Open Yibo Wu Final.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Terraillon Wellness Coach Supported Devices
Terraillon Wellness Coach Supported Devices Warning This document lists the smartphones compatible with the download of the Wellness Coach app from the App Store (Apple) and Play Store (Android). Some models have been tested by Terraillon to check the compatibility and smooth operation of the Wellness Coach app. However, many models have not been tested. Therefore, Terraillon doesn't ensure the proper functioning of the Wellness Coach application on these models. If your smartphone model does not appear in the list, thank you to send an email to [email protected] giving us the model of your smartphone so that we can activate if the application store allows it. BRAND MODEL NAME MANUFACTURER MODEL NAME OS REQUIRED ACER Liquid Z530 acer_T02 Android 4.3+ ACER Liquid Jade S acer_S56 Android 4.3+ ACER Liquid E700 acer_e39 Android 4.3+ ACER Liquid Z630 acer_t03 Android 4.3+ ACER Liquid Z320 T012 Android 4.3+ ARCHOS 45 Helium 4G a45he Android 4.3+ ARCHOS 50 Helium 4G a50he Android 4.3+ ARCHOS Archos 45b Helium ac45bhe Android 4.3+ ARCHOS ARCHOS 50c Helium ac50che Android 4.3+ APPLE iPhone 4S iOS8+ APPLE iPhone 5 iOS8+ APPLE iPhone 5C iOS8+ APPLE iPhone 5S iOS8+ APPLE iPhone 6 iOS8+ APPLE iPhone 6 Plus iOS8+ APPLE iPhone 6S iOS8+ APPLE iPhone 6S Plus iOS8+ APPLE iPad Mini 1 iOS8+ APPLE iPad Mini 2 iOS8+ 1 / 48 www.terraillon.com Terraillon Wellness Coach Supported Devices BRAND MODEL NAME MANUFACTURER MODEL NAME OS REQUIRED APPLE iPad Mini 3 iOS8+ APPLE iPad Mini 4 iOS8+ APPLE iPad 3 iOS8+ APPLE iPad 4 iOS8+ APPLE iPad Air iOS8+ -
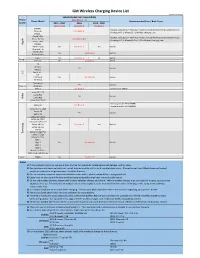
GM Wireless Charging Device List
GM Wireless Charging Device List Revision: Aug 30, 2019 Vehicle Model Year Compatibility Phone ( See Notes 1 - 7) Phone Model Recommended Case / Back Cover Brand 2015 - 2017 2018 2019 - 2020 (See Note 8) (See Note 8) (See Note 9) iPhone 6 ŸBEZALEL Latitude [Qi + PMA] Dual-Mode Universal Wireless Charging Receiver Case iPhone 6s See Note: A ŸAircharge MFi Qi iPhone 6S / 6 Wireless Charging Case iPhone 7 iPhone 6 Plus ŸBEZALEL Latitude [Qi + PMA] Dual-Mode Universal Wireless Charging Receiver Case e iPhone 6s Plus See Note: A & B l ŸAircharge MFi Qi iPhone 6S Plus / 6 Plus Wireless Charging Case p iPhone 7 Plus p A iPhone 8 iPhone X (10) No See Note: C Yes Built-in iPhone Xs / Xr iPhone 8 Plus No See Note: B Built-in iPhone Xs Max Pixel 3 No See Note: C Yes Built-in Google Pixel 3XL No See Note: B Built-in G6 Nexus 4 Yes Built-in Nexus 5 G Spectrum 2 L V30 V40 ThinQ No See Note: B Built-in G7 ThinQ Droid Maxx Yes Built-in Motorola Droid Mini Moto X See Note: A Incipio model: MT231 Lumia 830 / 930 a i Lumia 920 k Yes Built-in o Lumia 928 N Lumia 950 / 950 XL ŸSamsung model: EP-VG900BBU Galaxy S5 See Note: A ŸSamsung model: EP-CG900IBA Galaxy S6 / S6 Edge Galaxy S8 Yes Built-in Galaxy S9 Galaxy S10 / S10e Galaxy S6 Active Galaxy S7 / S7 Active g Galaxy S8 Plus No See Note: C Yes Built-in n u Galaxy S9 Plus s m S10 5G a Galaxy S6 Edge Plus S Galaxy S7 Edge Galaxy S10 Plus Note 5 Note 7 No See Note: B Built-in Note 8 Note 9 Note 10 / 10 Plus Note 10 5G / 10 Plus 5G Xiami MIX2S No See Note: B Built-in Notes: 1) If phone does not charge: remove it from charger for 3 seconds, rotate phone 180 degrees, and try again. -

