Forward Transliteration of Dzongkha Text to Braille
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Bhutanese and Tibetan Dzongs **
ON BHUTANESE AND TIBETAN DZONGS ** Ingun Bruskeland Amundsen** “Seen from without, it´s a rocky escarpment! Seen from within, it´s all gold and treasure!”1 There used to be impressive dzong complexes in Tibet and areas of the Himalayas with Tibetan influence. Today most of them are lost or in ruins, a few are restored as museums, and it is only in Bhutan that we find the dzongs still alive today as administration centers and monasteries. This paper reviews some of what is known about the historical developments of the dzong type of buildings in Tibet and Bhutan, and I shall thus discuss towers, khars (mkhar) and dzongs (rdzong). The first two are included in this context as they are important in the broad picture of understanding the historical background and typological developments of the later dzongs. The etymological background for the term dzong is also to be elaborated. Backdrop What we call dzongs today have a long history of development through centuries of varying religious and socio-economic conditions. Bhutanese and Tibetan histories describe periods verging on civil and religious war while others were more peaceful. The living conditions were tough, even in peaceful times. Whatever wealth one possessed had to be very well protected, whether one was a layman or a lama, since warfare and strife appear to have been endemic. Security measures * Paper presented at the workshop "The Lhasa valley: History, Conservation and Modernisation of Tibetan Architecture" at CNRS in Paris Nov. 1997, and submitted for publication in 1999. ** Ingun B. Amundsen, architect MNAL, lived and worked in Bhutan from 1987 until 1998. -

)53Lt- I'\.' -- the ENGLISH and FOREIGN LANGUAGES UNIVERSITY HYDERABAD 500605, INDIA
DZONGKHA SEGMENTS AND TONES: A PHONETIC AND PHONOLOGICAL INVESTIGATION KINLEY DORJEE . I Supervisor PROFESSOR K.G. VIJA Y AKRISHNAN Department of Linguistics and Contemporary English Hyderabad Co-supervisor Dr. T. Temsunungsang The English and Foreign Languages University Shillong Campus A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics SCHOOL OF LANGUAGE SCIENCES >. )53lt- I'\.' -- THE ENGLISH AND FOREIGN LANGUAGES UNIVERSITY HYDERABAD 500605, INDIA JULY 2011 To my mother ABSTRACT In this thesis, we make, for the first time, an acoustic investigation of supposedly unique phonemic contrasts: a four-way stop phonation contrast (voiceless, voiceless aspirated, voiced and devoiced), a three-way fricative contrast (voiceless, voiced and devoiced) and a two-way sonorant contrast (voiced and voiceless) in Dzongkha, a Tibeto-Burman language spoken in Western Bhutan. Paying special attention to the 'Devoiced' (as recorded in the literature) obstruent and the 'Voiceless' sonorants, we examine the durational and spectral characteristics, including the vowel quality (following the initial consonant types), in comparison with four other languages, viz .. Hindi. Korean (for obstruents), Mizo and Tenyidie (for sonorants). While the 'devoiced' phonation type in Dzongkha is not attested in any language in the region, we show that the devoiced type is very different from the 'breathy' phonation type, found in Hindi. However, when compared to the three-way voiceless stop phonation types (Tense, Lax and Aspirated) in Korean, we find striking similarities in the way the two stops CDevoiced' and 'Lax') employ their acoustic correlates. We extend our analysis of stops to fricatives, and analyse the three fricatives in Dzongkha as: Tense, Lax and Voiced. -

Review of Evidential Systems of Tibetan Languages
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303 Widmer, Manuel DOI: https://doi.org/10.1075/ltba.00002.wid Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-168681 Journal Article Accepted Version Originally published at: Widmer, Manuel (2017). Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303. Linguistics of the Tibeto- Burman Area, 40(2):285-303. DOI: https://doi.org/10.1075/ltba.00002.wid Review of Evidential systems of Tibetan languages Gawne, Lauren & Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. de Gruyter: Berlin. vi + 472 pp. ISBN 978-3-11-047374-2 Reviewed by Manuel Widmer 1 Tibetan evidentiality systems and their relevance for the typology of evidentiality The evidentiality1 systems of Tibetan languages rank among the most complex in the world. According to Tournadre & Dorje (2003: 110), the evidentiality systeM of Lhasa Tibetan (LT) distinguishes no less than four “evidential Moods”: (i) egophoric, (ii) testiMonial, (iii) inferential, and (iv) assertive. If one also takes into account the hearsay Marker, which is cOMMonly considered as an evidential category in typological survey studies (e.g. Aikhenvald 2004; Hengeveld & Dall’Aglio Hattnher 2015; inter alia), LT displays a five-fold evidential distinction. The LT systeM, however, is clearly not the Most cOMplex of its kind within the Tibetan linguistic area. -

