Brahminet-ITRANS Transliteration Scheme
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction
INTRODUCTION ’ P”(Bha.t.tikāvya) is one of the boldest “B experiments in classical literature. In the formal genre of “great poem” (mahākāvya) it incorprates two of the most powerful Sanskrit traditions, the “Ramáyana” and Pánini’s grammar, and several other minor themes. In this one rich mix of science and art, Bhatti created both a po- etic retelling of the adventures of Rama and a compendium of examples of grammar, metrics, the Prakrit language and rhetoric. As literature, his composition stands comparison with the best of Sanskrit poetry, in particular cantos , and . “Bhatti’s Poem” provides a comprehensive exem- plification of Sanskrit grammar in use and a good introduc- tion to the science (śāstra) of poetics or rhetoric (alamk. āra, lit. ornament). It also gives a taster of the Prakrit language (a major component in every Sanskrit drama) in an easily ac- cessible form. Finally it tells the compelling story of Prince Rama in simple elegant Sanskrit: this is the “Ramáyana” faithfully retold. e learned Indian curriculum in late classical times had at its heart a system of grammatical study and linguistic analysis. e core text for this study was the notoriously difficult “Eight Books” (A.s.tādhyāyī) of Pánini, the sine qua non of learning composed in the fourth century , and arguably the most remarkable and indeed foundational text in the history of linguistics. Not only is the “Eight Books” a description of a language unmatched in totality for any language until the nineteenth century, but it is also pre- sented in the most compact form possible through the use xix of an elaborate and sophisticated metalanguage, again un- known anywhere else in linguistics before modern times. -

GEO ROO DIST BUC PRO Prep ATE 111 Cha Dec Expi OTECHNICA OSEVELT ST TRICT CKEYE, ARI OJECT # 15 Pared By
GEOTECHNICAL EXPLORARATION REPORT ROOSEVELT STREET IMPROVEMENT DISTRICT BUCKEYE, ARIZONA PROJECT # 150004 Prepared by: ATEK Engineering Consultants, LLC 111 South Weber Drive, Suite 1 Chandler, Arizona 85226 Exp ires 9/30/2018 December 14, 2015 December 14, 2015 ATEK Project #150004 RITOCH-POWELL & Associates 5727 North 7th Street #120 Phoenix, AZ 85014 Attention: Mr. Keith L. Drunasky, P.E. RE: GEOTECHNICAL EXPLORATION REPORT Roosevelt Street Improvement District Buckeye, Arizona Dear Mr. Drunasky: ATEK Engineering Consultants, LLC is pleased to present the attached Geotechnical Exploration Report for the Roosevelt Street Improvement Disstrict located in Buckeye, Arizona. The purpose of our study was to explore and evaluate the subsurface conditions at the proposed site to develop geotechnical engineering recommendations for project design and construction. Based on our findings, the site is considered suittable for the proposed construction, provided geotechnical recommendations presented in thhe attached report are followed. Specific recommendations regarding the geotechnical aspects of the project design and construction are presented in the attached report. The recommendations contained within this report are depeendent on the provisions provided in the Limitations and Recommended Additional Services sections of this report. We appreciate the opportunity of providing our services for this project. If you have questions regarding this report or if we may be of further assistance, please contact the undersigned. Sincerely, ATEK Engineering Consultants, LLC Expires 9/30/2018 James P Floyd, P.E. Armando Ortega, P.E. Project Manager Principal Geotechnical Engineer Expires 9/30/2017 111 SOUTH WEBER DRIVE, SUITE 1 WWW.ATEKEC.COM P (480) 659-8065 CHANDLER, AZ 85226 F (480) 656-9658 TABLE OF CONTENTS 1. -
![Positional Notation Or Trigonometry [2, 13]](https://docslib.b-cdn.net/cover/6799/positional-notation-or-trigonometry-2-13-106799.webp)
Positional Notation Or Trigonometry [2, 13]
The Greatest Mathematical Discovery? David H. Bailey∗ Jonathan M. Borweiny April 24, 2011 1 Introduction Question: What mathematical discovery more than 1500 years ago: • Is one of the greatest, if not the greatest, single discovery in the field of mathematics? • Involved three subtle ideas that eluded the greatest minds of antiquity, even geniuses such as Archimedes? • Was fiercely resisted in Europe for hundreds of years after its discovery? • Even today, in historical treatments of mathematics, is often dismissed with scant mention, or else is ascribed to the wrong source? Answer: Our modern system of positional decimal notation with zero, to- gether with the basic arithmetic computational schemes, which were discov- ered in India prior to 500 CE. ∗Bailey: Lawrence Berkeley National Laboratory, Berkeley, CA 94720, USA. Email: [email protected]. This work was supported by the Director, Office of Computational and Technology Research, Division of Mathematical, Information, and Computational Sciences of the U.S. Department of Energy, under contract number DE-AC02-05CH11231. yCentre for Computer Assisted Research Mathematics and its Applications (CARMA), University of Newcastle, Callaghan, NSW 2308, Australia. Email: [email protected]. 1 2 Why? As the 19th century mathematician Pierre-Simon Laplace explained: It is India that gave us the ingenious method of expressing all numbers by means of ten symbols, each symbol receiving a value of position as well as an absolute value; a profound and important idea which appears so simple to us now that we ignore its true merit. But its very sim- plicity and the great ease which it has lent to all computations put our arithmetic in the first rank of useful inventions; and we shall appre- ciate the grandeur of this achievement the more when we remember that it escaped the genius of Archimedes and Apollonius, two of the greatest men produced by antiquity. -

