Phone Merger Specification for Multilingual ASR: the Motorola Polyphone Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

OSU WPL # 27 (1983) 140- 164. the Elimination of Ergative Patterns Of
OSU WPL # 27 (1983) 140- 164. The Elimination of Ergative Patterns of Case-Marking and Verbal Agreement in Modern Indic Languages Gregory T. Stump Introduction. As is well known, many of the modern Indic languages are partially ergative, showing accusative patterns of case- marking and verbal agreement in nonpast tenses, but ergative patterns in some or all past tenses. This partial ergativity is not at all stable in these languages, however; what I wish to show in the present paper, in fact, is that a large array of factors is contributing to the elimination of partial ergativity in the modern Indic languages. The forces leading to the decay of ergativity are diverse in nature; and any one of these may exert a profound influence on the syntactic development of one language but remain ineffectual in another. Before discussing this erosion of partial ergativity in Modern lndic, 1 would like to review the history of what the I ndian grammar- ians call the prayogas ('constructions') of a past tense verb with its subject and direct object arguments; the decay of Indic ergativity is, I believe, best envisioned as the effect of analogical develop- ments on or within the system of prayogas. There are three prayogas in early Modern lndic. The first of these is the kartariprayoga, or ' active construction' of intransitive verbs. In the kartariprayoga, the verb agrees (in number and p,ender) with its subject, which is in the nominative case--thus, in Vernacular HindOstani: (1) kartariprayoga: 'aurat chali. mard chala. woman (nom.) went (fern. sg.) man (nom.) went (masc. -
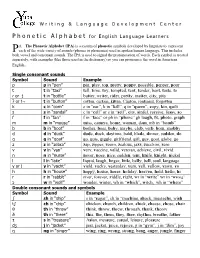
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Pronunciation
PRONUNCIATION Guide to the Romanized version of quotations from the Guru Granth Saheb. A. Consonants Gurmukhi letter Roman Word in Roman Word in Gurmukhi Meaning Letter letters using the letters using the relevant letter relevant letter from from the second the first column column S s Sabh sB All H h Het ihq Affection K k Krodh kroD Anger K kh Khayl Kyl Play G g Guru gurU Teacher G gh Ghar Gr House | ng Ngyani / gyani i|AwnI / igAwnI Possessing divine knowledge C c Cor cor Thief C ch Chaata Cwqw Umbrella j j Jahaaj jhwj Ship J jh Jhaaroo JwVU Broom \ ny Sunyi su\I Quiet t t Tap t`p Jump T th Thag Tg Robber f d Dar fr Fear F dh Dholak Folk Drum x n Hun hux Now q t Tan qn Body Q th Thuk Quk Sputum d d Den idn Day D dh Dhan Dn Wealth n n Net inq Everyday p p Peta ipqw Father P f Fal Pl Fruit b b Ben ibn Without B bh Bhagat Bgq Saint m m Man mn Mind X y Yam Xm Messenger of death r r Roti rotI Bread l l Loha lohw Iron v v Vasai vsY Dwell V r Koora kUVw Rubbish (n) in brackets, and (g) in brackets after the consonant 'n' both indicate a nasalised sound - Eg. 'Tu(n)' meaning 'you'; 'saibhan(g)' meaning 'by himself'. All consonants in Punjabi / Gurmukhi are sounded - Eg. 'pai-r' meaning 'foot' where the final 'r' is sounded. 3 Copyright Material: Gurmukh Singh of Raub, Pahang, Malaysia B. -

