Phonemes and Allophones of English Consonants
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Words and Alternative Basic Units for Linguistic Analysis
Words and alternative basic units for linguistic analysis 1 Words and alternative basic units for linguistic analysis Jens Allwood SCCIIL Interdisciplinary Center, University of Gothenburg A. P. Hendrikse, Department of Linguistics, University of South Africa, Pretoria Elisabeth Ahlsén SCCIIL Interdisciplinary Center, University of Gothenburg Abstract The paper deals with words and possible alternative to words as basic units in linguistic theory, especially in interlinguistic comparison and corpus linguistics. A number of ways of defining the word are discussed and related to the analysis of linguistic corpora and to interlinguistic comparisons between corpora of spoken interaction. Problems associated with words as the basic units and alternatives to the traditional notion of word as a basis for corpus analysis and linguistic comparisons are presented and discussed. 1. What is a word? To some extent, there is an unclear view of what counts as a linguistic word, generally, and in different language types. This paper is an attempt to examine various construals of the concept “word”, in order to see how “words” might best be made use of as units of linguistic comparison. Using intuition, we might say that a word is a basic linguistic unit that is constituted by a combination of content (meaning) and expression, where the expression can be phonetic, orthographic or gestural (deaf sign language). On closer examination, however, it turns out that the notion “word” can be analyzed and specified in several different ways. Below we will consider the following three main ways of trying to analyze and define what a word is: (i) Analysis and definitions building on observation and supposed easy discovery (ii) Analysis and definitions building on manipulability (iii) Analysis and definitions building on abstraction 2. -

Laryngeal Features in German* Michael Jessen Bundeskriminalamt, Wiesbaden Catherine Ringen University of Iowa
Phonology 19 (2002) 189–218. f 2002 Cambridge University Press DOI: 10.1017/S0952675702004311 Printed in the United Kingdom Laryngeal features in German* Michael Jessen Bundeskriminalamt, Wiesbaden Catherine Ringen University of Iowa It is well known that initially and when preceded by a word that ends with a voiceless sound, German so-called ‘voiced’ stops are usually voiceless, that intervocalically both voiced and voiceless stops occur and that syllable-final (obstruent) stops are voiceless. Such a distribution is consistent with an analysis in which the contrast is one of [voice] and syllable-final stops are devoiced. It is also consistent with the view that in German the contrast is between stops that are [spread glottis] and those that are not. On such a view, the intervocalic voiced stops arise because of passive voicing of the non-[spread glottis] stops. The purpose of this paper is to present experimental results that support the view that German has underlying [spread glottis] stops, not [voice] stops. 1 Introduction In spite of the fact that voiced (obstruent) stops in German (and many other Germanic languages) are markedly different from voiced stops in languages like Spanish, Russian and Hungarian, all of these languages are usually claimed to have stops that contrast in voicing. For example, Wurzel (1970), Rubach (1990), Hall (1993) and Wiese (1996) assume that German has underlying voiced stops in their different accounts of Ger- man syllable-final devoicing in various rule-based frameworks. Similarly, Lombardi (1999) assumes that German has underlying voiced obstruents in her optimality-theoretic (OT) account of syllable-final laryngeal neutralisation and assimilation in obstruent clusters. -

Nasal Release, Nasal Finals and Tonal Contrasts in Hanoi Vietnamese: an Aerodynamic Experiment Alexis Michaud, Tuân Vu-Ngoc, Angelique Amelot, Bernard Roubeau
Nasal release, nasal finals and tonal contrasts in Hanoi Vietnamese: an aerodynamic experiment Alexis Michaud, Tuân Vu-Ngoc, Angelique Amelot, Bernard Roubeau To cite this version: Alexis Michaud, Tuân Vu-Ngoc, Angelique Amelot, Bernard Roubeau. Nasal release, nasal finals and tonal contrasts in Hanoi Vietnamese: an aerodynamic experiment. Mon-Khmer Studies, 2006, 36, pp. 121-137. hal-00138758v2 HAL Id: hal-00138758 https://hal.archives-ouvertes.fr/hal-00138758v2 Submitted on 26 Jan 2008 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Nasal release, nasal finals and tonal contrasts in Hanoi * Vietnamese: An aerodynamic experiment Alexis MICHAUD Tuaán VUÕ NGOïC Laboratoire de Phonétique et Phonologie Laboratoire d’Informatique pour CNRS-Sorbonne Nouvelle, France la Me¤canique et les Sciences de l’Inge¤nieur CNRS-Universite¤s Paris-Sud et Pierre et Marie Curie, France Ange¤lique AMELOT Bernard ROUBEAU Laboratoire de Phonétique et Phonologie Service ORL, Ho^pital Tenon, France CNRS-Sorbonne Nouvelle, France Abstract The present research addresses three -

