Leveraging Resources on Anonymous Mobile Edge Nodes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Yibo Wu Final.Pdf
The Pennsylvania State University The Graduate School RESOURCE-AWARE CROWDSOURCING IN WIRELESS NETWORKS A Dissertation in Computer Science and Engineering by Yibo Wu c 2018 Yibo Wu Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy May 2018 The dissertation of Yibo Wu was reviewed and approved∗ by the following: Guohong Cao Professor of Computer Science and Engineering Dissertation Adviser, Chair of Committee Robert Collins Associate Professor of Computer Science and Engineering Sencun Zhu Associate Professor of Computer Science and Engineering Associate Professor of Information Sciences and Technology Zhenhui Li Associate Professor of Information Sciences and Technology Bhuvan Urgaonkar Associate Professor of Computer Science and Engineering Graduate Program Chair of Computer Science and Engineering ∗Signatures are on file in the Graduate School. Abstract The ubiquity of mobile devices has opened up opportunities for a wide range of applications based on photo/video crowdsourcing, where the server collects a large number of photos/videos from the public to obtain desired information. How- ever, transmitting large numbers of photos/videos in a wireless environment with bandwidth constraints is challenging, and it is hard to run computation-intensive image processing techniques on mobile devices with limited energy and computa- tion power to identify the useful photos/videos and remove redundancy. To address these challenges, we propose a framework to quantify the quality of crowdsourced photos/videos based on the accessible geographical and geometrical information (called metadata) including the orientation, position, and all other related param- eters of the built-in camera. From metadata, we can infer where and how the photo/video is taken, and then only transmit the most useful photos/videos. -

Performance Study of Real-Time Operating Systems for Internet Of
IET Software Research Article ISSN 1751-8806 Performance study of real-time operating Received on 11th April 2017 Revised 13th December 2017 systems for internet of things devices Accepted on 13th January 2018 E-First on 16th February 2018 doi: 10.1049/iet-sen.2017.0048 www.ietdl.org Rafael Raymundo Belleza1 , Edison Pignaton de Freitas1 1Institute of Informatics, Federal University of Rio Grande do Sul, Av. Bento Gonçalves, 9500, CP 15064, Porto Alegre CEP: 91501-970, Brazil E-mail: [email protected] Abstract: The development of constrained devices for the internet of things (IoT) presents lots of challenges to software developers who build applications on top of these devices. Many applications in this domain have severe non-functional requirements related to timing properties, which are important concerns that have to be handled. By using real-time operating systems (RTOSs), developers have greater productivity, as they provide native support for real-time properties handling. Some of the key points in the software development for IoT in these constrained devices, like task synchronisation and network communications, are already solved by this provided real-time support. However, different RTOSs offer different degrees of support to the different demanded real-time properties. Observing this aspect, this study presents a set of benchmark tests on the selected open source and proprietary RTOSs focused on the IoT. The benchmark results show that there is no clear winner, as each RTOS performs well at least on some criteria, but general conclusions can be drawn on the suitability of each of them according to their performance evaluation in the obtained results. -

Using Mcuboot with RA Family Mcus Introduction Mcuboot Is a Secure Bootloader for 32-Bit Mcus
Application Note Renesas RA Family Using MCUboot with RA Family MCUs Introduction MCUboot is a secure bootloader for 32-bit MCUs. It defines a common infrastructure for the bootloader, defines system flash layout on microcontroller systems, and provides a secure bootloader that enables easy software update. MCUboot is operating system and hardware independent and relies on hardware porting layers from the operating system it works with. The Renesas Flexible Software Package (FSP) integrates an MCUboot port starting from FSP v3.0.0. Users can benefit from using the FSP MCUboot Module to create a Root of Trust (RoT) for the system and perform secure booting and fail-safe application updates. The MCUboot is maintained by Linaro in the GitHub mcu-tools page https://github.com/mcu-tools/mcuboot. There is a \docs folder that holds the documentation for MCUboot in .md file format. This application note will refer to the above-mentioned documents wherever possible and is intended to provide additional information that is related to using the MCUboot Module with Renesas RA FSP v3.0.0 or later. This application note walks the user through application project creation using the MCUboot Module on Renesas EK-RA6M4 and EK-RA6M3 kits. Example projects for the use case of designing with TrustZone for multi-image support is provided for EK-RA6M4. Example projects for the use case of designing with single image support is provided for EK-RA6M3. The MCUboot Module is supported across the entire RA MCU Family. Guidelines of how to adapt the example project configurations for other RA Family MCUs are provided. -

