Variation in English /L
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Downloaded an Applet That Would Allow the Recordings to Be Collected Remotely
UC Berkeley UC Berkeley PhonLab Annual Report Title A Survey of English Vowel Spaces of Asian American Californians Permalink https://escholarship.org/uc/item/4w84m8k4 Journal UC Berkeley PhonLab Annual Report, 12(1) ISSN 2768-5047 Author Cheng, Andrew Publication Date 2016 DOI 10.5070/P7121040736 Peer reviewed eScholarship.org Powered by the California Digital Library University of California UC Berkeley Phonetics and Phonology Lab Annual Report (2016) A Survey of English Vowel Spaces of Asian American Californians Andrew Cheng∗ May 2016 Abstract A phonetic study of the vowel spaces of 535 young speakers of Californian English showed that participation in the California Vowel Shift, a sound change unique to the West Coast region of the United States, varied depending on the speaker's self- identified ethnicity. For example, the fronting of the pre-nasal hand vowel varied by ethnicity, with White speakers participating the most and Chinese and South Asian speakers participating less. In another example, Korean and South Asian speakers of Californian English had a more fronted foot vowel than the White speakers. Overall, the study confirms that CVS is present in almost all young speakers of Californian English, although the degree of participation for any individual speaker is variable on account of several interdependent social factors. 1 Introduction This is a study on the English spoken by Americans of Asian descent living in California. Specifically, it will look at differences in vowel qualities between English speakers of various ethnic -

Language Variation and Ethnicity in a Multicultural East London Secondary School
Language Variation and Ethnicity in a Multicultural East London Secondary School Shivonne Marie Gates Queen Mary, University of London April 2019 Abstract Multicultural London English (MLE) has been described as a new multiethnolect borne out of indirect language contact among ethnically-diverse adolescent friendship groups (Cheshire et al. 2011). Evidence of ethnic stratification was also found: for example, “non-Anglo” boys were more likely to use innovative MLE diphthong variants than other (male and female) participants. However, the data analysed by Cheshire and colleagues has limited ethnographic information and as such the role that ethnicity plays in language change and variation in London remains unclear. This is not dissimilar to other work on multiethnolects, which presents an orientation to a multiethnic identity as more salient than different ethnic identities (e.g. Freywald et al. 2011). This thesis therefore examines language variation in a different MLE-speaking adolescent community to shed light on the dynamics of ethnicity in a multicultural context. Data were gathered through a 12-month ethnography of a Year Ten (14-15 years old) cohort at Riverton, a multi-ethnic secondary school in Newham, East London, and include field notes and interviews with 27 students (19 girls, 8 boys). A full multivariate analysis of the face and price vowels alongside a quantitative description of individual linguistic repertoires sheds light on MLE’s status as the new London vernacular. Building on the findings of Cheshire et al. (2011), the present study suggests that language variation by ethnicity can have social meaning in multi-ethnic communities. There are apparent ethnolinguistic repertoires: ethnic minority boys use more advanced vowel realisations alongside high rates of DH-stopping, and the more innovative was/were levelling system. -
![Learning [Voice]](https://docslib.b-cdn.net/cover/5030/learning-voice-615030.webp)
Learning [Voice]
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Learning [Voice] Joshua Ian Tauberer University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the First and Second Language Acquisition Commons Recommended Citation Tauberer, Joshua Ian, "Learning [Voice]" (2010). Publicly Accessible Penn Dissertations. 288. https://repository.upenn.edu/edissertations/288 Please see my home page, http://razor.occams.info, for the data files and scripts that make this reproducible research. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/288 For more information, please contact [email protected]. Learning [Voice] Abstract The [voice] distinction between homorganic stops and fricatives is made by a number of acoustic correlates including voicing, segment duration, and preceding vowel duration. The present work looks at [voice] from a number of multidimensional perspectives. This dissertation's focus is a corpus study of the phonetic realization of [voice] in two English-learning infants aged 1;1--3;5. While preceding vowel duration has been studied before in infants, the other correlates of post-vocalic voicing investigated here --- preceding F1, consonant duration, and closure voicing intensity --- had not been measured before in infant speech. The study makes empirical contributions regarding the development of the production of [voice] in infants, not just from a surface- level perspective but also with implications for the phonetics-phonology interface in the adult and developing linguistic systems. Additionally, several methodological contributions will be made in the use of large sized corpora and data modeling techniques. The study revealed that even in infants, F1 at the midpoint of a vowel preceding a voiced consonant was lower by roughly 50 Hz compared to a vowel before a voiceless consonant, which is in line with the effect found in adults. -

