Quantile Based Histogram Equalization for Noise Robust Speech Recognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Les Grands Investisseurs Internationaux Stimulent L'envolée Des Écoles Privées
LE TEMPS Vendredi 11 avril2014 • Supplément du journalLe Temps-Ne peut être vendu séparément www.letemps.chfcarrieres Les grands investisseurs internationaux stimulent l'envolée des écoles privées >Education directeur de Champittet Même renseignement libre chose pour La Côte International School, qui inaugure son nouveau est une industrie campus à Aubonne en septembre. lucrative Ces fonds servent aussi à augmen ter les capacités d'accueil, comme en plein essor celles du Collège du Léman qui dé nombre aujourd'hui plus de 2000 > Les établissements élèves, contre la moitié il y a quinze ans. Plus gros, ces établissements entrent en bourse sont aussi plus puissants afin de re cruter les meilleurs directeurs et en ï;;;ï;~ii~-;::~~~ët····································· seignants, à en croire Nord Anglia, qui établit aussi des formations Les collèges vaudois de Cham <<maison>> pour les dirigeants et les pittet, La Côte International School enseignants. <<Le partage des bon et Beau-Soleil sont désormais cotés nes pratiques est d'une qualité que en bourse. Ils ont été rachetés en je n'ai jamais vue ailleursn, indique 2010 par Nord Anglia Education, Steffen Sommer. Enfin, ces ressour société introduite au New York ces soutiennent un marketing in Stock Exchange le 26 mars dernier. ternational efficace pour la con Le groupe d'origine britannique quête de nouveaux clients venant (27 écoles dans 11 pays, plus de de partout 17 000 étudiants) est une de ces en tités internationales spécialisées dans l'enseignement qui se déve Un réseau mondial loppent à la vitesse du marché des écoles privées dans le monde: trois d'établissements est ouvertures en cours à Hongkong, perçu comme un atout Dubaï, Chicago pouvant accueillir jusqu'à 1500 élèves. -

Schweizerische Privatschulen Ecoles Privees En Suisse Ecoles Privees En Suisse En Privees Ecoles • Istituti Privati in Svizzera Private Schools in Switzerland
Information und Beratung Information et conseils Informazione e consultazione Information and advice Información y consulta «Gute für die ganze Schweiz Service Scolaire de la FSEP pour toute la Suisse Case postale per tutta la Svizzera CH-3001 Berne for the whole of Switzerland Tél. +41 31 328 40 50 COLEGIOS PRIVADOS EN SUIZA 2018–2019 SUIZA EN PRIVADOS COLEGIOS • para toda la Suiza Fax +41 31 328 40 55 www.swiss-schools.ch [email protected] Noten für für die Region Lausanne/Vaud Association Vaudoise des Ecoles Privées (AVDEP) pour la région Lausanne/Vaud Case postale 1215 per la regione Lausanne/Vaud CH-1001 Lausanne for the region Lausanne/Vaud Tél. +41 21 796 33 00 para la región Lausanne/Vaud Fax +41 21 796 33 11 PRIVATE SCHOOLS IN SWITZERLAND SCHOOLS PRIVATE • www.avdep.ch die PKG*» [email protected] für die Region Genève Association Genevoise des Ecoles Privées (AGEP) pour la région Genève 98, rue de Saint-Jean per la regione Genève Case postale 5278 for the region Genève CH-1211 Genève 11 para la región Genève Tél. +41 58 715 32 30 *Mitglieder des Verbandes Schweizerischer Privat- IN SVIZZERA PRIVATI ISTITUTI • Fax +41 58 715 32 13 schulen (VSP) können sich der PKG Pensionskasse www.agep.ch [email protected] zu Vorzugskonditionen anschliessen. SCHWEIZERISCHE PRIVATSCHULEN ECOLES PRIVEES EN SUISSE ECOLES PRIVEES EN SUISSE ECOLES • ISTITUTI PRIVATI IN SVIZZERA PRIVATE SCHOOLS IN SWITZERLAND PKG Pensionskasse COLEGIOS PRIVADOS EN SUIZA 6000 Luzern 6 Tel 041 418 50 00 [email protected] · pkg.ch Printed in Switzerland/06.2018 9'000 SCHWEIZERISCHE -

