A Phonetically Transcribed Speech Dataset from an Endangered Language for Universal Phone Recognition Experiments
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Study on Human Rights Violation of Tangkhul Community in Ukhrul District, Manipur
A STUDY ON HUMAN RIGHTS VIOLATION OF TANGKHUL COMMUNITY IN UKHRUL DISTRICT, MANIPUR. A THESIS SUBMITTED TO THE TILAK MAHARASHTRA VIDYAPEETH, PUNE FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN SOCIAL WORK UNDER THE BOARD OF SOCIAL WORK STUDIES BY DEPEND KAZINGMEI PRN. 15514002238 UNDER THE GUIDANCE OF DR. G. R. RATHOD DIRECTOR, SOCIAL SCIENCE CENTRE, BVDU, PUNE SEPTEMBER 2019 DECLARATION I, DEPEND KAZINGMEI, declare that the Ph.D thesis entitled “A Study on Human Rights Violation of Tangkhul Community in Ukhrul District, Manipur.” is the original research work carried by me under the guidance of Dr. G.R. Rathod, Director of Social Science Centre, Bharati Vidyapeeth University, Pune, for the award of Ph.D degree in Social Work of the Tilak Maharashtra Vidyapeeth, Pune. I hereby declare that the said research work has not submitted previously for the award of any Degree or Diploma in any other University or Examination body in India or abroad. Place: Pune Mr. Depend Kazingmei Date: Research Student i CERTIFICATE This is to certify that the thesis entitled, “A Study on Human Rights Violation of Tangkhul Community in Ukhrul District, Manipur”, which is being submitted herewith for the award of the Degree of Ph.D in Social Work of Tilak Maharashtra Vidyapeeth, Pune is the result of original research work completed by Mr. Depend Kazingmei under my supervision and guidance. To the best of my knowledge and belief the work incorporated in this thesis has not formed the basis for the award of any Degree or similar title of this or any other University or examining body. -

A RECONSTRUCTION of PROTO-TANGKHULIC RHYMES David R
A RECONSTRUCTION OF PROTO-TANGKHULIC RHYMES David R. Mortensen University of Pittsburgh James A. Miller Independent Scholar This paper presents a reconstruction of the rhyme system of Proto-Tangkhulic, the putative ancestor of the Tangkhulic languages, a Tibeto-Burman subgroup. A reconstructed rhyme inventory for the proto-language is presented. Correspondence sets for each of the members of the inventory are then systematically presented, along with supporting cognate sets drawn from four Tangkhulic languages: Ukhrul, Huishu, Kachai, and Tusom. This paper also summarizes the major sound changes that relate Proto-Tangkhulic to the daughter languages on which the reconstruction is based. It is concluded that Proto-Tangkhulic was considerably more conservative than any of these languages. It preserved the Proto-Tibeto-Burman length distinction in certain contexts and reflexes of final *-l, even though these are not preserved as such in Ukhrul, Huishu, Kachai, or Tusom. Proto-Tangkhulic is argued to be a potentially useful source of evidence in the reconstruction of Proto-Tibeto- Burman. Tangkhulic, comparative reconstruction, rhymes, vowel length 1. INTRODUCTION The goal of this paper is to present a preliminary reconstruction of the rhyme system of Proto-Tangkhulic (PT), the ancestor of the Tangkhulic languages of Manipur and contiguous parts of India and Burma. It will show that Proto- Tangkhulic was a relatively conservative daughter language of Proto-Tibeto- Burman, preserving final *-l, and the vowel length distinction (in some contexts), among other features. As such, we suggest that Proto-Tangkhulic has significant importance in understanding the history of Tibeto-Burman. 1.1. The Tangkhulic language family All Tangkhulic languages are spoken in a compact area centered around Ukhrul District, Manipur State, India. -
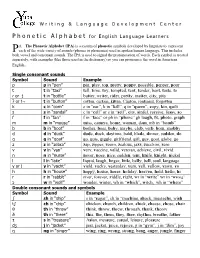
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

