What Do Phone Embeddings Learn About Phonology?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
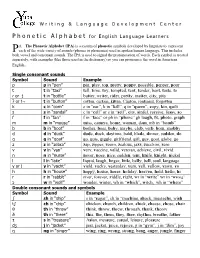
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS on THREE CONTINENTS a Dissertation Submitted to the Facu
FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS A Dissertation submitted to the Faculty of the Graduate School of Arts and Sciences of Georgetown University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics By Sheena Shah, M.S. Washington, DC May 14, 2013 Copyright 2013 by Sheena Shah All Rights Reserved ii FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS Sheena Shah, M.S. Thesis Advisors: Alison Mackey, Ph.D. Natalie Schilling, Ph.D. ABSTRACT This dissertation examines the causes behind the differences in proficiency in the North Indian language Gujarati among heritage learners of Gujarati in three diaspora locations. In particular, I focus on whether there is a relationship between heritage language ability and ethnic and cultural identity. Previous studies have reported divergent findings. Some have found a positive relationship (e.g., Cho, 2000; Kang & Kim, 2011; Phinney, Romero, Nava, & Huang, 2001; Soto, 2002), whereas others found no correlation (e.g., C. L. Brown, 2009; Jo, 2001; Smolicz, 1992), or identified only a partial relationship (e.g., Mah, 2005). Only a few studies have addressed this question by studying one community in different transnational locations (see, for example, Canagarajah, 2008, 2012a, 2012b). The current study addresses this matter by examining data from members of the same ethnic group in similar educational settings in three multi-ethnic and multilingual cities. The results of this study are based on a survey consisting of questionnaires, semi-structured interviews, and proficiency tests with 135 participants. Participants are Gujarati heritage language learners from the U.K., Singapore, and South Africa, who are either current students or recent graduates of a Gujarati School. -

Phones and Phonemes
NLPA-Phon1 (4/10/07) © P. Coxhead, 2006 Page 1 Natural Language Processing & Applications Phones and Phonemes 1 Phonemes If we are to understand how speech might be generated or recognized by a computer, we need to study some of the underlying linguistic theory. The aim here is to UNDERSTAND the theory rather than memorize it. I’ve tried to reduce and simplify as much as possible without serious inaccuracy. Speech consists of sequences of sounds. The use of an instrument (such as a speech spectro- graph) shows that most of normal speech consists of continuous sounds, both within words and across word boundaries. Speakers of a language can easily dissect its continuous sounds into words. With more difficulty, they can split words into component sounds, or ‘segments’. However, it is not always clear where to stop splitting. In the word strip, for example, should the sound represented by the letters str be treated as a unit, be split into the two sounds represented by st and r, or be split into the three sounds represented by s, t and r? One approach to isolating component sounds is to look for ‘distinctive unit sounds’ or phonemes.1 For example, three phonemes can be distinguished in the word cat, corresponding to the letters c, a and t (but of course English spelling is notoriously non- phonemic so correspondence of phonemes and letters should not be expected). How do we know that these three are ‘distinctive unit sounds’ or phonemes of the English language? NOT from the sounds themselves. A speech spectrograph will not show a neat division of the sound of the word cat into three parts. -

English Teachers' Mastery of the English Aspiration And
Arina Isti’anah - English Teachers’ Mastery of the English Aspiration and Stress Rules ENGLISH TEACHERS’ MASTERY OF THE ENGLISH ASPIRATION AND STRESS RULES Arina Isti’anah Sanata Dharma University [email protected] Abstract This paper tries to observe the English teachers’ awareness and representation of the English aspiration and stress rules. The research purposes to find out whether or not the teachers are aware of the English aspiration and stress rules, and to find out how the teachers represent the English aspiration and stress rules. Based on the analysis, it can be concluded that the teachers’ awareness of the English aspiration and stress rules is very low. It is indicated with the percentage which equals to 44% and 48% for English aspiration and stress rules. In representing the English aspiration and stress rules, the teachers face the problems in producing aspiration in the pronunciation, placing the right stress and pronouncing three and four X in the coda position. There are two reasons affecting the teachers’ awareness of the English aspiration and stress rules namely exposure and L1 influence. Artikel ini bertujuan untuk meneliti kesadaran dan representasi aturan aspirasi dan tekanan oleh guru bahasa Inggris. Penelitian ini bertujuan untuk menjelaskan apakah guru bahasa Inggris mempunyai kesadaran atas aturan aspirasi dan tekanan dalam bahasa Inggris, dan untuk menunjukkan bagaimana guru Bahasa Inggris mewujudkan aturan aspirasi dan tekanan dalam pelafalan mereka. Berdasarkan analisis yang dilakukan, dapat disimpulkan bahwa kesadaran guru Bahasa Inggris atas aturan aspirasi dan tekanan dalam Bahasa Inggris masih sangat rendah. Hal tersebut ditunjukkan oleh rendahnya prosentase dalam perwujudan aturan aspirasi dan tekanan: 44% dan 48%. -