Nexus-4 User Manual
NeXus-4 User Manual Version 2.0 0344 Table of contents 1 Service and support 3 1.1 About this manual 3 1.2 Warranty information 3 2 Safety information 4 2.1 Explanation of markings 4 2.2 Limitations of use 5 2.3 Safety measures and warnings 5 2.4 Precautionary measures 7 2.5 Disclosure of residual risk 7 2.6 Information for lay operators 7 3 Product overview 8 3.1 Product components 8 3.2 Intended use 8 3.3 NeXus-4 views 9 3.4 User interface 9 3.5 Patient connections 10 3.6 Device label 10 4 Instructions for use 11 4.1 Software 11 4.2 Powering the NeXus-4 12 4.3 Transfer data to PC 12 4.4 Perform measurement 13 4.5 Mobility 13 5 Operational principles 14 5.1 Bipolar input channels 14 5.2 Auxiliary input channel 14 5.3 Filtering 14 6 Maintenance 15 7 Electromagnetic guidance 16 8 Technical specifications 19 2 1 Service and support 1.1 About this manual This manual is intended for the user of the NeXus-4 system – referred to as ‘product’ throughout this manual. It contains general operating instructions, precautionary measures, maintenance instructions and information for use of the product. Read this manual carefully and familiarize yourself with the various controls and accessories before starting to use the product. This product is exclusively manufactured by Twente Medical Systems International B.V. for Mind Media B.V. Distribution and service is exclusively performed by or through Mind Media B.V. -

Vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus
vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus 7 HTC HTC One (M7) HTC One (M9) HTC Butterfly S HTC One (M8) HTC One (M10) LG LG Flex LG V20 LG G4 H815 LG G3 LG E988 Gpro LG G5 H860 LG V10 H962 LG G3 Titan Motorola Motorola RAZR M Motorola DROID Turbo Motorola Moto G (2st Gen) Motorola Droid MAXX Motorola Moto G (1st Gen) Motorola Moto X (1st Gen) Samsung Samsung Galaxy S6 edge + Samsung Galaxy Note 2 Samsung Galaxy S4 Active (SM-G9287) Samsung Galaxy S7 edge (SM- Samsung Galaxy Note 3 Samsung Galaxy S4 Mini G935FD) Samsung Galaxy Note 4 Samsung Galaxy S5 Samsung GALAXY J Samsung Galaxy Note 5 (SM- N9208) Samsung Galaxy S5 Active Samsung Galaxy A5 Duos Samsung Galaxy A9 (SM- Samsung Galaxy S3 Samsung Galaxy S5 Mini A9000) Samsung Galaxy S4 Samsung Galaxy S6 Sony Sony Ericsson Xperia Z Sony Xperia Z2 Sony Xperia X Sony Ericsson Xperia Z Ultra Sony Xperia Z3 Sony XPERIA Z5 Sony Ericsson Xperia Z1 Sony Xperia Z3 Compact Asus ASUS Zenfone 2 ASUS Zenfone 5 ASUS Zenfone 6 Huawei HUAWEI P8 HUAWEI CRR_L09 HUAWEI P9 Oppo OPPO X9076 OPPO X9009 Xiaomi XIAOMI 2S XIAOMI 3 XIAOMI 5 XIAOMI Note One Plus OnePlus 3 (A3000) vívosmart® 3 Google Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Pixel HTC HTC One (M9) HTC One (M10) HTC U11 HTC One (A9) HTC U Ultra LG LG V10 H962 LG G4 H815 LG G6 H870 LG V20 LG G5 H860 Motorola Motorola Moto Z Samsung Samsung Galaxy Note 3 Samsung Galaxy S6 Samsung Galaxy J5 Samsung Galaxy S6 edge + Samsung Galaxy Note 4 (SM-G9287) Samsung Galaxy -

Handset Industry 2013 Outlook
