Dual Script E2E Framework for Multilingual and Code-Switching ASR
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -
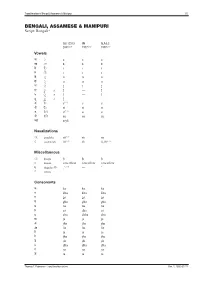
Transliteration of <Script Name>
Transliteration of Bengali, Assamese & Manipuri 1/5 BENGALI, ASSAMESE & MANIPURI Script: Bengali* ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) Vowels অ ◌ a a a আ ◌া ā ā ā ই ি◌ i i i ঈ ◌ী ī ī ī উ ◌ু u u u ঊ ◌ূ ū ū ū ঋ ◌ৃ r̥ ṛ r̥ ৠ ◌ৄ r̥̄ — r̥̄ ঌ ◌ৢ l̥ — l̥ ৡ ◌ৣ A l̥ ̄ — — এ ে◌ e(1.1) e e ঐ ৈ◌ ai ai ai ও ে◌া o(1.1) o o ঔ ে◌ৗ au au au অ�া a:yā — — Nasalizations ◌ং anunāsika ṁ(1.2) ṁ ṃ ◌ঁ candrabindu m̐ (1.2) m̐ n̐, m̐ (3.1) Miscellaneous ◌ঃ bisarga ḥ ḥ ḥ ◌্ hasanta vowelless vowelless vowelless (1.3) ঽ abagraha Ⓑ :’ — ’ ৺ isshara — — — Consonants ক ka ka ka খ kha kha kha গ ga ga ga ঘ gha gha gha ঙ ṅa ṅa ṅa চ ca cha ca ছ cha chha cha জ ja ja ja ঝ jha jha jha ঞ ña ña ña ট ṭa ṭa ṭa ঠ ṭha ṭha ṭha ড ḍa ḍa ḍa ঢ ḍha ḍha ḍha ণ ṇa ṇa ṇa ত ta ta ta Thomas T. Pedersen – transliteration.eki.ee Rev. 2, 2005-07-21 Transliteration of Bengali, Assamese & Manipuri 2/5 ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) থ tha tha tha দ da da da ধ dha dha dha ন na na na প pa pa pa ফ pha pha pha ব ba ba ba(3.2) ভ bha bha bha ম ma ma ma য ya ja̱ ya র ⒷⓂ ra ra ra ৰ Ⓐ ra ra ra ল la la la ৱ ⒶⓂ va va wa শ śa sha śa ষ ṣa ṣha sha স sa sa sa হ ha ha ha ড় ṛa ṙa ṛa ঢ় ṛha ṙha ṛha য় ẏa ya ẏa জ় za — — ব় wa — — ক় Ⓑ qa — — খ় Ⓑ k̲h̲a — — গ় Ⓑ ġa — — ফ় Ⓑ fa — — Adscript consonants ◌� ya-phala -ya(1.4) -ya ẏa ৎ khanda-ta -t -t ṯa ◌� repha r- r- r- ◌� baphala -b -b -b ◌� raphala -r -r -r Vowel ligatures (conjuncts)C � gu � ru � rū � Ⓐ ru � rū � śu � hr̥ � hu � tru � trū � ntu � lgu Thomas T. -

Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati
Component-I (A) – Personal details: Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. & Dr. K. Muniratnam Director i/c, Epigraphy, ASI, Mysore Dr. Sayantani Pal Dept. of AIHC, University of Calcutta. Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. Component-I (B) – Description of module: Subject Name Indian Culture Paper Name Indian Epigraphy Module Name/Title Kharosthi Script Module Id IC / IEP / 15 Pre requisites Kharosthi Script – Characteristics – Origin – Objectives Different Theories – Distribution and its End Keywords E-text (Quadrant-I) : 1. Introduction Kharosthi was one of the major scripts of the Indian subcontinent in the early period. In the list of 64 scripts occurring in the Lalitavistara (3rd century CE), a text in Buddhist Hybrid Sanskrit, Kharosthi comes second after Brahmi. Thus both of them were considered to be two major scripts of the Indian subcontinent. Both Kharosthi and Brahmi are first encountered in the edicts of Asoka in the 3rd century BCE. 2. Discovery of the script and its Decipherment The script was first discovered on one side of a large number of coins bearing Greek legends on the other side from the north western part of the Indian subcontinent in the first quarter of the 19th century. Later in 1830 to 1834 two full inscriptions of the time of Kanishka bearing the same script were found at Manikiyala in Pakistan. After this discovery James Prinsep named the script as ‘Bactrian Pehelevi’ since it occurred on a number of so called ‘Bactrian’ coins. To James Prinsep the characters first looked similar to Pahlavi (Semitic) characters. -

