Structure, Folding and Stability of Nucleoside Diphosphate Kinases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gene Symbol Gene Description ACVR1B Activin a Receptor, Type IB
Table S1. Kinase clones included in human kinase cDNA library for yeast two-hybrid screening Gene Symbol Gene Description ACVR1B activin A receptor, type IB ADCK2 aarF domain containing kinase 2 ADCK4 aarF domain containing kinase 4 AGK multiple substrate lipid kinase;MULK AK1 adenylate kinase 1 AK3 adenylate kinase 3 like 1 AK3L1 adenylate kinase 3 ALDH18A1 aldehyde dehydrogenase 18 family, member A1;ALDH18A1 ALK anaplastic lymphoma kinase (Ki-1) ALPK1 alpha-kinase 1 ALPK2 alpha-kinase 2 AMHR2 anti-Mullerian hormone receptor, type II ARAF v-raf murine sarcoma 3611 viral oncogene homolog 1 ARSG arylsulfatase G;ARSG AURKB aurora kinase B AURKC aurora kinase C BCKDK branched chain alpha-ketoacid dehydrogenase kinase BMPR1A bone morphogenetic protein receptor, type IA BMPR2 bone morphogenetic protein receptor, type II (serine/threonine kinase) BRAF v-raf murine sarcoma viral oncogene homolog B1 BRD3 bromodomain containing 3 BRD4 bromodomain containing 4 BTK Bruton agammaglobulinemia tyrosine kinase BUB1 BUB1 budding uninhibited by benzimidazoles 1 homolog (yeast) BUB1B BUB1 budding uninhibited by benzimidazoles 1 homolog beta (yeast) C9orf98 chromosome 9 open reading frame 98;C9orf98 CABC1 chaperone, ABC1 activity of bc1 complex like (S. pombe) CALM1 calmodulin 1 (phosphorylase kinase, delta) CALM2 calmodulin 2 (phosphorylase kinase, delta) CALM3 calmodulin 3 (phosphorylase kinase, delta) CAMK1 calcium/calmodulin-dependent protein kinase I CAMK2A calcium/calmodulin-dependent protein kinase (CaM kinase) II alpha CAMK2B calcium/calmodulin-dependent -

In Silico Prediction of High-Resolution Hi-C Interaction Matrices
ARTICLE https://doi.org/10.1038/s41467-019-13423-8 OPEN In silico prediction of high-resolution Hi-C interaction matrices Shilu Zhang1, Deborah Chasman 1, Sara Knaack1 & Sushmita Roy1,2* The three-dimensional (3D) organization of the genome plays an important role in gene regulation bringing distal sequence elements in 3D proximity to genes hundreds of kilobases away. Hi-C is a powerful genome-wide technique to study 3D genome organization. Owing to 1234567890():,; experimental costs, high resolution Hi-C datasets are limited to a few cell lines. Computa- tional prediction of Hi-C counts can offer a scalable and inexpensive approach to examine 3D genome organization across multiple cellular contexts. Here we present HiC-Reg, an approach to predict contact counts from one-dimensional regulatory signals. HiC-Reg pre- dictions identify topologically associating domains and significant interactions that are enri- ched for CCCTC-binding factor (CTCF) bidirectional motifs and interactions identified from complementary sources. CTCF and chromatin marks, especially repressive and elongation marks, are most important for HiC-Reg’s predictive performance. Taken together, HiC-Reg provides a powerful framework to generate high-resolution profiles of contact counts that can be used to study individual locus level interactions and higher-order organizational units of the genome. 1 Wisconsin Institute for Discovery, 330 North Orchard Street, Madison, WI 53715, USA. 2 Department of Biostatistics and Medical Informatics, University of Wisconsin-Madison, Madison, WI 53715, USA. *email: [email protected] NATURE COMMUNICATIONS | (2019) 10:5449 | https://doi.org/10.1038/s41467-019-13423-8 | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | https://doi.org/10.1038/s41467-019-13423-8 he three-dimensional (3D) organization of the genome has Results Temerged as an important component of the gene regulation HiC-Reg for predicting contact count using Random Forests. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

Identification of Conserved Genes Triggering Puberty in European Sea
Blázquez et al. BMC Genomics (2017) 18:441 DOI 10.1186/s12864-017-3823-2 RESEARCHARTICLE Open Access Identification of conserved genes triggering puberty in European sea bass males (Dicentrarchus labrax) by microarray expression profiling Mercedes Blázquez1,2* , Paula Medina1,2,3, Berta Crespo1,4, Ana Gómez1 and Silvia Zanuy1* Abstract Background: Spermatogenesisisacomplexprocesscharacterized by the activation and/or repression of a number of genes in a spatio-temporal manner. Pubertal development in males starts with the onset of the first spermatogenesis and implies the division of primary spermatogonia and their subsequent entry into meiosis. This study is aimed at the characterization of genes involved in the onset of puberty in European sea bass, and constitutes the first transcriptomic approach focused on meiosis in this species. Results: European sea bass testes collected at the onset of puberty (first successful reproduction) were grouped in stage I (resting stage), and stage II (proliferative stage). Transition from stage I to stage II was marked by an increase of 11ketotestosterone (11KT), the main fish androgen, whereas the transcriptomic study resulted in 315 genes differentially expressed between the two stages. The onset of puberty induced 1) an up-regulation of genes involved in cell proliferation, cell cycle and meiosis progression, 2) changes in genes related with reproduction and growth, and 3) a down-regulation of genes included in the retinoic acid (RA) signalling pathway. The analysis of GO-terms and biological pathways showed that cell cycle, cell division, cellular metabolic processes, and reproduction were affected, consistent with the early events that occur during the onset of puberty. -