A Deep Generative Model of Vowel Formant Typology
A Deep Generative Model of Vowel Formant Typology Ryan Cotterell and Jason Eisner Department of Computer Science Johns Hopkins University, Baltimore MD, 21218 ryan.cotterell,eisner @jhu.edu { } Abstract and its goal should be the construction of a univer- sal prior over potential languages. A probabilistic What makes some types of languages more approach does not rule out linguistic systems com- probable than others? For instance, we know pletely (as long as one’s theoretical formalism can that almost all spoken languages contain the vowel phoneme /i/; why should that be? The describe them at all), but it can position phenomena field of linguistic typology seeks to answer on a scale from very common to very improbable. these questions and, thereby, divine the mech- Probabilistic modeling also provides a discipline anisms that underlie human language. In our for drawing conclusions from sparse data. While work, we tackle the problem of vowel system we know of over 7000 human languages, we have typology, i.e., we propose a generative proba- some sort of linguistic analysis for only 2300 of bility model of which vowels a language con- them (Comrie et al., 2013), and the dataset used in tains. In contrast to previous work, we work di- rectly with the acoustic information—the first this paper (Becker-Kristal, 2010) provides simple two formant values—rather than modeling dis- vowel data for fewer than 250 languages. crete sets of phonemic symbols (IPA). We de- Formants are the resonant frequencies of the hu- velop a novel generative probability model and man vocal tract during the production of speech report results based on a corpus of 233 lan- sounds. -
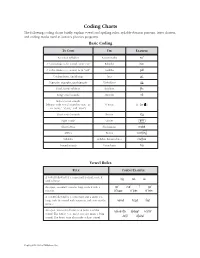
Phonics TRB Coding Chart
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss. -

Grapheme-To-Phone Using Finite-State Transducers D
GRAPHEME-TO-PHONE USING FINITE-STATE TRANSDUCERS D. Caseiro, I. Trancoso, L. Oliveira C. Viana INESC-ID/IST CLUL RuaAlves Redol 9, 1000-029 Lisbon, Portugal Av.Prof. Gama Pinto 2, Lisbon, Portugal ABSTRACT Some of the most common approaches to grapheme-to-phone convertion can be compiled to WFSTs,among which are CARTs Severalapproaches have been adopted over the years for [6], and most rule systems, such as two-level [7] and rewriting grapheme-to-phone conversion for European Portuguese: hand- rules [8]. derived rules, neural networks, classification and regression trees, In this work, we first show how we compiled the rules of the etc. This paper describes different approaches implemented as DIXI system to WFSTs (Section 2), we then present data-driven Weighted Finite State Transducers (WFSTs), motivated by their approaches to the problem (Section 3), and finally we combine the flexibility in integrating multiples sources of information and other knowledge-based with the data-driven approaches (Section 4). interesting properties such as inversion. We describe and compare In order to assess the performance of the different methods, we rule-based, data-driven and hybrid approaches. Best results were used a pronunciation lexicon built on the PF (“Portuguˆes Funda- obtained with the rule-based approach, but one should take into mental”) corpus. The lexicon contains around 26000 forms. 25% account the fact that the data-driven one was trained with automat- of the corpus was randomly selected for evaluation. The remaining ically transcribed material. portion of the corpus was used for training or debugging. The sizeofthetraining material for the data-driven approaches was increased with a subset of the BD-P´ublico [9] text corpus. -

