Phones and Phonemes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grapheme-To-Lexeme Feedback in the Spelling System: Evidence from a Dysgraphic Patient
COGNITIVE NEUROPSYCHOLOGY, 2006, 23 (2), 278–307 Grapheme-to-lexeme feedback in the spelling system: Evidence from a dysgraphic patient Michael McCloskey Johns Hopkins University, Baltimore, USA Paul Macaruso Community College of Rhode Island, Warwick, and Haskins Laboratories, New Haven, USA Brenda Rapp Johns Hopkins University, Baltimore, USA This article presents an argument for grapheme-to-lexeme feedback in the cognitive spelling system, based on the impaired spelling performance of dysgraphic patient CM. The argument relates two features of CM’s spelling. First, letters from prior spelling responses intrude into sub- sequent responses at rates far greater than expected by chance. This letter persistence effect arises at a level of abstract grapheme representations, and apparently results from abnormal persistence of activation. Second, CM makes many formal lexical errors (e.g., carpet ! compute). Analyses revealed that a large proportion of these errors are “true” lexical errors originating in lexical selec- tion, rather than “chance” lexical errors that happen by chance to take the form of words. Additional analyses demonstrated that CM’s true lexical errors exhibit the letter persistence effect. We argue that this finding can be understood only within a functional architecture in which activation from the grapheme level feeds back to the lexeme level, thereby influencing lexical selection. INTRODUCTION a brain-damaged patient with an acquired spelling deficit, arguing from his error pattern that Like other forms of language processing, written the cognitive system for written word produc- word production implicates multiple levels of tion includes feedback connections from gra- representation, including semantic, orthographic pheme representations to orthographic lexeme lexeme, grapheme, and allograph levels. -

ON SOME CATEGORIES for DESCRIBING the SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami
ON SOME CATEGORIES FOR DESCRIBING THE SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami 1. A lexeme is the minimum unit that carries meaning. Thus a lexeme can be a "word" as well as an affix (i.e., something smaller than a word) or an idiom (i.e,, something larger than a word). 2. A sememe is a unit of meaning that can be realized as a single lexeme. It is defined as a structure constituted by those features having distinctive functions (i.e., serving to distinguish the sememe in question from other semernes that contrast with it).' A question that arises at this point is whether or not one lexeme always corresponds to just one serneme and no more. Three theoretical positions are foreseeable: (I) one which holds that one lexeme always corresponds to just one sememe and no more, (2) one which holds that one lexeme corresponds to an indefinitely large number of sememes, and (3) one which holds that one lexeme corresponds to a certain limited number of sememes. These three positions wiIl be referred to as (1) the "Grundbedeutung" theory, (2) the "use" theory, and (3) the "polysemy" theory, respectively. The Grundbedeutung theory, however attractive in itself, is to be rejected as unrealistic. Suppose a preliminary analysis has revealed that a lexeme seems to be used sometimes in an "abstract" sense and sometimes in a "concrete" sense. In order to posit a Grundbedeutung under such circumstances, it is to be assumed that there is a still higher level at which "abstract" and "concrete" are neutralized-this is certainly a theoretical possibility, but it seems highly unlikely and unrealistic from a psychological point of view. -

