Spoken Indian Language Identification: a Review of Features and Databases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Jefferson: Education As the Antidote to “Failed Revolutions”
1 | MESALC NEWSLETTER Volume 7, Issue 1 | Spring 2018 Jefferson: Education as the Antidote Jefferson: to “Failed Revolutions” ................. 1 Education as the Antidote to J-Term in Kerala: India in Global History .......................................... 3 “Failed Revolutions” Welcome to MESALC: New Hindi Instructor ...................................... 4 New Fall 2018 Courses ................. 5 New Faculty Publications ............. 6 Sajedeh Hosseini: Serving as a TA at Mr. Jefferson’s School Brightened my Days ......................................... 8 Mehr Farooqi: A Night of Ghazals “The Arab Spring” now seems to many but a distant and Sufi Kalam ............................. 9 memory, a chimera, a false hope, one too painful to remember, revisit, or even study seriously. Mr. Jefferson would beg to Janaezjah Ryder: From Pune to differ. UVA ............................................... 10 Jefferson’s words on revolution did not stop with his crafting of America’s Declaration of Independence. During the Hanadi Al-Samman: The Aesthetics half century that followed, Jefferson avidly followed and of Trauma ...................................... 11 commented upon revolutionary developments around the world. While Ambassador to France, Jefferson warmly supported the Aenon Moose’s Speech at 2017 emerging French Revolution, counseling moderation and MESALC Graduation Ceremony .. 12 advising the Marquis de Lafayette on France’s Declaration of the Rights of Man. Thomas Jefferson Makes his Debut As France’s revolution struggled, Jefferson as US Secretary of State offered encouragement to French friends and on Arabic TV ................................. 13 intellectuals. To the Duchess d’Auville, on April 2, 1790, Jefferson wrote, “You have had some checks, some horrors since st Envisioning 21 Century Middle I left you; but the way to heaven, you know, has always been East & South Asian Studies ......... -

Using 'North Wind and the Sun' Texts to Sample Phoneme Inventories
Blowing in the wind: Using ‘North Wind and the Sun’ texts to sample phoneme inventories Louise Baird ARC Centre of Excellence for the Dynamics of Language, The Australian National University [email protected] Nicholas Evans ARC Centre of Excellence for the Dynamics of Language, The Australian National University [email protected] Simon J. Greenhill ARC Centre of Excellence for the Dynamics of Language, The Australian National University & Department of Linguistic and Cultural Evolution, Max Planck Institute for the Science of Human History [email protected] Language documentation faces a persistent and pervasive problem: How much material is enough to represent a language fully? How much text would we need to sample the full phoneme inventory of a language? In the phonetic/phonemic domain, what proportion of the phoneme inventory can we expect to sample in a text of a given length? Answering these questions in a quantifiable way is tricky, but asking them is necessary. The cumulative col- lection of Illustrative Texts published in the Illustration series in this journal over more than four decades (mostly renditions of the ‘North Wind and the Sun’) gives us an ideal dataset for pursuing these questions. Here we investigate a tractable subset of the above questions, namely: What proportion of a language’s phoneme inventory do these texts enable us to recover, in the minimal sense of having at least one allophone of each phoneme? We find that, even with this low bar, only three languages (Modern Greek, Shipibo and the Treger dialect of Breton) attest all phonemes in these texts. -

Linguistic Survey of India Bihar
LINGUISTIC SURVEY OF INDIA BIHAR 2020 LANGUAGE DIVISION OFFICE OF THE REGISTRAR GENERAL, INDIA i CONTENTS Pages Foreword iii-iv Preface v-vii Acknowledgements viii List of Abbreviations ix-xi List of Phonetic Symbols xii-xiii List of Maps xiv Introduction R. Nakkeerar 1-61 Languages Hindi S.P. Ahirwal 62-143 Maithili S. Boopathy & 144-222 Sibasis Mukherjee Urdu S.S. Bhattacharya 223-292 Mother Tongues Bhojpuri J. Rajathi & 293-407 P. Perumalsamy Kurmali Thar Tapati Ghosh 408-476 Magadhi/ Magahi Balaram Prasad & 477-575 Sibasis Mukherjee Surjapuri S.P. Srivastava & 576-649 P. Perumalsamy Comparative Lexicon of 3 Languages & 650-674 4 Mother Tongues ii FOREWORD Since Linguistic Survey of India was published in 1930, a lot of changes have taken place with respect to the language situation in India. Though individual language wise surveys have been done in large number, however state wise survey of languages of India has not taken place. The main reason is that such a survey project requires large manpower and financial support. Linguistic Survey of India opens up new avenues for language studies and adds successfully to the linguistic profile of the state. In view of its relevance in academic life, the Office of the Registrar General, India, Language Division, has taken up the Linguistic Survey of India as an ongoing project of Government of India. It gives me immense pleasure in presenting LSI- Bihar volume. The present volume devoted to the state of Bihar has the description of three languages namely Hindi, Maithili, Urdu along with four Mother Tongues namely Bhojpuri, Kurmali Thar, Magadhi/ Magahi, Surjapuri. -