7112712551213Eokjhjustificati
Consultancy Services for Carrying out Feasibility Study, Preparation of Detailed Project Report and providing pre- Final Alignment construction services in respect of 2 laning of Pallel-Chandel Option Study Report Section of NH- 102C on Engineering, Procurement and Construction mode in the state of Manipur. ALIGNMENT OPTION STUDY 1.1 Prologue National Highways and Infrastructure Development Corporation (NHIDCL) is a fully owned company of the Ministry of Road Transport & Highways (MoRT&H), Government of India. The company promotes, surveys, establishes, design, build, operate, maintain and upgrade National Highways and Strategic Roads including interconnecting roads in parts of the country which share international boundaries with neighboring countrie. The regional connectivity so enhanced would promote cross border trade and commerce and help safeguard India’s international borders. This would lead to the formation of a more integrated and economically consolidated South and South East Asia. In addition, there would be overall economic benefits for the local population and help integrate the peripheral areas with the mainstream in a more robust manner. As a part of the above mentioned endeavor, National Highways & Infrastructure Development Corporation Limited (NHIDCL) has been entrusted with the assignment of Consultancy Services for Carrying out Feasibility Study, Preparation of Detailed Project Report and providing pre-construction services in respect of 2 laning with paved of Pallel-Chandel Section of NH-102C in the state of Manipur. National Highways & Infrastructure Development Corporation Ltd. is the employer and executing agency for the consultancy services and the standards of output required from the appointed consultants are of international level both in terms of quality and adherence to the agreed time schedule. -

Sl. No. Segment Name Name of the Selected Candidates
ORDER Imphal, the 2nd May 2015 NO: 2/BJP-MP/Elec/2015: The State Election Committee, BJP Manipur Pradesh nominated the following persons/party members to be set up as BJP Candidates in the ensuing 6th ADC Election Manipur, 2015 in their respective ADC Segments as indicated below against their names. CHANDEL DISTRICT AUTONOMOUS DISTRICT COUNCIL ELECTION NAME OF ASSEMBLY CONSTITUENCY --- 41/ CHANDEL SL. SEGMENT SEGME NAME OF THE ADDRESS NO. NAME -NT SELECTED NO. CANDIDATES 1 CHANDEL H/Q 12 SR.NGAMLHUNG PANCHAI VILLAGE 2 TOUPOKPI 21 SR.KONAHRING ANAL HRINGPHE VILLAGE 3 CHAKPI 19 HRANGLIM JEREMIAH KHUBUNG KHULLEN KARONG 4 VOMKU 13 BERADIN SHILSHI NEW LAMKANG KHUNTHAK 5 SUGNU AREA 22 THANKHANPAO SUGNU LOKHIJANG 6 WANGKHERA 20 TS.ISMIEL ANAL WANGKHERA VILLAGE 7 AIHANG 10 THAMBAL SHILSHI PURUM PANTHA 8 PANTHA 11 H.ANGTIN MONSANG JAPHOU VILLAGE 9 SAJIK TAMPAK 23 THANGSUANKAP GELNGAI VILAAGE 10 TOLBUNG 24 THANGKHOMANG AIBOL JOUPI VILLAGE HAOKIP CHANDEL DISTRICT AUTONOMOUS DISTRICT COUNCIL ELECTION NAME OF ASSEMBLY CONSTITUENCY --- 42/ TENGNOUPAL SL. SEGMENT SEGME NAME OF THE ADDRESS NO. NAME -NT SELECTED NO. CANDIDATES 1 KOMLATHABI 8 NG.KOSHING MAYON KOMLATHABI VILLAGE 2 MACHI 2 SK.KOTHIL MACHI VILLAGE, MACHI BLOCK 3 RILRAM 5 K.PRAKASH LANGKHONGCHING VILLAGE 4 MOREH 17 LAMTHANG HAOKIP UKHRUL DISTRICT AUTONOMOUS DISTRICT COUNCIL ELECTION NAME OF ASSEMBLY CONSTITUENCY --- 43/ PHUNGYAR SL. SEGMENT SEGME NAME OF THE ADDRESS NO. NAME -NT SELECTED NO. CANDIDATES 1 GRIHANG 19 SAUL DUIDAND GRIHANG VILLAGE KAMJONG 2 SHINGKAP 21 HENRY W. KEISHING TANGKHUL HUNDUNG 3 KAMJONG 18 C.HOPINGSON KAMJONG BUNGPA KHULLEN 4 CHAITRIC 17 KS.GRACESON SOMI PUSHING VILLAGE 5 PHUNGYAR 20 A. -