Globalphone: Pronunciation Dictionaries in 20 Languages
GlobalPhone: Pronunciation Dictionaries in 20 Languages Tanja Schultz and Tim Schlippe Cognitive Systems Lab, Karlsruhe Institute of Technology (KIT), Germany [email protected] Abstract This paper describes the advances in the multilingual text and speech database GLOBALPHONE a multilingual database of high-quality read speech with corresponding transcriptions and pronunciation dictionaries in 20 languages. GLOBALPHONE was designed to be uniform across languages with respect to the amount of data, speech quality, the collection scenario, the transcription and phone set conventions. With more than 400 hours of transcribed audio data from more than 2000 native speakers GLOBALPHONE supplies an excellent basis for research in the areas of multilingual speech recognition, rapid deployment of speech processing systems to yet unsupported languages, language identification tasks, speaker recognition in multiple languages, multilingual speech synthesis, as well as monolingual speech recognition in a large variety of languages. Very recently the GLOBALPHONE pronunciation dictionaries have been made available for research and commercial purposes by the European Language Resources Association (ELRA). Keywords: Speech, Text, and Dictionary Resources for Multilingual Speech Processing 1. Introduction More than ten years ago we released a multilingual text With more than 7100 languages in the world (Lewis et al., and speech corpus GLOBALPHONE to address the lack of 2013) and the need to support multiple input and output databases which are consistent across languages (Schultz, languages, it is one of the most pressing challenge for the 2002). By that time the database consisted of 15 languages speech and language community to develop and deploy but since then has been extended significantly to cover more speech processing systems in yet unsupported languages languages, more speakers, more text resources, and more rapidly and at reasonable costs (Schultz, 2004; Schultz and word types along with their pronunciations. -

Collation Sounds Boo
In a nutshell……… Synthetic Phonics Teaching: The best way to teach the technical skills of reading (decoding) and spelling (encoding) in the English language is to teach the core code knowledge of The English Alphabetic Code in systematic steps and the three core skills of: 1. READING - sound out and blend (synthesise) the sounds (phonemes) represented by the letters and letter groups (graphemes) all-through-the-printed-word, from left to right (e.g. see ‘tray’, say “/t/ /r/ /ai/”, hear and say “tray”). 2. SPELLING - segment (or split up) the smallest identifiable sounds (phonemes) all-through-the-spoken-word (e.g. hear “tray”, identify /t/ /r/ /ai/) and then pull letter/s from memory to spell the word ‘tray’. 3. WRITING - record the correct shapes of the letters or letter groups (graphemes), from left to right, which represent the phonemes identified from segmenting the spoken word from beginning to end. The English Alphabetic Code: We can identify around 44 phonemes (the smallest identifiable sounds in words) in the English language but there are only 26 letters in The Alphabet to represent the 44+ sounds. Single letters and letters combined into letter groups act as code for the sounds, for example; the grapheme ‘ie’ is pronounced /igh/ as in the word ‘tie’. The English Alphabetic Code is complicated by the fact that it has many ‘spelling alternatives’ and ‘pronunciation alternatives’, for example; the grapheme ‘ie’ can also be pronounced /ee/ as in the word ‘chief’. The Alphabetic Code, therefore, needs to be taught explicitly and systematically for both reading and spelling. -

The Phonetics and Phonology of Retroflexes Published By
The Phonetics and Phonology of Retroflexes Published by LOT phone: +31 30 253 6006 Trans 10 fax: +31 30 253 6000 3512 JK Utrecht e-mail: [email protected] The Netherlands http://wwwlot.let.uu.nl/ Cover illustration by Silke Hamann ISBN 90-76864-39-X NUR 632 Copyright © 2003 Silke Hamann. All rights reserved. The Phonetics and Phonology of Retroflexes Fonetiek en fonologie van retroflexen (met een samenvatting in het Nederlands) Proefschrift ter verkrijging van de graad van doctor aan de Universiteit Utrecht op gezag van de Rector Magnificus, Prof. Dr. W.H. Gispen, ingevolge het besluit van het College voor Promoties in het openbaar te verdedigen op vrijdag 6 juni 2003 des middags te 4.15 uur door Silke Renate Hamann geboren op 25 februari 1971 te Lampertheim, Duitsland Promotoren: Prof. dr. T. A. Hall (Leipzig University) Prof. dr. Wim Zonneveld (Utrecht University) Contents 1 Introduction 1 1.1 Markedness of retroflexes 3 1.2 Phonetic cues and phonological features 6 1.3 Outline of the dissertation 8 Part I: Phonetics of Retroflexes 2 Articulatory variation and common properties of retroflexes 11 2.1 Phonetic terminology 12 2.2 Parameters of articulatory variation 14 2.2.1 Speaker dependency 15 2.2.2 Vowel context 16 2.2.3 Speech rate 17 2.2.4 Manner dependency 19 2.2.4.1 Plosives 19 2.2.4.2 Nasals 20 2.2.4.3 Fricatives 21 2.2.4.4 Affricates 23 2.2.4.5 Laterals 24 2.2.4.6 Rhotics 25 2.2.4.7 Retroflex vowels 26 2.2.5 Language family 27 2.2.6 Iventory size 28 2.3 Common articulatory properties of retroflexion 32 2.3.1 Apicality 33 2.3.2 Posteriority -