Greek and Latin Roots, Prefixes, and Suffixes
GREEK AND LATIN ROOTS, PREFIXES, AND SUFFIXES This is a resource pack that I put together for myself to teach roots, prefixes, and suffixes as part of a separate vocabulary class (short weekly sessions). It is a combination of helpful resources that I have found on the web as well as some tips of my own (such as the simple lesson plan). Lesson Plan Ideas ........................................................................................................... 3 Simple Lesson Plan for Word Study: ........................................................................... 3 Lesson Plan Idea 2 ...................................................................................................... 3 Background Information .................................................................................................. 5 Why Study Word Roots, Prefixes, and Suffixes? ......................................................... 6 Latin and Greek Word Elements .............................................................................. 6 Latin Roots, Prefixes, and Suffixes .......................................................................... 6 Root, Prefix, and Suffix Lists ........................................................................................... 8 List 1: MEGA root list ................................................................................................... 9 List 2: Roots, Prefixes, and Suffixes .......................................................................... 32 List 3: Prefix List ...................................................................................................... -
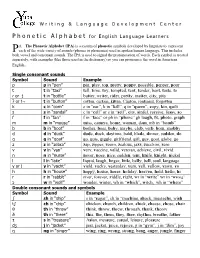
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

An Acoustic Account of the Allophonic Realization of /T/ Amber King St
Linguistic Portfolios Volume 1 Article 12 2012 An Acoustic Account of the Allophonic Realization of /T/ Amber King St. Cloud State University Ettien Koffi St. Cloud State University Follow this and additional works at: https://repository.stcloudstate.edu/stcloud_ling Part of the Applied Linguistics Commons Recommended Citation King, Amber and Koffi, Ettien (2012) "An Acoustic Account of the Allophonic Realization of /T/," Linguistic Portfolios: Vol. 1 , Article 12. Available at: https://repository.stcloudstate.edu/stcloud_ling/vol1/iss1/12 This Article is brought to you for free and open access by theRepository at St. Cloud State. It has been accepted for inclusion in Linguistic Portfolios by an authorized editor of theRepository at St. Cloud State. For more information, please contact [email protected]. King and Koffi: An Acoustic Account of the Allophonic Realization of /T/ AN ACOUSTIC ACCOUNT OF THE ALLOPHONIC REALIZATIONS OF /T/ AMBER KING AND ETTIEN KOFFI 1.0 Introduction This paper is a laboratory phonology account of the different pronunciations of the phoneme /t/. Laboratory phonology is a relatively new analytical tool that is being used to validate and verify claims made by phonologists about the pronunciation of sounds. It is customary for phonologists to predict on the basis of auditory impressions and intuition alone that allophones exist for such and such phonemes. An allophone is defined as different realizations of the same phoneme based on the environments in which it occurs. For instance, it has been proposed that the phoneme /t/ has anywhere from four to eight allophones in General American English (GAE). To verify this claim Amber, one of the co-author of this paper recorded herself saying the words <still>, <Tim>, <kit>, <bitter>, <kitten>, <winter>, <fruition>, <furniture>, and <listen>. -

