Bha††Oji D¥K∑Ita on Spho†A* (Published In: Journal of Indian Philosophy 33(1), 2005, 3-41)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction
INTRODUCTION ’ P”(Bha.t.tikāvya) is one of the boldest “B experiments in classical literature. In the formal genre of “great poem” (mahākāvya) it incorprates two of the most powerful Sanskrit traditions, the “Ramáyana” and Pánini’s grammar, and several other minor themes. In this one rich mix of science and art, Bhatti created both a po- etic retelling of the adventures of Rama and a compendium of examples of grammar, metrics, the Prakrit language and rhetoric. As literature, his composition stands comparison with the best of Sanskrit poetry, in particular cantos , and . “Bhatti’s Poem” provides a comprehensive exem- plification of Sanskrit grammar in use and a good introduc- tion to the science (śāstra) of poetics or rhetoric (alamk. āra, lit. ornament). It also gives a taster of the Prakrit language (a major component in every Sanskrit drama) in an easily ac- cessible form. Finally it tells the compelling story of Prince Rama in simple elegant Sanskrit: this is the “Ramáyana” faithfully retold. e learned Indian curriculum in late classical times had at its heart a system of grammatical study and linguistic analysis. e core text for this study was the notoriously difficult “Eight Books” (A.s.tādhyāyī) of Pánini, the sine qua non of learning composed in the fourth century , and arguably the most remarkable and indeed foundational text in the history of linguistics. Not only is the “Eight Books” a description of a language unmatched in totality for any language until the nineteenth century, but it is also pre- sented in the most compact form possible through the use xix of an elaborate and sophisticated metalanguage, again un- known anywhere else in linguistics before modern times. -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Devan¯Agar¯I for TEX Version 2.17.1
Devanagar¯ ¯ı for TEX Version 2.17.1 Anshuman Pandey 6 March 2019 Contents 1 Introduction 2 2 Project Information 3 3 Producing Devan¯agar¯ıText with TEX 3 3.1 Macros and Font Definition Files . 3 3.2 Text Delimiters . 4 3.3 Example Input Files . 4 4 Input Encoding 4 4.1 Supplemental Notes . 4 5 The Preprocessor 5 5.1 Preprocessor Directives . 7 5.2 Protecting Text from Conversion . 9 5.3 Embedding Roman Text within Devan¯agar¯ıText . 9 5.4 Breaking Pre-Defined Conjuncts . 9 5.5 Supported LATEX Commands . 9 5.6 Using Custom LATEX Commands . 10 6 Devan¯agar¯ıFonts 10 6.1 Bombay-Style Fonts . 11 6.2 Calcutta-Style Fonts . 11 6.3 Nepali-Style Fonts . 11 6.4 Devan¯agar¯ıPen Fonts . 11 6.5 Default Devan¯agar¯ıFont (LATEX Only) . 12 6.6 PostScript Type 1 . 12 7 Special Topics 12 7.1 Delimiter Scope . 12 7.2 Line Spacing . 13 7.3 Hyphenation . 13 7.4 Captions and Date Formats (LATEX only) . 13 7.5 Customizing the date and captions (LATEX only) . 14 7.6 Using dvnAgrF in Sections and References (LATEX only) . 15 7.7 Devan¯agar¯ıand Arabic Numerals . 15 7.8 Devan¯agar¯ıPage Numbers and Other Counters (LATEX only) . 15 1 7.9 Category Codes . 16 8 Using Devan¯agar¯ıin X E LATEXand luaLATEX 16 8.1 Using Hindi with Polyglossia . 17 9 Using Hindi with babel 18 9.1 Installation . 18 9.2 Usage . 18 9.3 Language attributes . 19 9.3.1 Attribute modernhindi . -

Pronunciation
PRONUNCIATION Guide to the Romanized version of quotations from the Guru Granth Saheb. A. Consonants Gurmukhi letter Roman Word in Roman Word in Gurmukhi Meaning Letter letters using the letters using the relevant letter relevant letter from from the second the first column column S s Sabh sB All H h Het ihq Affection K k Krodh kroD Anger K kh Khayl Kyl Play G g Guru gurU Teacher G gh Ghar Gr House | ng Ngyani / gyani i|AwnI / igAwnI Possessing divine knowledge C c Cor cor Thief C ch Chaata Cwqw Umbrella j j Jahaaj jhwj Ship J jh Jhaaroo JwVU Broom \ ny Sunyi su\I Quiet t t Tap t`p Jump T th Thag Tg Robber f d Dar fr Fear F dh Dholak Folk Drum x n Hun hux Now q t Tan qn Body Q th Thuk Quk Sputum d d Den idn Day D dh Dhan Dn Wealth n n Net inq Everyday p p Peta ipqw Father P f Fal Pl Fruit b b Ben ibn Without B bh Bhagat Bgq Saint m m Man mn Mind X y Yam Xm Messenger of death r r Roti rotI Bread l l Loha lohw Iron v v Vasai vsY Dwell V r Koora kUVw Rubbish (n) in brackets, and (g) in brackets after the consonant 'n' both indicate a nasalised sound - Eg. 'Tu(n)' meaning 'you'; 'saibhan(g)' meaning 'by himself'. All consonants in Punjabi / Gurmukhi are sounded - Eg. 'pai-r' meaning 'foot' where the final 'r' is sounded. 3 Copyright Material: Gurmukh Singh of Raub, Pahang, Malaysia B. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Tibetan Romanization Table