EAST TUSOM: a PHONETIC and PHONOLOGICAL SKETCH of a LARGELY UNDOCUMENTED TANGKHULIC LANGUAGE David R
XXXX XXXX — XXXX EAST TUSOM: A PHONETIC AND PHONOLOGICAL SKETCH OF A LARGELY UNDOCUMENTED TANGKHULIC LANGUAGE David R. Mortensen and Jordan Picone Carnegie Mellon University and University of Pittsburgh East Tusom is a Tibeto-Burman language of Manipur, India, belonging to the Tangkhulic group. While it shares some innovations with the other Tangkhulic languages, it differs markedly from “Standard Tangkhul” (which is based on the speech of Ukhrul town). Past documentation is limited to a small set of hastily transcribed forms in a comparative reconstruction of Tangkhulic rhymes (Mortensen & Miller 2013; Mortensen 2012). This paper presents the first substantial sketch of an aspect of the language: its (descriptive) phonetics and phonology. The data are based on recordings of an extensive wordlist (730 items) and one short text, all from one fluent native speaker in her mid-twenties. We present the phonetic inventory of East Tusom and a phonemicization, with exhaustive examples. We also present an overview of the major phonological patterns and generalizations in the language. Of special interest are a “placeless nasal” that is realized as nasalization on the preceding vowel unless it is followed by a consonant and numerous plosive-fricative clusters (where the fricative is roughly homorganic with the following vowel) that have developed from historical aspirated plosives. A complete wordlist, organized by gloss and semantic field, is provided as appendices. phonetics; phonology; clusters; placeless nasal; assimilation; language documentation; Tangkhulic INTRODUCTION The East Tusom Language The topic of this paper is the phonetics and phonology of an endangered Tibeto- Burman language spoken in Tusom village, Ukhrul District, Manipur State, India, perhaps in surrounding villages, and by families who have left the area. -

The Emergence of Obstruents After High Vowels*
John Benjamins Publishing Company This is a contribution from Diachronica 29:4 © 2012. John Benjamins Publishing Company This electronic file may not be altered in any way. The author(s) of this article is/are permitted to use this PDF file to generate printed copies to be used by way of offprints, for their personal use only. Permission is granted by the publishers to post this file on a closed server which is accessible to members (students and staff) only of the author’s/s’ institute, it is not permitted to post this PDF on the open internet. For any other use of this material prior written permission should be obtained from the publishers or through the Copyright Clearance Center (for USA: www.copyright.com). Please contact [email protected] or consult our website: www.benjamins.com Tables of Contents, abstracts and guidelines are available at www.benjamins.com The emergence of obstruents after high vowels* David R. Mortensen University of Pittsburgh While a few cases of the emergence of obstruents after high vowels are found in the literature (Burling 1966, 1967, Blust 1994), no attempt has been made to comprehensively collect instances of this sound change or give them a unified explanation. This paper attempts to resolve this gap in the literature by introduc- ing a post-vocalic obstruent emergence (POE) as a recurring sound change with a phonetic (aerodynamic) basis. Possible cases are identified in Tibeto-Burman, Austronesian, and Grassfields Bantu. Special attention is given to a novel case in the Tibeto-Burman language Huishu. Keywords: epenthesis, sound change, aerodynamics, exemplar theory, Tibeto- Burman, Austronesian, Niger-Congo 1. -