Telugu Wordnet
Telugu WordNet S. Arulmozi Department of Dravidian & Computational Linguistics Dravidian University, Kuppam 517425, India [email protected] Abstract Section 4 gives a statistical account on the synsets developed. The last section This paper describes an attempt to develop Telugu WordNet, particularly construction of summarizes the work. synsets in Telugu language along the lines of Hindi synsets using the expansion approach. 2 The Telugu Language Based on the Hindi WordNet synsets, we assign Telugu synsets manually using the Offline Tool Telugu belongs to the South Central Dravidian Interface. We share the challenges faced in the subgroup of the Dravidian family of languages. construction of core synsets from Hindi into It has recorded history from 6th Century A.D. Telugu language. A brief account on Telugu th language and its notable features are also and literary history dating back to 11 Century provided. A.D. It has been recently awarded the Classical Status. It is the second most spoken language 1 Introduction after Hindi in India. Telugu has been the language of choice for lyrical compositions for WordNet building activities in Dravidian its vowel ending words, rightly called the languages started with the work of Tamil “Italian of the East”. WordNet1 at AU-KBC Research Centre using The vocabulary of Telugu is highly Rajendran’s (2001) ontological classification Sanskritized in addition to the Persian-Arabic of Tamil vocabulary. Work on Dravidian borrowings / kaburu/ `story ’, WordNet (comprising WordNets in four major కబురు జవాబు /javaabu/ `answer ’; Urdu /taraaju/ Dravidian languages, viz. Kannada, తరా灁 Malayalam, Tamil and Telugu) started during a 2 `balance’. It does have cognates in other Workshop held at Chennai in which synsets Dravidan languages such as puli/ `tiger ’, were built for Construction Domain. -
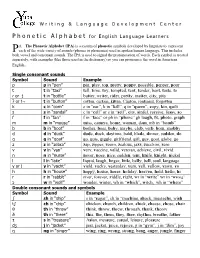
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Diachrony of Ergative Future
• THE EVOLUTION OF THE TENSE-ASPECT SYSTEM IN HINDI/URDU: THE STATUS OF THE ERGATIVE ALGNMENT Annie Montaut INALCO, Paris Proceedings of the LFG06 Conference Universität Konstanz Miriam Butt and Tracy Holloway King (Editors) 2006 CSLI Publications http://csli-publications.stanford.edu/ Abstract The paper deals with the diachrony of the past and perfect system in Indo-Aryan with special reference to Hindi/Urdu. Starting from the acknowledgement of ergativity as a typologically atypical feature among the family of Indo-European languages and as specific to the Western group of Indo-Aryan dialects, I first show that such an evolution has been central to the Romance languages too and that non ergative Indo-Aryan languages have not ignored the structure but at a certain point went further along the same historical logic as have Roman languages. I will then propose an analysis of the structure as a predication of localization similar to other stative predications (mainly with “dative” subjects) in Indo-Aryan, supporting this claim by an attempt of etymologic inquiry into the markers for “ergative” case in Indo- Aryan. Introduction When George Grierson, in the full rise of language classification at the turn of the last century, 1 classified the languages of India, he defined for Indo-Aryan an inner circle supposedly closer to the original Aryan stock, characterized by the lack of conjugation in the past. This inner circle included Hindi/Urdu and Eastern Panjabi, which indeed exhibit no personal endings in the definite past, but only gender-number agreement, therefore pertaining more to the adjectival/nominal class for their morphology (calâ, go-MSG “went”, kiyâ, do- MSG “did”, bola, speak-MSG “spoke”). -