Customized Book List Popular Science
ABCD springer.com Springer Customized Book List Popular Science FRANKFURT BOOKFAIR 2007 springer.com/booksellers Popular Science 1 Relax - Interiors for Human Jones, Partners: Architecture architektur.aktuell 331, 10/2007 Wellness El Segundo architektur.aktuell informiert zehnmal jährlich über aktuelle Architekturthemen in ihren interes- In today’s fast-moving world everyone welcomes santesten baulichen Realisierungen. State-of-the- a place to relax, feel good, to recharge their batter- Fields of interest Art Fotografie, Analysen von Europas f´ührenden ies. Wellness and body care are gaining importance, Architecture, general Architekturkritikern in deutscher und englischer and not only among the rich and famous. A huge Sprache sowie Plan- und Datenmaterial dokumen- number of wellness facilities have opened in recent Type of publication tieren die wichtigsten neuen Bauten in Österreich years. Some are outstanding examples of superb inte- Monograph und ganz Europa. Essays über aktuelle theoretische rior design. Relax showcases the hottest 32 designs. und historische Fragen von prominenten Autoren It covers Spas and Thermal Baths, Massage, Hair Due October 2007 vertiefen die Themenschwerpunkte, die Architek- and Beauty Salons, Health Farms and Gyms. Each tur als eine kulturelle Aufgabe begreifen. Zusätzlich project has been selected for its beauty and for the 2007. 400 p. 575 illus., 270 in color. Hardcover informiert architektur.aktuell über neue Produkte innovative concept behind its creation. In addition to und bietet mit einem "journal", Buch- und Ausstel- works by well-known names such as Karim Rashid, 48,00 € lungsrezensionen, New Media- und Internet-Site-Be- Steven Holl and Jun Aoki, Relax includes interiors by ISBN 978-1-56898-700-2 sprechungen sowie einem Veranstaltungskalender promising young designers. -

Language Courses
HR-DHO-SAS 06/2021 LANGUAGE COURSES Language Courses at CERN are open to the members of personnel and their spouses/partners (subject to a fee). Please contact: [email protected] CERN Welcome Club organises language courses for its members: https://club-welcome.web.cern.ch/languages-courses-engl Certain local associations run a number of affordable French courses in the Canton of Geneva: https://francais-integration.ch/en/, https://www.ge.ch/document/bie-apprendre-francais-geneve The CAGI centre runs a conversation exchange program: http://www.cagi.ch/en/newcomers-network/conversation-exchange-program.php Consult also the list of private schools edited by the “Association Genevoise des Ecoles Privées”: http://www.agep.ch/eng/index.php Certain consulates in Geneva also organise language courses. You can find this information under: https://cds.cern.ch/record/1994327/files/LanguageCourses.pdf Holiday Official Organisation Address Telephone Languages Particularities courses Exams SWITZERLAND ACADEMIE DE LANGUES ET DE Rue du Rhône 118, 1204 Genève 022 731 77 56 English, French, other languages All types of lessons Yes COMMERCE http://www.academy-geneva.ch/ upon request ASC LANGUAGES 72, rue de Lausanne, 1202 Genève 022 731 85 20 English, French, German, Spanish, Adults, small groups Yes Preparation Entrance: 50, rue Rothschild Italian, Portuguese, Russian, individuals, intensive, "total only https://www.asc-languages.ch Chinese, Arabic and Japanese impact" children (through schools) CANTERBURY SCHOOL Rue de la Fontenette 13, -