Technical Overview 11 October 2016 Problem and Context
Technical Overview 11 October 2016 Problem and Context First release of a successful connected product… …. now make that repeatable please. An Open Source OS for MCUs • Open source networking stacks: Bluetooth Host and Controller • Pre-empGve, ckless RTOS with power management Security • Secure bootloader and Image Upgrade Networking Stats & Console & Config & • Flash FS and Access Mechanisms Logging Shell Upgrade Drivers Power • Build & Package Management OS HAL • Management Interfaces Secure Bootloader & FFS A Community Driven OS Why Apache So<ware Founda?on? Cloud Providers IP Providers • Liberal, BSD-style license • Strong Licensing and IP policies • Meritocracy • Free to contribute, contributors control project direcGon. • History of working with large organizaons: IBM, Pivotal/ EMC, MicrosoY. • Many years experience managing large, complex projects (e.g., Apache, Hadoop, MCU Vendors End-Users Subversion) Community driven open source best way to maintain healthy ecosystem RTOS • Tickless operaon: low power hooks • Driver Interface • Pre-empGve, mulGtasking RTOS • Strict priority-based scheduling • Up to 253 different priority levels • Unified buffer management • Resource uGlizaon tracking and watchdog • High-resoluGon Gmers • Built-in tasks: • Idle RTOS - Event Driven Model • Event Queues provide a mechanism for “mostly-sleeping” asynchronous tasks • Wake-up on: • Message from another Task • Timer • I/O state change • Incoming packet • Watchdog • Perform operaons: • Send an alert • Respond to a request • Schedule a wakeup • Go back to -

Zephyr-RTOS Übersicht Und Status
Zephyr-RTOS Übersicht und Status ECC 1. Juni 2021, © Markus Kappeler About me ● Markus Kappeler ● 25 years in business ● Soft- and Hardware development ● Founder of bytesatwork ● Sailing, Skiing Hiking and Mountain-Biking Agenda ● Zephyr ● Was ist Zephyr ● Features ● Roadmap ● RTOS – Realtime ● Footprint ● Bootloader mcuboot Zephyr Project ● Opensource Realtime Betriebsystem ● Lebendige Community ● Mehrere Architekturen ● Modular und Konfigurierbar ● Bereit für Produkt-Entwicklung Zephyr Hardware Architekturen Zephyr Projekt Mitglieder Februar 2016 2021 Upstream commits last year Momentum 2016 2021 Entwickler 80 969 Commits 2806 52591 Boards 4 250+ Zephyr Board-Unterstützung Siehe auch: https://docs.zephyrproject.org/latest/boards/index.html Zephyr Ecosystem Kernel / HAL Zephyr OS Zephyr “Community” • Scheduler • Kernel objects und services • Kernel und HAL Zephyr Project • low-level Architektur und BSP • OS Services wie IPC, Logging, file • Power Management und low level systems, crypto Interfaces zur Hardware Zephyr Project OS Services and Low level APIs • Plattform spezifische Treiber Zephyr OS • Generisches I/O API • SDK, Tools und Kernel / HAL Entwicklungsumgebung • File systems, Logging, Debugging und IPC • Zusätzliche Middleware OS Services • Cryptography Services • Device Management und Application Services Bootloader • Networking und Connectivity Application Services Zephyr Community • High Level APIs • Zugang zu standardisierten Daten • 3rd Party Module und Bibliotheken Modellen • Support für Zephyr in 3rd Party • High Level -

