Devanagari Range: 0900–097F
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

Introduction
INTRODUCTION ’ P”(Bha.t.tikāvya) is one of the boldest “B experiments in classical literature. In the formal genre of “great poem” (mahākāvya) it incorprates two of the most powerful Sanskrit traditions, the “Ramáyana” and Pánini’s grammar, and several other minor themes. In this one rich mix of science and art, Bhatti created both a po- etic retelling of the adventures of Rama and a compendium of examples of grammar, metrics, the Prakrit language and rhetoric. As literature, his composition stands comparison with the best of Sanskrit poetry, in particular cantos , and . “Bhatti’s Poem” provides a comprehensive exem- plification of Sanskrit grammar in use and a good introduc- tion to the science (śāstra) of poetics or rhetoric (alamk. āra, lit. ornament). It also gives a taster of the Prakrit language (a major component in every Sanskrit drama) in an easily ac- cessible form. Finally it tells the compelling story of Prince Rama in simple elegant Sanskrit: this is the “Ramáyana” faithfully retold. e learned Indian curriculum in late classical times had at its heart a system of grammatical study and linguistic analysis. e core text for this study was the notoriously difficult “Eight Books” (A.s.tādhyāyī) of Pánini, the sine qua non of learning composed in the fourth century , and arguably the most remarkable and indeed foundational text in the history of linguistics. Not only is the “Eight Books” a description of a language unmatched in totality for any language until the nineteenth century, but it is also pre- sented in the most compact form possible through the use xix of an elaborate and sophisticated metalanguage, again un- known anywhere else in linguistics before modern times. -

GEO ROO DIST BUC PRO Prep ATE 111 Cha Dec Expi OTECHNICA OSEVELT ST TRICT CKEYE, ARI OJECT # 15 Pared By
GEOTECHNICAL EXPLORARATION REPORT ROOSEVELT STREET IMPROVEMENT DISTRICT BUCKEYE, ARIZONA PROJECT # 150004 Prepared by: ATEK Engineering Consultants, LLC 111 South Weber Drive, Suite 1 Chandler, Arizona 85226 Exp ires 9/30/2018 December 14, 2015 December 14, 2015 ATEK Project #150004 RITOCH-POWELL & Associates 5727 North 7th Street #120 Phoenix, AZ 85014 Attention: Mr. Keith L. Drunasky, P.E. RE: GEOTECHNICAL EXPLORATION REPORT Roosevelt Street Improvement District Buckeye, Arizona Dear Mr. Drunasky: ATEK Engineering Consultants, LLC is pleased to present the attached Geotechnical Exploration Report for the Roosevelt Street Improvement Disstrict located in Buckeye, Arizona. The purpose of our study was to explore and evaluate the subsurface conditions at the proposed site to develop geotechnical engineering recommendations for project design and construction. Based on our findings, the site is considered suittable for the proposed construction, provided geotechnical recommendations presented in thhe attached report are followed. Specific recommendations regarding the geotechnical aspects of the project design and construction are presented in the attached report. The recommendations contained within this report are depeendent on the provisions provided in the Limitations and Recommended Additional Services sections of this report. We appreciate the opportunity of providing our services for this project. If you have questions regarding this report or if we may be of further assistance, please contact the undersigned. Sincerely, ATEK Engineering Consultants, LLC Expires 9/30/2018 James P Floyd, P.E. Armando Ortega, P.E. Project Manager Principal Geotechnical Engineer Expires 9/30/2017 111 SOUTH WEBER DRIVE, SUITE 1 WWW.ATEKEC.COM P (480) 659-8065 CHANDLER, AZ 85226 F (480) 656-9658 TABLE OF CONTENTS 1. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
![Positional Notation Or Trigonometry [2, 13]](https://docslib.b-cdn.net/cover/6799/positional-notation-or-trigonometry-2-13-106799.webp)
Positional Notation Or Trigonometry [2, 13]
The Greatest Mathematical Discovery? David H. Bailey∗ Jonathan M. Borweiny April 24, 2011 1 Introduction Question: What mathematical discovery more than 1500 years ago: • Is one of the greatest, if not the greatest, single discovery in the field of mathematics? • Involved three subtle ideas that eluded the greatest minds of antiquity, even geniuses such as Archimedes? • Was fiercely resisted in Europe for hundreds of years after its discovery? • Even today, in historical treatments of mathematics, is often dismissed with scant mention, or else is ascribed to the wrong source? Answer: Our modern system of positional decimal notation with zero, to- gether with the basic arithmetic computational schemes, which were discov- ered in India prior to 500 CE. ∗Bailey: Lawrence Berkeley National Laboratory, Berkeley, CA 94720, USA. Email: [email protected]. This work was supported by the Director, Office of Computational and Technology Research, Division of Mathematical, Information, and Computational Sciences of the U.S. Department of Energy, under contract number DE-AC02-05CH11231. yCentre for Computer Assisted Research Mathematics and its Applications (CARMA), University of Newcastle, Callaghan, NSW 2308, Australia. Email: [email protected]. 1 2 Why? As the 19th century mathematician Pierre-Simon Laplace explained: It is India that gave us the ingenious method of expressing all numbers by means of ten symbols, each symbol receiving a value of position as well as an absolute value; a profound and important idea which appears so simple to us now that we ignore its true merit. But its very sim- plicity and the great ease which it has lent to all computations put our arithmetic in the first rank of useful inventions; and we shall appre- ciate the grandeur of this achievement the more when we remember that it escaped the genius of Archimedes and Apollonius, two of the greatest men produced by antiquity. -