Sekretariat Der Ständigen Konferenz Der Kultusminister Der Länder in Der Bundesrepublik Deutschland
Sekretariat der Ständigen Konferenz der Kultusminister der Länder in der Bundesrepublik Deutschland Prüfungen zur Erlangung der deutschen Hochschulzugangsberechtigung an Deutschen Schulen im Ausland Stand: Juli 2018 I. Deutsches Internationales Abitur Ordnung zur Erlangung der Allgemeinen Hoch- schulreife an Deutschen Schulen im Ausland (Beschluss der Kultusministerkonferenz vom 11.06.2015) Datum des KMK-Beschlusses Ägypten Deutsche Evangelische Oberschule Kairo 31.08.1957 Deutsche Schule der Borromäerinnen 03.07.1996 Alexandria Deutsche Schule der Borromäerinnen 05.12.1995 Kairo Europa-Schule Kairo 15.12.2011 Argentinien Goethe-Schule in Buenos Aires 10.08.1971/11.06.2015 Belgien Deutsche Internationale Schule Brüssel 17.09.2008 Bolivien Deutsche Schule La Paz 08.08.1984/11.06.2015 Brasilien Deutsche Schule Rio de Janeiro 24.02.1984/11.06.2015 Deutscher Zug des Colegio Visconde de 28.03.1978/11.06.2015 Porto Seguro in Sao Paulo Colégio Humboldt Sao Paulo 26.06.1997/11.06.2015 Colégio Visonde de Porto Seguro II in 10.12.2008/11.06.2015 Vallinhos Bulgarien Deutsche Schule Sofia 26./27.09.2012 Chile Deutsche Schule Santiago 20.09.2006 China Deutsche Botschaftsschule Peking 07.10.1998 Deutsche Schule Shanghai – 29.03.2006 Eurocampus Deutsche Schule Shanghai Pudong 09./10.12.2015 Deutsch-Schweizerische Internationale 06.12.2006 Schule Hongkong Costa Rica Deutsche Schule San José 06.11.1984/11.06.2015 ... - 2 - Dänemark St. Petri-Schule Kopenhagen 12.03.2008 Ecuador Deutsche Schule Quito 04.04.1986/11.06.2015 Finnland Deutsche Schule Helsinki -

Offer by Switzerland to Host the Permanent Secretariat of the Minamata Convention on Mercury in Geneva
June 2015 Offer by Switzerland to host the Permanent Secretariat of the Minamata Convention on Mercury in Geneva In response to the to the invitation of the Executive Director of UNEP dated 5 December 2014 to submit a proposal for physically hosting the Secretariat of the Minamata Convention on Mercury Offer by Switzerland to host the Permanent Secretariat of the Minamata Convention on Mercury in Geneva Contents Introduction 3 Summary 5 Categories of information that may form part of a proposal from a government interested in physically hosting the Secretariat of the Minamata Convention on Mercury 7 Introduction Switzerland’s policy on international organisations 7 Legal framework 7 Features of the office site and related financial issues 10 Local facilities and conditions 12 Other relevant information 20 Annex A (relating to question 10 b) 23 1. International organisations within the UN System 23 2. International organisations outside the UN system 24 3. Non governmental Organizations (NGOs) 25 Annex B (relating to question 10 f) 27 Direct Flights from Geneva – including the Zurich hub 27 Annex C (relating to question 10 a) 29 Diplomatic representations in Geneva 29 States accredited to UNOG based outside Geneva: 33 Permanent Delegations of the international organizations (Observer Offices): 33 Other entities (with observer status): 33 Special Missions: 34 Annex D (relating to question10 i) 35 List of public and private hospitals and clinics in Geneva 35 Annex E: Overview of the International Environment House, home to the interim Secretariat of the Minamata Convention 38 2 The Head of the Federal Department of the Environment, Transport, Energy and Communications DETEC Introduction The adoption of the Minamata Convention on Mercury marks an important success in the protection of human health and the global environment. -