Different but Not All Opposite: Contributions to Lexical Relationships Teaching in Primary School
INTE - ITICAM - IDEC 2018, Paris-FRANCE VOLUME 1 All Different But Not All Opposite: Contributions To Lexical Relationships Teaching In Primary School Adriana BAPTISTA Polytechnic Institute of Porto – School of Media Arts and Design inED – Centre for Research and Innovation in Education Portugal [email protected] Celda CHOUPINA Polytechnic Institute of Porto – School of Education inED – Centre for Research and Innovation in Education Centre of Linguistics of the University of Porto Portugal [email protected] José António COSTA Polytechnic Institute of Porto – School of Education inED – Centre for Research and Innovation in Education Centre of Linguistics of the University of Porto Portugal [email protected] Joana QUERIDO Polytechnic Institute of Porto – School of Education Portugal [email protected] Inês OLIVEIRA Polytechnic Institute of Porto – School of Education Centre of Linguistics of the University of Porto Portugal [email protected] Abstract The lexicon allows the expression of particular cosmovisions, which is why there are a wide range of lexical relationships, involving different linguistic particularities (Coseriu, 1991; Teixeira , 2005). We find, however, in teaching context, that these variations are often replaced by dichotomous and decontextualized proposals of lexical organization, presented, for instance, in textbooks and other supporting materials (Baptista et al., 2017). Thus, our paper is structured in two parts. First, we will try to account for the diversity of lexical relations (Choupina, Costa & Baptista, 2013), considering phonological, morphological, syntactic, semantic, pragmatic- discursive, cognitive and historical criteria (Lehmann & Martin-Berthet, 2008). Secondly, we present an experimental study that aims at verifying if primary school pupils intuitively organize their mental lexicon in a dichotomous way. -

Lexical Sense Labeling and Sentiment Potential Analysis Using Corpus-Based Dependency Graph
mathematics Article Lexical Sense Labeling and Sentiment Potential Analysis Using Corpus-Based Dependency Graph Tajana Ban Kirigin 1,* , Sanda Bujaˇci´cBabi´c 1 and Benedikt Perak 2 1 Department of Mathematics, University of Rijeka, R. Matejˇci´c2, 51000 Rijeka, Croatia; [email protected] 2 Faculty of Humanities and Social Sciences, University of Rijeka, SveuˇcilišnaAvenija 4, 51000 Rijeka, Croatia; [email protected] * Correspondence: [email protected] Abstract: This paper describes a graph method for labeling word senses and identifying lexical sentiment potential by integrating the corpus-based syntactic-semantic dependency graph layer, lexical semantic and sentiment dictionaries. The method, implemented as ConGraCNet application on different languages and corpora, projects a semantic function onto a particular syntactical de- pendency layer and constructs a seed lexeme graph with collocates of high conceptual similarity. The seed lexeme graph is clustered into subgraphs that reveal the polysemous semantic nature of a lexeme in a corpus. The construction of the WordNet hypernym graph provides a set of synset labels that generalize the senses for each lexical cluster. By integrating sentiment dictionaries, we introduce graph propagation methods for sentiment analysis. Original dictionary sentiment values are integrated into ConGraCNet lexical graph to compute sentiment values of node lexemes and lexical clusters, and identify the sentiment potential of lexemes with respect to a corpus. The method can be used to resolve sparseness of sentiment dictionaries and enrich the sentiment evaluation of Citation: Ban Kirigin, T.; lexical structures in sentiment dictionaries by revealing the relative sentiment potential of polysemous Bujaˇci´cBabi´c,S.; Perak, B. Lexical Sense Labeling and Sentiment lexemes with respect to a specific corpus. -

Velar Segments in Old English and Old Irish
In: Jacek Fisiak (ed.) Proceedings of the Sixth International Conference on Historical Linguistics. Amsterdam: John Benjamins, 1985, 267-79. Velar segments in Old English and Old Irish Raymond Hickey University of Bonn The purpose of this paper is to look at a section of the phoneme inventories of the oldest attested stage of English and Irish, velar segments, to see how they are manifested phonetically and to consider how they relate to each other on the phonological level. The reason I have chosen to look at two languages is that it is precisely when one compares two language systems that one notices that structural differences between languages on one level will be correlated by differences on other levels demonstrating their interrelatedness. Furthermore it is necessary to view segments on a given level in relation to other segments. The group under consideration here is just one of several groups. Velar segments viewed within the phonological system of both Old English and Old Irish cor relate with three other major groups, defined by place of articulation: palatals, dentals, and labials. The relationship between these groups is not the same in each language for reasons which are morphological: in Old Irish changes in grammatical category are frequently indicated by palatalizing a final non-palatal segment (labial, dental, or velar). The same function in Old English is fulfilled by suffixes and /or prefixes. This has meant that for Old English the phonetically natural and lower-level alternation of velar elements with palatal elements in a palatal environ ment was to be found whereas in Old Irish this alternation had been denaturalized and had lost its automatic character. -