The Fontspec Package Font Selection for XƎLATEX and Lualatex
The fontspec package Font selection for XƎLATEX and LuaLATEX Will Robertson and Khaled Hosny [email protected] 2013/05/12 v2.3b Contents 7.5 Different features for dif- ferent font sizes . 14 1 History 3 8 Font independent options 15 2 Introduction 3 8.1 Colour . 15 2.1 About this manual . 3 8.2 Scale . 16 2.2 Acknowledgements . 3 8.3 Interword space . 17 8.4 Post-punctuation space . 17 3 Package loading and options 4 8.5 The hyphenation character 18 3.1 Maths fonts adjustments . 4 8.6 Optical font sizes . 18 3.2 Configuration . 5 3.3 Warnings .......... 5 II OpenType 19 I General font selection 5 9 Introduction 19 9.1 How to select font features 19 4 Font selection 5 4.1 By font name . 5 10 Complete listing of OpenType 4.2 By file name . 6 font features 20 10.1 Ligatures . 20 5 Default font families 7 10.2 Letters . 20 6 New commands to select font 10.3 Numbers . 21 families 7 10.4 Contextuals . 22 6.1 More control over font 10.5 Vertical Position . 22 shape selection . 8 10.6 Fractions . 24 6.2 Math(s) fonts . 10 10.7 Stylistic Set variations . 25 6.3 Miscellaneous font select- 10.8 Character Variants . 25 ing details . 11 10.9 Alternates . 25 10.10 Style . 27 7 Selecting font features 11 10.11 Diacritics . 29 7.1 Default settings . 11 10.12 Kerning . 29 7.2 Changing the currently se- 10.13 Font transformations . 30 lected features . -

Proceedings of the Second Workshop on Advances in Text Input Methods (WTIM 2)
COLING 2012 24th International Conference on Computational Linguistics Proceedings of the Second Workshop on Advances in Text Input Methods (WTIM 2) Workshop chairs: Kalika Bali, Monojit Choudhury and Yoh Okuno 15 December 2012 Mumbai, India Diamond sponsors Tata Consultancy Services Linguistic Data Consortium for Indian Languages (LDC-IL) Gold Sponsors Microsoft Research Beijing Baidu Netcon Science Technology Co. Ltd. Silver sponsors IBM, India Private Limited Crimson Interactive Pvt. Ltd. Yahoo Easy Transcription & Software Pvt. Ltd. Proceedings of the Second Workshop on Advances in Text Input Methods (WTIM 2) Kalika Bali, Monojit Choudhury and Yoh Okuno (eds.) Revised preprint edition, 2012 Published by The COLING 2012 Organizing Committee Indian Institute of Technology Bombay, Powai, Mumbai-400076 India Phone: 91-22-25764729 Fax: 91-22-2572 0022 Email: [email protected] This volume c 2012 The COLING 2012 Organizing Committee. Licensed under the Creative Commons Attribution-Noncommercial-Share Alike 3.0 Nonported license. http://creativecommons.org/licenses/by-nc-sa/3.0/ Some rights reserved. Contributed content copyright the contributing authors. Used with permission. Also available online in the ACL Anthology at http://aclweb.org ii Preface It is our great pleasure to present the proceedings of the Second Workshop on Advances in Text Input Methods (WTIM-2) held in conjunction with Coling 2012, on 15th December 2012, in Mumbai, India. This workshop is a sequel to the first WTIM which was held in conjunction with IJCNLP 2011 in November 2011, Chiang Mai, Thailand. The aim of the current workshop remains the same as the previous one that is to bring together the researchers and developers of text input technologies around the world, and share their innovations, research findings and issues across different applications, devices, modes and languages. -