07 January 2013 Americas/United States Equity Research Telecommunications Equipment / MARKET WEIGHT Handset Industry 2013 Outlook Research Analysts INDUSTRY PRIMER Kulbinder Garcha 212 325 4795 [email protected] Bigger market, Apple and Samsung win Achal Sultania 44 20 7883 6884 ■ Market size underestimated for both smartphones/handsets. Our bottom-up [email protected] analysis suggests that the market underestimates the size of low-end ‘white- Talal Khan, CFA label’ smartphones, which causes us to restate our 2012/2013 volume estimates 212 325 8603 for the smartphone market higher by 6%/15% and 3%/4% for overall handsets. [email protected] We also raise our smartphone volume estimates by 20-25% long term and now Matthew Cabral estimate 1.43bn/1.74bn smartphones to be shipped in 2015/2017. We believe 212 538 6260 that the growth of ‘white-label’ smartphone market specifically poses a threat for [email protected] vendors like Nokia, RIMM, LG and possibly Samsung, given their exposure to feature phones and low-end smartphone segments. Ray Bao 212 325 1227 ■ Raising LT smartphone units to 1.74bn – a barbell develops for price points. [email protected] We believe that the addressable market for smartphones is 4.95bn longer term, Asian Research Analysts resulting in effective penetration of only 24% currently given our estimate of 1.2bn smartphone users by end of 2012. We expect effective smartphone Randy Abrams, CFA 886 2 2715 6366 penetration to rise to ~80% long term driving smartphone volumes of [email protected] 1.43bn/1.74bn units by 2015/2017 (26%/19% CAGR over this period). -

Evaluating Bluetooth Low Energy for Iot
Evaluating Bluetooth Low Energy for IoT Jonathan Furst¨ ∗, Kaifei Cheny, Hyung-Sin Kimy and Philippe Bonnet∗ ∗IT University of Copenhagen, yUC Berkeley [email protected], fkaifei, [email protected], [email protected] Abstract—Bluetooth Low Energy (BLE) is the short-range, While others have experienced similar phenomena [7], we single-hop protocol of choice for the edge of the IoT. Despite could not find systematic studies of BLE characteristics on its growing significance for phone-to-peripheral communication, smartphones in the literature. Most existing work focus on the BLE’s smartphone system performance characteristics are not well understood. As others, we experienced mixed erratic perfor- BLE performance of BLE SoCs [8], [9], [10], [11], [12], with- mance results in our BLE based smartphone-centric applications. out quantifying BLE performance in a smartphone context. In these applications, developers can only access low-level func- However, smartphones-peripheral systems represent a large set tionalities through multiple layers of OS and hardware abstrac- of BLE applications in the wild [1], [2], [3]. In our work, tions. We propose an experimental framework for such systems, we thus focus on two questions: (1) Can we show systematic with which we perform experiments on a variety of modern smartphones. Our evaluation characterizes existing devices and variations in BLE application behavior across smartphone gives new insight about peripheral parameters settings. We show models? (2) Can we define a model to characterize BLE that BLE performances vary significantly in non-trivial ways, performance on smartphones, that could inform application depending on SoC and OS with a vast impact on applications. -

Bedienungsanleitung LG Google Nexus 4