Demystifying Internet of Things Security Successful Iot Device/Edge and Platform Security Deployment — Sunil Cheruvu Anil Kumar Ned Smith David M
Demystifying Internet of Things Security Successful IoT Device/Edge and Platform Security Deployment — Sunil Cheruvu Anil Kumar Ned Smith David M. Wheeler Demystifying Internet of Things Security Successful IoT Device/Edge and Platform Security Deployment Sunil Cheruvu Anil Kumar Ned Smith David M. Wheeler Demystifying Internet of Things Security: Successful IoT Device/Edge and Platform Security Deployment Sunil Cheruvu Anil Kumar Chandler, AZ, USA Chandler, AZ, USA Ned Smith David M. Wheeler Beaverton, OR, USA Gilbert, AZ, USA ISBN-13 (pbk): 978-1-4842-2895-1 ISBN-13 (electronic): 978-1-4842-2896-8 https://doi.org/10.1007/978-1-4842-2896-8 Copyright © 2020 by The Editor(s) (if applicable) and The Author(s) This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Open Access This book is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made. The images or other third party material in this book are included in the book’s Creative Commons license, unless indicated otherwise in a credit line to the material. -

A Rust-Based Runtime for the Internet of Things
A Rust-based Runtime for the Internet of Things Fredrik Nilsson Niklas Adolfsson Department of Computer Science and Engineering CHALMERS UNIVERSITY OF TECHNOLOGY UNIVERSITY OF GOTHENBURG Gothenburg, Sweden 2017 Master’s thesis 2017 A Rust-based Runtime for the Internet of Things Fredrik Nilsson Niklas Adolfsson Department of Computer Science and Engineering Chalmers University of Technology University of Gothenburg Gothenburg, Sweden 2017 A Rust-based Runtime for the Internet of Things Fredrik Nilsson Niklas Adolfsson © Fredrik Nilsson, Niklas Adolfsson, 2017. Supervisor: Olaf Landsiedel Examiner: Magnus Almgren Master’s Thesis 2017 Department of Computer Science and Engineering Chalmers University of Technology and University of Gothenburg SE-412 96 Gothenburg Telephone +46 31 772 1000 Typeset in LATEX Gothenburg, Sweden 2017 iv A Rust-based Runtime for the Internet of Things Fredrik Nilsson Niklas Adolfsson Department of Computer Science and Engineering Chalmers University of Technology and University of Gothenburg Abstract As the number of connected devices increases, known as the Internet of Things (IoT), reliability and security become more important. C and C++ are common programming languages for IoT devices, mostly due to their fine-grained memory management and low runtime overhead. As these languages are not memory-safe and memory management has proven to be difficult to handle correctly, problems such as buffer overflows and dangling pointers are likely to increase as the IoT de- vices become more prevalent. These problems can result in reliability and security issues. In contrast to C and C++, Rust is a memory-safe systems programming lan- guage that, just like C and C++, provides low runtime overhead and fine-grained memory management. -