Characterization of the Small RNA Transcriptomes of Cell Protrusions and Cell Bodies of Highly Metastatic Hepatocellular Carcinoma Cells Via RNA Sequencing
ONCOLOGY LETTERS 22: 568, 2021 Characterization of the small RNA transcriptomes of cell protrusions and cell bodies of highly metastatic hepatocellular carcinoma cells via RNA sequencing WENPIN CAI1*, JINGZHANG JI2*, BITING WU2*, KAIXUAN HAO2, PING REN2, YU JIN2, LIHONG YANG2, QINGCHAO TONG2 and ZHIFA SHEN2 1Department of Laboratory Medicine, Wen Zhou Traditional Chinese Medicine Hospital; 2Zhejiang Provincial Key Laboratory of Medical Genetics, Key Laboratory of Laboratory Medicine, Ministry of Education, School of Laboratory Medicine and Life Sciences, Wenzhou Medical University, Wenzhou, Zhejiang 325035, P.R. China Received July 11, 2020; Accepted February 23, 2021 DOI: 10.3892/ol.2021.12829 Abstract. Increasing evidence suggest that hepatocellular differentially expressed miRNAs and circRNAs. The interac‑ carcinoma (HCC) HCCLM3 cells initially develop pseudo‑ tion maps between miRNAs and circRNAs were constructed, podia when they metastasize, and microRNAs (miRNAs/miRs) and signaling pathway maps were analyzed to determine the and circular RNAs (circRNAs) have been demonstrated to molecular mechanism and regulation of the differentially serve important roles in the development, progression and expressed miRNAs and circRNAs. Taken together, the results metastasis of cancer. The present study aimed to isolate the of the present study suggest that the Boyden chamber assay cell bodies (CBs) and cell protrusions (CPs) from HCCLM3 can be used to effectively isolate the somatic CBs and CPs of cells, and screen the miRNAs and circRNAs associated with HCC, which can be used to screen the miRNAs and circRNAs HCC infiltration and metastasis in CBs and CPs. The Boyden associated with invasion and metastasis of HCC. chamber assay has been confirmed to effectively isolate the CBs and CPs from HCCLM3 cells via observation of microtu‑ Introduction bule immunofluorescence, DAPI staining and nuclear protein H3 western blotting. -

The Function of NM23-H1/NME1 and Its Homologs in Major Processes Linked to Metastasis
University of Dundee The Function of NM23-H1/NME1 and Its Homologs in Major Processes Linked to Metastasis Mátyási, Barbara; Farkas, Zsolt; Kopper, László; Sebestyén, Anna; Boissan, Mathieu; Mehta, Anil Published in: Pathology and Oncology Research DOI: 10.1007/s12253-020-00797-0 Publication date: 2020 Licence: CC BY Document Version Publisher's PDF, also known as Version of record Link to publication in Discovery Research Portal Citation for published version (APA): Mátyási, B., Farkas, Z., Kopper, L., Sebestyén, A., Boissan, M., Mehta, A., & Takács-Vellai, K. (2020). The Function of NM23-H1/NME1 and Its Homologs in Major Processes Linked to Metastasis. Pathology and Oncology Research, 26(1), 49-61. https://doi.org/10.1007/s12253-020-00797-0 General rights Copyright and moral rights for the publications made accessible in Discovery Research Portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from Discovery Research Portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain. • You may freely distribute the URL identifying the publication in the public portal. Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine -

Characterization of the Small Molecule Kinase Inhibitor SU11248 (Sunitinib/ SUTENT in Vitro and in Vivo
TECHNISCHE UNIVERSITÄT MÜNCHEN Lehrstuhl für Genetik Characterization of the Small Molecule Kinase Inhibitor SU11248 (Sunitinib/ SUTENT in vitro and in vivo - Towards Response Prediction in Cancer Therapy with Kinase Inhibitors Michaela Bairlein Vollständiger Abdruck der von der Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt der Technischen Universität München zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften genehmigten Dissertation. Vorsitzender: Univ. -Prof. Dr. K. Schneitz Prüfer der Dissertation: 1. Univ.-Prof. Dr. A. Gierl 2. Hon.-Prof. Dr. h.c. A. Ullrich (Eberhard-Karls-Universität Tübingen) 3. Univ.-Prof. A. Schnieke, Ph.D. Die Dissertation wurde am 07.01.2010 bei der Technischen Universität München eingereicht und durch die Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt am 19.04.2010 angenommen. FOR MY PARENTS 1 Contents 2 Summary ................................................................................................................................................................... 5 3 Zusammenfassung .................................................................................................................................................... 6 4 Introduction .............................................................................................................................................................. 8 4.1 Cancer .............................................................................................................................................................. -

