Energy Modeling and Management for Data Services in Multi-Tier Mobile Cloud Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Yibo Wu Final.Pdf
The Pennsylvania State University The Graduate School RESOURCE-AWARE CROWDSOURCING IN WIRELESS NETWORKS A Dissertation in Computer Science and Engineering by Yibo Wu c 2018 Yibo Wu Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy May 2018 The dissertation of Yibo Wu was reviewed and approved∗ by the following: Guohong Cao Professor of Computer Science and Engineering Dissertation Adviser, Chair of Committee Robert Collins Associate Professor of Computer Science and Engineering Sencun Zhu Associate Professor of Computer Science and Engineering Associate Professor of Information Sciences and Technology Zhenhui Li Associate Professor of Information Sciences and Technology Bhuvan Urgaonkar Associate Professor of Computer Science and Engineering Graduate Program Chair of Computer Science and Engineering ∗Signatures are on file in the Graduate School. Abstract The ubiquity of mobile devices has opened up opportunities for a wide range of applications based on photo/video crowdsourcing, where the server collects a large number of photos/videos from the public to obtain desired information. How- ever, transmitting large numbers of photos/videos in a wireless environment with bandwidth constraints is challenging, and it is hard to run computation-intensive image processing techniques on mobile devices with limited energy and computa- tion power to identify the useful photos/videos and remove redundancy. To address these challenges, we propose a framework to quantify the quality of crowdsourced photos/videos based on the accessible geographical and geometrical information (called metadata) including the orientation, position, and all other related param- eters of the built-in camera. From metadata, we can infer where and how the photo/video is taken, and then only transmit the most useful photos/videos. -

Reflex: Remote Flash at the Performance of Local Flash
ReFlex: Remote Flash at the Performance of Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis Flash Memory Summit 2017 Santa Clara, CA Stanford MAST1 ! Flash in Datacenters § NVMe Flash • 1,000x higher throughput than disk (1MIOPS) • 100x lower latency than disk (50-70usec) § But Flash is often underutilized due to imbalanced resource requirements Example Datacenter Flash Use-Case Applica(on Tier Datastore Tier Datastore Service get(k) Key-Value Store So9ware put(k,val) App App Tier Tier App Clients Servers TCP/IP NIC CPU RAM Hardware Flash 3 Imbalanced Resource Utilization Sample utilization of Facebook servers hosting a Flash-based key-value store over 6 months 4 [EuroSys’16] Flash storage disaggregation. Ana Klimovic, Christos Kozyrakis, Eno Thereska, Binu John, Sanjeev Kumar. Imbalanced Resource Utilization Sample utilization of Facebook servers hosting a Flash-based key-value store over 6 months 5 [EuroSys’16] Flash storage disaggregation. Ana Klimovic, Christos Kozyrakis, Eno Thereska, Binu John, Sanjeev Kumar. Imbalanced Resource Utilization u"lizaon Sample utilization of Facebook servers hosting a Flash-based key-value store over 6 months 6 [EuroSys’16] Flash storage disaggregation. Ana Klimovic, Christos Kozyrakis, Eno Thereska, Binu John, Sanjeev Kumar. Imbalanced Resource Utilization u"lizaon Flash capacity and bandwidth are underutilized for long periods of time 7 [EuroSys’16] Flash storage disaggregation. Ana Klimovic, Christos Kozyrakis, Eno Thereska, Binu John, Sanjeev Kumar Solution: Remote Access to Storage § Improve resource utilization by sharing NVMe Flash between remote tenants § There are 3 main concerns: 1. Performance overhead for remote access 2. Interference on shared Flash 3. Flexibility of Flash usage 8 Issue 1: Performance Overhead 4kB random read 1000 Local Flash iSCSI (1 core) 800 libaio+libevent (1core) 600 4x throughput drop 400 200 p95 read latency(us) 2× latency increase 0 0 50 100 150 200 250 300 IOPS (Thousands) • Traditional network/storage protocols and Linux I/O libraries (e.g. -