The Impact of English Language on Tangkhul Literacy
THE IMPACT OF ENGLISH LANGUAGE ON TANGKHUL LITERACY A THESIS SUBMITTED TO TILAK MAHARASHTRA VIDYAPEETH, PUNE FOR THE DEGREE OF DOCTOR OF PHILOSOPHY (Ph.D.) IN ENGLISH BY ROBERT SHIMRAY UNDER THE GUIDANCE OF Dr. GAUTAMI PAWAR UNDER THE BOARD OF ARTS & FINEARTS STUDIES MARCH, 2016 DECLARATION I hereby declare that the thesis entitled “The Impact of English Language on Tangkhul Literacy” completed by me has not previously been formed as the basis for the award of any Degree or other similar title upon me of this or any other Vidyapeeth or examining body. Place: Robert Shimray Date: (Research Student) I CERTIFICATE This is to certify that the thesis entitled “The Impact of English Language on Tangkhul Literacy” which is being submitted herewith for the award of the degree of Vidyavachaspati (Ph.D.) in English of Tilak Maharashtra Vidyapeeth, Pune is the result of original research work completed by Robert Shimray under my supervision and guidance. To the best of my knowledge and belief the work incorporated in this thesis has not formed the basis for the award of any Degree or similar title or any University or examining body upon him. Place: Dr. Gautami Pawar Date: (Research Guide) II ACKNOWLEDGEMENT First of all, having answered my prayer, I would like to thank the Almighty God for the privilege and opportunity of enlightening me to do this research work to its completion and accomplishment. Having chosen Rev. William Pettigrew to be His vessel as an ambassador to foreign land, especially to the Tangkhul Naga community, bringing the enlightenment of the ever lasting gospel of love and salvation to mankind, today, though he no longer dwells amongst us, yet his true immortal spirit of love and sacrifice linger. -

CDL-1, UKL-1, SNP-1 Sl. No. Form No. Name Address District Catego Ry Status Recommendation of the Screening Commit
Post A1: STI Counselor 3 Posts: CDL-1, UKL-1, SNP-1 Post Graduate degree I diploma in Psychology / Social Work/ Sociology/ Anthropology/ Human Development/ Nursing; with minimum 1 year experience after PG degree/ diploma, of working in field of counselling in health sector; preferably in STI / RTI and HIV. Or Graduate in Psychology/Social Work/ Sociology/ Anthropology/ Human Development/ Essential Qualification & Experience: Nursing; with minimum 3 years .experience after graduation, of working in field of counselling in health sector; preferably in STI/RTI and HIV. In the case of those recruited from the community of people infected with or affected by HIV/AIDS, the experience will be relaxed to a minimum of one year of experience in the field of HIV/AIDS. 1. Working knowledge of computers Sl. Form Catego Recommendation of the Name Address District Status No. No. ry Screening Committee Domicile not enclosed, Applicant to submit the 1 2 Lanmila Khapudang Kongkan Village Kamjong ST Experience required documents certificate not enclosed Domicile not enclosed, Experience Applicant to submit the 2 38 Dilbung Rengwar Eric Purum Pantha Village Chandel ST certificate , Caste required documents certificate not enclosed 3 54 Makhreluibou Luikang Makhrelu Senapati ST All submitted Recommended 4 483 Ngorum Kennedy Japhou Village Chandel ST All submitted Recommended Domicile not Applicant to submit the 5 564 Jacinta Telen Penaching Village Chandel ST enclosed required documents Experience Mayanglangjing Tamang Imphal Applicant to submit the 6 756 -