Privatschulen Schweiz 2017 Écoles Privées Suisses Private Schools Switzerland
privatschulen schweiz écoles privées suisses private schools switzerland 2017 private schoolsswitzerland écoles privéessuisses privatschulen schweiz 2017 Titelbild: Illustration de couverture: Title picture: Évi Forgó, Froschaugasse 8, 8001 Zürich Évi Forgó, Froschaugasse 8, 8001 Zürich Évi Forgó, Froschaugasse 8, 8001 Zurich Die Adressen der Schulen (Stand August 2016) Les adresses des écoles (état août 2016) nous The addresses of the schools (as at August 2016) wurden uns freundlicherweise von den kantonalen ont été aimablement fournies par les directions de were kindly provided by the cantonal education Bildungsdirektionen zur Verfügung gestellt. l’instruction publique concernées. departments. Bezugsquelle für weitere Exemplare: Pour toute commande supplémentaire, adressez-vous à: Further copies are available from: Verzeichnis «privatschulen schweiz» Registre «écoles privées suisses» "privatschulen schweiz" directory Cornelia Raimondi Thomas Ammann Cornelia Raimondi Baldernstrasse 2, CH-8134 Adliswil Baldernstrasse 2, CH-8134 Adliswil Baldernstrasse 2, CH-8134 Adliswil Telefon 043 928 37 38 Téléphone 043 928 37 39 Telephone +41 (0)43 928 37 38 www.privatschulen-schweiz.ch www.ecolesprivees-suisses.ch www.privateschools-switzerland.ch [email protected] [email protected] [email protected] Die Verzeichnisse werden Ämtern, Ärzten, Berufs- Les registres sont remis gratuitement notamment The directories are provided free of charge to public beratern, Berufsinformationszentren, Konsulaten, administrations, -
Master Reference
Master Enseignement public ou privé : les dessous d'une transition : études de cas sur les stratégies parentales de scolarisation en territoire genevois DE LUCIA BARRANTES, Carole, LENNARD, Anne-Christine Abstract Ce mémoire se focalise sur les phénomènes de zapping scolaire, ou transition de l'enseignement public au privé, ou inversement. Le contexte de la recherche se limite à au territoire genevois et à la scolarité obligatoire. Le contexte historique correspond à une période charnière que nous appellerons « l'après rénovation » qui se caractérise par l'entrée en vigueur des « 13 priorités » de Charles Beer, ministre en charge de l'éducation et président du Département de l'Instruction publique. Le contexte politique et social genevois peut quant à lui être qualifié d'instable ou de volatile. Au travers de ces études de cas, nous tentons de mettre en exergue les critères de jugement qui orientent le choix des parents en direction d'une offre éducative, plutôt que d'une autre, ce que recherchent les parents en matière d'éducation pour leurs enfants, et lorsqu'il y a transition, quelles sont les configurations de critères différents qui conduisent à cette décision. L'analyse proposée se base, d'une part, sur les entretiens semi-directifs de 13 parents, décrivant le parcours scolaire de 36 [...] Reference DE LUCIA BARRANTES, Carole, LENNARD, Anne-Christine. Enseignement public ou privé : les dessous d'une transition : études de cas sur les stratégies parentales de scolarisation en territoire genevois. Master : Univ. Genève, 2009 Available at: http://archive-ouverte.unige.ch/unige:3801 Disclaimer: layout of this document may differ from the published version. -
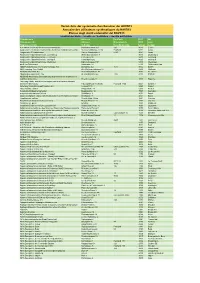