Curriculum Vitae
CURRICULUM VITAE NAME: STEPHEN A WATTERS 516 Dyer Ave Waco, TX 76708 (254) 366 - 7844 e-mail: [email protected] ACADEMIC DEGREES: PhD in Linguistics, Rice University, 2018 Thesis: A Grammar of Dzongkha: phonology, words, and simple sentences Master of Arts in Linguistics, University of Texas at Arlington, 1996 Thesis: A Preliminary Study of Prosody in Dzongkha Bachelor of Arts in Linguistics, University of Washington, 1990 (with an emphasis in database management) Associate of Arts, Peninsula College, Washington, 1986 AREAS OF SPECIAL INTEREST: Linguistic Field Research, Linguistic Typology, Languages of the Himalaya, Language Documentation, Translation, Tone Language in relation to human flourishing PROFESSIONAL EXPERIENCE: TEACHING: Adjunct Faculty, Baylor University, Jan 2015 to 2018 Instructor, Linguistic Analysis, Rice University, Fall 2014 Teaching Assistant, Linguistic Analysis, Rice University, Fall 2013 Teaching Assistant, Introduction to Linguistics, Rice University, Spring 2013 Visiting Lecturer, Central Department of Linguistics, Tribhuvan University, Kathmandu Nepal, 1998 to 2009 LINGUISTIC FIELD WORK: Visiting Research Scholar, Central Department of Linguistics, Tribhuvan University, Kathmandu, Nepal, 1998 to 2007 Sociolinguistic researcher, Indian sub-continent, SIL International, 1986 to 1988 CONSULTING and ADMINISTRATION: Translation Consultant, SIL Intl, 2001 to present International Consultant to LinSuN (Linguistic Survey of Nepal), Government of Nepal, 2007 to 2010 Technical Studies Department Coordinator, SAG, SIL Intl, 2006 to 2008 RESEARCH and APPOINTMENTS: Adjunct Researcher, LCRC, James Cook University, 2020 to present Visiting Fellow, LCRC, James Cook University, 2019 Research Director, SIL Intl, 2019 to present Pike Scholar, Pike Center for Integrative Scholarship, SIL Intl, 2019 to present Fellow, Institute for Studies of Religion, Baylor University, 2018 to present AWARDS: The James T. -

ONIX for Books Codelists Issue 40
ONIX for Books Codelists Issue 40 23 January 2018 DOI: 10.4400/akjh All ONIX standards and documentation – including this document – are copyright materials, made available free of charge for general use. A full license agreement (DOI: 10.4400/nwgj) that governs their use is available on the EDItEUR website. All ONIX users should note that this is the fourth issue of the ONIX codelists that does not include support for codelists used only with ONIX version 2.1. Of course, ONIX 2.1 remains fully usable, using Issue 36 of the codelists or earlier. Issue 36 continues to be available via the archive section of the EDItEUR website (http://www.editeur.org/15/Archived-Previous-Releases). These codelists are also available within a multilingual online browser at https://ns.editeur.org/onix. Codelists are revised quarterly. Go to latest Issue Layout of codelists This document contains ONIX for Books codelists Issue 40, intended primarily for use with ONIX 3.0. The codelists are arranged in a single table for reference and printing. They may also be used as controlled vocabularies, independent of ONIX. This document does not differentiate explicitly between codelists for ONIX 3.0 and those that are used with earlier releases, but lists used only with earlier releases have been removed. For details of which code list to use with which data element in each version of ONIX, please consult the main Specification for the appropriate release. Occasionally, a handful of codes within a particular list are defined as either deprecated, or not valid for use in a particular version of ONIX or with a particular data element. -

Map by Steve Huffman Data from World Language Mapping System 16
Tajiki Tajiki Tajiki Shughni Southern Pashto Shughni Tajiki Wakhi Wakhi Wakhi Mandarin Chinese Sanglechi-Ishkashimi Sanglechi-Ishkashimi Wakhi Domaaki Sanglechi-Ishkashimi Khowar Khowar Khowar Kati Yidgha Eastern Farsi Munji Kalasha Kati KatiKati Phalura Kalami Indus Kohistani Shina Kati Prasuni Kamviri Dameli Kalami Languages of the Gawar-Bati To rw al i Chilisso Waigali Gawar-Bati Ushojo Kohistani Shina Balti Parachi Ashkun Tregami Gowro Northwest Pashayi Southwest Pashayi Grangali Bateri Ladakhi Northeast Pashayi Southeast Pashayi Shina Purik Shina Brokskat Aimaq Parya Northern Hindko Kashmiri Northern Pashto Purik Hazaragi Ladakhi Indian Subcontinent Changthang Ormuri Gujari Kashmiri Pahari-Potwari Gujari Bhadrawahi Zangskari Southern Hindko Kashmiri Ladakhi Pangwali Churahi Dogri Pattani Gahri Ormuri Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Southern Pashto Ladakhi Central Pashto Khams Tibetan Kullu Pahari KinnauriBhoti Kinnauri Sunam Majhi Western Panjabi Mandeali Jangshung Tukpa Bilaspuri Chitkuli Kinnauri Mahasu Pahari Eastern Panjabi Panang Jaunsari Western Balochi Southern Pashto Garhwali Khetrani Hazaragi Humla Rawat Central Tibetan Waneci Rawat Brahui Seraiki DarmiyaByangsi ChaudangsiDarmiya Western Balochi Kumaoni Chaudangsi Mugom Dehwari Bagri Nepali Dolpo Haryanvi Jumli Urdu Buksa Lowa Raute Eastern Balochi Tichurong Seke Sholaga Kaike Raji Rana Tharu Sonha Nar Phu ChantyalThakali Seraiki Raji Western Parbate Kham Manangba Tibetan Kathoriya Tharu Tibetan Eastern Parbate Kham Nubri Marwari Ts um Gamale Kham Eastern -