Comparative Analysis of American English and Mexican Spanish Consonants for Computer Assisted Pronunciation Training*
REVISTA SIGNOS. ESTUDIOS DE LINGÜÍSTICA ISSN 0718-0934 © 2017 PUCV, Chile DOI: 10.4067/S0718-09342017000200195 50(94) 195-216 Comparative analysis of American English and Mexican Spanish consonants for Computer Assisted Pronunciation Training* Análisis comparativo de las consonantes del inglés americano y español mexicano para la enseñanza de la pronunciación del inglés asistida por computadora Olga Kolesnikova INSTITUTO POLITÉCNICO NACIONAL MÉXICO [email protected] Recibido: 17-X-2014 / Aceptado: 30-VIII-2016 Abstract The objective of this work is two-fold. Firstly, we aim at detecting similarities and differences between the consonant systems of two languages, namely, American English and Mexican Spanish. To achieve this, we perform a theoretic comparative analysis of consonants of the two languages at the level of both phonemes and allophones. Secondly, a possible practical usage of our results is considered; therefore, as an example of an application, we consider computer-assisted pronunciation training (CAPT) for teaching American English pronunciation to Mexican Spanish speakers. In particular, we took advantage of the results of our analysis to define some hypothetic error patterns which can be used as a starting point for diagnosing possible mispronunciations, their posterior verification, and adjustment taking into account the principles of phonotactics and empirical phonetic analysis of the English learners’ speech. The latter will result in error rules to be applied in a CAPT system for error identification and generation of appropriate corrective feedback. An adequate choice of correcting techniques will improve English pronunciation acquisition and help learners to develop less accented speech. Also, similarities found between the two consonant systems make it possible to organize and present the pronunciation teaching material using a stress-free method of helping learners to adjust their speech organs to new sounds building on the phonetic habits of their first language. -

Lexical Semantics
Lexical Semantics COMP-599 Oct 20, 2015 Outline Semantics Lexical semantics Lexical semantic relations WordNet Word Sense Disambiguation • Lesk algorithm • Yarowsky’s algorithm 2 Semantics The study of meaning in language What does meaning mean? • Relationship of linguistic expression to the real world • Relationship of linguistic expressions to each other Let’s start by focusing on the meaning of words— lexical semantics. Later on: • meaning of phrases and sentences • how to construct that from meanings of words 3 From Language to the World What does telephone mean? • Picks out all of the objects in the world that are telephones (its referents) Its extensional definition not telephones telephones 4 Relationship of Linguistic Expressions How would you define telephone? e.g, to a three-year- old, or to a friendly Martian. 5 Dictionary Definition http://dictionary.reference.com/browse/telephone Its intensional definition • The necessary and sufficient conditions to be a telephone This presupposes you know what “apparatus”, “sound”, “speech”, etc. mean. 6 Sense and Reference (Frege, 1892) Frege was one of the first to distinguish between the sense of a term, and its reference. Same referent, different senses: Venus the morning star the evening star 7 Lexical Semantic Relations How specifically do terms relate to each other? Here are some ways: Hypernymy/hyponymy Synonymy Antonymy Homonymy Polysemy Metonymy Synecdoche Holonymy/meronymy 8 Hypernymy/Hyponymy ISA relationship Hyponym Hypernym monkey mammal Montreal city red wine beverage 9 Synonymy and Antonymy Synonymy (Roughly) same meaning offspring descendent spawn happy joyful merry Antonymy (Roughly) opposite meaning synonym antonym happy sad descendant ancestor 10 Homonymy Same form, different (and unrelated) meaning Homophone – same sound • e.g., son vs.