Phonetics and Phonology
TRNAVA UNIVERSITY IN TRNAVA FACULTY OF EDUCATION PHONETICS AND PHONOLOGY Selected Aspects of English Pronunciation Učebné texty Hana Vančová Trnava 2019 Phonetics and Phonology. Selected Aspects of English Pronunciation Učebné texty. © Mgr. Hana Vančová, PhD. Recenzenti: prof. PaedDr. Silvia Pokrivčáková, PhD. Mgr. Eva Lukáčová, PhD. Jazyková korektúra: M. A. Louise Kocianová Vydal: Pedagogická fakulta Trnavskej univerzity v Trnave Vydanie: prvé Náklad: elektronické vydanie Trnava 2019 ISBN 978-80-568-0178-9 2 OBSAH Introduction ................................................................................................................................ 5 1 THE ACOUSTIC ASPECT OF LANGUAGE ................................................................................... 6 1.1 The development of human speech ................................................................................. 6 1.2 Interfaces of phonetics and phonology with other linguistic disciplines ......................... 8 1.3 English orthography and pronunciation ......................................................................... 11 2 PHONEMES AND ALLOPHONES ............................................................................................. 16 2. 1 Vowel sounds ................................................................................................................. 16 2.1.1 Vowels (monophthongs) .......................................................................................... 16 2.1.2 Diphthongs .............................................................................................................. -

A Morpho-Phonemic Analysis on Sasak Affixation
International Journal of Linguistics, Literature and Translation (IJLLT) ISSN: 2617-0299 (Online); ISSN: 2708-0099 (Print) DOI: 10.32996/ijllt Journal Homepage: www.al-kindipublisher.com/index.php/ijllt A Morpho-phonemic Analysis on Sasak Affixation Wahyu Kamil Syarifaturrahman1, Sutarman*2 & Zainudin Abdussamad3 123Fakultas Sosial dan Humaniora,Universitas Bumigora, Indonesia Corresponding Author: Sutarman, E-mail: [email protected] ARTICLE INFORMATION ABSTRACT Received: November 17, 2020 The current study analyses the morpho-phonemic in Sasak affixation especially in Accepted: January 02, 2021 Ngeno-Ngene dialect. This study is a qualitative research in nature. The data were Volume: 4 collected via field linguistic method using three techniques of data collection: Issue: 1 observation, interview, and note-taking. The study used a qualitative research method DOI: 10.32996/ijllt.2021.4.1.13 to describe all morphophonemic process of affixation in Ngeno-Ngene dialect of Sasak language. The results of the study revealed that there are two affixes that KEYWORDS undergo morphophonemic process, namely, prefix be-, pe-, ng-, t-, me- and simulfix ke-an. Prefix be- can cause epenthesis (additional r ), prefix pe- causes epenthesis Morpho-phonemic, Sasak, (additional n and mi) and assimilation ( k n), prefix ng- causes assimilation (k ŋ), Affixation, Ngeno-Ngene dialect prefix t- causes epenthesis (additional e) and prefix me- causes assimilation (p m). The simulfix ke-an in this dialect causes epenthesis in which there will be lexical addition ‘r,m,n’ when the simulfix ke-an is used. 1. Introduction 1 Affixation is an integral part of a language that has been discussed widely in most of languages in the world including Sasak language. -

CLIPPING in ENGLISH SLANG NEOLOGISMS Dmytro Borys
© 2018 D. Borys Research article LEGE ARTIS Language yesterday, today, tomorrow Vol. III. No 1 2018 CLIPPING IN ENGLISH SLANG NEOLOGISMS Dmytro Borys Kyiv National Linguistic University, Kyiv, Ukraine Borys, D. (2018). Clipping in English slang neologisms. In Lege artis. Language yesterday, today, tomorrow. The journal of University of SS Cyril and Methodius in Trnava. Warsaw: De Gruyter Open, 2018, III (1), June 2018, p. 1-45. DOI: 10.2478/lart-2018-0001 ISSN 2453-8035 Abstract: The research is concerned with the phonotactic, morphotactic, graphic, logical, derivational, and syntactic features of clipped English slang neologisms coined in the early 21st century. The main preconceptions concerning clipping per se are revisited and critically rethought upon novel slang material. An innovative three-level taxonomy of clippings is outlined. The common and distinctive features of diverse types of clipping are identified and systemized. Key words: clipping, slang neologism, back-clipping, mid-clipping, fore-clipping, edge-clipping. 1. Introduction Redundancy ubiquitously permeates human life. According to Cherry, "redundancy is built into the structural forms of different languages in diverse ways" (1957: 18-19, 118). In linguistics, it accounts for adaptability as one of the driving factors of language longevity and sustainability. In lexicology, redundancy underlies the cognitive process of conceptualization (Eysenck & Keane 2000: 306-307); constitutes a prerequisite for secondary nomination and semantic shifting; contributes to assimilation of borrowings; nurtures the global trend in all-pervasive word structure simplification, affecting lexicon and beyond. In word formation, the type of redundancy involved is dimensional redundancy, which is defined as "the redundancy rate of information dimensions" (Hsia 1973: 8), as opposed to between-channel, distributional, sequential, process-memory, and semiotic redundancies (ibid., 8-9). -