THE LANGUAGES of MANIPUR: a CASE STUDY of the KUKI-CHIN LANGUAGES* Pauthang Haokip Department of Linguistics, Assam University, Silchar
Linguistics of the Tibeto-Burman Area Volume 34.1 — April 2011 THE LANGUAGES OF MANIPUR: A CASE STUDY OF THE KUKI-CHIN LANGUAGES* Pauthang Haokip Department of Linguistics, Assam University, Silchar Abstract: Manipur is primarily the home of various speakers of Tibeto-Burman languages. Aside from the Tibeto-Burman speakers, there are substantial numbers of Indo-Aryan and Dravidian speakers in different parts of the state who have come here either as traders or as workers. Keeping in view the lack of proper information on the languages of Manipur, this paper presents a brief outline of the languages spoken in the state of Manipur in general and Kuki-Chin languages in particular. The social relationships which different linguistic groups enter into with one another are often political in nature and are seldom based on genetic relationship. Thus, Manipur presents an intriguing area of research in that a researcher can end up making wrong conclusions about the relationships among the various linguistic groups, unless one thoroughly understands which groups of languages are genetically related and distinct from other social or political groupings. To dispel such misconstrued notions which can at times mislead researchers in the study of the languages, this paper provides an insight into the factors linguists must take into consideration before working in Manipur. The data on Kuki-Chin languages are primarily based on my own information as a resident of Churachandpur district, which is further supported by field work conducted in Churachandpur district during the period of 2003-2005 while I was working for the Central Institute of Indian Languages, Mysore, as a research investigator. -

The Emergence of Obstruents After High Vowels 1. Introduction
The Emergence of Obstruents after High Vowels 1. Introduction Vennemann (1988) and others have argued that sound changes which insert segments most commonly do so in a manner that “improves” syllable structure: they provide syllables with onsets, allow consonants that would otherwise be codas to syllabify as onsets, relieve hiatus between vowels, and so on. On the other hand, the deletion of consonants seems to be particularly common in final position, a tendency that is reflected not only in the diachronic mechanisms outlined by Vennemann, but also reified in synchronic mechanisms like the Optimality Theoretic NoCoda constraint (Prince and Smolensky 1993). It may seem surprising, then, that there is small but robust class of sound changes in which obstruents (usually stops, but sometimes fricatives) emerge after word-final vowels. Discussions of individual instances of this phenomenon have periodically appeared in the literature. The best-known case is from Maru (a Tibeto-Burman language closely related to Burmese) and was discovered by Karlgren (1931), Benedict (1948), and Burling (1966; 1967). Ubels (1975) independently noticed epenthetic stops in Grassfields Bantu languages and Stallcup (1978) discussed this development in another Grassfields Bantu language, Moghamo, drawing an explicit parallel to Maru. Blust (1994) presented the most comprehensive treatment of these sound changes to date (in the context of making an argument about the unity of vowel and consonant features). To the Maru case, he added two additional instances from the Austronesian family: Lom (Belom) and Singhi. He also presented two historical scenarios through which these changes could occur: diphthongization and “direct hardening” of the terminus of the vowel. -

FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS on THREE CONTINENTS a Dissertation Submitted to the Facu
FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS A Dissertation submitted to the Faculty of the Graduate School of Arts and Sciences of Georgetown University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics By Sheena Shah, M.S. Washington, DC May 14, 2013 Copyright 2013 by Sheena Shah All Rights Reserved ii FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS Sheena Shah, M.S. Thesis Advisors: Alison Mackey, Ph.D. Natalie Schilling, Ph.D. ABSTRACT This dissertation examines the causes behind the differences in proficiency in the North Indian language Gujarati among heritage learners of Gujarati in three diaspora locations. In particular, I focus on whether there is a relationship between heritage language ability and ethnic and cultural identity. Previous studies have reported divergent findings. Some have found a positive relationship (e.g., Cho, 2000; Kang & Kim, 2011; Phinney, Romero, Nava, & Huang, 2001; Soto, 2002), whereas others found no correlation (e.g., C. L. Brown, 2009; Jo, 2001; Smolicz, 1992), or identified only a partial relationship (e.g., Mah, 2005). Only a few studies have addressed this question by studying one community in different transnational locations (see, for example, Canagarajah, 2008, 2012a, 2012b). The current study addresses this matter by examining data from members of the same ethnic group in similar educational settings in three multi-ethnic and multilingual cities. The results of this study are based on a survey consisting of questionnaires, semi-structured interviews, and proficiency tests with 135 participants. Participants are Gujarati heritage language learners from the U.K., Singapore, and South Africa, who are either current students or recent graduates of a Gujarati School.