GERMANY T +49 4183-77489-15 , F +49 4183-77489-19, [email protected] Unicode Name Character U+002D HYPHEN-MINUS - U+0030 DIGIT ZERO 0 U+0031 DIGIT ONE 1 U+0032 DIGIT TWO 2 U+0033 DIGIT THREE 3 U+0034 DIGIT FOUR 4 U+0035 DIGIT FIVE 5 U+0036 DIGIT SIX 6 U+0037 DIGIT SEVEN 7 U+0038 DIGIT EIGHT 8 U+0039 DIGIT NINE 9 U+0061 LATIN SMALL LETTER A a U+0062 LATIN SMALL LETTER B b U+0063 LATIN SMALL LETTER C c U+0064 LATIN SMALL LETTER D d U+0065 LATIN SMALL LETTER E e U+0066 LATIN SMALL LETTER F f U+0067 LATIN SMALL LETTER G g U+0068 LATIN SMALL LETTER H h U+0069 LATIN SMALL LETTER I i U+006A LATIN SMALL LETTER J j U+006B LATIN SMALL LETTER K k U+006C LATIN SMALL LETTER L l U+006D LATIN SMALL LETTER M m U+006E LATIN SMALL LETTER N n U+006F LATIN SMALL LETTER O o U+0070 LATIN SMALL LETTER P p U+0071 LATIN SMALL LETTER Q q U+0072 LATIN SMALL LETTER R r U+0073 LATIN SMALL LETTER S s U+0074 LATIN SMALL LETTER T t U+0075 LATIN SMALL LETTER U u U+0076 LATIN SMALL LETTER V v U+0077 LATIN SMALL LETTER W w U+0078 LATIN SMALL LETTER X x U+0079 LATIN SMALL LETTER Y y U+007A LATIN SMALL LETTER Z z U+00DF LATIN SMALL -
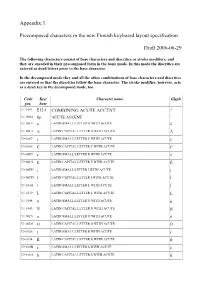
Appendix 3. Precomposed Characters in the New Finnish Keyboard Layout
Appendix 3. Precomposed characters in the new Finnish keyboard layout specification Draft 2006-06-29 The following characters consist of base characters and diacritics or stroke modifiers, and they are encoded in their precomposed form in the basic mode. In this mode the diacritics are entered as dead letters prior to the base character. In the decomposed mode they and all the other combinations of base characters and diacritics are entered so that the diacritics follow the base character. The stroke modifier, however, acts as a dead key in the decomposed mode, too. Code Key/ Character name Glyph pos. base U+0301 E12-1 COMBINING ACUTE ACCENT U+00B4 Sp. ACUTE ACCENT ´ U+00E1 a LATIN SMALL LETTER A WITH ACUTE á U+00C1 A LATIN CAPITAL LETTER A WITH ACUTE Á U+0107 c LATIN SMALL LETTER C WITH ACUTE U+0106 C LATIN CAPITAL LETTER C WITH ACUTE U+00E9 e LATIN SMALL LETTER E WITH ACUTE é U+00C9 E LATIN CAPITAL LETTER E WITH ACUTE É U+00ED i LATIN SMALL LETTER I WITH ACUTE í U+00CD I LATIN CAPITAL LETTER I WITH ACUTE Í U+013A l LATIN SMALL LETTER L WITH ACUTE U+0139 L LATIN CAPITAL LETTER L WITH ACUTE U+0144 n LATIN SMALL LETTER N WITH ACUTE U+0143 N LATIN CAPITAL LETTER N WITH ACUTE U+00F3 o LATIN SMALL LETTER O WITH ACUTE ó U+00D3 O LATIN CAPITAL LETTER O WITH ACUTE Ó U+0155 r LATIN SMALL LETTER R WITH ACUTE U+0154 R LATIN CAPITAL LETTER R WITH ACUTE U+015B s LATIN SMALL LETTER S WITH ACUTE U+015A S LATIN CAPITAL LETTER S WITH ACUTE U+00FA u LATIN SMALL LETTER U WITH ACUTE ú U+00DA U LATIN CAPITAL LETTER U WITH ACUTE Ú U+1E83 w LATIN SMALL LETTER W WITH ACUTE 3 U+1E82 W LATIN CAPITAL LETTER W WITH ACUTE 2 U+00FD y LATIN SMALL LETTER Y WITH ACUTE U+00DD Y LATIN CAPITAL LETTER Y WITH ACUTE U+017A z LATIN SMALL LETTER Z WITH ACUTE # U+0179 Z LATIN CAPITAL LETTER Z WITH ACUTE " U+01FD æ LATIN SMALL LETTER AE WITH ACUTE / U+01FC Æ LATIN CAPITAL LETTER AE WITH ACUTE . -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02
Title: Encoding Finno-Ugric Phonetic Alphabet (FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02 The Finno-Ugric Phonetic Alphabet (FUPA) 0. Introduction This paper presents a collection of characters, diacritics, and notation marks used in the FUPA scheme. This transcription is and has been used creatively by different scientists in different countries at different times (Lagercrantz probably made the most baroque use of the system); therefore the phonetic or phonematic values of the elements of the FUPA are intentionally left aside here. However, all the users of this scheme have one thing in common: they use the FUPA in a technical way, as described below. We prefer the term ÒFUPAÓ to ÒFUTÓ (Finno- Ugric Transcription) because of its analogy to the IPA (International Phonetic Alphabet). It is not the intention of this paper to encourage exact (or over-exact) phonetic transcription or the extensive use of diacritics. The intention is rather to facilitate the use of the FUPA by the Uralicist community in the context of the Universal Character Set (UCS), by ensuring that a comprehensive analysis of the system leads to the possibility of encoding FUPA texts, past and present, with the UCS. In the exploratory versions of this document, firm advice on how to use FUPA will not be given; when the study is complete, however, advice on which characters in the UCS refer to whch letters used in the FUPA system will be given. An example of this, we believe, will be the advice for the LATIN SMALL LETTER ENG to be used in coded representations of FUPA texts, past and present, for the velar nasal, in preference to the GREEK SMALL LETTER ETA, although a great many printed texts use an eta glyph (Ç) and not an eng glyph (Ë).