Association of Genetic Polymorphisms in Genes Involved in Ara-C And
Zhu et al. J Transl Med (2018) 16:90 https://doi.org/10.1186/s12967-018-1463-1 Journal of Translational Medicine RESEARCH Open Access Association of genetic polymorphisms in genes involved in Ara‑C and dNTP metabolism pathway with chemosensitivity and prognosis of adult acute myeloid leukemia (AML) Ke‑Wei Zhu1,2, Peng Chen1,2, Dao‑Yu Zhang1,2, Han Yan1,2, Han Liu1,2, Li‑Na Cen1,2, Yan‑Ling Liu1,2, Shan Cao1,2, Gan Zhou1,2, Hui Zeng4, Shu‑Ping Chen4, Xie‑Lan Zhao4 and Xiao‑Ping Chen1,2,3,5* Abstract Background: Cytarabine arabinoside (Ara-C) has been the core of chemotherapy for adult acute myeloid leukemia (AML). Ara-C undergoes a three-step phosphorylation into the active metabolite Ara-C triphosphosphate (ara-CTP). Several enzymes are involved directly or indirectly in either the formation or detoxifcation of ara-CTP. Methods: A total of 12 eQTL (expression Quantitative Trait Loci) single nucleotide polymorphisms (SNPs) or tag SNPs in 7 genes including CMPK1, NME1, NME2, RRM1, RRM2, SAMHD1 and E2F1 were genotyped in 361 Chinese non-M3 AML patients by using the Sequenom Massarray system. Association of the SNPs with complete remission (CR) rate after Ara-C based induction therapy, relapse-free survival (RFS) and overall survival (OS) were analyzed. Results: Three SNPs were observed to be associated increased risk of chemoresistance indicated by CR rate (NME2 rs3744660, E2F1 rs3213150, and RRM2 rs1130609), among which two (rs3744660 and rs1130609) were eQTL. Com‑ bined genotypes based on E2F1 rs3213150 and RRM2 rs1130609 polymorphisms further increased the risk of non-CR. -

Two Separate Functions of NME3 Critical for Cell Survival Underlie a Neurodegenerative Disorder
Two separate functions of NME3 critical for cell survival underlie a neurodegenerative disorder Chih-Wei Chena, Hong-Ling Wanga, Ching-Wen Huangb, Chang-Yu Huangc, Wai Keong Lima, I-Chen Tua, Atmaja Koorapatia, Sung-Tsang Hsiehd, Hung-Wei Kand, Shiou-Ru Tzenge, Jung-Chi Liaof, Weng Man Chongf, Inna Naroditzkyg, Dvora Kidronh,i, Ayelet Eranj, Yousif Nijimk, Ella Selak, Hagit Baris Feldmanl, Limor Kalfonm, Hadas Raveh-Barakm, Tzipora C. Falik-Zaccaim,n, Orly Elpelego, Hanna Mandelm,p,1, and Zee-Fen Changa,q,1 aInstitute of Molecular Medicine, College of Medicine, National Taiwan University, 10002 Taipei, Taiwan; bDepartment of Medicine, College of Medicine, National Taiwan University, 10002 Taipei, Taiwan; cInstitute of Biochemistry and Molecular Biology, National Yang-Ming University, 11221 Taipei, Taiwan; dInstitute of Anatomy and Cell Biology, College of Medicine, National Taiwan University, 10002 Taipei, Taiwan; eInstitute of Biochemistry and Molecular Biology, College of Medicine, National Taiwan University, 10002 Taipei, Taiwan; fInstitute of Atomic and Molecular Sciences, Academia Sinica, 10617 Taipei, Taiwan; gDepartment of Pathology, Rambam Health Care Campus, 31096 Haifa, Israel; hDepartment of Pathology, Meir Hospital, 44100 Kfar Saba, Israel; iSackler School of Medicine, Tel Aviv University, 69978 Tel Aviv, Israel; jDepartment of Radiology, Rambam Health Care Campus, 31096 Haifa, Israel; kPediatric and Neonatal Unit, Nazareth Hospital EMMS, 17639 Nazareth, Israel; lThe Genetics Institute, Rambam Health Care Campus, 31096 Haifa, Israel; mInstitute of Human Genetics, Galilee Medical Center, 22100 Nahariya, Israel; nThe Azrieli Faculty of Medicine, Bar Ilan University, 13100 Safed, Israel; oDepartment of Genetic and Metabolic Diseases, Hadassah Hebrew University Medical Center, 91120 Jerusalem, Israel; pMetabolic Unit, Technion Faculty of Medicine, Rambam Health Care Campus, 31096 Haifa, Israel; and qCenter of Precision Medicine, College of Medicine, National Taiwan University, 10002 Taipei, Taiwan Edited by Christopher K. -
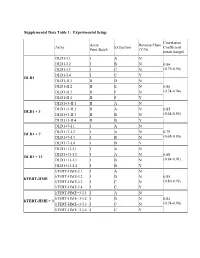
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom.