Databases Featuring Genomic Sequence Alignment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In Silico Prediction of High-Resolution Hi-C Interaction Matrices
ARTICLE https://doi.org/10.1038/s41467-019-13423-8 OPEN In silico prediction of high-resolution Hi-C interaction matrices Shilu Zhang1, Deborah Chasman 1, Sara Knaack1 & Sushmita Roy1,2* The three-dimensional (3D) organization of the genome plays an important role in gene regulation bringing distal sequence elements in 3D proximity to genes hundreds of kilobases away. Hi-C is a powerful genome-wide technique to study 3D genome organization. Owing to 1234567890():,; experimental costs, high resolution Hi-C datasets are limited to a few cell lines. Computa- tional prediction of Hi-C counts can offer a scalable and inexpensive approach to examine 3D genome organization across multiple cellular contexts. Here we present HiC-Reg, an approach to predict contact counts from one-dimensional regulatory signals. HiC-Reg pre- dictions identify topologically associating domains and significant interactions that are enri- ched for CCCTC-binding factor (CTCF) bidirectional motifs and interactions identified from complementary sources. CTCF and chromatin marks, especially repressive and elongation marks, are most important for HiC-Reg’s predictive performance. Taken together, HiC-Reg provides a powerful framework to generate high-resolution profiles of contact counts that can be used to study individual locus level interactions and higher-order organizational units of the genome. 1 Wisconsin Institute for Discovery, 330 North Orchard Street, Madison, WI 53715, USA. 2 Department of Biostatistics and Medical Informatics, University of Wisconsin-Madison, Madison, WI 53715, USA. *email: [email protected] NATURE COMMUNICATIONS | (2019) 10:5449 | https://doi.org/10.1038/s41467-019-13423-8 | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | https://doi.org/10.1038/s41467-019-13423-8 he three-dimensional (3D) organization of the genome has Results Temerged as an important component of the gene regulation HiC-Reg for predicting contact count using Random Forests. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

Investigation of the Underlying Hub Genes and Molexular Pathogensis in Gastric Cancer by Integrated Bioinformatic Analyses
bioRxiv preprint doi: https://doi.org/10.1101/2020.12.20.423656; this version posted December 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Investigation of the underlying hub genes and molexular pathogensis in gastric cancer by integrated bioinformatic analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2020.12.20.423656; this version posted December 22, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract The high mortality rate of gastric cancer (GC) is in part due to the absence of initial disclosure of its biomarkers. The recognition of important genes associated in GC is therefore recommended to advance clinical prognosis, diagnosis and and treatment outcomes. The current investigation used the microarray dataset GSE113255 RNA seq data from the Gene Expression Omnibus database to diagnose differentially expressed genes (DEGs). Pathway and gene ontology enrichment analyses were performed, and a proteinprotein interaction network, modules, target genes - miRNA regulatory network and target genes - TF regulatory network were constructed and analyzed. Finally, validation of hub genes was performed. The 1008 DEGs identified consisted of 505 up regulated genes and 503 down regulated genes. -

Identification of Potential Key Genes and Pathway Linked with Sporadic Creutzfeldt-Jakob Disease Based on Integrated Bioinformatics Analyses
medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Identification of potential key genes and pathway linked with sporadic Creutzfeldt-Jakob disease based on integrated bioinformatics analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 , Iranna Kotturshetti 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. 3. Department of Ayurveda, Rajiv Gandhi Education Society`s Ayurvedic Medical College, Ron, Karnataka 562209, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Abstract Sporadic Creutzfeldt-Jakob disease (sCJD) is neurodegenerative disease also called prion disease linked with poor prognosis. The aim of the current study was to illuminate the underlying molecular mechanisms of sCJD. The mRNA microarray dataset GSE124571 was downloaded from the Gene Expression Omnibus database. Differentially expressed genes (DEGs) were screened. -

Hippo and Sonic Hedgehog Signalling Pathway Modulation of Human Urothelial Tissue Homeostasis
Hippo and Sonic Hedgehog signalling pathway modulation of human urothelial tissue homeostasis Thomas Crighton PhD University of York Department of Biology November 2020 Abstract The urinary tract is lined by a barrier-forming, mitotically-quiescent urothelium, which retains the ability to regenerate following injury. Regulation of tissue homeostasis by Hippo and Sonic Hedgehog signalling has previously been implicated in various mammalian epithelia, but limited evidence exists as to their role in adult human urothelial physiology. Focussing on the Hippo pathway, the aims of this thesis were to characterise expression of said pathways in urothelium, determine what role the pathways have in regulating urothelial phenotype, and investigate whether the pathways are implicated in muscle-invasive bladder cancer (MIBC). These aims were assessed using a cell culture paradigm of Normal Human Urothelial (NHU) cells that can be manipulated in vitro to represent different differentiated phenotypes, alongside MIBC cell lines and The Cancer Genome Atlas resource. Transcriptomic analysis of NHU cells identified a significant induction of VGLL1, a poorly understood regulator of Hippo signalling, in differentiated cells. Activation of upstream transcription factors PPARγ and GATA3 and/or blockade of active EGFR/RAS/RAF/MEK/ERK signalling were identified as mechanisms which induce VGLL1 expression in NHU cells. Ectopic overexpression of VGLL1 in undifferentiated NHU cells and MIBC cell line T24 resulted in significantly reduced proliferation. Conversely, knockdown of VGLL1 in differentiated NHU cells significantly reduced barrier tightness in an unwounded state, while inhibiting regeneration and increasing cell cycle activation in scratch-wounded cultures. A signalling pathway previously observed to be inhibited by VGLL1 function, YAP/TAZ, was unaffected by VGLL1 manipulation. -

ARHGDIG / RHOGDI-3 Antibody (C-Terminus) Goat Polyclonal Antibody Catalog # ALS15383
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 ARHGDIG / RHOGDI-3 Antibody (C-Terminus) Goat Polyclonal Antibody Catalog # ALS15383 Specification ARHGDIG / RHOGDI-3 Antibody (C-Terminus) - Product Information Application WB, IHC Primary Accession Q99819 Reactivity Human, Monkey, Dog Host Goat Clonality Polyclonal Calculated MW 25kDa KDa ARHGDIG / RHOGDI-3 Antibody (C-Terminus) - Additional Information Gene ID 398 ARHGDIG antibody (0.5 ug/ml) staining of HeLa lysate (35 ug protein/ml in RIPA buffer). Other Names Rho GDP-dissociation inhibitor 3, Rho GDI 3, Rho-GDI gamma, ARHGDIG Target/Specificity Human ARHGDIG. Reconstitution & Storage Store at -20°C. Minimize freezing and thawing. Precautions ARHGDIG / RHOGDI-3 Antibody (C-Terminus) is for research use only and not for use in diagnostic or therapeutic procedures. Anti-ARHGDIG / RHOGDI-3 antibody IHC of human brain, cortex. ARHGDIG / RHOGDI-3 Antibody (C-Terminus) - Protein Information ARHGDIG / RHOGDI-3 Antibody (C-Terminus) - Background Name ARHGDIG Inhibits GDP/GTP exchange reaction of RhoB. Function Interacts specifically with the GDP- and Inhibits GDP/GTP exchange reaction of GTP-bound forms of post- translationally RhoB. Interacts specifically with the GDP- processed Rhob and Rhog proteins, both of and GTP-bound forms of post-translationally which show a growth-regulated expression in processed Rhob and Rhog proteins, both of mammalian cells. Stimulates the release of the which show a growth-regulated expression GDP-bound but not the GTP-bound RhoB in mammalian cells. Stimulates the release protein. Also inhibits the GDP/GTP exchange of of the GDP-bound but not the GTP-bound RhoB but shows less ability to inhibit the Page 1/2 10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 RhoB protein. -
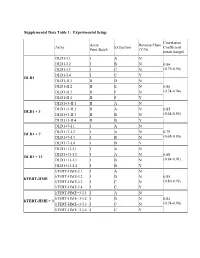
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

The Disruption Ofcelf6, a Gene Identified by Translational Profiling
2732 • The Journal of Neuroscience, February 13, 2013 • 33(7):2732–2753 Neurobiology of Disease The Disruption of Celf6, a Gene Identified by Translational Profiling of Serotonergic Neurons, Results in Autism-Related Behaviors Joseph D. Dougherty,1,2 Susan E. Maloney,1,2 David F. Wozniak,2 Michael A. Rieger,1,2 Lisa Sonnenblick,3,4,5 Giovanni Coppola,4 Nathaniel G. Mahieu,1 Juliet Zhang,6 Jinlu Cai,8 Gary J. Patti,1 Brett S. Abrahams,8 Daniel H. Geschwind,3,4,5 and Nathaniel Heintz6,7 Departments of 1Genetics and 2Psychiatry, Washington University School of Medicine, St. Louis, Missouri 63110, 3UCLA Center for Autism Research and Treatment, Semel Institute for Neuroscience and Behavior, 4Program in Neurogenetics, Department of Neurology, and 5Department of Human Genetics, David Geffen School of Medicine at UCLA, Los Angeles, California 90095, 6Laboratory of Molecular Biology, Howard Hughes Medical Institute, and 7The GENSAT Project, Rockefeller University, New York, New York 10065, and 8Departments of Genetics and Neuroscience, Albert Einstein College of Medicine, New York, New York 10461 The immense molecular diversity of neurons challenges our ability to understand the genetic and cellular etiology of neuropsychiatric disorders. Leveraging knowledge from neurobiology may help parse the genetic complexity: identifying genes important for a circuit that mediates a particular symptom of a disease may help identify polymorphisms that contribute to risk for the disease as a whole. The serotonergic system has long been suspected in disorders that have symptoms of repetitive behaviors and resistance to change, including autism. We generated a bacTRAP mouse line to permit translational profiling of serotonergic neurons. -

Mir-34/449 Control Apical Actin Network Formation During Multiciliogenesis Through Small Gtpase Pathways
ARTICLE Received 7 Jul 2015 | Accepted 17 Aug 2015 | Published 18 Sep 2015 DOI: 10.1038/ncomms9386 OPEN miR-34/449 control apical actin network formation during multiciliogenesis through small GTPase pathways Benoıˆt Chevalier1,2,*, Anna Adamiok3,*, Olivier Mercey1,2,*, Diego R. Revinski3, Laure-Emmanuelle Zaragosi1,2, Andrea Pasini3, Laurent Kodjabachian3, Pascal Barbry1,2 & Brice Marcet1,2 Vertebrate multiciliated cells (MCCs) contribute to fluid propulsion in several biological processes. We previously showed that microRNAs of the miR-34/449 family trigger MCC differentiation by repressing cell cycle genes and the Notch pathway. Here, using human and Xenopus MCCs, we show that beyond this initial step, miR-34/449 later promote the assembly of an apical actin network, required for proper basal bodies anchoring. Identification of miR-34/449 targets related to small GTPase pathways led us to characterize R-Ras as a key regulator of this process. Protection of RRAS messenger RNA against miR-34/449 binding impairs actin cap formation and multiciliogenesis, despite a still active RhoA. We propose that miR-34/449 also promote relocalization of the actin binding protein Filamin-A, a known RRAS interactor, near basal bodies in MCCs. Our study illustrates the intricate role played by miR-34/449 in coordinating several steps of a complex differentiation programme by regulating distinct signalling pathways. 1 CNRS, Institut de Pharmacologie Mole´culaire et Cellulaire (IPMC), UMR-7275, 660 route des Lucioles, 06560 Sophia-Antipolis, France. 2 University of Nice-Sophia-Antipolis (UNS), Institut de Pharmacologie Mole´culaire et Cellulaire, 660 route des Lucioles, Valbonne, 06560 Sophia-Antipolis, France. -

2014-Platform-Abstracts.Pdf
American Society of Human Genetics 64th Annual Meeting October 18–22, 2014 San Diego, CA PLATFORM ABSTRACTS Abstract Abstract Numbers Numbers Saturday 41 Statistical Methods for Population 5:30pm–6:50pm: Session 2: Plenary Abstracts Based Studies Room 20A #198–#205 Featured Presentation I (4 abstracts) Hall B1 #1–#4 42 Genome Variation and its Impact on Autism and Brain Development Room 20BC #206–#213 Sunday 43 ELSI Issues in Genetics Room 20D #214–#221 1:30pm–3:30pm: Concurrent Platform Session A (12–21): 44 Prenatal, Perinatal, and Reproductive 12 Patterns and Determinants of Genetic Genetics Room 28 #222–#229 Variation: Recombination, Mutation, 45 Advances in Defining the Molecular and Selection Hall B1 Mechanisms of Mendelian Disorders Room 29 #230–#237 #5-#12 13 Genomic Studies of Autism Room 6AB #13–#20 46 Epigenomics of Normal Populations 14 Statistical Methods for Pedigree- and Disease States Room 30 #238–#245 Based Studies Room 6CF #21–#28 15 Prostate Cancer: Expression Tuesday Informing Risk Room 6DE #29–#36 8:00pm–8:25am: 16 Variant Calling: What Makes the 47 Plenary Abstracts Featured Difference? Room 20A #37–#44 Presentation III Hall BI #246 17 New Genes, Incidental Findings and 10:30am–12:30pm:Concurrent Platform Session D (49 – 58): Unexpected Observations Revealed 49 Detailing the Parts List Using by Exome Sequencing Room 20BC #45–#52 Genomic Studies Hall B1 #247–#254 18 Type 2 Diabetes Genetics Room 20D #53–#60 50 Statistical Methods for Multigene, 19 Genomic Methods in Clinical Practice Room 28 #61–#68 Gene Interaction -