Uptalk in Southern British English
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/305684920 Uptalk in Southern British English Conference Paper · May 2016 DOI: 10.21437/SpeechProsody.2016-32 CITATION READS 1 332 2 authors, including: Amalia Arvaniti University of Kent 93 PUBLICATIONS 2,044 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: Components of intonation and the structure of intonational meaning View project Modelling variability: gradience and categoriality in intonation View project All content following this page was uploaded by Amalia Arvaniti on 28 August 2016. The user has requested enhancement of the downloaded file. Speech Prosody 2016 31 May - 3 Jun 2106, Boston, USA Uptalk in Southern British English Amalia Arvaniti1, Madeleine Atkins1 1 University of Kent [email protected], [email protected] Abstract but with different melodies for each: L* L-H% is used primarily with statements, and H* H-H% and L* H-H% with questions The present study deals with the realization and function of [4]. New Zealand English also uses uptalk for both statements uptalk in Southern British English (SBE), a variety in which the and questions [3], with the tunes used for each function use of uptalk has been little investigated. Eight speakers (4 becoming increasingly distinct [5]. In Australian English, on the male, 4 female) were recorded while taking part in a Map Task other hand, uptalk is used with statements mostly when the and playing a board game. All speakers used uptalk for a variety speaker wishes to hold the floor [3]. -

The Real California1
THE REAL CALIFORNIA1 PENELOPE ECKERT AND NORMA MENDOZA-DENTON When most Americans think of California English, they might remember the stereotypes made famous by Frank and Moon Unit Zappa in their song "Valley Girl," circa 1982. "Like, totally! Gag me with a spoon! " intoned Moon Unit, instantly cementing a stereotype of California English as being primarily the province of Valley Girls and Surfer Dudes. But California is not just the land of beaches and blonds. While Hollywood images crowd our consciousness, the real California, with a population of nearly 34 million, is only 46.7% white (most of whom are not blond and most of whom don't live close to the beach or in the San Fernando Valley). California has for generations been home to a large Latino population Ð a population that today accounts for 32.4% of Californians. Also for generations it has been the home of a large Chinese-American and Japanese-American population and in recent years, with the influx of immigrants from other parts of Asia, it now boasts a large and diverse Asian American population (11.2%). Most of the sizeable African-American population (16.4%) in California speak some form of African-American Vernacular English, with few traces of surfer dude or valley girl. Each of these groups brings a distinctive style, which provides a rich set of linguistic resources for all inhabitants of the state. Ways of speaking are the outcome of stylistic activity Ð activity that people engage in collaboratively as they carve out a distinctive place for themselves in the social landscape. -

Anna Enarsson New Blends in the English Language Engelska C
Estetisk-filosofiska fakulteten Anna Enarsson New Blends in the English Language Engelska C-uppsats Termin: Höstterminen 2006 Handledare: Michael Wherrity Karlstads universitet 651 88 Karlstad Tfn 054-700 10 00 Fax 054-700 14 60 [email protected] www.kau.se Titel: New Blends in the English Language Författare: Anna Enarsson Antal sidor: 29 Abstract: The aim of this essay was to identify new blends that have entered the English language. Firstly six different word-formation processes, including blending, was described. Those were compounding, clipping, backformation, acronyming, derivation and blending. The investigation was done by using a list of blends from Wikipedia. The words were looked up in the Longman dictionary of 2005 and in a dictionary online. A google search and a corpus investigation were also conducted. The investigation suggested that most of the blends were made by clipping and the second most common form was clipping and overlapping. Blends with only overlapping was unusual and accounted for only three percent. The investigation also suggested that the most common way to create blends by clipping was to use the first part of the first word and the last part of the second word. The blends were not only investigated according to their structure but also according to the domains they occur in. This part of the investigation suggested that the blends were most frequent in the technical domain, but also in the domain of society. Table of contents 1. Introduction and aims..........................................................................................................1 -