Velar Segments in Old English and Old Irish
In: Jacek Fisiak (ed.) Proceedings of the Sixth International Conference on Historical Linguistics. Amsterdam: John Benjamins, 1985, 267-79. Velar segments in Old English and Old Irish Raymond Hickey University of Bonn The purpose of this paper is to look at a section of the phoneme inventories of the oldest attested stage of English and Irish, velar segments, to see how they are manifested phonetically and to consider how they relate to each other on the phonological level. The reason I have chosen to look at two languages is that it is precisely when one compares two language systems that one notices that structural differences between languages on one level will be correlated by differences on other levels demonstrating their interrelatedness. Furthermore it is necessary to view segments on a given level in relation to other segments. The group under consideration here is just one of several groups. Velar segments viewed within the phonological system of both Old English and Old Irish cor relate with three other major groups, defined by place of articulation: palatals, dentals, and labials. The relationship between these groups is not the same in each language for reasons which are morphological: in Old Irish changes in grammatical category are frequently indicated by palatalizing a final non-palatal segment (labial, dental, or velar). The same function in Old English is fulfilled by suffixes and /or prefixes. This has meant that for Old English the phonetically natural and lower-level alternation of velar elements with palatal elements in a palatal environ ment was to be found whereas in Old Irish this alternation had been denaturalized and had lost its automatic character. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Acoustics and Perception of Velar Softening for Unaspirated Stops
ARTICLE IN PRESS Journal of Phonetics 37 (2009) 189–211 www.elsevier.com/locate/phonetics Acoustics and perception of velar softening for unaspirated stops Daniel Recasensa,b,Ã, Aina Espinosaa,b aDepartament de Filologia Catalana, Universitat Auto`noma de Barcelona, Bellaterra, Barcelona, Spain bLaboratori de Fone`tica, Institut d’Estudis Catalans, c/Carme, 47, Barcelona 08001, Spain Received 2 July 2008; received in revised form 16 January 2009; accepted 20 January 2009 Abstract This paper provides articulatory, acoustic and perceptual data in support of the hypothesis that the velar softening process through which /k/ becomes /tP/ is based on articulation rather than on acoustic equivalence if operating on unaspirated stops. Production data for unaspirated /k/ are analyzed for five speakers of Majorcan Catalan, where the velar stop phoneme exhibits (alveolo)palatal or velar allophones depending on vowel context and position. Data on several parameters, i.e., contact anteriority and dorsopalatal contact degree, burst spectral peak frequency, energy and duration, and F2 and F3 vowel transition endpoints and ranges, suggest that /tP/ may have originated from (alveolo)palatal stop realizations not only before front vocalic segments but also before low and central vowels and word finally. Perception results are consistent with the production data in indicating that the most significant /tP/ perception cues are burst energy before /], u/ and burst duration word/utterance finally. They also suggest that velar softening for unaspirated /k/ before front vocalic segments is triggered by an increase in burst frication energy and duration resulting from the narrowing of an (alveolo)palatal central channel occurring at stop closure release. -

FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS on THREE CONTINENTS a Dissertation Submitted to the Facu
FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS A Dissertation submitted to the Faculty of the Graduate School of Arts and Sciences of Georgetown University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics By Sheena Shah, M.S. Washington, DC May 14, 2013 Copyright 2013 by Sheena Shah All Rights Reserved ii FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS Sheena Shah, M.S. Thesis Advisors: Alison Mackey, Ph.D. Natalie Schilling, Ph.D. ABSTRACT This dissertation examines the causes behind the differences in proficiency in the North Indian language Gujarati among heritage learners of Gujarati in three diaspora locations. In particular, I focus on whether there is a relationship between heritage language ability and ethnic and cultural identity. Previous studies have reported divergent findings. Some have found a positive relationship (e.g., Cho, 2000; Kang & Kim, 2011; Phinney, Romero, Nava, & Huang, 2001; Soto, 2002), whereas others found no correlation (e.g., C. L. Brown, 2009; Jo, 2001; Smolicz, 1992), or identified only a partial relationship (e.g., Mah, 2005). Only a few studies have addressed this question by studying one community in different transnational locations (see, for example, Canagarajah, 2008, 2012a, 2012b). The current study addresses this matter by examining data from members of the same ethnic group in similar educational settings in three multi-ethnic and multilingual cities. The results of this study are based on a survey consisting of questionnaires, semi-structured interviews, and proficiency tests with 135 participants. Participants are Gujarati heritage language learners from the U.K., Singapore, and South Africa, who are either current students or recent graduates of a Gujarati School. -