Tibetan Comment [LRH1]: Transliteration revisions are highlighted below in light-gray or otherwise noted in a comment. ALA-LC romanization of Tibetan letters follows the principles of the Wylie transliteration system, as described by Turrell Wylie (1959). Diacritical marks are used for those letters representing Indic or other non-Tibetan languages, and parallel the use of these marks when transcribing their counterpart letters in Sanskrit. These are applied for the sake of consistency, and to reflect international publishing standards. Accordingly, romanize words of non-Tibetan origin systematically (following this table) in all cases, even though the word may derive from Sanskrit or another language. When Tibetan is written in another script (e.g., ʼPhags-pa) the corresponding letters in that script are also romanized according to this table. Consonants (see Notes 1-3) Vernacular Romanization Vernacular Romanization Vernacular Romanization ka da zha ཀ་ ད་ ཞ་ kha na za ཁ་ ན་ ཟ་ Comment [LH2]: While the current ALA-LC ga pa ’a table stipulates that an apostrophe should be used, ག་ པ་ འ་ this revision proposal recommends that the long- nga pha ya standing defacto LC practice of using an alif (U+02BC) be continued and explicitly stipulated in ང་ ཕ་ ཡ་ the Table. See accompanying Narrative for details. ca ba ra ཅ་ བ་ ར་ cha ma la ཆ་ མ་ ལ་ ja tsa sha ཇ་ ཙ་ ཤ་ nya tsha sa ཉ་ ཚ་ ས་ ta dza ha ཏ་ ཛ་ ཧ་ tha wa a ཐ་ ཝ་ ཨ་ Vowels and Diphthongs (see Notes 4 and 5) ཨི་ i ཨཱི་ ī རྀ་ r̥ ཨུ་ u ཨཱུ་ ū རཱྀ་ r̥̄ ཨེ་ e ཨཻ་ ai ལྀ་ ḷ ཨོ་ o ཨཽ་ au ལཱྀ ḹ ā ཨཱ་ Other Letters or Diacritical Marks Used in Words of Non-Tibetan Origin (see Notes 6 and 7) ṭa gha ḍha ཊ་ གྷ་ ཌྷ་ ṭha jha anusvāra ṃ Comment [LH3]: This letter combination does ཋ་ ཇྷ་ ◌ ཾ not occur in Tibetan texts, and has been deprecated from the Unicode Standard. -
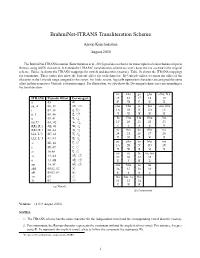
Brahminet-ITRANS Transliteration Scheme
BrahmiNet-ITRANS Transliteration Scheme Anoop Kunchukuttan August 2020 The BrahmiNet-ITRANS notation (Kunchukuttan et al., 2015) provides a scheme for transcription of major Indian scripts in Roman, using ASCII characters. It extends the ITRANS1 transliteration scheme to cover characters not covered in the original scheme. Tables 1a shows the ITRANS mappings for vowels and diacritics (matras). Table 1b shows the ITRANS mappings for consonants. These tables also show the Unicode offset for each character. By Unicode offset, we mean the offset of the character in the Unicode range assigned to the script. For Indic scripts, logically equivalent characters are assigned the same offset in their respective Unicode codepoint ranges. For illustration, we also show the Devanagari characters corresponding to the transliteration. ka kha ga gha ∼Na, N^a ITRANS Unicode Offset Devanagari 15 16 17 18 19 a 05 अ क ख ग घ ङ aa, A 06, 3E आ, ◌ा cha Cha ja jha ∼na, JNa i 07, 3F इ, ि◌ 1A 1B 1C 1D 1E ii, I 08, 40 ई, ◌ी च छ ज झ ञ u 09, 41 उ, ◌ु Ta Tha Da Dha Na uu, U 0A, 42 ऊ, ◌ू 1F 20 21 22 23 RRi, R^i 0B, 43 ऋ, ◌ृ ट ठ ड ढ ण RRI, R^I 60, 44 ॠ, ◌ॄ ta tha da dha na LLi, L^i 0C, 62 ऌ, ◌ॢ 24 25 26 27 28 LLI, L^I 61, 63 ॡ, ◌ॣ त थ द ध न pa pha ba bha ma .e 0E, 46 ऎ, ◌ॆ 2A 2B 2C 2D 2E e 0F, 47 ए, ◌े प फ ब भ म ai 10,48 ऐ, ◌ै ya ra la va, wa .o 12, 4A ऒ, ◌ॊ 2F 30 32 35 o 13, 4B ओ, ◌ो य र ल व au 14, 4C औ, ◌ौ sha Sha sa ha aM 05 02, 02 अं 36 37 38 39 aH 05 03, 03 अः श ष स ह .m 02 ◌ं Ra lda, La zha .h 03 ◌ः 31 33 34 (a) Vowels ऱ ळ ऴ (b) Consonants Version: v1.0 (9 August 2020) NOTES: 1. -

The Formal Kharoṣṭhī Script from the Northern Tarim Basin in Northwest
Acta Orientalia Hung. 73 (2020) 3, 335–373 DOI: 10.1556/062.2020.00015 Th e Formal Kharoṣṭhī script from the Northern Tarim Basin in Northwest China may write an Iranian language1 FEDERICO DRAGONI, NIELS SCHOUBBEN and MICHAËL PEYROT* L eiden University Centre for Linguistics, Universiteit Leiden, Postbus 9515, 2300 RA Leiden, Th e Netherlands E-mail: [email protected]; [email protected]; *Corr esponding Author: [email protected] Received: February 13, 2020 •Accepted: May 25, 2020 © 2020 The Authors ABSTRACT Building on collaborative work with Stefan Baums, Ching Chao-jung, Hannes Fellner and Georges-Jean Pinault during a workshop at Leiden University in September 2019, tentative readings are presented from a manuscript folio (T II T 48) from the Northern Tarim Basin in Northwest China