Phonetics in Phonology 1. Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Journal of Phonetics (1984) 12: 345-354
In: Journal of Phonetics (1984) 12: 345-354. On the nature of labial velar shift Raymond Hickey Bonn University Abstract Labial velar shift is a common diachronic occurrence in various languages which in recent works on phonology has been captured by the reintroduction of the Jakobsonian feature [grave]. The type of shift involved, the form and direction it takes is a matter which has received insufficient attention. The present study is an attempt to account for this shift by viewing manifestations of it in Romance, Celtic, Germanic, Slavic and Uralic. The essential difference between lenition and labial velar shift is emphasized and the notion of favouring conditions for the shift (the phonotactic environment of the segments involved) is introduced. In all cases the acoustic (and hence autditory) similarity of the segments which undergo shifting is seen to be the triggering factor. It is by now commonplace to maintain that a phonological framework must take cognizance of, and provide notational means for describing, the interrelatedness of labial and velar segments. Evidence abounds in a variety of languages (see below) that labials and velars relate in a manner which say labials and dentals do not. In early distinctive feature theory (Jakobson and Halle, 1956, p. 43) this fact could be captured by the use of the feature [grave]. It was also quickly recognized by linguists after the publication of Chomsky and Halle (1968) that the abandoning of the feature [grave] constituted a loss in generalization (Ladefoged, 1972, p.44; Hyman, 1973; Lass and Anderson, 1975, p.187). However, in those works where the necessity for the feature [grave] is insisted upon (Davidsen-Nielsen and Ørum, 1978, p.201; Sommerstein, 1977, p. -

At the Juncture of Prosody, Phonology, and Phonetics – the Interaction of Phrasal and Syllable Structure in Shaping the Timing of Consonant Gestures∗
At the juncture of prosody, phonology, and phonetics – the interaction of phrasal and syllable structure in shaping the timing of consonant gestures∗ Dani Byrd and Susie Choi The Laboratory Phonology research paradigm has established that abstract phonological structure has direct reflections in the spatiotemporal details of speech production. Past exploration of the complex relationship between lin- guistic structural properties and articulation has resulted in a softening of a severance between phonetics and phonology, which in recent years has begun to likewise encompass the phonetics-prosody interface. The abstract organiza- tion not only of words, but also of phrases, has a complex and rich effect on the articulatory details of speech production. This paper considers how phono- logical and prosodic structure interact in shaping the temporal realization of consonant sequences. Specifically, we examine the influence on articulatory timing of syllable structure effects in onset, coda, and heterosyllabic positions, and prosodic effects in the vicinity of a variety of phrase boundary conditions that grade in strength. Simultaneously, this work seeks to test and refine the π- gesture theoretical model of prosodic representation in speech production (Byrd & Saltzman 2003). 1. Introduction Three of the founders of Laboratory Phonology – Beckman, Ladd, and Pierre- humbert – describe its research paradigm as “involving the cooperation of peo- ple...whoshareaconcernforstrengtheningfoundations of phonology through improved methodology, explicit modeling, and cumulation of results” (Pier- rehumbert, Beckman, and Ladd 2001). Over the preceding nine Laboratory Phonology conferences, leading research in linguistic speech experimentation has clearly established that many aspects of abstract phonological structure are directly reflected in the spatiotemporal details of speech production. -
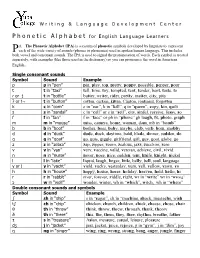
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Effects of Instruction on L2 Pronunciation Development: a Synthesis of 15 Quasiexperimental Intervention Studies
RESEARCH ISSUES TESOL Quarterly publishes brief commentaries on aspects of qualitative and quantitative research. Edited by CONSTANT LEUNG King’s College London Effects of Instruction on L2 Pronunciation Development: A Synthesis of 15 Quasi- Experimental Intervention Studies KAZUYA SAITO Waseda University Tokyo, Japan doi: 10.1002/tesq.67 & Over the past 25 years second language (L2) acquisition research has paid considerable attention to the effectiveness of instruction on L2 morphosyntax development, and the findings of relevant empirical studies have been extensively summarized using narrative review meth- ods (e.g., Ellis, 2002) as well as meta-analytic review methods (e.g., Spada & Tomita, 2010). These researchers have reached a consensus that (a) integrating language focus into meaning-oriented classrooms is more effective than a purely naturalistic approach, and (b) contextu- alized grammar teaching methods (e.g., focus-on-form instruction, form-focused instruction) is more effective than decontexualized gram- mar teaching methods (e.g., focus-on-formS instruction, grammar- translation method). What is surprising in this vein of L2 acquisition studies, however, is the lack of research in the area of L2 pronuncia- tion development. Pronunciation teaching has been notorious for its overdependence on decontextualized practice such as mechanical drills and repetition, reminiscent of the audiolingual teaching meth- ods of several decades ago (for discussion, see Celce-Murcia, Brinton, Goodwin, & Griner, 2010). Furthermore, very few language teachers actually receive adequate training in the specific area of pronunciation teaching (Foote, Holtby, & Derwing, 2011). 842 TESOL QUARTERLY Vol. 46, No. 4, December 2012 © 2012 TESOL International Association In recent years, several researchers have made strong calls for research on teaching for intelligible (rather than native-like) pronunciation. -