The Formal Kharoṣṭhī Script from the Northern Tarim Basin in Northwest
Acta Orientalia Hung. 73 (2020) 3, 335–373 DOI: 10.1556/062.2020.00015 Th e Formal Kharoṣṭhī script from the Northern Tarim Basin in Northwest China may write an Iranian language1 FEDERICO DRAGONI, NIELS SCHOUBBEN and MICHAËL PEYROT* L eiden University Centre for Linguistics, Universiteit Leiden, Postbus 9515, 2300 RA Leiden, Th e Netherlands E-mail: [email protected]; [email protected]; *Corr esponding Author: [email protected] Received: February 13, 2020 •Accepted: May 25, 2020 © 2020 The Authors ABSTRACT Building on collaborative work with Stefan Baums, Ching Chao-jung, Hannes Fellner and Georges-Jean Pinault during a workshop at Leiden University in September 2019, tentative readings are presented from a manuscript folio (T II T 48) from the Northern Tarim Basin in Northwest China written in the thus far undeciphered Formal Kharoṣṭhī script. Unlike earlier scholarly proposals, the language of this folio can- not be Tocharian, nor can it be Sanskrit or Middle Indic (Gāndhārī). Instead, it is proposed that the folio is written in an Iranian language of the Khotanese-Tumšuqese type. Several readings are proposed, but a full transcription, let alone a full translation, is not possible at this point, and the results must consequently remain provisional. KEYWORDS Kharoṣṭhī, Formal Kharoṣṭhī, Khotanese, Tumšuqese, Iranian, Tarim Basin 1 We are grateful to Stefan Baums, Chams Bernard, Ching Chao-jung, Doug Hitch, Georges-Jean Pinault and Nicholas Sims-Williams for very helpful discussions and comments on an earlier draft. We also thank the two peer-reviewers of the manuscript. One of them, Richard Salomon, did not wish to remain anonymous, and espe- cially his observation on the possible relevance of Khotan Kharoṣṭhī has proved very useful. -

The Spread of Hindu-Arabic Numerals in the European Tradition of Practical Mathematics (13 Th -16 Th Centuries)
Figuring Out: The Spread of Hindu-Arabic Numerals in the European Tradition of Practical Mathematics (13 th -16 th centuries) Raffaele Danna PhD Candidate Faculty of History, University of Cambridge [email protected] CWPESH no. 35 1 Abstract: The paper contributes to the literature focusing on the role of ideas, practices and human capital in pre-modern European economic development. It argues that studying the spread of Hindu- Arabic numerals among European practitioners allows to open up a perspective on a progressive transmission of useful knowledge from the commercial revolution to the early modern period. The analysis is based on an original database recording detailed information on over 1200 texts, both manuscript and printed. This database provides the most detailed reconstruction available of the European tradition of practical arithmetic from the late 13 th to the end of the 16 th century. It can be argued that this is the tradition which drove the adoption of Hindu-Arabic numerals in Europe. The dataset is analysed with statistical and spatial tools. Since the spread of these texts is grounded on inland patterns, the evidence suggests that a continuous transmission of useful knowledge may have played a role during the shift of the core of European trade from the Mediterranean to the Atlantic. 2 Introduction Given their almost universal diffusion, Hindu-Arabic numerals can easily be taken for granted. Nevertheless, for a long stretch of European history numbers have been represented using Roman numerals, as the positional numeral system reached western Europe at a relatively late stage. This paper provides new evidence to reconstruct the transition of European practitioners from Roman to Hindu-Arabic numerals. -

General Historical and Analytical / Writing Systems: Recent Script
9 Writing systems Edited by Elena Bashir 9,1. Introduction By Elena Bashir The relations between spoken language and the visual symbols (graphemes) used to represent it are complex. Orthographies can be thought of as situated on a con- tinuum from “deep” — systems in which there is not a one-to-one correspondence between the sounds of the language and its graphemes — to “shallow” — systems in which the relationship between sounds and graphemes is regular and trans- parent (see Roberts & Joyce 2012 for a recent discussion). In orthographies for Indo-Aryan and Iranian languages based on the Arabic script and writing system, the retention of historical spellings for words of Arabic or Persian origin increases the orthographic depth of these systems. Decisions on how to write a language always carry historical, cultural, and political meaning. Debates about orthography usually focus on such issues rather than on linguistic analysis; this can be seen in Pakistan, for example, in discussions regarding orthography for Kalasha, Wakhi, or Balti, and in Afghanistan regarding Wakhi or Pashai. Questions of orthography are intertwined with language ideology, language planning activities, and goals like literacy or standardization. Woolard 1998, Brandt 2014, and Sebba 2007 are valuable treatments of such issues. In Section 9.2, Stefan Baums discusses the historical development and general characteristics of the (non Perso-Arabic) writing systems used for South Asian languages, and his Section 9.3 deals with recent research on alphasyllabic writing systems, script-related literacy and language-learning studies, representation of South Asian languages in Unicode, and recent debates about the Indus Valley inscriptions. -

3 Writing Systems
Writing Systems 43 3 Writing Systems PETER T. DANIELS Chapters on writing systems are very rare in surveys of linguistics – Trager (1974) and Mountford (1990) are the only ones that come to mind. For a cen- tury or so – since the realization that unwritten languages are as legitimate a field of study, and perhaps a more important one, than the world’s handful of literary languages – writing systems were (rightly) seen as secondary to phonological systems and (wrongly) set aside as unworthy of study or at best irrelevant to spoken language. The one exception was I. J. Gelb’s attempt (1952, reissued with additions and corrections 1963) to create a theory of writ- ing informed by the linguistics of his time. Gelb said that what he wrote was meant to be the first word, not the last word, on the subject, but no successors appeared until after his death in 1985.1 Although there have been few lin- guistic explorations of writing, a number of encyclopedic compilations have appeared, concerned largely with the historical development and diffusion of writing,2 though various popularizations, both new and old, tend to be less than accurate (Daniels 2000). Daniels and Bright (1996; The World’s Writing Systems: hereafter WWS) includes theoretical and historical materials but is primarily descriptive, providing for most contemporary and some earlier scripts information (not previously gathered together) on how they represent (the sounds of) the languages they record. This chapter begins with a historical-descriptive survey of the world’s writ- ing systems, and elements of a theory of writing follow.