written in the thus far undeciphered Formal Kharoṣṭhī script. Unlike earlier scholarly proposals, the language of this folio can- not be Tocharian, nor can it be Sanskrit or Middle Indic (Gāndhārī). Instead, it is proposed that the folio is written in an Iranian language of the Khotanese-Tumšuqese type. Several readings are proposed, but a full transcription, let alone a full translation, is not possible at this point, and the results must consequently remain provisional. KEYWORDS Kharoṣṭhī, Formal Kharoṣṭhī, Khotanese, Tumšuqese, Iranian, Tarim Basin 1 We are grateful to Stefan Baums, Chams Bernard, Ching Chao-jung, Doug Hitch, Georges-Jean Pinault and Nicholas Sims-Williams for very helpful discussions and comments on an earlier draft. We also thank the two peer-reviewers of the manuscript. One of them, Richard Salomon, did not wish to remain anonymous, and espe- cially his observation on the possible relevance of Khotan Kharoṣṭhī has proved very useful. -

Draft Screening Assessment
Screening Asse ssment for the Challenge Phenol, (1,1-dimethylethyl)-4-methoxy- (Butylated hydroxyanisole) Chemical Abstracts Service Registry Number 25013-16-5 Environment Canada Health Canada July 2010 Screening Assessment CAS RN 25013-16-5 Synopsis The Ministers of the Environment and of Health have conducted a screening assessment of phenol, (1,1-dimethylethyl)-4-methoxy- (also known as butylated hydroxyanisole or BHA), Chemical Abstracts Service Registry Number 25013-16-5. The substance BHA was identified in the categorization of the Domestic Substances List as a high priority for action under the Challenge, as it was determined to present intermediate potential for exposure of individuals in Canada and was considered to present a high hazard to human health, based upon classification by other agencies on the basis of carcinogenicity. The substance did not meet the ecological categorization criteria for persistence, bioaccumulation or inherent toxicity to aquatic organisms. Therefore, this assessment focuses principally upon information relevant to the evaluation of risks to human health. According to information reported in response to a notice published under section 71 of the Canadian Environmental Protection Act, 1999 (CEPA 1999), no BHA was manufactured in Canada in 2006 at quantities equal to or greater than the reporting threshold of 100 kg. However, between 100 and 1000 kg of BHA was imported into Canada, while between 1000 and 10 000 kg of BHA was used in Canada alone, in a product, in a mixture or in a manufactured item. BHA is permitted for use in Canada as an antioxidant in food. In fats and fat-containing foods, BHA delays the deterioration of flavours and odours and substantially increases the shelf life. -

Designing Devanagari Type
Designing Devanagari type The effect of technological restrictions on current practice Kinnat Sóley Lydon BA degree final project Iceland Academy of the Arts Department of Design and Architecture Designing Devanagari type: The effect of technological restrictions on current practice Kinnat Sóley Lydon Final project for a BA degree in graphic design Advisor: Gunnar Vilhjálmsson Graphic design Department of Design and Architecture December 2015 This thesis is a 6 ECTS final project for a Bachelor of Arts degree in graphic design. No part of this thesis may be reproduced in any form without the express consent of the author. Abstract This thesis explores the current process of designing typefaces for Devanagari, a script used to write several languages in India and Nepal. The typographical needs of the script have been insufficiently met through history and many Devanagari typefaces are poorly designed. As the various printing technologies available through the centuries have had drastic effects on the design of Devanagari, the thesis begins with an exploration of the printing history of the script. Through this exploration it is possible to understand which design elements constitute the script, and which ones are simply legacies of older technologies. Following the historic overview, the character set and unique behavior of the script is introduced. The typographical anatomy is analyzed, while pointing out specific design elements of the script. Although recent years has seen a rise of interest on the subject of Devanagari type design, literature on the topic remains sparse. This thesis references books and articles from a wide scope, relying heavily on the works of Fiona Ross and her extensive research on non-Latin typography.