The Festvox Indic Frontend for Grapheme-To-Phoneme Conversion
The Festvox Indic Frontend for Grapheme-to-Phoneme Conversion Alok Parlikar, Sunayana Sitaram, Andrew Wilkinson and Alan W Black Carnegie Mellon University Pittsburgh, USA aup, ssitaram, aewilkin, [email protected] Abstract Text-to-Speech (TTS) systems convert text into phonetic pronunciations which are then processed by Acoustic Models. TTS frontends typically include text processing, lexical lookup and Grapheme-to-Phoneme (g2p) conversion stages. This paper describes the design and implementation of the Indic frontend, which provides explicit support for many major Indian languages, along with a unified framework with easy extensibility for other Indian languages. The Indic frontend handles many phenomena common to Indian languages such as schwa deletion, contextual nasalization, and voicing. It also handles multi-script synthesis between various Indian-language scripts and English. We describe experiments comparing the quality of TTS systems built using the Indic frontend to grapheme-based systems. While this frontend was designed keeping TTS in mind, it can also be used as a general g2p system for Automatic Speech Recognition. Keywords: speech synthesis, Indian language resources, pronunciation 1. Introduction in models of the spectrum and the prosody. Another prob- lem with this approach is that since each grapheme maps Intelligible and natural-sounding Text-to-Speech to a single “phoneme” in all contexts, this technique does (TTS) systems exist for a number of languages of the world not work well in the case of languages that have pronun- today. However, for low-resource, high-population lan- ciation ambiguities. We refer to this technique as “Raw guages, such as languages of the Indian subcontinent, there Graphemes.” are very few high-quality TTS systems available. -
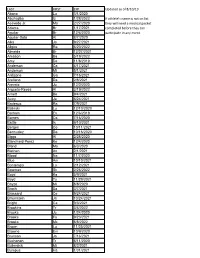
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

2020 Language Need and Interpreter Use Study, As Required Under Chair, Executive and Planning Committee Government Code Section 68563 HON
JUDICIAL COUNCIL OF CALIFORNIA 455 Golden Gate Avenue May 15, 2020 San Francisco, CA 94102-3688 Tel 415-865-4200 TDD 415-865-4272 Fax 415-865-4205 www.courts.ca.gov Hon. Gavin Newsom Governor of California HON. TANI G. CANTIL- SAKAUYE State Capitol, First Floor Chief Justice of California Chair of the Judicial Council Sacramento, California 95814 HON. MARSHA G. SLOUGH Re: 2020 Language Need and Interpreter Use Study, as required under Chair, Executive and Planning Committee Government Code section 68563 HON. DAVID M. RUBIN Chair, Judicial Branch Budget Committee Chair, Litigation Management Committee Dear Governor Newsom: HON. MARLA O. ANDERSON Attached is the Judicial Council report required under Government Code Chair, Legislation Committee section 68563, which requires the Judicial Council to conduct a study HON. HARRY E. HULL, JR. every five years on language need and interpreter use in the California Chair, Rules Committee trial courts. HON. KYLE S. BRODIE Chair, Technology Committee The study was conducted by the Judicial Council’s Language Access Hon. Richard Bloom Services and covers the period from fiscal years 2014–15 through 2017–18. Hon. C. Todd Bottke Hon. Stacy Boulware Eurie Hon. Ming W. Chin If you have any questions related to this report, please contact Mr. Douglas Hon. Jonathan B. Conklin Hon. Samuel K. Feng Denton, Principal Manager, Language Access Services, at 415-865-7870 or Hon. Brad R. Hill Ms. Rachel W. Hill [email protected]. Hon. Harold W. Hopp Hon. Hannah-Beth Jackson Mr. Patrick M. Kelly Sincerely, Hon. Dalila C. Lyons Ms. Gretchen Nelson Mr. -

RELG 357D1 Sanskrit 2, Fall 2020 Syllabus
RELG 357D1: Sanskrit 2 Fall 2020 McGill University School of Religious Studies Tuesdays & Thursdays, 10:05 – 11:25 am Instructor: Hamsa Stainton Email: [email protected] Office hours: by appointment via phone or Zoom Note: Due to COVID-19, this course will be offered remotely via synchronous Zoom class meetings at the scheduled time. If students have any concerns about accessibility or equity please do not hesitate to contact me directly. Overview This is a Sanskrit reading course in which intermediate Sanskrit students will prepare translations of Sanskrit texts and present them in class. While the course will review Sanskrit grammar when necessary, it presumes students have already completed an introduction to Sanskrit grammar. Readings: All readings will be made available on myCourses. If you ever have any issues accessing the readings, or there are problems with a PDF, please let me know immediately. You may also wish to purchase or borrow a hard copy of Charles Lanman’s A Sanskrit Reader (1884) for ease of reference, but the ebook will be on myCourses. The exact reading on a given day will depend on how far we progressed in the previous class. For the first half of the course, we will be reading selections from the Lanman’s Sanskrit Reader, and in the second half of the course we will read from the Bhagavadgītā. Assessment and grading: Attendance: 20% Class participation based on prepared translations: 20% Test #1: 25% Test #2: 35% For attendance and class participation, students are expected to have prepared translations of the relevant Sanskrit text. -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language.