Mesenchymal Stem Cells from Multiple Myeloma Patients Display Distinct Genomic Profile As Compared with Those from Normal Donors
Leukemia (2009) 23, 1515–1527 & 2009 Macmillan Publishers Limited All rights reserved 0887-6924/09 $32.00 www.nature.com/leu ORIGINAL ARTICLE Mesenchymal stem cells from multiple myeloma patients display distinct genomic profile as compared with those from normal donors M Garayoa1,5,6, JL Garcia1,2,6, C Santamaria3, A Garcia-Gomez1, JF Blanco4, A Pandiella1, JM Herna´ndez3, FM Sanchez-Guijo3,5, M-C del Can˜izo3,5, NC Gutie´rrez3, and JF San Miguel1,3,5 1Centro de Investigacio´n del Ca´ncer, Instituto de Biologı´a Molecular y Celular del Ca´ncer, Universidad de Salamanca-CSIC, Salamanca, Spain; 2Unidad de Investigacio´n, Instituto de Estudio de Ciencias de la Salud de Castilla y Leo´n (IECSCYL) – Hospital Universitario de Salamanca. Salamanca, Spain; 3Servicio de Hematologı´a. Hospital Universitario de Salamanca. Salamanca, Spain; 4Servicio de Traumatologı´a. Hospital Universitario de Salamanca. Salamanca, Spain and 5Centro en Red de Medicina Regenerativa y Terapia Celular de Castilla y Leo´n, Salamanca, Spain It is an open question whether in multiple myeloma (MM) bone directly by interactions of myeloma cells with BM stromal cells marrow stromal cells contain genomic alterations, which may and extracellular matrix proteins or indirectly by secretion of contribute to the pathogenesis of the disease. We conducted an array-based comparative genomic hybridization (array-CGH) soluble cytokine and growth factors by myeloma cells and/or analysis to compare the extent of unbalanced genomic altera- stromal cells. These interactions and growth factor circuits tions in mesenchymal stem cells from 21 myeloma patients ultimately lead to the activation of pleiotrophic signalling (MM-MSCs) and 12 normal donors (ND-MSCs) after in vitro cascades, which promote proliferation, cell survival, anti- culture expansion. -

ATR16 Syndrome: Mechanisms Linking Monosomy to Phenotype 2 3 4 Christian Babbs,*1 Jill Brown,1 Sharon W
bioRxiv preprint doi: https://doi.org/10.1101/768895; this version posted October 7, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 ATR16 Syndrome: Mechanisms Linking Monosomy to Phenotype 2 3 4 Christian Babbs,*1 Jill Brown,1 Sharon W. Horsley,1 Joanne Slater,1 Evie Maifoshie,1 5 Shiwangini Kumar,2 Paul Ooijevaar,3 Marjolein Kriek,3 Amanda Dixon-McIver,2 6 Cornelis L. Harteveld,3 Joanne Traeger-Synodinos,4 Douglas Higgs1 and Veronica 7 Buckle*1 8 9 10 11 12 1. MRC Molecular Haematology Unit, MRC Weatherall Institute of Molecular 13 Medicine, University of Oxford, Oxford, UK. 14 15 2. IGENZ Ltd, Auckland, New Zealand. 16 17 3. Department of Clinical Genetics, Leiden University Medical Center, Leiden, The 18 Netherlands. 19 20 4. Department of Medical Genetics, National and Kapodistrian University of Athens, 21 Greece. 22 23 24 25 *Authors for correspondence 26 [email protected] 27 [email protected] 28 29 1 bioRxiv preprint doi: https://doi.org/10.1101/768895; this version posted October 7, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Abstract 2 3 Background: Sporadic deletions removing 100s-1000s kb of DNA, and 4 variable numbers of poorly characterised genes, are often found in patients 5 with a wide range of developmental abnormalities. In such cases, 6 understanding the contribution of the deletion to an individual’s clinical 7 phenotype is challenging.