Bimoraicity and Feet in Japanese
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uhm Phd 9506222 R.Pdf
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UM! films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent UJWD the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adverselyaffect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-band comer and continuing from left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. U·M·I University Microfilms tnternauonat A Bell & Howell tntorrnatron Company 300 North Zeeb Road. Ann Arbor. M148106-1346 USA 313/761-4700 800:521·0600 Order Number 9506222 The linguistic and psycholinguistic nature of kanji: Do kanji represent and trigger only meanings? Matsunaga, Sachiko, Ph.D. University of Hawaii, 1994 Copyright @1994 by Matsunaga, Sachiko. -

Establishing Okinawan Heritage Language Education
Establishing Okinawan heritage language education ESTABLISHING OKINAWAN HERITAGE LANGUAGE EDUCATION Patrick HEINRICH (University of Duisburg-Essen) ABSTRACT In spite of Okinawan language endangerment, heritage language educa- tion for Okinawan has still to be established as a planned and purposeful endeavour. The present paper discusses the prerequisites and objectives of Okinawan Heritage Language (OHL) education.1 It examines language attitudes towards Okinawan, discusses possibilities and constraints un- derlying its curriculum design, and suggests research which is necessary for successfully establishing OHL education. The following results are presented. Language attitudes reveal broad support for establishing Ok- inawan heritage language education. A curriculum for OHL must consid- er the constraints arising from the present language situation, as well as language attitudes towards Okinawan. Research necessary for the estab- lishment of OHL can largely draw from existing approaches to foreign language education. The paper argues that establishment of OHL educa- tion should start with research and the creation of emancipative ideas on what Okinawan ought to be in the future – in particular which societal functions it ought to fulfil. A curriculum for OHL could be established by following the user profiles and levels of linguistic proficiency of the Common European Framework of Reference for Languages. 1 This paper specifically treats the language of Okinawa Island only. Other languages of the Ryukyuan language family such as the languages of Amami, Miyako, Yaeyama and Yonaguni are not considered here. The present paper draws on research conducted in 2005 in Okinawa. Research was supported by a Japanese Society for the Promotion of Science fellowship which is gratefully acknowledged here. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Galio Uma, Maƙerin Azurfa Maƙeri (M): Ni Ina Da Shekara Yanzu…
LANGUAGE PROGRAM, 232 BAY STATE ROAD, BOSTON, MA 02215 [email protected] www.bu.edu/Africa/alp 617.353.3673 Interview 2: Galio Uma, Maƙerin Azurfa Maƙeri (M): Ni ina da shekara yanzu…, ina da vers …alal misali vers mille neuf cent quatre vingt et quatre (1984) gare mu parce que wajenmu babu hopital lokacin da anka haihe ni ban san shekaruna ba, gaskiya. Ihehehe! Makaranta, ban yi makaranta ba sabo da an sa ni makaranta sai daga baya wajenmu babana bai da hali, mammana bai da hali sai mun biya. Akwai nisa tsakaninmu da inda muna karatu. Kilometir kama sha biyar kullum ina tahiya da ƙahwa. To, ha na gaji wani lokaci mu hau jaki, wani lokaci mu hau raƙumi, to wani lokaci ma babu hali, babu karatu. Amman na yi shekara shidda ina karatu ko biyat. Amman ban ji daɗi ba da ban yi karatu ba. Sabo da shi ne daɗin duniya. Mm. To mu Buzaye ne muna yin buzanci. Ana ce muna Tuareg. Mais Tuareg ɗin ma ba guda ba ne. Mu artisans ne zan ce miki. Can ainahinmu ma ba mu da wani aiki sai ƙira. Duka mutanena suna can Abala. Nan ga ni dai na nan ga. Ka gani ina da mata, ina da yaro. Akwai babana, akwai mammana. Ina da ƙanne huɗu, macce biyu da namiji biyu. Suna duka cikin gida. Duka kuma kama ni ne chef de famille. Duka ni ne ina aider ɗinsu. Sabo da babana yana da shekara saba’in da biyar. Vers. Mammana yana da shekara shi ma hamsin da biyar. -
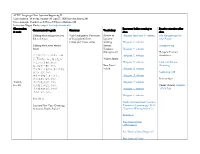
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -

NOT WRITING AS a KEY FACTOR in LANGUAGE ENDANGERMENT: the CASE of the RYUKYU ISLANDS Patrick Heinrich Dokkyo University, Tokyo
NOT WRITING AS A KEY FACTOR IN LANGUAGE ENDANGERMENT: THE CASE OF THE RYUKYU ISLANDS Patrick Heinrich Dokkyo University, Tokyo Abstract: Language shift differs from case to case. Yet, specifi c types of language shift can be identifi ed. Language shift in the Ryukyu Islands is caused by the socioeconomic changes resulting from the transition from the dynastic realms of the Ryukyu Kingdom and the Tokugawa Shogunate to the modern Meiji state. We call the scenario of shift after the transition from a dynastic realm to a modern state ‘type III’ language shift here. In type III, one language adopts specifi c new functions, which undermine the utility of other local or ethnic languages. The dominance of one language over others hinges, amongst other things, on the extent to which a written tradition existed or not. In the Ryukyu Kingdom, Chinese and Japanese were employed as the main languages of writing. The lack of a writing tradition paved the way for the Ryukyuan languages to be declared dialects of the written language, that is, of Japanese. Such assessment of Ryukyuan language status was fi rst put forth by mainland bureaucrats and later rationalized by Japanese national linguistics. Such a proceeding is an example of what Heinz Kloss calls near-dialectization. In order to undo the effects thereof, language activists are turning to writing in order to lay claim to their view that the endangered Ryukyuan Abstand languages be recognized as languages. Key words: Ryukyuan languages, language shift theory, writing, language adaptation, language revitalization INTRODUCTION The Ryukyuan languages have rarely been written in their history. -

The Languages of Japan and Korea. London: Routledge 2 The
To appear in: Tranter, David N (ed.) The Languages of Japan and Korea. London: Routledge 2 The relationship between Japanese and Korean John Whitman 1. Introduction This chapter reviews the current state of Japanese-Ryukyuan and Korean internal reconstruction and applies the results of this research to the historical comparison of both families. Reconstruction within the families shows proto-Japanese-Ryukyuan (pJR) and proto-Korean (pK) to have had very similar phonological inventories, with no laryngeal contrast among consonants and a system of six or seven vowels. The main challenges for the comparativist are working through the consequences of major changes in root structure in both languages, revealed or hinted at by internal reconstruction. These include loss of coda consonants in Japanese, and processes of syncope and medial consonant lenition in Korean. The chapter then reviews a small number (50) of pJR/pK lexical comparisons in a number of lexical domains, including pronouns, numerals, and body parts. These expand on the lexical comparisons proposed by Martin (1966) and Whitman (1985), in some cases responding to the criticisms of Vovin (2010). It identifies a small set of cognates between pJR and pK, including approximately 13 items on the standard Swadesh 100 word list: „I‟, „we‟, „that‟, „one‟, „two‟, „big‟, „long‟, „bird‟, „tall/high‟, „belly‟, „moon‟, „fire‟, „white‟ (previous research identifies several more cognates on this list). The paper then concludes by introducing a set of cognate inflectional morphemes, including the root suffixes *-i „infinitive/converb‟, *-a „infinitive/irrealis‟, *-or „adnominal/nonpast‟, and *-ko „gerund.‟ In terms of numbers of speakers, Japanese-Ryukyuan and Korean are the largest language isolates in the world. -

EFFECTS of ONLINE ORAL PRACTICE on JAPANESE PITCH ACCENTUATION ACQUISITION Mayu Miyamoto Purdue University
Purdue University Purdue e-Pubs Open Access Theses Theses and Dissertations Spring 2014 EFFECTS OF ONLINE ORAL PRACTICE ON JAPANESE PITCH ACCENTUATION ACQUISITION Mayu Miyamoto Purdue University Follow this and additional works at: https://docs.lib.purdue.edu/open_access_theses Part of the Asian Studies Commons, and the Linguistics Commons Recommended Citation Miyamoto, Mayu, "EFFECTS OF ONLINE ORAL PRACTICE ON JAPANESE PITCH ACCENTUATION ACQUISITION" (2014). Open Access Theses. 223. https://docs.lib.purdue.edu/open_access_theses/223 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. Graduate School ETD Form 9 (Revised/) PURDUE UNIVERSITY GRADUATE SCHOOL Thesis/Dissertation Acceptance This is to certify that the thesis/dissertation prepared By Mayu Miyamoto Entitled EFFECTS OF ONLINE ORAL PRACTICE ON JAPANESE PITCH ACCENTUATION ACQUISITION Master of Arts For the degree of Is approved by the final examining committee: Atsushi Fukada Mariko Moroishi Wei April Ginther To the best of my knowledge and as understood by the student in the 7KHVLV'LVVHUWDWLRQ$JUHHPHQW 3XEOLFDWLRQ'HOD\DQGCHUWLILFDWLRQDisclaimer (Graduate School Form ), this thesis/dissertation DGKHUHVWRWKHSURYLVLRQVRIPurdue University’s “Policy on Integrity in Research” and the use of copyrighted material. Atsushi Fukada Approved by Major Professor(s): ____________________________________ ____________________________________ Approved by:Atsushi Fukada 04/22/2014 Head of the 'HSDUWPHQWGraduate Program Date EFFECTS OF ONLINE ORAL PRACTICE ON JAPANESE PITCH ACCENTUATION ACQUISITION A Thesis Submitted to the Faculty of Purdue University by Mayu Miyamoto In Partial Fulfillment of the Requirements for the Degree of Master of Arts May 2014 Purdue University West Lafayette, Indiana ii ACKNOWLEDGEMENTS I would like to express my sincere gratitude to my advisor and committee chair, Professor Atsushi Fukada, for his continuous support, encouragement, and advice throughout my career at Purdue University. -

The Degree of the Speaker's Negative Attitude in a Goal-Shifting
In Christopher Brown and Qianping Gu and Cornelia Loos and Jason Mielens and Grace Neveu (eds.), Proceedings of the 15th Texas Linguistics Society Conference, 150-169. 2015. The degree of the speaker’s negative attitude in a goal-shifting comparison Osamu Sawada∗ Mie University [email protected] Abstract The Japanese comparative expression sore-yori ‘than it’ can be used for shifting the goal of a conversation. What is interesting about goal-shifting via sore-yori is that, un- like ordinary goal-shifting with expressions like tokorode ‘by the way,’ using sore-yori often signals the speaker’s negative attitude toward the addressee. In this paper, I will investigate the meaning and use of goal-shifting comparison and consider the mecha- nism by which the speaker’s emotion is expressed. I will claim that the meaning of the pragmatic sore-yori conventionally implicates that the at-issue utterance is preferable to the previous utterance (cf. metalinguistic comparison (e.g. (Giannakidou & Yoon 2011))) and that the meaning of goal-shifting is derived if the goal associated with the at-issue utterance is considered irrelevant to the goal associated with the previous utterance. Moreover, I will argue that the speaker’s negative attitude is shown by the competition between the speaker’s goal and the hearer’s goal, and a strong negativity emerges if the goals are assumed to be not shared. I will also compare sore-yori to sonna koto-yori ‘than such a thing’ and show that sonna koto-yori directly expresses a strong negative attitude toward the previous utterance. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

Subj: Revision
Intercultural Communication Studies IX-1 Fall 1999-0 Hoffer - Review REVIEW Multilingual Japan. John C. Maher and Kyoko Yashiro, editors. Clevedon, UK: Multilingual Matters. 1995. Multilingual Japan, a special issue of the Journal of Multilingual and Multicultural Matters, edited by John C. Maher and Kyoko Yashiro, is an excellent book from which to learn more about the language and cultural history and status of Japan. The stereotype that Japan is a unique monolingual/ monocultural country is one that refuses to go away. All countries are unique and, as they make clear, Japan has never been monolingual and monocultural. We need more such serious empirical studies like that conducted by Maher and Yashiro to help change the rather resistant attitudes of the government and a segment of the population at large. On the more than 3000 islands which stretch from Hokkaido almost to Taiwan, the languages which are present in identifiable numbers include Japanese, Ainu, the various types of Ryukyuan languages, Korean, Chinese, English, and some languages from Southeast Asia. Maher and Yashiro note that required English courses have produced millions of Japanese with some level of bilingual ability and that the large number of Japanese families which have returned after lengthy stays abroad means that there is a large number of bilinguals involving several of the world's languages. Japan is and has been a multilingual country with a large number of bilinguals in the mainstream of society. Matsumori's chapter covers Ryukyuan, a cover term for a group of languages which are spoken in the southern islands of Japan and which have a close relation to the Japanese language. -
![Learning [Voice]](https://docslib.b-cdn.net/cover/5030/learning-voice-615030.webp)
Learning [Voice]
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Learning [Voice] Joshua Ian Tauberer University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the First and Second Language Acquisition Commons Recommended Citation Tauberer, Joshua Ian, "Learning [Voice]" (2010). Publicly Accessible Penn Dissertations. 288. https://repository.upenn.edu/edissertations/288 Please see my home page, http://razor.occams.info, for the data files and scripts that make this reproducible research. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/288 For more information, please contact [email protected]. Learning [Voice] Abstract The [voice] distinction between homorganic stops and fricatives is made by a number of acoustic correlates including voicing, segment duration, and preceding vowel duration. The present work looks at [voice] from a number of multidimensional perspectives. This dissertation's focus is a corpus study of the phonetic realization of [voice] in two English-learning infants aged 1;1--3;5. While preceding vowel duration has been studied before in infants, the other correlates of post-vocalic voicing investigated here --- preceding F1, consonant duration, and closure voicing intensity --- had not been measured before in infant speech. The study makes empirical contributions regarding the development of the production of [voice] in infants, not just from a surface- level perspective but also with implications for the phonetics-phonology interface in the adult and developing linguistic systems. Additionally, several methodological contributions will be made in the use of large sized corpora and data modeling techniques. The study revealed that even in infants, F1 at the midpoint of a vowel preceding a voiced consonant was lower by roughly 50 Hz compared to a vowel before a voiceless consonant, which is in line with the effect found in adults.