Why Is Pronunciation So Difficult to Learn?
www.ccsenet.org/elt English Language Teaching Vol. 4, No. 3; September 2011 Why is Pronunciation So Difficult to Learn? Abbas Pourhossein Gilakjani (Corresponding author) School of Educational Studies, Universiti Sains Malaysia, Malaysia 3A-05-06 N-Park Jalan Batu Uban 11700 Gelugor Pulau Pinang Malaysia Tel: 60-174-181-660 E-mail: [email protected] Mohammad Reza Ahmadi School of Educational Studies, Universiti Sains Malaysia, Malaysia 3A-05-06 N-Park Alan Batu Uban 1700 Gelugor Pulau Pinang Malaysia Tel: 60-175-271-870 E-mail: [email protected] Received: January 8, 2011 Accepted: March 21, 2011 doi:10.5539/elt.v4n3p74 Abstract In many English language classrooms, teaching pronunciation is granted the least attention. When ESL teachers defend the poor pronunciation skills of their students, their arguments could either be described as a cop-out with respect to their inability to teach their students proper pronunciation or they could be regarded as taking a stand against linguistic influence. If we learn a second language in childhood, we learn to speak it fluently and without a ‘foreign accent’; if we learn in adulthood, it is very unlikely that we will attain a native accent. In this study, the researchers first review misconceptions about pronunciation, factors affecting the learning of pronunciation. Then, the needs of learners and suggestions for teaching pronunciation will be reviewed. Pronunciation has a positive effect on learning a second language and learners can gain the skills they need for effective communication in English. Keywords: Pronunciation, Learning, Teaching, Misconceptions, Factors, Needs, Suggestions 1. Introduction General observation suggests that it is those who start to learn English after their school years are most likely to have serious difficulties in acquiring intelligible pronunciation, with the degree of difficulty increasing markedly with age. -

Phonological Typology, Rhythm Types and the Phonetics-Phonology Interface
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2012 Phonological typology, rhythm types and the phonetics-phonology interface. A methodological overview and three case studies on Italo-Romance dialects Schmid, Stephan Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-73782 Book Section Published Version Originally published at: Schmid, Stephan (2012). Phonological typology, rhythm types and the phonetics-phonology interface. A methodological overview and three case studies on Italo-Romance dialects. In: Ender, Andrea; Leemann, Adrian; Wälchli, Bernhard. Methods in contemporary linguistics. Berlin: de Gruyter Mouton, 45-68. Phonological typology, rhythm types and the phonetics-phonology interface. A methodological overview and three case studies on Italo- Romance dialects Stephan Schmid 1. Introduction Phonological typology has mainly concentrated on phoneme inventories and on implicational universals, whereas the notion of ‘language type’ ap- pears to be less appealing from a phonological perspective. An interesting candidate for establishing language types on the grounds of phonological or phonetic criteria would have come from the dichotomy of ‘stress-timing’ vs. ‘syllable-timing’, if instrumental research carried out by a number of phoneticians had not invalidated the fundamental claim of the so-called ‘isochrony hypothesis’. Nevertheless, the idea of classifying languages according to their rhythmic properties has continued to inspire linguists and phoneticians, giving rise to two diverging methodological perspectives. The focus of the first framework mainly lies on how phonological processes relate to prosodic domains, in particular to the syllable and to the phonolog- ical word. -