Multi-Resolution Storage and Search in Sensor Networks Deepak Ganesan University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Computer Science Department Faculty Publication Computer Science Series 2003 Multi-resolution Storage and Search in Sensor Networks Deepak Ganesan University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/cs_faculty_pubs Part of the Computer Sciences Commons Recommended Citation Ganesan, Deepak, "Multi-resolution Storage and Search in Sensor Networks" (2003). Computer Science Department Faculty Publication Series. 79. Retrieved from https://scholarworks.umass.edu/cs_faculty_pubs/79 This Article is brought to you for free and open access by the Computer Science at ScholarWorks@UMass Amherst. It has been accepted for inclusion in Computer Science Department Faculty Publication Series by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. Multi-resolution Storage and Search in Sensor Networks Deepak Ganesan Department of Computer Science, University of Massachusetts, Amherst, MA 01003 Ben Greenstein, Deborah Estrin Department of Computer Science, University of California, Los Angeles, CA 90095, John Heidemann University of Southern California/Information Sciences Institute, Marina Del Rey, CA 90292 and Ramesh Govindan Department of Computer Science, University of Southern California, Los Angeles, CA 90089 Wireless sensor networks enable dense sensing of the environment, offering unprecedented op- portunities for observing the physical world. This paper addresses two key challenges in wireless sensor networks: in-network storage and distributed search. The need for these techniques arises from the inability to provide persistent, centralized storage and querying in many sensor networks. Centralized storage requires multi-hop transmission of sensor data to internet gateways which can quickly drain battery-operated nodes. -

Network-Compute Co-Design for Distributed In-Memory Computing” Advisors: Prof
Network–Compute Co-Design for Distributed In-Memory Computing Alexandros Daglis Ph.D. Thesis July 6, 2018 Thesis Committee Prof. Babak Falsafi, Prof. Edouard Bugnion, thesis directors Prof. Paolo Ienne, jury president Dr. Paolo Faraboschi, external examiner Prof. James Larus, internal examiner Prof. Gurindar Sohi, external examiner Communication and Information Sciences École Polytechnique Fédérale de Lausanne Lausanne, Switzerland T¨c paideÐac êfh tὰς μὲn ûÐzac εἶnai πικράς, tὸn δὲ καρπὸn γλυκύν. — Aristotèlhc The roots of education are bitter, but the fruit is sweet. — Aristotle To my family Acknowledgements My PhD journey has undoubtedly been the most challenging and, at the same time, most rewarding so far in my life. A journey that transformed me into a better person and taught me the true value of perseverance, team work, empathy, and patience. I would not have been able to reach the finish line if it weren’t for the wonderful people around me; people who were always there to magnify the joy of the best moments; people who would always support and help me push through the hardest times. To all of these people, I owe my deepest gratitude. It is therefore apposite to start this thesis by thanking them. First and foremost, I am grateful to my advisors, Babak and Ed. Babak has been a constant source of stimulation to keep pushing myself out of my comfort zone, a practice instrumental to my success. He taught me the importance of asking the right questions and taking a step back to look at the big picture. Babak’s attention to detail and quest for perfection confirms that the "the path of virtues goes through toils". -

Terraillon Wellness Coach Supported Devices
Terraillon Wellness Coach Supported Devices Warning This document lists the smartphones compatible with the download of the Wellness Coach app from the App Store (Apple) and Play Store (Android). Some models have been tested by Terraillon to check the compatibility and smooth operation of the Wellness Coach app. However, many models have not been tested. Therefore, Terraillon doesn't ensure the proper functioning of the Wellness Coach application on these models. If your smartphone model does not appear in the list, thank you to send an email to [email protected] giving us the model of your smartphone so that we can activate if the application store allows it. BRAND MODEL NAME MANUFACTURER MODEL NAME OS REQUIRED ACER Liquid Z530 acer_T02 Android 4.3+ ACER Liquid Jade S acer_S56 Android 4.3+ ACER Liquid E700 acer_e39 Android 4.3+ ACER Liquid Z630 acer_t03 Android 4.3+ ACER Liquid Z320 T012 Android 4.3+ ARCHOS 45 Helium 4G a45he Android 4.3+ ARCHOS 50 Helium 4G a50he Android 4.3+ ARCHOS Archos 45b Helium ac45bhe Android 4.3+ ARCHOS ARCHOS 50c Helium ac50che Android 4.3+ APPLE iPhone 4S iOS8+ APPLE iPhone 5 iOS8+ APPLE iPhone 5C iOS8+ APPLE iPhone 5S iOS8+ APPLE iPhone 6 iOS8+ APPLE iPhone 6 Plus iOS8+ APPLE iPhone 6S iOS8+ APPLE iPhone 6S Plus iOS8+ APPLE iPad Mini 1 iOS8+ APPLE iPad Mini 2 iOS8+ 1 / 48 www.terraillon.com Terraillon Wellness Coach Supported Devices BRAND MODEL NAME MANUFACTURER MODEL NAME OS REQUIRED APPLE iPad Mini 3 iOS8+ APPLE iPad Mini 4 iOS8+ APPLE iPad 3 iOS8+ APPLE iPad 4 iOS8+ APPLE iPad Air iOS8+ -