MBM63860404 (1.1) G (1.1) MBM63860404 support.google.com/nexus For online help and support, visit visit support, and help online For Quick Start Guide Start Quick Kurzanleitung Online-Hilfe und Unterstützung fi nden Sie unter support.google.com/nexus Google, Android, Gmail, Google Maps, Nexus, Google Play, YouTube, Google+ und andere Marken sind Eigentum von Google Inc. Eine Liste mit Google-Marken ist unter http://www.google. com/permissions/guidelines.html verfügbar. LG und das LG- Logo sind Marken von LG Electronics Inc. Alle anderen Marken sind Eigentum ihrer jeweiligen Inhaber. Der Inhalt dieser Anleitung kann in einigen Details vom Produkt oder seiner Software abweichen. Alle Informationen in diesem Dokument können ohne vorherige Ankündigung geändert werden. Online-Hilfe und Unterstützung fi nden Sie unter support.google.com/nexus NEXUS 4 KURZANLEITUNG 1 Lieferumfang Ih 3 K a Micro-USB-Kabel N s Ladegerät/Netzkabel L t E Nexus 4 SIM-Auswurfschlüssel s S Diese Kurzanleitung und ein Heft mit Sicherheits- und Warnhinweisen sind ebenfalls Teil des Lieferumfangs. • Falls ein Teil beschädigt ist oder fehlt, wenden Sie sich für weitere Hilfe an Ihren Händler. • Verwenden Sie ausschließlich zugelassenes Zubehör. • Zubehör kann je nach Land unterschiedlich sein. 2 NEXUS 4 KURZANLEITUNG NE Ihr Nexus 4 3,5-mm- OBERSEITE Mikrofon Kopfhörer- anschluss Frontka- mera Näherungs- sensor Hörer Lautstärke- taste Ein-/Aus- und Sperrtaste Einlege- schacht für SIM-Karte LED ör. FRONTANSICHT NG NEXUS 4 KURZANLEITUNG 3 Kamera- L objektiv 3,5-mm- Na Kopfhörer- vo Ein-/Aus- anschluss und m Sperrtaste W Lautstärke- La Blitz taste En un La Induktions- Ne spule Laut- sprecher ZURÜCK Ladegerät/USB/ Mikrofon SlimPort UNTERSEITE 4 NEXUS 4 KURZANLEITUNG NE Laden des Akkus Nach dem Auspacken des Nexus 4 ist der Akku nicht vollständig geladen. -
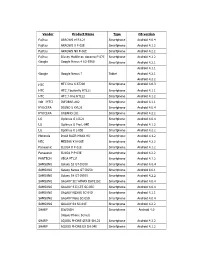
Vendor Product Name Type OS Version Fujitsu ARROWS Ef FJL21
Vendor Product Name Type OS version Fujitsu ARROWS ef FJL21 Smartphone Android 4.0.4 Fujitsu ARROWS X F-02E Smartphone Android 4.1.2 Fujitsu ARROWS NX F-06E Smartphone Android 4.2.2 Fujitsu Disney Mobile on docomo F-07E Smartphone Android 4.2.2 Google Google Nexus 4 LG-E960 Smartphone Android 4.2.1 Android 4.1.1 Google Google Nexus 7 Tablet Android 4.2.1 Android 4.2.2 HTC HTC One X S7200 Smartphone Android 4.0.3 HTC HTC J butterfly HTL21 Smartphone Android 4.1.1 HTC HTC J One HTL22 Smartphone Android 4.1.2 iida(HTC) INFOBAR A02 Smartphone Android 4.1.1 KYOCERA DIGNO S KYL21 Smartphone Android 4.0.4 KYOCERA URBANO L01 Smartphone Android 4.2.2 LG Optimus G LGL21 Smartphone Android 4.0.4 LG Optimus G Pro L-04E Smartphone Android 4.1.2 LG Optimus it L-05E Smartphone Android 4.2.2 Motorola Droid RAZR MAXX HD Smartphone Android 4.1.2 NEC MEDIAS X N-06E Smartphone Android 4.2.2 Panasonic ELUGA X P-02E Smartphone Android 4.1.2 Panasonic ELUGA P P-03E Smartphone Android 4.2.2 PANTECH VEGA PTL21 Smartphone Android 4.1.2 SAMSUNG Galaxy S3 GT-I9300 Smartphone Android 4.0.4 SAMSUNG Galaxy Nexus GT-I9250 Smartphone Android 4.0.1 SAMSUNG Galaxy S4 GT-I9505 Smartphone Android 4.2.2 SAMSUNG GALAXY SII WiMAX ISW11SC Smartphone Android 4.0.4 SAMSUNG GALAXY S II LTE SC-03D Smartphone Android 4.0.4 SAMSUNG GALAXY NEXUS SC-04D Smartphone Android 4.1.1 SAMSUNG GALAXY Note SC-05D Smartphone Android 4.0.4 SAMSUNG GALAXY S4 SC-04E Smartphone Android 4.2.2 SHARP ISW16SH Smartphone Android 4.0 (Aquos Phone Series) SHARP AQUOS PHONE SERIE SHL22 Smartphone Android -