Export USN 06.04.2021
Verzeichnis der systematischen Benutzer der AHVN13 Annuaire des utilisateurs systématiques du NAVS13 Elenco degli utenti sistematici del NAVS13 Identität der Stelle – identité de l'institution – identità dell'istituto Firmenname Adresse Postfach PLZ Ort Raison sociale Adresse Case postale NPA Lieu Ragione sociale Indirizzo Casella postale Luogo Luogo A.H. Meyer & Cie AG Personalvorsorgestiftung Badenerstrasse 329 120 8040 Zürich Aargauische Gebäudeversicherung - Kantonale Unfallversicherung Bleichemattstrasse 12/14 Postfach 5001 Aarau Aargauische Pensionskasse Hintere Bahnhofstr. 8 2127 5001 Aarau Aargauische Sprachheilschule, Laufenbrug Winterthurerstrasse 5 5080 Laufenburg Aargauische Sprachheilschule, Lenzburg Turnerweg 16 5600 Lenzburg Aargauische Sprachheilschule, Oftringen Campingweg 12 4665 Oftringen Aargauische Sprachheilschule, Wettingen Bahnhofstrasse 107 5430 Wettingen aarReha Schinznach Badstrasse 55 5116 Schinznach Bad ABB Pensionskasse c/o Avadis Vorsorge AG Zollstrasse 42 1077 8005 Zürich ABC Learning Tree GmbH Alte Wollerauerstrasse 34 8832 Wollerau Abraxas Informatik AG Rosenbergstrasse 30 9001 St. Gallen ABS Betreuungsservice AG St. Jakobstrasse 66 1105 4133 Pratteln ABSMAD Association Broyarde pour la promotion de la santé et le maintien à domicile Rue du Temple 11 1530 Payerne Abteilung Militär- und Bevölkerungsschutz des Kantons Obwald, Dienstelle Zivilschutz Polizeigebäude Foribach Postfach 1465 6061 Sarnen 1 Abteilung Wehrpflichtersatz Kanton Uri Lehnplatz 22 6460 Altdorf ABZ-SUiSSE GmbH Wiggermatte 16 6260 Reiden -

The WSIS Outcome Document
WSIS Forum 2019 Outcome Document WSIS Forum 2019 Outcome Document Information and Communication Technologies for achieving the Sustainable Development Goals (13 August 2019) Disclaimer Please note the WSIS Forum 2019 Outcome Document is a compilation of the outcomes of the sessions (Thematic Workshops, Country Workshops, Action Line Facilitation Meetings, Interactive Sessions, Information Sessions and Policy Sessions) submitted to the WSIS Secretariat by the organizations responsible for their respective sessions. ITU does not hold any responsibility for the outcomes provided by the organizers of the sessions for the WSIS Forum 2019. © ITU, 2019 International Telecommunication Union (ITU), Geneva Table of Contents WSIS Forum 2019: Introduction......................................................................................................... 1 Open Consultation Process ............................................................................................................... 4 Participation at the WSIS Forum 2019 .............................................................................................. 6 Social Media at the WSIS Forum 2019 .............................................................................................. 8 Opening Segment ............................................................................................................................. 14 Moderated High-Level Policy Sessions ....................................................................................................... 19 Moderated -

Jahrbuch 2015 / 2016