Succinct: Enabling Queries on Compressed Data
Succinct: Enabling Queries on Compressed Data Rachit Agarwal, Anurag Khandelwal, and Ion Stoica, University of California, Berkeley https://www.usenix.org/conference/nsdi15/technical-sessions/presentation/agarwal This paper is included in the Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15). May 4–6, 2015 • Oakland, CA, USA ISBN 978-1-931971-218 Open Access to the Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) is sponsored by USENIX Succinct: Enabling Queries on Compressed Data Rachit Agarwal Anurag Khandelwal Ion Stoica UC Berkeley UC Berkeley UC Berkeley Abstract that indexes can be as much as 8× larger than the in- Succinct is a data store that enables efficient queries di- put data size. Traditional compression techniques can rectly on a compressed representation of the input data. reduce the memory footprint but suffer from degraded Succinct uses a compression technique that allows ran- throughput since data needs to be decompressed even dom access into the input, thus enabling efficient stor- for simple queries. Thus, existing data stores either re- age and retrieval of data. In addition, Succinct natively sort to using complex memory management techniques supports a wide range of queries including count and for identifying and caching “hot” data [5, 6, 26, 35] or search of arbitrary strings, range and wildcard queries. simply executing queries off-disk or off-SSD [25].In What differentiates Succinct from previous techniques either case, latency and throughput advantages of in- is that Succinct supports these queries without storing dexes drop compared to in-memory query execution. -
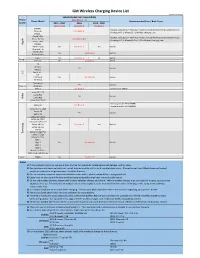
GM Wireless Charging Device List
GM Wireless Charging Device List Revision: Aug 30, 2019 Vehicle Model Year Compatibility Phone ( See Notes 1 - 7) Phone Model Recommended Case / Back Cover Brand 2015 - 2017 2018 2019 - 2020 (See Note 8) (See Note 8) (See Note 9) iPhone 6 ŸBEZALEL Latitude [Qi + PMA] Dual-Mode Universal Wireless Charging Receiver Case iPhone 6s See Note: A ŸAircharge MFi Qi iPhone 6S / 6 Wireless Charging Case iPhone 7 iPhone 6 Plus ŸBEZALEL Latitude [Qi + PMA] Dual-Mode Universal Wireless Charging Receiver Case e iPhone 6s Plus See Note: A & B l ŸAircharge MFi Qi iPhone 6S Plus / 6 Plus Wireless Charging Case p iPhone 7 Plus p A iPhone 8 iPhone X (10) No See Note: C Yes Built-in iPhone Xs / Xr iPhone 8 Plus No See Note: B Built-in iPhone Xs Max Pixel 3 No See Note: C Yes Built-in Google Pixel 3XL No See Note: B Built-in G6 Nexus 4 Yes Built-in Nexus 5 G Spectrum 2 L V30 V40 ThinQ No See Note: B Built-in G7 ThinQ Droid Maxx Yes Built-in Motorola Droid Mini Moto X See Note: A Incipio model: MT231 Lumia 830 / 930 a i Lumia 920 k Yes Built-in o Lumia 928 N Lumia 950 / 950 XL ŸSamsung model: EP-VG900BBU Galaxy S5 See Note: A ŸSamsung model: EP-CG900IBA Galaxy S6 / S6 Edge Galaxy S8 Yes Built-in Galaxy S9 Galaxy S10 / S10e Galaxy S6 Active Galaxy S7 / S7 Active g Galaxy S8 Plus No See Note: C Yes Built-in n u Galaxy S9 Plus s m S10 5G a Galaxy S6 Edge Plus S Galaxy S7 Edge Galaxy S10 Plus Note 5 Note 7 No See Note: B Built-in Note 8 Note 9 Note 10 / 10 Plus Note 10 5G / 10 Plus 5G Xiami MIX2S No See Note: B Built-in Notes: 1) If phone does not charge: remove it from charger for 3 seconds, rotate phone 180 degrees, and try again. -

Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory
Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory Shivaram Venkataraman†∗, Niraj Tolia‡, Parthasarathy Ranganathan†, and Roy H. Campbell∗ †HP Labs, Palo Alto, ‡Maginatics, and ∗University of Illinois, Urbana-Champaign Abstract ther disk or flash. Not only are they byte-addressable and low-latency like DRAM but, they are also non-volatile. The predicted shift to non-volatile, byte-addressable Projected cost [19] and power-efficiency characteris- memory (e.g., Phase Change Memory and Memristor), tics of Non-Volatile Byte-addressable Memory (NVBM) the growth of “big data”, and the subsequent emergence lead us to believe that it can replace both disk and mem- of frameworks such as memcached and NoSQL systems ory in data stores (e.g., memcached, database systems, require us to rethink the design of data stores. To de- NoSQL systems, etc.) but not through legacy inter- rive the maximum performance from these new mem- faces (e.g., block interfaces or file systems). First, the ory technologies, this paper proposes the use of single- overhead of PCI accesses or system calls will dominate level data stores. For these systems, where no distinc- NVBM’s sub-microsecond access latencies. More im- tion is made between a volatile and a persistent copy of portantly, these interfaces impose a two-level logical sep- data, we present Consistent and Durable Data Structures aration of data, differentiating between in-memory and (CDDSs) that, on current hardware, allows programmers on-disk copies. Traditional data stores have to both up- to safely exploit the low-latency and non-volatile as- date the in-memory data and, for durability, sync the data pects of new memory technologies. -

(ASE 18 US 8,370.224 B2 Page 2
USOO8370224B2 (12) United States Patent (10) Patent No.: US 8,370.224 B2 Grewal (45) Date of Patent: Feb. 5, 2013 (54) GRAPHICAL INTERFACE FOR DISPLAY OF 6,574,779 B2 6/2003 Allen et al. ASSETS IN AN ASSET MANAGEMENT 6,581,045 B1 6/2003 Watson 6,631,552 B2 10/2003 Yamaguchi SYSTEM 6,650,346 B1 1 1/2003 Jaeger et al. 6,691,115 B2 2/2004 Mosher, Jr. et al. (75) Inventor: Ardaman Singh Grewal, Milwaukee, 6,735,752 B2 5, 2004 Manoo WI (US) 6,738,958 B2 5, 2004 Manoo 6,763,377 B1 7/2004 Belknap et al. 6,775,576 B2 8/2004 Spriggs et al. (73) Assignee: Rockwell Automation Technologies, 6,782,399 B2 8/2004 Mosher, Jr. Inc., Mayfield Heights, OH (US) 6,789,214 B1 9/2004 De Bonis-Hamelin et al. 6,806,813 B1 10/2004 Cheng et al. (*) Notice: Subject to any disclaimer, the term of this 6,847,982 B2 1/2005 Parker et al. patent is extended or adjusted under 35 6,889,096 B2 * 5/2005 Spriggs et al. .................. 7OO/17 U.S.C. 154(b) by 247 days. (Continued) (21) Appl. No.: 11/535,549 FOREIGN PATENT DOCUMENTS GB 2414568 A 11, 2005 (22) Filed: Sep. 27, 2006 WO 2006/081024 A2 8, 2006 (65) Prior Publication Data OTHER PUBLICATIONS US 2008/OO77512 A1 Mar. 27, 2008 “Gibson Petroleum Selects Couay to Add Location Intelligence to Fleet Management System.” Canada NewsWire Nov. 29, 2001 (51) Int. Cl. ProQuest Newsstand, ProQuest. -

Bluecache: a Scalable Distributed Flash-Based Key-Value Store
BlueCache: A Scalable Distributed Flash-based Key-value Store Shuotao Xuz Sungjin Leey Sang-Woo Junz Ming Liuz Jamey Hicks[ Arvindz zMassachusetts Institute of Technology yInha University [Accelerated Tech, Inc fshuotao, wjun, ml, [email protected] [email protected] [email protected] ABSTRACT KVS caches are used extensively in web infrastructures because of A key-value store (KVS), such as memcached and Redis, is widely their simplicity and effectiveness. used as a caching layer to augment the slower persistent backend Applications that use KVS caches in data centers are the ones storage in data centers. DRAM-based KVS provides fast key-value that have guaranteed high hit-rates. Nevertheless, different appli- access, but its scalability is limited by the cost, power and space cations have very different characteristics in terms of the size of needed by the machine cluster to support a large amount of DRAM. queries, the size of replies and the request rate. KVS servers are This paper offers a 10X to 100X cheaper solution based on flash further subdivided into application pools, each representing a sepa- storage and hardware accelerators. In BlueCache key-value pairs rate application domain, to deal with these differences. Each appli- are stored in flash storage and all KVS operations, including the cation pool has its own prefix of the keys and typically it does not flash controller are directly implemented in hardware. Further- share its key-value pairs with other applications. Application mixes more, BlueCache includes a fast interconnect between flash con- also change constantly, therefore it is important for applications to trollers to provide a scalable solution. -