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

Devanagari in Luatex
Devanagari in LuaTeX Using OpenType features Ivo Geradts Kai Eigner 1. About us 2. Foreign scripts in TeX, past and present 3. OpenType features 4. OpenType rendering engines 5. ConTeXt engine 6. Example 1: Latin with mark and mkmk 7. Example 2: Arabic 8. Example 3: Devanagari 1. About us TAT Zetwerk offers academic typesetting services Specialties: - critical editions - foreign scripts PlainTeX, for two reasons: - our exotic needs - well documented 2. Foreign scripts in TeX, past and present Past: 8-bit PostScript fonts; e.g. approach for classical greek: - encoding: α = a, β = b, γ = g - ligature table: σ = s, ς = /s, ἄ = a)' - multitude of font-related files: tfm, vf, pfb, enc Present: new TeX-engines XeTeX and LuaTeX can handle OpenType fonts containing Unicode glyph table: - ἄ is unicode position 1F04 3. OpenType features OpenType fonts contain more information than traditional fonts - tfm: bounding boxes, kerning, ligaturen, etc. - OpenType additions: GPOS, GSUB, marks Introduction of XeTeX and LuaTeX removes old limitations: - vocalized Hebrew, Arabic - CJK - Devanagari 4. OpenType rendering engines OpenType fonts require rendering engine, such as: - Uniscribe (Windows) - AAT (OS X); XeTeX on OS X - Graphite (Windows and Linux); XeTeX on all platforms - ConTeXt engine: collection of Lua-scripts attached to various callbacks related to font calls and processing of node list 5. ConTeXt engine - independent of operating system - readable and modifiable - work in progress 6. Example 1: Latin script with mark and mkmk 7. Example 2: Arabic 8. Example 3: Devanagari - Introduction: what is Devanagari? - Devanagari and OpenType - Examples Devanagari Script - Sanskrit (old Indic) - Hindi - Nepali Abugida (consonant–vowel sequences are written as a unit) क = “ka” ◌ क् = “k” क + ् (halant) ◌ क = “ku” क + ु (matra) Mahabharata Syllable structure - Consonants: e.g. -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging
ORIGINAL ARTICLE Neuroscience http://dx.doi.org/10.3346/jkms.2014.29.10.1416 • J Korean Med Sci 2014; 29: 1416-1424 Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging Zang-Hee Cho,1 Nambeom Kim,1 The two basic scripts of the Korean writing system, Hanja (the logography of the traditional Sungbong Bae,2 Je-Geun Chi,1 Korean character) and Hangul (the more newer Korean alphabet), have been used together Chan-Woong Park,1 Seiji Ogawa,1,3 since the 14th century. While Hanja character has its own morphemic base, Hangul being and Young-Bo Kim1 purely phonemic without morphemic base. These two, therefore, have substantially different outcomes as a language as well as different neural responses. Based on these 1Neuroscience Research Institute, Gachon University, Incheon, Korea; 2Department of linguistic differences between Hanja and Hangul, we have launched two studies; first was Psychology, Yeungnam University, Kyongsan, Korea; to find differences in cortical activation when it is stimulated by Hanja and Hangul reading 3Kansei Fukushi Research Institute, Tohoku Fukushi to support the much discussed dual-route hypothesis of logographic and phonological University, Sendai, Japan routes in the brain by fMRI (Experiment 1). The second objective was to evaluate how Received: 14 February 2014 Hanja and Hangul affect comprehension, therefore, recognition memory, specifically the Accepted: 5 July 2014 effects of semantic transparency and morphemic clarity on memory consolidation and then related cortical activations, using functional magnetic resonance imaging (fMRI) Address for Correspondence: (Experiment 2). The first fMRI experiment indicated relatively large areas of the brain are Young-Bo Kim, MD Department of Neuroscience and Neurosurgery, Gachon activated by Hanja reading compared to Hangul reading. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
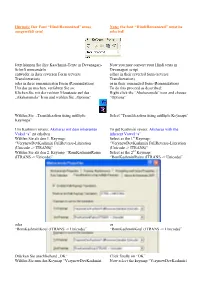
Note: the Font “Hindiromanized” Must Be Selected
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...].