A Brief Description of Consonants in Modern Standard Arabic
Linguistics and Literature Studies 2(7): 185-189, 2014 http://www.hrpub.org DOI: 10.13189/lls.2014.020702 A Brief Description of Consonants in Modern Standard Arabic Iram Sabir*, Nora Alsaeed Al-Jouf University, Sakaka, KSA *Corresponding Author: [email protected] Copyright © 2014 Horizon Research Publishing All rights reserved. Abstract The present study deals with “A brief Modern Standard Arabic. This study starts from an description of consonants in Modern Standard Arabic”. This elucidation of the phonetic bases of sounds classification. At study tries to give some information about the production of this point shows the first limit of the study that is basically Arabic sounds, the classification and description of phonetic rather than phonological description of sounds. consonants in Standard Arabic, then the definition of the This attempt of classification is followed by lists of the word consonant. In the present study we also investigate the consonant sounds in Standard Arabic with a key word for place of articulation in Arabic consonants we describe each consonant. The criteria of description are place and sounds according to: bilabial, labio-dental, alveolar, palatal, manner of articulation and voicing. The attempt of velar, uvular, and glottal. Then the manner of articulation, description has been made to lead to the drawing of some the characteristics such as phonation, nasal, curved, and trill. fundamental conclusion at the end of the paper. The aim of this study is to investigate consonant in MSA taking into consideration that all 28 consonants of Arabic alphabets. As a language Arabic is one of the most 2. -
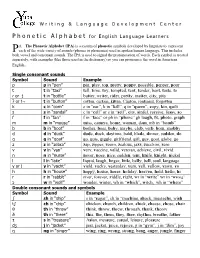
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Vowel Acoustics Reliably Differentiate Three Coronal Stops of Wubuy Across Prosodic Contexts
Vowel acoustics reliably differentiate three coronal stops of Wubuy across prosodic contexts Rikke L. BundgaaRd-nieLsena, BRett J. BakeRb, ChRistian kRoosa, MaRk haRveyc and CatheRine t. Besta,d aMARCS Auditory Laboratories, University of Western Sydney bSchool of Languages and Linguistics, University of Melbourne cSchool of Humanities and Social Science, University of Newcastle dHaskins Laboratories, New Haven Abstract The present study investigates the acoustic differentiation of three coronal stops in the indigenous Australian language Wubuy. We test independent claims that only VC (vowel-into-consonant) transitions provide robust acoustic cues for retroflex as compared to alveolar and dental coronal stops, with no differentiating cues among these three coronal stops evident in CV (consonant-into-vowel) transitions. The four-way stop distinction /t, t̪ , ʈ, c/ in Wubuy is contrastive word-initially (Heath 1984) and by implication utterance-initially, i.e., in CV-only contexts, which suggests that acoustic differentiation should be expected to occur in the CV transitions of this language, including in initial positions. Therefore, we examined both VC and CV formant transition information in the three target coronal stops across VCV (word-internal), V#CV (word-initial but utterance-medial) and ##CV (word- and utterance-initial), for /a / vowel contexts, which provide the optimal environment for investigating formant transitions. Results confirm that these coro- nal contrasts are maintained in the CVs in this vowel context, and in all three posi- tions. The patterns of acoustic differences across the three syllable contexts also provide some support for a systematic role of prosodic boundaries in influencing the degree of coronal stop differentiation evident in the vowel formant transitions. -

LT3212 Phonetics Assignment 4 Mavis, Wong Chak Yin
LT3212 Phonetics Assignment 4 Mavis, Wong Chak Yin Essay Title: The sound system of Japanese This essay aims to introduce the sound system of Japanese, including the inventories of consonants, vowels, and diphthongs. The phonological variations of the sound segments in different phonetic environments are also included. For the illustration, word examples are given and they are presented in the following format: [IPA] (Romaji: “meaning”). Consonants In Japanese, there are 14 core consonants, and some of them have a lot of allophonic variations. The various types of consonants classified with respect to their manner of articulation are presented as follows. Stop Japanese has six oral stops or plosives, /p b t d k g/, which are classified into three place categories, bilabial, alveolar, and velar, as listed below. In each place category, there is a pair of plosives with the contrast in voicing. /p/ = a voiceless bilabial plosive [p]: [ippai] (ippai: “A cup of”) /b/ = a voiced bilabial plosive [b]: [baɴ] (ban: “Night”) /t/ = a voiceless alveolar plosive [t]: [oto̞ ːto̞ ] (ototo: “Brother”) /d/ = a voiced alveolar plosive [d]: [to̞ mo̞ datɕi] (tomodachi: “Friend”) /k/ = a voiceless velar plosive [k]: [kaiɰa] (kaiwa: “Conversation”) /g/ = a voiced velar plosive [g]: [ɡakɯβsai] (gakusai: “Student”) Phonetically, Japanese also has a glottal stop [ʔ] which is commonly produced to separate the neighboring vowels occurring in different syllables. This phonological phenomenon is known as ‘glottal stop insertion’. The glottal stop may be realized as a pause, which is used to indicate the beginning or the end of an utterance. For instance, the word “Japanese money” is actually pronounced as [ʔe̞ ɴ], instead of [je̞ ɴ], and the pronunciation of “¥15” is [dʑɯβːɡo̞ ʔe̞ ɴ]. -