Phone Merger Specification for Multilingual ASR: the Motorola Polyphone Network
Phone Merger Specification for Multilingual ASR: The Motorola Polyphone Network Lynette Melnar and Jim Talley Motorola Human Interface Labs, Voice Dialog Systems Lab, USA E-mail: [email protected], [email protected] ABSTRACT 2. MOTPOLY: OVERVIEW This paper describes the Motorola Polyphone Network MotPoly is a knowledge-based, hierarchically arranged (MotPoly), a hierarchical, universal phone phone merger specification network for shared correspondence network that defines allowable phone multilingual and multi-dialect acoustic modeling. The mergers for shared acoustic modeling in multilingual and organization of MotPoly is language-independent and multi-dialect automatic speech recognition (ML-ASR). phone merger is defined by an internally ranked system of MotPoly’s organization is defined by phonetic similarity relative phonetic similarity, phonological contrastiveness, and other language-independent phonological factors. and phone frequency. MotPoly functions in ML-ASR as a Unlike other approaches to shared acoustic modeling, phone merger framework that constrains data-driven MotPoly can be effectively used in systems where acoustic modeling strategies. Because MotPoly is not computational resources are limited, such as portable biased toward any particular language, language family, devices. Furthermore, it is less constrained by language or language type, it is a universal, static definition of data availability than other approaches. With MotPoly as phone merger and can be used unmodified to specify part of an overall strategy, Motorola’s Voice Dialog likely mergers for an unlimited number of phones from Systems Lab’s ML-ASR team was able to define a set of any collection of languages or dialects. multilingual acoustic models whose size was only 23% of the largest monolingual model set but whose overall MotPoly is of particular value in applications that are performance was higher than the monolingual models by restricted in computational and language resources. -

Phonemes and Allophones of English Consonants
Rough definition of phoneme • Phoneme (Concise Dictionary of English consonants: Linguistics, Oxford U. Press 1997) Phonemes and Allophones • “The smallest distinct sound unit in a given language: e.g. /»tIp/ in English realizes the Effects related to aspiration and three successive phonemes, represented in ‘devoiced’ voiced sounds and a few spelling by the letters t, i, and p. other issues Phonemic differences vs. Phonemes allophonic differences • Strict, detailed definitions of the term phoneme are • Differences in speech sound that can signal complex differences between two different words are – Not part of this course phonemic differences – Take phonology courses to fight over the details • Other differences in speech sound that are • Rough and ready idea is indispensable for practical phonetics clearly audible are only allophonic – Must make a distinction between phonemic and differences allophonic differences – ‘pronunciation variants’ that cannot signal different words. Representing allophonic Answer: ‘pie, spy, buy’ differences • ‘Broad’ (= coarse-grained) transcription enough Phonemes in ‘/’ (slash or solidus, pl solidi) for phonemic representation marks – Choose simple symbol for a ‘representative’ (allo)phone /p/ /b/ • ‘Narrow’ (= fine-grained) transcription often requires diacritics • Diacritics for stops [p] [pH] [b] [b8] pH - aspirated p p| - ‘p with inaudible release’ (‘unreleased p’) b8 - ‘(partially) devoiced b’ Phones in square brackets Examples ‘Stop.’, ‘Stop!’, Examples: ‘pie, spy, buy’ ‘Stop!!’, ‘Stob!’ • ‘pie’ [»pHaj]