Terraillon Wellness Coach Supported Devices
Terraillon Wellness Coach Supported Devices Warning This document lists the smartphones compatible with the download of the Wellness Coach app from the App Store (Apple) and Play Store (Android). Some models have been tested by Terraillon to check the compatibility and smooth operation of the Wellness Coach app. However, many models have not been tested. Therefore, Terraillon doesn't ensure the proper functioning of the Wellness Coach application on these models. If your smartphone model does not appear in the list, thank you to send an email to [email protected] giving us the model of your smartphone so that we can activate if the application store allows it. BRAND MODEL NAME MANUFACTURER MODEL NAME OS REQUIRED ACER Liquid Z530 acer_T02 Android 4.3+ ACER Liquid Jade S acer_S56 Android 4.3+ ACER Liquid E700 acer_e39 Android 4.3+ ACER Liquid Z630 acer_t03 Android 4.3+ ACER Liquid Z320 T012 Android 4.3+ ARCHOS 45 Helium 4G a45he Android 4.3+ ARCHOS 50 Helium 4G a50he Android 4.3+ ARCHOS Archos 45b Helium ac45bhe Android 4.3+ ARCHOS ARCHOS 50c Helium ac50che Android 4.3+ APPLE iPhone 4S iOS8+ APPLE iPhone 5 iOS8+ APPLE iPhone 5C iOS8+ APPLE iPhone 5S iOS8+ APPLE iPhone 6 iOS8+ APPLE iPhone 6 Plus iOS8+ APPLE iPhone 6S iOS8+ APPLE iPhone 6S Plus iOS8+ APPLE iPad Mini 1 iOS8+ APPLE iPad Mini 2 iOS8+ 1 / 48 www.terraillon.com Terraillon Wellness Coach Supported Devices BRAND MODEL NAME MANUFACTURER MODEL NAME OS REQUIRED APPLE iPad Mini 3 iOS8+ APPLE iPad Mini 4 iOS8+ APPLE iPad 3 iOS8+ APPLE iPad 4 iOS8+ APPLE iPad Air iOS8+ -
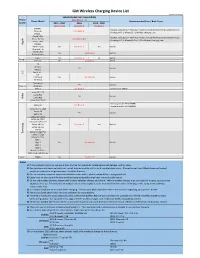
GM Wireless Charging Device List
GM Wireless Charging Device List Revision: Aug 30, 2019 Vehicle Model Year Compatibility Phone ( See Notes 1 - 7) Phone Model Recommended Case / Back Cover Brand 2015 - 2017 2018 2019 - 2020 (See Note 8) (See Note 8) (See Note 9) iPhone 6 ŸBEZALEL Latitude [Qi + PMA] Dual-Mode Universal Wireless Charging Receiver Case iPhone 6s See Note: A ŸAircharge MFi Qi iPhone 6S / 6 Wireless Charging Case iPhone 7 iPhone 6 Plus ŸBEZALEL Latitude [Qi + PMA] Dual-Mode Universal Wireless Charging Receiver Case e iPhone 6s Plus See Note: A & B l ŸAircharge MFi Qi iPhone 6S Plus / 6 Plus Wireless Charging Case p iPhone 7 Plus p A iPhone 8 iPhone X (10) No See Note: C Yes Built-in iPhone Xs / Xr iPhone 8 Plus No See Note: B Built-in iPhone Xs Max Pixel 3 No See Note: C Yes Built-in Google Pixel 3XL No See Note: B Built-in G6 Nexus 4 Yes Built-in Nexus 5 G Spectrum 2 L V30 V40 ThinQ No See Note: B Built-in G7 ThinQ Droid Maxx Yes Built-in Motorola Droid Mini Moto X See Note: A Incipio model: MT231 Lumia 830 / 930 a i Lumia 920 k Yes Built-in o Lumia 928 N Lumia 950 / 950 XL ŸSamsung model: EP-VG900BBU Galaxy S5 See Note: A ŸSamsung model: EP-CG900IBA Galaxy S6 / S6 Edge Galaxy S8 Yes Built-in Galaxy S9 Galaxy S10 / S10e Galaxy S6 Active Galaxy S7 / S7 Active g Galaxy S8 Plus No See Note: C Yes Built-in n u Galaxy S9 Plus s m S10 5G a Galaxy S6 Edge Plus S Galaxy S7 Edge Galaxy S10 Plus Note 5 Note 7 No See Note: B Built-in Note 8 Note 9 Note 10 / 10 Plus Note 10 5G / 10 Plus 5G Xiami MIX2S No See Note: B Built-in Notes: 1) If phone does not charge: remove it from charger for 3 seconds, rotate phone 180 degrees, and try again. -

Nexus-4 User Manual
NeXus-4 User Manual Version 2.0 0344 Table of contents 1 Service and support 3 1.1 About this manual 3 1.2 Warranty information 3 2 Safety information 4 2.1 Explanation of markings 4 2.2 Limitations of use 5 2.3 Safety measures and warnings 5 2.4 Precautionary measures 7 2.5 Disclosure of residual risk 7 2.6 Information for lay operators 7 3 Product overview 8 3.1 Product components 8 3.2 Intended use 8 3.3 NeXus-4 views 9 3.4 User interface 9 3.5 Patient connections 10 3.6 Device label 10 4 Instructions for use 11 4.1 Software 11 4.2 Powering the NeXus-4 12 4.3 Transfer data to PC 12 4.4 Perform measurement 13 4.5 Mobility 13 5 Operational principles 14 5.1 Bipolar input channels 14 5.2 Auxiliary input channel 14 5.3 Filtering 14 6 Maintenance 15 7 Electromagnetic guidance 16 8 Technical specifications 19 2 1 Service and support 1.1 About this manual This manual is intended for the user of the NeXus-4 system – referred to as ‘product’ throughout this manual. It contains general operating instructions, precautionary measures, maintenance instructions and information for use of the product. Read this manual carefully and familiarize yourself with the various controls and accessories before starting to use the product. This product is exclusively manufactured by Twente Medical Systems International B.V. for Mind Media B.V. Distribution and service is exclusively performed by or through Mind Media B.V. -

Vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus
vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus 7 HTC HTC One (M7) HTC One (M9) HTC Butterfly S HTC One (M8) HTC One (M10) LG LG Flex LG V20 LG G4 H815 LG G3 LG E988 Gpro LG G5 H860 LG V10 H962 LG G3 Titan Motorola Motorola RAZR M Motorola DROID Turbo Motorola Moto G (2st Gen) Motorola Droid MAXX Motorola Moto G (1st Gen) Motorola Moto X (1st Gen) Samsung Samsung Galaxy S6 edge + Samsung Galaxy Note 2 Samsung Galaxy S4 Active (SM-G9287) Samsung Galaxy S7 edge (SM- Samsung Galaxy Note 3 Samsung Galaxy S4 Mini G935FD) Samsung Galaxy Note 4 Samsung Galaxy S5 Samsung GALAXY J Samsung Galaxy Note 5 (SM- N9208) Samsung Galaxy S5 Active Samsung Galaxy A5 Duos Samsung Galaxy A9 (SM- Samsung Galaxy S3 Samsung Galaxy S5 Mini A9000) Samsung Galaxy S4 Samsung Galaxy S6 Sony Sony Ericsson Xperia Z Sony Xperia Z2 Sony Xperia X Sony Ericsson Xperia Z Ultra Sony Xperia Z3 Sony XPERIA Z5 Sony Ericsson Xperia Z1 Sony Xperia Z3 Compact Asus ASUS Zenfone 2 ASUS Zenfone 5 ASUS Zenfone 6 Huawei HUAWEI P8 HUAWEI CRR_L09 HUAWEI P9 Oppo OPPO X9076 OPPO X9009 Xiaomi XIAOMI 2S XIAOMI 3 XIAOMI 5 XIAOMI Note One Plus OnePlus 3 (A3000) vívosmart® 3 Google Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Pixel HTC HTC One (M9) HTC One (M10) HTC U11 HTC One (A9) HTC U Ultra LG LG V10 H962 LG G4 H815 LG G6 H870 LG V20 LG G5 H860 Motorola Motorola Moto Z Samsung Samsung Galaxy Note 3 Samsung Galaxy S6 Samsung Galaxy J5 Samsung Galaxy S6 edge + Samsung Galaxy Note 4 (SM-G9287) Samsung Galaxy -

Handset Industry 2013 Outlook
07 January 2013 Americas/United States Equity Research Telecommunications Equipment / MARKET WEIGHT Handset Industry 2013 Outlook Research Analysts INDUSTRY PRIMER Kulbinder Garcha 212 325 4795 [email protected] Bigger market, Apple and Samsung win Achal Sultania 44 20 7883 6884 ■ Market size underestimated for both smartphones/handsets. Our bottom-up [email protected] analysis suggests that the market underestimates the size of low-end ‘white- Talal Khan, CFA label’ smartphones, which causes us to restate our 2012/2013 volume estimates 212 325 8603 for the smartphone market higher by 6%/15% and 3%/4% for overall handsets. [email protected] We also raise our smartphone volume estimates by 20-25% long term and now Matthew Cabral estimate 1.43bn/1.74bn smartphones to be shipped in 2015/2017. We believe 212 538 6260 that the growth of ‘white-label’ smartphone market specifically poses a threat for [email protected] vendors like Nokia, RIMM, LG and possibly Samsung, given their exposure to feature phones and low-end smartphone segments. Ray Bao 212 325 1227 ■ Raising LT smartphone units to 1.74bn – a barbell develops for price points. [email protected] We believe that the addressable market for smartphones is 4.95bn longer term, Asian Research Analysts resulting in effective penetration of only 24% currently given our estimate of 1.2bn smartphone users by end of 2012. We expect effective smartphone Randy Abrams, CFA 886 2 2715 6366 penetration to rise to ~80% long term driving smartphone volumes of [email protected] 1.43bn/1.74bn units by 2015/2017 (26%/19% CAGR over this period).