LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Implementation of Sanskrit Linguistics in Artificial Intelligence Programming
ISSN: 2456 - 3935 International Journal of Advances in Computer and Electronics Engineering Volume: 02 Issue: 02, February 2017, pp. 17 – 27 Implementation of Sanskrit Linguistics in Artificial Intelligence Programming Neetesh Vashishtha UG Scholar, Department of Computer Science Engineering, Jaipur Engineering College and Research Center, India Email: [email protected] Abstract: This research paper is directed towards examining the extent to which the Sanskrit language can be implemented in programming, principally in the domain of Artificial Intelligence. This paper can be divided into three major sections. The first section explains the significance of Sanskrit over other languages. The second section explores that if it’s actually beneficial to program in Sanskrit rather than English. The third section includes coding of two identical AI programs, one made to interact in English and the other in Sanskrit. They are analyzed separately and then compared collectively to seek for the advantages the Sanskrit linguistics offer in Artificial Intelligence programming. We then conclude that Sanskrit, when used for communicating with the AI machines, is remarkable with an astounding versatility and brilliant learning abilities for an AI. The Sanskrit being strict and bundled, results in a compact and unambiguous form of conversations with the AI programs. Keyword: Artificial Intelligence; Deep Learning; Java; Language linguistics; Machine Learning; Sanskrit 1. INTRODUCTION The primary objective of this paper is to present The number of possible incorrect sentences are- the possibility of adopting Sanskrit as a means of 5! – 1 = 120-1 communication with the artificial intelligence. The = 119 permutations paper also aims to extend this proposal with pro- gramming the AI in Sanskrit Linguistics. -

Edatlas: an Efficient Disambiguation Algorithm for Texting in Languages with Abugida Scripts
edATLAS: An Efficient Disambiguation Algorithm for Texting in Languages with Abugida Scripts Sourav Ghosh, Sourabh Vasant Gothe, Chandramouli Sanchi, Barath Raj Kandur Raja Samsung R&D Institute Bangalore, Karnataka, India 560037 Email: { sourav.ghosh, sourab.gothe, cm.sanchi, barathraj.kr }@samsung.com Abstract—Abugida refers to a phonogram writing system where each syllable is represented using a single consonant or typographic ligature, along with a default vowel or optional diacritic(s) to denote other vowels. However, texting in these languages has some unique challenges in spite of the advent of devices with soft keyboard supporting custom key layouts. The number of characters in these languages is large enough to require characters to be spread over multiple views in the layout. Having to switch between views many times to type a single word hinders the natural thought process. This prevents popular usage of native keyboard layouts. On the other hand, supporting romanized scripts (native words transcribed using Latin characters) with language model based suggestions is also set back by the lack of uniform romanization rules. (a) (b) To this end, we propose a disambiguation algorithm and showcase its usefulness in two novel mutually non-exclusive Fig. 1: Application of edATLAS in (a) ambiguous input for input methods for languages natively using the abugida writing abugida scripts, and (b) word variants for romanized scripts system: (a) disambiguation of ambiguous input for abugida scripts, and (b) disambiguation of word variants in romanized scripts. We benchmark these approaches using public datasets, and show an improvement in typing speed by 19:49%, 25:13%, who prefer transliteration layouts [4] by a very large margin, 14:89 and %, in Hindi, Bengali, and Thai, respectively, using as seen in Figure 2. -

Sanskrit As a Programming Language: Possibilities & Difficulties Vipin Mishra
IJISET - International Journal of Innovative Science, Engineering & Technology, Vol. 2 Issue 4, April 2015. www.ijiset.com ISSN 2348 – 7968 Sanskrit as a Programming Language: Possibilities & Difficulties Vipin Mishra Abstract In the past twenty years, much time, effort, and money has been expended on designing an unambiguous representation of natural languages to make them accessible to computer processing. These efforts have centered on creating schemata designed to parallel logical relations with relations expressed by the syntax and semantics of natural languages, which are clearly cumbersome and ambiguous in their function as vehicles for the transmission of logical data. Understandably, there is a widespread belief that natural languages are unsuitable for the transmission of many ideas that artificial languages can render with great precision and mathematical rigor. But this dichotomy, which has served as a premise underlying much work in the areas of linguistics and artificial intelligence, is a false one. There is at least one language, Sanskrit, which for the duration of almost 1,000 years was a living spoken language with a considerable literature of its own. Besides works of literary value, there was a long philosophical and grammatical tradition that has continued to exist with undiminished vigor until the present century. Among the accomplishments of the grammarians can be reckoned a method for paraphrasing Sanskrit in a manner that is identical not only in essence but in form with current work in Artificial Intelligence. This article demonstrates that a natural language can serve as an artificial language also, and that much work in AI has been reinventing a wheel millennia old. -