Deutsche Auslandsschularbeit: Bildungspartnerschaften 2015 2016 Bundesverwaltungsamt Der zentrale Dienstleister des Bundes Herausgeber: Bundesverwaltungsamt – Zentralstelle für das Auslandsschulwesen – Besucheradresse: Husarenstraße 32, 53111 Bonn Postadresse: Bundesverwaltungsamt, 50728 Köln Kontakt ZfA: Telefon: 022899 358 - 86 53 Telefax: 022899 358 - 28 55 E-Mail: [email protected] Kontakt BVA: Telefon: 022899 358 - 0 Telefax: 022899 358 - 28 23 E-Mail: [email protected] Internet: www.bundesverwaltungsamt.de www.auslandsschulwesen.de Wir verzichten im Jahrbuch auf eine durchgängige Nennung der weiblichen und männlichen Form, um eine einheitliche Darstellung und eine bessere Lesbarkeit zu gewährleisten. Die Verwendung der männlichen Form umfasst beide Geschlechter. VORWORT VORWORT Vorwort des Leiters der ZfA, Joachim Lauer Vorwort des Leiters der ZfA, Joachim Lauer „Education is the most powerful weapon which you can use „ Initiativen“ und „Denkanstöße“, mit welchem Engagement Ausbildung in den von der ZfA betreuten berufsbildenden Bandbreite deutscher Kultur- und Bildungspolitik im Aus- to change the world.“ Lehrkräfte, Schülerinnen und Schüler sowie Eltern mit der Einrichtungen im Mittelpunkt des Interesses, denn diese land erleben. Wir möchten Sie mit einer bunten Foto collage Situation umgehen. Einrichtungen vermitteln ihren Schülerinnen und Schü- an diesem eindrucksvollen Ereignis teilhaben lassen. Dieses Zitat des ehemaligen südafrikanischen Präsiden- lern nicht nur fachliches Know-how, sondern auch Kennt- ten Nelson Mandela stammt aus dem Jahr 1993. Auch wenn Wertvolle Unterstützung erhalten die Schulen durch die nisse der deutschen Sprache. Auch die Wirtschaft kommt zu Unter dem Motto „Menschen bewegen“ steht auch das Kapitel Mandela das Wort „Waffe“ benutzt, so war sein Schaffen im- Politik. Der Deutsche Bundestag hat erst im November 2015 Wort, indem Vertreter international agierender Unterneh- „Alumni“: Es beinhaltet eine Sammlung an Bildungsbiogra- mer darauf ausgerichtet, Frieden zu stiften. -

Unterrichtung Durch Die Bundesregierung
Deutscher Bundestag Drucksache 11 /1642 11. Wahlperiode 14.01.88 Sachgebiet 223 Unterrichtung durch die Bundesregierung Bericht der Bundesregierung über Stand und Entwicklung der deutschen Schulen im Ausland Inhaltsverzeichnis Seite Einführung 3 I. Entwicklung des Auslandsschulwesens seit dem Rahmenplan 3 1. Deutsche Schulen im Ausland 3 1.1 Schulische Versorgung von deutschen Kindern im Ausland 3 1.2 Begegnungsschulen 4 1.3 Europäische Schulen 4 1.4 Schulen mit verstärktem Deutschunterricht 5 1.5 Sprachgruppenschulen 5 1.6 Sonnabendschulen und Sprachkurse 5 1.7 Maßnahmen für alle deutschen Schulen im Ausland 6 2. Deutsch als Fremdsprache im ausländischen Schulwesen 6 3. Internationale Zusammenarbeit im Schulwesen 7 II. Gegenwärtige Probleme des Auslandsschulwesens 8 1. Deutsche Schulen im Ausland 8 2. Deutsch als Fremdsprache im ausländischen Schulwesen 9 3. Internationale Zusammenarbeit im Schulwesen 10 III. Ziele und Maßnahmen 10 1. Deutsche Schulen im Ausland 10 1.1 Schulneugründungen 10 Zugeleitet mit Schreiben des Bundesministers des Auswärtigen — 011 — 300.10 — vom 11. Januar 1988. Drucksache 11/1642 Deutscher Bundestag — 11. Wahlperiode Seite 1.2 Vertikaler und horizontaler Ausbau bestehender Schulen 10 1.3 Fernlehrwerk 11 1.4 Rechtliche Absicherung 11 1.5 Änderung der Schulstrukturen 11 1.6 Zusätzlicher Einsatz deutscher Lehrer 11 1.7 Verbesserung der Fortbildung 12 1.8 Verbesserung der Schulberatung 12 1.9 Soziale Offenheit 12 1.10 Ausstattung des Schulbaufonds 12 2. Deutsch als Fremdsprache im ausländischen Schulwesen 12 2.1 Rang des Deutschunterrichts in ausländischen Unterrichtsprogram men 12 2.2 Einrichtung von Nachmittags- und Abendunterricht sowie Ferien- kursen 13 2.3 Personelle Maßnahmen 13 2.4 Schulpartnerschaften 13 3.