Weakening Processes in the Optimality Framework K.G.Vijayakrishnan1 0
1 Weakening Processes in the Optimality Framework K.G.Vijayakrishnan1 0. Introduction Processes of weakening may be subsumed under two heads namely, the loss of marked feature specifications such as voicing, aspiration, place specification or even the loss of an entire segment, and lenition, exemplifying processes such as voicing, spirantization and sonorization. This paper is an attempt at an analysis of both types of consonantal weakening in the framework of Optimality Theory (henceforth OT). In section 1 we take up the phenomenon of weakening as the loss of feature specification and propose an analysis in terms of prosodic alignment and featural markedness. Section 2 examines lenition in Tamil and proposes a universal constraint ‘Harmonic Sonorancy’ which explains the process as an assimilatory tendency to increase the sonority of consonants in the neighbourhood of sonorants. 1. Weakening as loss of marked feature specification The loss of marked feature specification is the converse of licensing of marked feature specification in prosodically strong positions. Extending the approach to licensing in Smolensky (1995) and Zoll (1998), we show that the distribution of marked feature specification can be accounted for in terms of alignment to prosodic categories. The loss of marked feature specification is widely attested in the following prosodically weak positions. (1) Loss of Marked Feature Specification in Prosodically Weak Positions a) syllable coda well-known examples coda devoicing in German, Dutch, Polish, Catalan lesser known example coda deaspiration in standard colloquial Bangla Standard colloquial Bangla i. lab ~ labher ‘profit ~ genetive’ ii. ghOr‘house’ iii. ciæhi ‘letter’ b) onset of non-head syllables well-known example lack of aspiration of voiceless stops in English lesser known examples lack of aspiration in non-initial stops in the Adilabad dialect of Gondi (Subrahmanian 1968), the Hooghli dialect of Bangla (Ghosh 1995); in both cases aspiration is distinctive in voiceless and voiced stops. -

Phonology of Marathi-Hindi Contact in Eastern Vidarbha
Volume II, Issue VII, November 2014 - ISSN 2321-7065 Change in Progress: Phonology of Marathi-Hindi contact in (astern Vidarbha Rahul N. Mhaiskar Assistant Professor Department of Linguistics, Deccan Collage Post Graduate and Research Institute, Yerwada Pune Abstract Language contact studies the multilingualism and bilingualism in particular language society. There are two division of vidarbha, Nagpur (eastern) and Amaravati (western). It occupied 21.3% of area of the state of Maharashtra. This Area is connected to Hindi speaking states, Madhya Pradesh and Chhattisgarh. When speakers of different languages interact closely, naturally their languages influence each other. There is a close interaction between the speakers of Hindi and local Marathi and they are influencing each other’s languages. A majority of Vidarbhians speak Varhadi, a dialect of Marathi. The present paper aims to look into the phonological nature of Marathi-Hindi contact in eastern Vidarbha. Standard Marathi is used as a medium of instruction for education and Hindi is used for informal communication in this area. This situation creates phonological variation in Marathi for instance: the standard Marathi ‘c’ is pronounced like Hindi ‘þ’. Eg. Marathi Local Variety Hindi pac paþ panþ ‘five’ cor þor þor ‘thief’ Thus, this paper will be an attempt to examine the phonological changes occurs due to influence of Hindi. Keywords: Marathi-Hindi, Language Contact, Phonology, Vidarbha. http://www.ijellh.com 63 Volume II, Issue VII, November 2014 - ISSN 2321-7065 Introduction: Multilingualism and bilingualism is likely to be common phenomenon throughout the world. There are so many languages spoken in the world where there is much variation in language over short distances. -

Language and Literature
1 Indian Languages and Literature Introduction Thousands of years ago, the people of the Harappan civilisation knew how to write. Unfortunately, their script has not yet been deciphered. Despite this setback, it is safe to state that the literary traditions of India go back to over 3,000 years ago. India is a huge land with a continuous history spanning several millennia. There is a staggering degree of variety and diversity in the languages and dialects spoken by Indians. This diversity is a result of the influx of languages and ideas from all over the continent, mostly through migration from Central, Eastern and Western Asia. There are differences and variations in the languages and dialects as a result of several factors – ethnicity, history, geography and others. There is a broad social integration among all the speakers of a certain language. In the beginning languages and dialects developed in the different regions of the country in relative isolation. In India, languages are often a mark of identity of a person and define regional boundaries. Cultural mixing among various races and communities led to the mixing of languages and dialects to a great extent, although they still maintain regional identity. In free India, the broad geographical distribution pattern of major language groups was used as one of the decisive factors for the formation of states. This gave a new political meaning to the geographical pattern of the linguistic distribution in the country. According to the 1961 census figures, the most comprehensive data on languages collected in India, there were 187 languages spoken by different sections of our society. -