Kenneth J. De Jong Curriculum Vita
Kenneth J. de Jong Department of Linguistics 859 Ballantine Hall Indiana University Bloomington, Ind. 47405 Work: (812) 856-1307; [email protected] Curriculum Vita January 12, 2017 Education Ph.D., August, 1991. (MA, June, 1987). Linguistics, Ohio State University, Columbus, Ohio. Specializations: Phonetics, Laboratory Phonology, Phonological Theory, Speech Production, Second Language Acquisition, and Language Change. Dissertation: The Oral Articulation of English Stress Accent. B.A., June, 1984. English, Calvin College, Grand Rapids, Michigan. Academic Appointments Professor, Department of Linguistics and Department of Cognitive Science, Indiana University, 2010 - date Adjunct Professor, Department of Second Languages Studies, Indiana University, 2010 - date. Associate Professor, Department of Linguistics and Department of Cognitive Science, Indiana University, 2002 – 2010 Adjunct Associate Professor, Department of Second Languages Studies, Indiana University, 2006 – 2010. Assistant Professor, Department of Linguistics and Cognitive Science Program, Indiana University, 1995 - 2002 Visiting Assistant Professor, Department of Linguistics, Indiana University, 1994 - 1995. Research Linguist, Eloquent Technology, Inc., Ithaca, N.Y. 1993 - 1994. Visiting Scholar, Department of Modern Languages and Linguistics, Cornell University, 1993 - 1994. NIH Post-doctoral Fellow, Phonetics Laboratory, University of California, Los Angeles, 1991 - 1993. Visiting Assistant Professor, Department of Linguistics, University of California, Los Angeles; 1992, -

February 2014 JOSEPH CURTIS SALMONS 818 Van Hise Hall
February 2014 JOSEPH CURTIS SALMONS 818 Van Hise Hall [email protected] Department of German tel. 608.262.2192 1220 Linden Dr. 608.262.8180 University of Wisconsin fax 608.262.7949 Madison, WI 53706 www.joseph-salmons.net EDUCATION and APPOINTMENTS 2015 American Dialect Society Professor, Linguistic Society of America Summer Institute, University of Chicago. 2006-2010, Fall 2012 Director, Center for the Study of Upper Midwestern Cultures. 2012-2015 Affiliated faculty, Department of Scandinavian Studies, University of Wisconsin – Madison. 2011-2016 Wisconsin Alumni Research Foundation Named Professorship: Lester W.J. “Smoky” Seifert Professor of Germanic Linguistics. 2008- Adjunct, Center for the Advanced Study of Language (CASL), University of Maryland. 2007 Adjunct Professor, Speech and Hearing Science, The Ohio State University. 2000-2006 Co-director, Center for the Study of Upper Midwestern Cultures. 1999-2002 Affiliated faculty, Department of Linguistics, University of Wisconsin – Madison. 1997- Professor of German, University of Wisconsin – Madison. 1997-2002 Director, Max Kade Institute for German-American Studies. 1995-1997 Associate Professor of German, University of Wisconsin – Madison. 1993 (Fall) Visiting Associate Professor, German, University of Wisconsin – Madison. 1991-1995 Associate Professor, German and Linguistics, Purdue University. 1985-1991 Assistant Professor, German and Linguistics, Purdue University. 1978-1984 PhD, University of Texas, Austin. German (Germanic Linguistics). 1980-1981 Christian-Albrechts Universität Kiel. DAAD Fellowship. 1974-1978 BA, University of North Carolina, Charlotte. Philosophy. MAJOR SERVICE 2014-2017 Nominating Committee, Linguistic Society of America. 2014- Editorial advisory board, Amsterdamer Beiträge zur älteren Germanistik. 2012- Co-editor, with Nils Langer, Stephan Elspaß and Wim Vandenbussche. Historical Sociolinguistics: Studies on Language and Society in the Past. -

FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS on THREE CONTINENTS a Dissertation Submitted to the Facu
FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS A Dissertation submitted to the Faculty of the Graduate School of Arts and Sciences of Georgetown University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics By Sheena Shah, M.S. Washington, DC May 14, 2013 Copyright 2013 by Sheena Shah All Rights Reserved ii FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS Sheena Shah, M.S. Thesis Advisors: Alison Mackey, Ph.D. Natalie Schilling, Ph.D. ABSTRACT This dissertation examines the causes behind the differences in proficiency in the North Indian language Gujarati among heritage learners of Gujarati in three diaspora locations. In particular, I focus on whether there is a relationship between heritage language ability and ethnic and cultural identity. Previous studies have reported divergent findings. Some have found a positive relationship (e.g., Cho, 2000; Kang & Kim, 2011; Phinney, Romero, Nava, & Huang, 2001; Soto, 2002), whereas others found no correlation (e.g., C. L. Brown, 2009; Jo, 2001; Smolicz, 1992), or identified only a partial relationship (e.g., Mah, 2005). Only a few studies have addressed this question by studying one community in different transnational locations (see, for example, Canagarajah, 2008, 2012a, 2012b). The current study addresses this matter by examining data from members of the same ethnic group in similar educational settings in three multi-ethnic and multilingual cities. The results of this study are based on a survey consisting of questionnaires, semi-structured interviews, and proficiency tests with 135 participants. Participants are Gujarati heritage language learners from the U.K., Singapore, and South Africa, who are either current students or recent graduates of a Gujarati School. -