The Misuse of Android Unix Domain Sockets and Security Implications
The Misuse of Android Unix Domain Sockets and Security Implications Yuru Shaoy, Jason Ott∗, Yunhan Jack Jiay, Zhiyun Qian∗, Z. Morley Maoy yUniversity of Michigan, ∗University of California, Riverside {yurushao, jackjia, zmao}@umich.edu, [email protected], [email protected] ABSTRACT eral vulnerabilities (e.g., CVE-2011-1823, CVE-2011-3918, In this work, we conduct the first systematic study in un- and CVE-2015-6841) have already been reported. Vendor derstanding the security properties of the usage of Unix do- customizations make things worse, as they expose additional main sockets by both Android apps and system daemons Linux IPC channels: CVE-2013-4777 and CVE-2013-5933. as an IPC (Inter-process Communication) mechanism, espe- Nevertheless, unlike Android IPCs, the use of Linux IPCs cially for cross-layer communications between the Java and on Android has not yet been systematically studied. native layers. We propose a tool called SInspector to ex- In addition to the Android system, apps also have access pose potential security vulnerabilities in using Unix domain to the Linux IPCs implemented within Android. Among sockets through the process of identifying socket addresses, them, Unix domain sockets are the only one apps can easily detecting authentication checks, and performing data flow make use of: signals are not capable of carrying data and analysis. Our in-depth analysis revealed some serious vul- not suitable for bidirectional communications; Netlink sock- nerabilities in popular apps and system daemons, such as ets are geared for communications across the kernel space root privilege escalation and arbitrary file access. Based and the user space. -

Android Supported Devices
Android Supported Devices Mobile Track Call Notifications Call Notifications Text Notifications Music Control Make Model OS Required Requires Google Play Requires OS 4.3+ Requires OS 4.3+ Requires OS 4.3+ Requires OS 4.4+ Services (Charge, Charge HR) (Surge) (Surge) (Surge) Samsung Galaxy S3 — ✓ ✓ ✓ — Galaxy S3 Mini (excluding Samsung — — “Value Edition” GT-i8200) ✓ ✓ ✓ Samsung Galaxy S4 — ✓ ✓ ✓ ✓ Samsung Galaxy S4 mini — ✓ ✓ ✓ ✓ Samsung Galaxy S4 Active — ✓ ✓ ✓ ✓ Samsung Galaxy S4 Zoom — ✓ ✓ ✓ ✓ Samsung Galaxy S5 — ✓ ✓ ✓ ✓ Samsung Galaxy S5 Mini — ✓ ✓ ✓ ✓ Samsung Galaxy S6 — ✓ ✓ ✓ ✓ Samsung Galaxy S6 Edge — ✓ ✓ ✓ ✓ Samsung Galaxy Note II — ✓ ✓ ✓ ✓ Samsung Galaxy Note II Duos — ✓ ✓ ✓ ✓ Samsung Galaxy Young 2 Duos — ✓ ✓ ✓ ✓ Samsung Galaxy Note III — ✓ ✓ ✓ ✓ Samsung Galaxy Note III Round — ✓ ✓ ✓ ✓ Samsung Galaxy Note 4 — ✓ ✓ ✓ ✓ Samsung Galaxy Note Edge — ✓ ✓ ✓ ✓ Samsung Galaxy Note 8.0 — ✓ ✓ ✓ ✓ Samsung Galaxy Note 10.1 — ✓ ✓ ✓ ✓ Samsung Galaxy Rugby Pro — ✓ ✓ ✓ ✓ Samsung Galaxy Mega — ✓ ✓ ✓ ✓ Samsung Galaxy S5 Active — ✓ ✓ ✓ ✓ Samsung Galaxy S5 Sport — ✓ ✓ ✓ ✓ Fitbit | Android Supported Devices Page 1 of 7 Android Supported Devices Mobile Track Call Notifications Call Notifications Text Notifications Music Control Make Model OS Required Requires Google Play Requires OS 4.3+ Requires OS 4.3+ Requires OS 4.3+ Requires OS 4.4+ Services (Charge, Charge HR) (Surge) (Surge) (Surge) Samsung Galaxy S3 Neo — ✓ ✓ ✓ — Samsung Galaxy S3 Slim — ✓ ✓ ✓ — Samsung Galaxy Ace Style — ✓ ✓ ✓ ✓ Samsung Galaxy Tab 3 — ✓ ✓ ✓ ✓ Samsung Galaxy Tab S — ✓ ✓ ✓ ✓ -