Dual Script E2E Framework for Multilingual and Code-Switching ASR
Dual Script E2E Framework for Multilingual and Code-Switching ASR Mari Ganesh Kumar, Jom Kuriakose, Anand Thyagachandran, Arun Kumar A*, Ashish Seth*, Lodagala V S V Durga Prasad*, Saish Jaiswal*, Anusha Prakash, and Hema A Murthy Indian Institute of Technology Madras [email protected] (MGK), [email protected] (JK), [email protected] (AP), [email protected] (HAM) Abstract have different written scripts, they share a common phonetic base. Inspired by this, a common label set for 13 Indian lan- India is home to multiple languages, and training automatic guages was developed for TTS synthesis [6]. In [7], a rule-based speech recognition (ASR) systems is challenging. Over time, unified parser for 13 Indian languages was proposed to convert each language has adopted words from other languages, such grapheme-based Indian language text to phoneme-based CLS. as English, leading to code-mixing. Most Indian languages also CLS has shown to be successful for TTS systems developed us- have their own unique scripts, which poses a major limitation in ing both hidden Markov model (HMM) based approaches [6], training multilingual and code-switching ASR systems. and recent end-to-end frameworks [4, 5]. For training multilin- Inspired by results in text-to-speech synthesis, in this paper, gual ASR systems, recent studies use transliterated text pooled we use an in-house rule-based phoneme-level common label set across various languages [8, 9]. In the context of multilingual (CLS) representation to train multilingual and code-switching ASR systems for Indian languages, [10] used a simple character ASR for Indian languages. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -
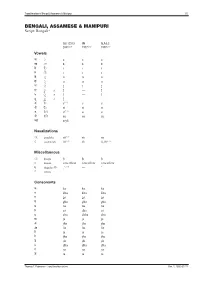
Transliteration of <Script Name>
Transliteration of Bengali, Assamese & Manipuri 1/5 BENGALI, ASSAMESE & MANIPURI Script: Bengali* ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) Vowels অ ◌ a a a আ ◌া ā ā ā ই ি◌ i i i ঈ ◌ী ī ī ī উ ◌ু u u u ঊ ◌ূ ū ū ū ঋ ◌ৃ r̥ ṛ r̥ ৠ ◌ৄ r̥̄ — r̥̄ ঌ ◌ৢ l̥ — l̥ ৡ ◌ৣ A l̥ ̄ — — এ ে◌ e(1.1) e e ঐ ৈ◌ ai ai ai ও ে◌া o(1.1) o o ঔ ে◌ৗ au au au অ�া a:yā — — Nasalizations ◌ং anunāsika ṁ(1.2) ṁ ṃ ◌ঁ candrabindu m̐ (1.2) m̐ n̐, m̐ (3.1) Miscellaneous ◌ঃ bisarga ḥ ḥ ḥ ◌্ hasanta vowelless vowelless vowelless (1.3) ঽ abagraha Ⓑ :’ — ’ ৺ isshara — — — Consonants ক ka ka ka খ kha kha kha গ ga ga ga ঘ gha gha gha ঙ ṅa ṅa ṅa চ ca cha ca ছ cha chha cha জ ja ja ja ঝ jha jha jha ঞ ña ña ña ট ṭa ṭa ṭa ঠ ṭha ṭha ṭha ড ḍa ḍa ḍa ঢ ḍha ḍha ḍha ণ ṇa ṇa ṇa ত ta ta ta Thomas T. Pedersen – transliteration.eki.ee Rev. 2, 2005-07-21 Transliteration of Bengali, Assamese & Manipuri 2/5 ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) থ tha tha tha দ da da da ধ dha dha dha ন na na na প pa pa pa ফ pha pha pha ব ba ba ba(3.2) ভ bha bha bha ম ma ma ma য ya ja̱ ya র ⒷⓂ ra ra ra ৰ Ⓐ ra ra ra ল la la la ৱ ⒶⓂ va va wa শ śa sha śa ষ ṣa ṣha sha স sa sa sa হ ha ha ha ড় ṛa ṙa ṛa ঢ় ṛha ṙha ṛha য় ẏa ya ẏa জ় za — — ব় wa — — ক় Ⓑ qa — — খ় Ⓑ k̲h̲a — — গ় Ⓑ ġa — — ফ় Ⓑ fa — — Adscript consonants ◌� ya-phala -ya(1.4) -ya ẏa ৎ khanda-ta -t -t ṯa ◌� repha r- r- r- ◌� baphala -b -b -b ◌� raphala -r -r -r Vowel ligatures (conjuncts)C � gu � ru � rū � Ⓐ ru � rū � śu � hr̥ � hu � tru � trū � ntu � lgu Thomas T.