UC Berkeley Dissertations, Department of Linguistics
UC Berkeley Dissertations, Department of Linguistics Title The Aeroacoustics of Nasalized Fricatives Permalink https://escholarship.org/uc/item/00h9g9gg Author Shosted, Ryan K Publication Date 2006 eScholarship.org Powered by the California Digital Library University of California The Aeroacoustics of Nasalized Fricatives by Ryan Keith Shosted B.A. (Brigham Young University) 2000 M.A. (University of California, Berkeley) 2003 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the GRADUATE DIVISION of the UNIVERSITY OF CALIFORNIA, BERKELEY Committee in charge: John J. Ohala, Chair Keith Johnson Milton M. Azevedo Fall 2006 The dissertation of Ryan Keith Shosted is approved: Chair Date Date Date University of California, Berkeley Fall 2006 The Aeroacoustics of Nasalized Fricatives Copyright 2006 by Ryan Keith Shosted 1 Abstract The Aeroacoustics of Nasalized Fricatives by Ryan Keith Shosted Doctor of Philosophy in Linguistics University of California, Berkeley John J. Ohala, Chair Understanding the relationship of aerodynamic laws to the unique geometry of the hu- man vocal tract allows us to make phonological and typological predictions about speech sounds typified by particular aerodynamic regimes. For example, some have argued that the realization of nasalized fricatives is improbable because fricatives and nasals have an- tagonistic aerodynamic specifications. Fricatives require high pressure behind the suprala- ryngeal constriction as a precondition for high particle velocity. Nasalization, on the other hand, vents back pressure by allowing air to escape through the velopharyngeal orifice. This implies that an open velopharyngeal port will reduce oral particle velocity, thereby potentially extinguishing frication. By using a mechanical model of the vocal tract and spoken fricatives that have undergone coarticulatory nasalization, it is shown that nasal- ization must alter the spectral characteristics of fricatives, e.g. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

The Phonological Role in English Pronunciation Instruction
The Phonological Role in English Pronunciation Instruction Kwan-Young Oh Yosu National University The purpose of this paper is to demonstrate a more effective way for improving Korean students’ pronunciation relating to the phonological role in English pronunciation instruction. Three different aspects of pronunciation will be considered: general, syllabic, prosodic aspects relating to the two language differences, as well as the teaching of pronunciation in the classroom. In addition to that, from the American-style language training of students, what problems the students encounter will be demonstrated. Hence, this will make clear what problems the Korean students face when attempting to speak English. Furthermore, an alternative for teaching English pronunciation, which makes use of a new program students can access on the internet regardless of their place and space, will be suggested. Giving consideration to the result of this study suggests that it is necessary to develop this methodology of instruction further. 1. Difficulties in teaching English Pronunciation to Korean Students 1.1. Language Differences in both English and Korean One thing that most Korean students have difficulty with is their pronunciation of the phonemic aspects; several sounds existing in English, consonants and vowels, that aren’t in Korean phonemes. From this respect, admittedly, it is hard for Korean students to perceive and pronounce non-Korean sounds. For example, when Korean students try to pronounce the sound /b/, they almost always mispronounce it as /p/ because the sound /b/ isn’t in Korean. 1.1.1. Phonemic aspects Now, if we compare the two languages regarding the articulation of consonants, we can definitely see the articulatory difference. -

For the Third Case. Fairly Detailed Phonetic and Distributional Data Are Also Utilized
nof:J1611tNT nmsohlw ED 030 098 AL 001 858 By-Moskowitz, Arlene I. The Two-Year -Old Stage in the Acquisition of English Phonology. Spons Agency-American Cuunoi of Learned Societies, New Yofk, N.Y.; Social Science Research Council, Washington, D.C. Pub Date 29 Dec 68 Note-24p.. Slightly expanded verzion of i. paper presented at the 43rd Annual Meeting of the Linguistic Society of America, New York City, December 29, 1968. EDRS Price MF-1025 HC-$1.30 Descriptors -*Child Language, Consonants, Distinctive Features, Early Childhood, Enghsh. Language Development, Language Learning Levels, Language Patterns, Language Typology, Phonemes. Phonetic Analysis. ePhonogi,gy, Vowels The phonologies of three English-speaking children at approximately two years of age are examined. Two of the analyses are based on pOblished:studies. the third is based on observations and recordings made by the author. Summary statements on phonemic inventories and on correspondences with the adult model are presented. For the third case. fairly detailed phonetic and distributional data are also utilized. The paper attempts to draw conclusions about typical difficulties of phonological development at this stage and possible strategies used by children in attaining the adult norms. (Author/JD) . r U.S. DEPARTMENT Of HEALTH, EDUCATION & WELFARE OFFICE Of EDUCATION TINS DOCUMENT HAS BEEN REPRODUCED EXACTLY AS RECEIVEDFROM DIE PERSON OR 016ANIZATION 0116INATIN6 IT.POINTS Of VIEW OR OPINIONS STAB DO NOT IIKESSAMLY REPRESENT OFFICIAL OFRCEOf EDUCATION POSITION OR POUCY. TR TWO*TIAMOLD SUM IN Mg ACQUISITION orMUSHPHOMOLO0Y1 Arlen* I. Noskovitz AL 001858 0. Introduction. It is a widely held view among linguists and paycholinguists that the phonology of a child's speech at any 2 ilage during the acquisition process is structured. -