Phones and Phonemes
NLPA-Phon1 (4/10/07) © P. Coxhead, 2006 Page 1 Natural Language Processing & Applications Phones and Phonemes 1 Phonemes If we are to understand how speech might be generated or recognized by a computer, we need to study some of the underlying linguistic theory. The aim here is to UNDERSTAND the theory rather than memorize it. I’ve tried to reduce and simplify as much as possible without serious inaccuracy. Speech consists of sequences of sounds. The use of an instrument (such as a speech spectro- graph) shows that most of normal speech consists of continuous sounds, both within words and across word boundaries. Speakers of a language can easily dissect its continuous sounds into words. With more difficulty, they can split words into component sounds, or ‘segments’. However, it is not always clear where to stop splitting. In the word strip, for example, should the sound represented by the letters str be treated as a unit, be split into the two sounds represented by st and r, or be split into the three sounds represented by s, t and r? One approach to isolating component sounds is to look for ‘distinctive unit sounds’ or phonemes.1 For example, three phonemes can be distinguished in the word cat, corresponding to the letters c, a and t (but of course English spelling is notoriously non- phonemic so correspondence of phonemes and letters should not be expected). How do we know that these three are ‘distinctive unit sounds’ or phonemes of the English language? NOT from the sounds themselves. A speech spectrograph will not show a neat division of the sound of the word cat into three parts. -

English Teachers' Mastery of the English Aspiration And
Arina Isti’anah - English Teachers’ Mastery of the English Aspiration and Stress Rules ENGLISH TEACHERS’ MASTERY OF THE ENGLISH ASPIRATION AND STRESS RULES Arina Isti’anah Sanata Dharma University [email protected] Abstract This paper tries to observe the English teachers’ awareness and representation of the English aspiration and stress rules. The research purposes to find out whether or not the teachers are aware of the English aspiration and stress rules, and to find out how the teachers represent the English aspiration and stress rules. Based on the analysis, it can be concluded that the teachers’ awareness of the English aspiration and stress rules is very low. It is indicated with the percentage which equals to 44% and 48% for English aspiration and stress rules. In representing the English aspiration and stress rules, the teachers face the problems in producing aspiration in the pronunciation, placing the right stress and pronouncing three and four X in the coda position. There are two reasons affecting the teachers’ awareness of the English aspiration and stress rules namely exposure and L1 influence. Artikel ini bertujuan untuk meneliti kesadaran dan representasi aturan aspirasi dan tekanan oleh guru bahasa Inggris. Penelitian ini bertujuan untuk menjelaskan apakah guru bahasa Inggris mempunyai kesadaran atas aturan aspirasi dan tekanan dalam bahasa Inggris, dan untuk menunjukkan bagaimana guru Bahasa Inggris mewujudkan aturan aspirasi dan tekanan dalam pelafalan mereka. Berdasarkan analisis yang dilakukan, dapat disimpulkan bahwa kesadaran guru Bahasa Inggris atas aturan aspirasi dan tekanan dalam Bahasa Inggris masih sangat rendah. Hal tersebut ditunjukkan oleh rendahnya prosentase dalam perwujudan aturan aspirasi dan tekanan: 44% dan 48%. -

A Deep Generative Model of Vowel Formant Typology
A Deep Generative Model of Vowel Formant Typology Ryan Cotterell and Jason Eisner Department of Computer Science Johns Hopkins University, Baltimore MD, 21218 ryan.cotterell,eisner @jhu.edu { } Abstract and its goal should be the construction of a univer- sal prior over potential languages. A probabilistic What makes some types of languages more approach does not rule out linguistic systems com- probable than others? For instance, we know pletely (as long as one’s theoretical formalism can that almost all spoken languages contain the vowel phoneme /i/; why should that be? The describe them at all), but it can position phenomena field of linguistic typology seeks to answer on a scale from very common to very improbable. these questions and, thereby, divine the mech- Probabilistic modeling also provides a discipline anisms that underlie human language. In our for drawing conclusions from sparse data. While work, we tackle the problem of vowel system we know of over 7000 human languages, we have typology, i.e., we propose a generative proba- some sort of linguistic analysis for only 2300 of bility model of which vowels a language con- them (Comrie et al., 2013), and the dataset used in tains. In contrast to previous work, we work di- rectly with the acoustic information—the first this paper (Becker-Kristal, 2010) provides simple two formant values—rather than modeling dis- vowel data for fewer than 250 languages. crete sets of phonemic symbols (IPA). We de- Formants are the resonant frequencies of the hu- velop a novel generative probability model and man vocal tract during the production of speech report results based on a corpus of 233 lan- sounds.