Quick Start Guide
TM Quick Start Guide English Android 5.0, Lollipop Copyright © 2014 Google Inc. All rights reserved. Edition 1.5a Google, Android, Gmail, Google Maps, Chrome, Chromecast, Android Wear, Nexus, Google Play, YouTube, Google+, and other trademarks are property of Google Inc. A list of Google trademarks is available at http://www.google. com/permissions/trademark/our-trademarks.html. All other marks and trademarks are properties of their respective owners. This book introduces Android 5.0, Lollipop for Nexus and Google Play edi- tion devices. Its content may differ in some details from some of the prod- ucts described or the software that runs on them. All information provided here is subject to change without notice. For best results, make sure you’re running the latest Android system update. To find your device’s version number or check for the latest system update, go to Settings > System > About phone or About tablet and look for Android version or System updates. If you don’t have a Nexus or Google Play edition phone or tablet and are running Android 5.0 on some other device, some details of the system as described in this book may vary. For comprehensive online help and support, including details about Nexus and Google Play edition hardware running the software described in this book and links to information about other Android devices, visit support. google.com/android. ANDROID QUICK START GUIDE ii Table of contents 1 Welcome to Android 1 About Android 5.0, Lollipop 1 Android Auto 2 Android TV 2 Android Wear 3 Set up your device 3 Make -

Android Quick Start Guide, Android 5.0, Lollipop
TM QuickStartGuide English Android5.0,Lollipop Copyright©2014GoogleInc.Allrightsreserved. Edition1.0 Google,Android,Gmail,GoogleMaps,Chrome,Chromecast,AndroidWear, Nexus,GooglePlay,YouTube,Google+,andothertrademarksareproperty ofGoogleInc.AlistofGoogletrademarksisavailableathttp://www.google. com/permissions/trademark/our-trademarks.html.Allothermarksand trademarksarepropertiesoftheirrespectiveowners. ThisbookintroducesAndroid5.0,LollipopforNexusandGooglePlayedi tiondevices.Itscontentmaydifferinsomedetailsfromsomeoftheprod uctsdescribedorthesoftwarethatrunsonthem.Allinformationprovided hereissubjecttochangewithoutnotice. Forbestresults,makesureyou’rerunningthelatestAndroidsystemupdate. Tofindyourdevice’sversionnumberorcheckforthelatestsystemupdate, goto Settings>System>AboutphoneorAbouttabletandlookfor AndroidversionorSystemupdates. Ifyoudon’thaveaNexusorGooglePlayeditionphoneortabletandare runningAndroid5.0onsomeotherdevice,somedetailsofthesystemas describedinthisbookmayvary. Forcomprehensiveonlinehelpandsupport,includingdetailsaboutNexus andGooglePlayeditionhardwarerunningthesoftwaredescribedinthis bookandlinkstoinformationaboutotherAndroiddevices,visitsupport. google.com/android. ANDROIDQUICKSTARTGUIDE ii Tableofcontents 1 WelcometoAndroid 1 AboutAndroid5.0,Lollipop 1 AndroidAuto,AndroidTV,andAndroidWear 2 AndroidAuto 2 AndroidTV 2 AndroidWear 2 Setupyourdevice 3 Makeyourselfathome 4 SendanSMS(textmessage)fromyourphone5 Makeaphonecall 5 Makeavideocall 6 Sendanemail 7 Statusbar 7 QuickSettings 7 Managebatterylife 8 Getaround 9 Nexusnavigationbuttons