Unit 2 Structures Handout.Pdf
2. The definition of a language as a structure of structures 2.1. Phonetics and phonology Relevance for studying language in its natural or primary medium: oral sounds rather than written symbols. Phonic medium: the range of sounds produced by the speech organs insofar as the play a role in language Speech sounds: Individual sounds within that range Phonetics is the study of the phonic medium: The study of the production, transmission, and reception of human sound-making used in speech. e.g. classification of sounds as voiced vs voiceless: /b/ vs /p/ Phonology is the study of the phonic medium not in itself but in relation with language. e.g. application of voice to the explanation of differences within the system of language: housen vs housev usen vs usev 2.1.1. Phonetics It is usually divided into three branches which study the phonic medium from three points of view: Articulatory phonetics: speech sounds according to the way in which they are produced by the speech organs. Acoustic phonetics: speech sounds according to the physical properties of their sound-waves. Auditory phonetics: speech sounds according to their perception and identification. Articulatory phonetics has the longest tradition, and its progress in the 19th century contributed a standardize and internationally accepted system of phonetic transcription: the origins of the International Phonetic Alphabet used today and relying on sound symbols and diacritics. It studies production in relation with the vocal tract, i.e., organs such as: lungs trachea or windpipe, containing: larynx vocal folds glottis pharyngeal cavity nose mouth, containing fixed organs: teeth and teeth ridge hard palate pharyngeal wall mobile organs: lips tongue soft palate jaw According to their function and participation, sounds may take several features: Voice: voiced vs voiceless sounds, according to the participation of the vocal folds e.g. -

Why Is Pronunciation So Difficult to Learn?
www.ccsenet.org/elt English Language Teaching Vol. 4, No. 3; September 2011 Why is Pronunciation So Difficult to Learn? Abbas Pourhossein Gilakjani (Corresponding author) School of Educational Studies, Universiti Sains Malaysia, Malaysia 3A-05-06 N-Park Jalan Batu Uban 11700 Gelugor Pulau Pinang Malaysia Tel: 60-174-181-660 E-mail: [email protected] Mohammad Reza Ahmadi School of Educational Studies, Universiti Sains Malaysia, Malaysia 3A-05-06 N-Park Alan Batu Uban 1700 Gelugor Pulau Pinang Malaysia Tel: 60-175-271-870 E-mail: [email protected] Received: January 8, 2011 Accepted: March 21, 2011 doi:10.5539/elt.v4n3p74 Abstract In many English language classrooms, teaching pronunciation is granted the least attention. When ESL teachers defend the poor pronunciation skills of their students, their arguments could either be described as a cop-out with respect to their inability to teach their students proper pronunciation or they could be regarded as taking a stand against linguistic influence. If we learn a second language in childhood, we learn to speak it fluently and without a ‘foreign accent’; if we learn in adulthood, it is very unlikely that we will attain a native accent. In this study, the researchers first review misconceptions about pronunciation, factors affecting the learning of pronunciation. Then, the needs of learners and suggestions for teaching pronunciation will be reviewed. Pronunciation has a positive effect on learning a second language and learners can gain the skills they need for effective communication in English. Keywords: Pronunciation, Learning, Teaching, Misconceptions, Factors, Needs, Suggestions 1. Introduction General observation suggests that it is those who start to learn English after their school years are most likely to have serious difficulties in acquiring intelligible pronunciation, with the degree of difficulty increasing markedly with age.