Clipping As Morphology: Evidence from Japanese
University of Calgary PRISM: University of Calgary's Digital Repository Graduate Studies The Vault: Electronic Theses and Dissertations 2018-01-15 Clipping as Morphology: Evidence from Japanese Daniel, Adam Daniel, A. D. (2018). Clipping as Morphology: Evidence from Japanese (Unpublished master's thesis). University of Calgary, Calgary, AB. http://hdl.handle.net/1880/106310 master thesis University of Calgary graduate students retain copyright ownership and moral rights for their thesis. You may use this material in any way that is permitted by the Copyright Act or through licensing that has been assigned to the document. For uses that are not allowable under copyright legislation or licensing, you are required to seek permission. Downloaded from PRISM: https://prism.ucalgary.ca UNIVERSITY OF CALGARY Clipping as Morphology: Evidence from Japanese by Adam Drake Daniel A THESIS SUBMITTED TO THE FACULTY OF GRADUATE STUDIES IN PARTIAL FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS GRADUATE PROGRAM IN LINGUISTICS CALGARY, ALBERTA JANUARY, 2018 © Adam Drake Daniel 2018 ABSTRACT This thesis examines the role of morphology in clipping through an investigation of the Japanese language. The research objectives of this thesis are to outline the roles of morphology, phonology, and semantics in the clipping process, to distinguish patterns and types of clipping, and to explore whether the clipping process should be described in the grammar, as well as to determine whether clipped forms are organized lexically. The objectives of this thesis are met through analyzing the relevant literature, compiling and analyzing a database of Japanese clipped forms, and conducting a survey study involving native Japanese speakers. -
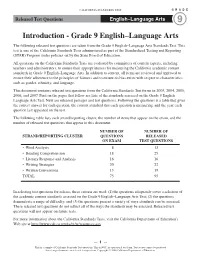
Grade 9 ELA Released Test Questions
CALIFORNIA STANDARDS TEST GRADE Released Test Questions English–Language Arts 9 Introduction - Grade 9 English–Language Arts The following released test questions are taken from the Grade 9 English–Language Arts Standards Test. This test is one of the California Standards Tests administered as part of the Standardized Testing and Reporting (STAR) Program under policies set by the State Board of Education. All questions on the California Standards Tests are evaluated by committees of content experts, including teachers and administrators, to ensure their appropriateness for measuring the California academic content standards in Grade 9 English–Language Arts. In addition to content, all items are reviewed and approved to ensure their adherence to the principles of fairness and to ensure no bias exists with respect to characteristics such as gender, ethnicity, and language. This document contains released test questions from the California Standards Test forms in 2003, 2004, 2005, 2006, and 2007. First on the pages that follow are lists of the standards assessed on the Grade 9 English– Language Arts Test. Next are released passages and test questions. Following the questions is a table that gives the correct answer for each question, the content standard that each question is measuring, and the year each question last appeared on the test. The following table lists each strand/reporting cluster, the number of items that appear on the exam, and the number of released test questions that appear in this document. NUMBER OF NUMBER OF STRAND/REPORTING -

Patterns of Vowel Production in Speakers of American English from the State of Utah
Brigham Young University BYU ScholarsArchive Theses and Dissertations 2009-08-06 Patterns of Vowel Production in Speakers of American English from the State of Utah Larkin Hopkins Reeves Brigham Young University - Provo Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Communication Sciences and Disorders Commons BYU ScholarsArchive Citation Reeves, Larkin Hopkins, "Patterns of Vowel Production in Speakers of American English from the State of Utah" (2009). Theses and Dissertations. 1886. https://scholarsarchive.byu.edu/etd/1886 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. PATTERNS OF VOWEL PRODUCTION IN SPEAKERS OF AMERICAN ENGLISH FROM THE STATE OF UTAH by Larkin Hopkins Reeves A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Science Department of Communication Disorders Brigham Young University December, 2009 BRIGHAM YOUNG UNIVERSITY GRADUATE COMMITTEE APPROVAL of a thesis submitted by Larkin Hopkins Reeves This thesis has been read by each member of the following graduate committee and by majority vote has been found to be satisfactory. Date Shawn L. Nissen, Chair Date Ron W. Channell Date Christopher Dromey BRIGHAM YOUNG UNIVERSITY As chair of the candidate’s graduate committee, I have read the thesis of Larkin Hopkins Reeves in its final form and have found that (1) its format, citations, and bibliographical style are consistent and acceptable and fulfill university and department style requirements; (2) its illustrative materials including figures, tables, and charts are in place; and (3) the final manuscript is satisfactory to the graduate committee and is ready for submission to the university library.