Nexus-4 User Manual
NeXus-4 User Manual Version 2.0 0344 Table of contents 1 Service and support 3 1.1 About this manual 3 1.2 Warranty information 3 2 Safety information 4 2.1 Explanation of markings 4 2.2 Limitations of use 5 2.3 Safety measures and warnings 5 2.4 Precautionary measures 7 2.5 Disclosure of residual risk 7 2.6 Information for lay operators 7 3 Product overview 8 3.1 Product components 8 3.2 Intended use 8 3.3 NeXus-4 views 9 3.4 User interface 9 3.5 Patient connections 10 3.6 Device label 10 4 Instructions for use 11 4.1 Software 11 4.2 Powering the NeXus-4 12 4.3 Transfer data to PC 12 4.4 Perform measurement 13 4.5 Mobility 13 5 Operational principles 14 5.1 Bipolar input channels 14 5.2 Auxiliary input channel 14 5.3 Filtering 14 6 Maintenance 15 7 Electromagnetic guidance 16 8 Technical specifications 19 2 1 Service and support 1.1 About this manual This manual is intended for the user of the NeXus-4 system – referred to as ‘product’ throughout this manual. It contains general operating instructions, precautionary measures, maintenance instructions and information for use of the product. Read this manual carefully and familiarize yourself with the various controls and accessories before starting to use the product. This product is exclusively manufactured by Twente Medical Systems International B.V. for Mind Media B.V. Distribution and service is exclusively performed by or through Mind Media B.V. -

Vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus
vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus 7 HTC HTC One (M7) HTC One (M9) HTC Butterfly S HTC One (M8) HTC One (M10) LG LG Flex LG V20 LG G4 H815 LG G3 LG E988 Gpro LG G5 H860 LG V10 H962 LG G3 Titan Motorola Motorola RAZR M Motorola DROID Turbo Motorola Moto G (2st Gen) Motorola Droid MAXX Motorola Moto G (1st Gen) Motorola Moto X (1st Gen) Samsung Samsung Galaxy S6 edge + Samsung Galaxy Note 2 Samsung Galaxy S4 Active (SM-G9287) Samsung Galaxy S7 edge (SM- Samsung Galaxy Note 3 Samsung Galaxy S4 Mini G935FD) Samsung Galaxy Note 4 Samsung Galaxy S5 Samsung GALAXY J Samsung Galaxy Note 5 (SM- N9208) Samsung Galaxy S5 Active Samsung Galaxy A5 Duos Samsung Galaxy A9 (SM- Samsung Galaxy S3 Samsung Galaxy S5 Mini A9000) Samsung Galaxy S4 Samsung Galaxy S6 Sony Sony Ericsson Xperia Z Sony Xperia Z2 Sony Xperia X Sony Ericsson Xperia Z Ultra Sony Xperia Z3 Sony XPERIA Z5 Sony Ericsson Xperia Z1 Sony Xperia Z3 Compact Asus ASUS Zenfone 2 ASUS Zenfone 5 ASUS Zenfone 6 Huawei HUAWEI P8 HUAWEI CRR_L09 HUAWEI P9 Oppo OPPO X9076 OPPO X9009 Xiaomi XIAOMI 2S XIAOMI 3 XIAOMI 5 XIAOMI Note One Plus OnePlus 3 (A3000) vívosmart® 3 Google Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Pixel HTC HTC One (M9) HTC One (M10) HTC U11 HTC One (A9) HTC U Ultra LG LG V10 H962 LG G4 H815 LG G6 H870 LG V20 LG G5 H860 Motorola Motorola Moto Z Samsung Samsung Galaxy Note 3 Samsung Galaxy S6 Samsung Galaxy J5 Samsung Galaxy S6 edge + Samsung Galaxy Note 4 (SM-G9287) Samsung Galaxy