Phones and Phonemes
NLPA-Phon1 (4/10/07) © P. Coxhead, 2006 Page 1 Natural Language Processing & Applications Phones and Phonemes 1 Phonemes If we are to understand how speech might be generated or recognized by a computer, we need to study some of the underlying linguistic theory. The aim here is to UNDERSTAND the theory rather than memorize it. I’ve tried to reduce and simplify as much as possible without serious inaccuracy. Speech consists of sequences of sounds. The use of an instrument (such as a speech spectro- graph) shows that most of normal speech consists of continuous sounds, both within words and across word boundaries. Speakers of a language can easily dissect its continuous sounds into words. With more difficulty, they can split words into component sounds, or ‘segments’. However, it is not always clear where to stop splitting. In the word strip, for example, should the sound represented by the letters str be treated as a unit, be split into the two sounds represented by st and r, or be split into the three sounds represented by s, t and r? One approach to isolating component sounds is to look for ‘distinctive unit sounds’ or phonemes.1 For example, three phonemes can be distinguished in the word cat, corresponding to the letters c, a and t (but of course English spelling is notoriously non- phonemic so correspondence of phonemes and letters should not be expected). How do we know that these three are ‘distinctive unit sounds’ or phonemes of the English language? NOT from the sounds themselves. A speech spectrograph will not show a neat division of the sound of the word cat into three parts. -

English Teachers' Mastery of the English Aspiration And
Arina Isti’anah - English Teachers’ Mastery of the English Aspiration and Stress Rules ENGLISH TEACHERS’ MASTERY OF THE ENGLISH ASPIRATION AND STRESS RULES Arina Isti’anah Sanata Dharma University [email protected] Abstract This paper tries to observe the English teachers’ awareness and representation of the English aspiration and stress rules. The research purposes to find out whether or not the teachers are aware of the English aspiration and stress rules, and to find out how the teachers represent the English aspiration and stress rules. Based on the analysis, it can be concluded that the teachers’ awareness of the English aspiration and stress rules is very low. It is indicated with the percentage which equals to 44% and 48% for English aspiration and stress rules. In representing the English aspiration and stress rules, the teachers face the problems in producing aspiration in the pronunciation, placing the right stress and pronouncing three and four X in the coda position. There are two reasons affecting the teachers’ awareness of the English aspiration and stress rules namely exposure and L1 influence. Artikel ini bertujuan untuk meneliti kesadaran dan representasi aturan aspirasi dan tekanan oleh guru bahasa Inggris. Penelitian ini bertujuan untuk menjelaskan apakah guru bahasa Inggris mempunyai kesadaran atas aturan aspirasi dan tekanan dalam bahasa Inggris, dan untuk menunjukkan bagaimana guru Bahasa Inggris mewujudkan aturan aspirasi dan tekanan dalam pelafalan mereka. Berdasarkan analisis yang dilakukan, dapat disimpulkan bahwa kesadaran guru Bahasa Inggris atas aturan aspirasi dan tekanan dalam Bahasa Inggris masih sangat rendah. Hal tersebut ditunjukkan oleh rendahnya prosentase dalam perwujudan aturan aspirasi dan tekanan: 44% dan 48%. -

Bradley 2015 Labialization and Palatalization in Judeo-Spanish
LABIALIZATION AND PALATALIZATION IN JUDEO-SPANISH PHONOLOGY* TRAVIS G. BRADLEY University of California, Davis Judeo-Spanish (JS) presents a number of phonological processes involving secondary articulations. This paper establishes novel descriptive generalizations based on labialization and palatalization phenomena across different JS dialects. I show how these generalizations are part of a broader cross-linguistic typology of secondary articulation patterns, which would remain incomplete on the basis of non-Sephardic Spanish alone. I propose an analysis in Optimality Theory (OT) that accounts for this variation using the same universal constraints that are active in languages beyond Ibero-Romance. This paper demonstrates the utility of OT as an analytical framework for doing JS phonology and in turn highlights the importance of JS to phonological theory by bringing new generalizations and data to bear on the analysis of secondary articulations. 1. Introduction Judeo-Spanish (henceforth, JS) refers to those varieties of Spanish preserved by the Sephardic Jews who were expelled from Spain in 1492 and have emigrated throughout Europe, North Africa, the Middle East, and later, the United States. JS is intriguing to study from both diachronic and synchronic perspectives. The linguistic system retains many archaic features, which gives us a unique, albeit indirect, window into the structure of Old Spanish (henceforth, OS). Having evolved in relative isolation from the linguistic norms of the Iberian Peninsula and often in contact with other