The Dravidian Languages
THE DRAVIDIAN LANGUAGES BHADRIRAJU KRISHNAMURTI The Pitt Building, Trumpington Street, Cambridge, United Kingdom The Edinburgh Building, Cambridge CB2 2RU, UK 40 West 20th Street, New York, NY 10011–4211, USA 477 Williamstown Road, Port Melbourne, VIC 3207, Australia Ruiz de Alarc´on 13, 28014 Madrid, Spain Dock House, The Waterfront, Cape Town 8001, South Africa http://www.cambridge.org C Bhadriraju Krishnamurti 2003 This book is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2003 Printed in the United Kingdom at the University Press, Cambridge Typeface Times New Roman 9/13 pt System LATEX2ε [TB] A catalogue record for this book is available from the British Library ISBN 0521 77111 0hardback CONTENTS List of illustrations page xi List of tables xii Preface xv Acknowledgements xviii Note on transliteration and symbols xx List of abbreviations xxiii 1 Introduction 1.1 The name Dravidian 1 1.2 Dravidians: prehistory and culture 2 1.3 The Dravidian languages as a family 16 1.4 Names of languages, geographical distribution and demographic details 19 1.5 Typological features of the Dravidian languages 27 1.6 Dravidian studies, past and present 30 1.7 Dravidian and Indo-Aryan 35 1.8 Affinity between Dravidian and languages outside India 43 2 Phonology: descriptive 2.1 Introduction 48 2.2 Vowels 49 2.3 Consonants 52 2.4 Suprasegmental features 58 2.5 Sandhi or morphophonemics 60 Appendix. Phonemic inventories of individual languages 61 3 The writing systems of the major literary languages 3.1 Origins 78 3.2 Telugu–Kannada. -

The Syllable Structure of Bangla in Optimality Theory and Its Application to the Analysis of Verbal Inflectional Paradigms in Distributed Morphology
The syllable structure of Bangla in Optimality Theory and its application to the analysis of verbal inflectional paradigms in Distributed Morphology von Somdev Kar Philosophische Dissertation angenommen von der Neuphilologischen Fakultät der Universität Tübingen am 09. Januar 2009 Tübingen 2009 Gedruckt mit Genehmigung der Neuphilologischen Fakultät der Universität Tübingen Hauptberichterstatter : Prof. Hubert Truckenbrodt, Ph.D. Mitberichterstatter : PD Dr. Ingo Hertrich Dekan : Prof. Dr. Joachim Knape ii To my parents... iii iv ACKNOWLEDGEMENTS First and foremost, I owe a great debt of gratitude to Prof. Hubert Truckenbrodt who was extremely kind to agree to be my research adviser and to help me to formulate this work. His invaluable guidance, suggestions, feedbacks and above all his robust optimism steered me to come up with this study. Prof. Probal Dasgupta (ISI) and Prof. Gautam Sengupta (HCU) provided insightful comments that have given me a different perspective to various linguistic issues of Bangla. I thank them for their valuable time and kind help to me. I thank Prof. Sengupta, Dr. Niladri Sekhar Dash and CIIL, Mysore for their help, cooperation and support to access the Bangla corpus I used in this work. In this connection I thank Armin Buch (Tübingen) who worked on the extraction of data from the raw files of the corpus used in this study. And, I wish to thank Ronny Medda, who read a draft of this work with much patience and gave me valuable feedbacks. Many people have helped in different ways. I would like to express my sincere thanks and gratefulness to Prof. Josef Bayer for sending me some important literature, Prof. -

Detecting Pre-Modern Lexical Influence from South India in Maritime Southeast Asia
Archipel Études interdisciplinaires sur le monde insulindien 89 | 2015 Varia Detecting pre-modern lexical influence from South India in Maritime Southeast Asia Détecter l’influence du lexique pré‑moderne de l’Inde du Sud en Asie du Sud-Est maritime. Tom Hoogervorst Electronic version URL: http://journals.openedition.org/archipel/490 DOI: 10.4000/archipel.490 ISSN: 2104-3655 Publisher Association Archipel Printed version Date of publication: 15 April 2015 Number of pages: 63-93 ISBN: 978-2-910513-72-6 ISSN: 0044-8613 Electronic reference Tom Hoogervorst, “Detecting pre-modern lexical influence from South India in Maritime Southeast Asia”, Archipel [Online], 89 | 2015, Online since 15 June 2017, connection on 05 March 2021. URL: http://journals.openedition.org/archipel/490 ; DOI: https://doi.org/10.4000/archipel.490 Association Archipel EMPRUNTS ET RÉINTERPRÉTATIONS TOM HOOGERVORST1 Detecting pre-modern lexical influence from South India in Maritime Southeast Asia2 Introduction In the mid-19th century, the famous Malacca-born language instructor Abdullah bin Abdul Kadir documented the following account in his autobiography Hikayat Abdullah (Munšī 1849): “[…] my father sent me to a teacher to learn Tamil, an Indian language, because it had been the custom from the time of our forefathers in Malacca for all the children of good and well-to-do families to learn it. It was useful for doing computations and accounts, and for purposes of conversation because at that time Malacca was crowded with Indian merchants. Many were the men who had become rich by trading in Malacca, so much so that the names of Tamil traders had become famous.