Languages and Technology in Bhutan
Languages and Technology in Bhutan Bhutan and Languages Policy • Land area : 38,394 sq km • Enshrined in Constitution: • Population : 734,374 (2018) • Section 8, Article 1: “Dzongkha is the national language of Bhutan” • Linguistically rich country with 19 different • Section 1, Article 4: “language” and “literature” languages spoken to be preserved, protected and promoted • The Bhutanese languages are classified under • Dzongkha Development Commission is mandated Central Bodhish, East Bodhish, Bodic, and Indo- to formulate language plans and policies, develop Aryan (van Driem 1998) and promote Dzongkha, the national language • All the languages of Bhutan with the exception of and document, preserve and promote other Dzongkha, Tshangla, and Lhotsham, fall under the indigenous languages of Bhutan category of “endangered” languages. • Three languages, namely Monkha, Lhokpu, and Language policy of Bhutan Gongduk are critically endangered. can be summarized in the • One dialect kown as Olekha, a variety of Monkha form of Quadrilingual spoken in Rukha under Wangdue Dzongkhag, is a Model moribund. • ’Ucän Script is used to write Dzongkha it is consists Mother Tongue in this of thirty consonant symbols and four vowel model is the sum total of all symbols. Other languages can also be written the mother tongues in using the same script. Bhutan. Language Technology • Currently, it is limited to input, storage and display for Dzongkha • So far, very less has been done in terms of Natural Language Processing (NLP): • Dzongkha word segmentation using syllable feature – 95% accurate • Dzongkha part of speech tagging -90% accurate • Dzongkha automatic speech recognition -66% accurate • Not being able to develop technology for Dzongkha and other indigenous languages of Bhutan is a threat to our languages and culture. -

World Braille Usage, Third Edition
World Braille Usage Third Edition Perkins International Council on English Braille National Library Service for the Blind and Physically Handicapped Library of Congress UNESCO Washington, D.C. 2013 Published by Perkins 175 North Beacon Street Watertown, MA, 02472, USA International Council on English Braille c/o CNIB 1929 Bayview Avenue Toronto, Ontario Canada M4G 3E8 and National Library Service for the Blind and Physically Handicapped, Library of Congress, Washington, D.C., USA Copyright © 1954, 1990 by UNESCO. Used by permission 2013. Printed in the United States by the National Library Service for the Blind and Physically Handicapped, Library of Congress, 2013 Library of Congress Cataloging-in-Publication Data World braille usage. — Third edition. page cm Includes index. ISBN 978-0-8444-9564-4 1. Braille. 2. Blind—Printing and writing systems. I. Perkins School for the Blind. II. International Council on English Braille. III. Library of Congress. National Library Service for the Blind and Physically Handicapped. HV1669.W67 2013 411--dc23 2013013833 Contents Foreword to the Third Edition .................................................................................................. viii Acknowledgements .................................................................................................................... x The International Phonetic Alphabet .......................................................................................... xi References ............................................................................................................................ -

Pdflib-9.3.1-Tutorial.Pdf
ABC PDFlib, PDFlib+PDI, PPS A library for generating PDF on the fly PDFlib 9.3.1 Tutorial For use with C, C++, Java, .NET, .NET Core, Objective-C, Perl, PHP, Python, RPG, Ruby Copyright © 1997–2021 PDFlib GmbH and Thomas Merz. All rights reserved. PDFlib users are granted permission to reproduce printed or digital copies of this manual for internal use. PDFlib GmbH Franziska-Bilek-Weg 9, 80339 München, Germany www.pdflib.com phone +49 • 89 • 452 33 84-0 [email protected] [email protected] (please include your license number) This publication and the information herein is furnished as is, is subject to change without notice, and should not be construed as a commitment by PDFlib GmbH. PDFlib GmbH assumes no responsibility or lia- bility for any errors or inaccuracies, makes no warranty of any kind (express, implied or statutory) with re- spect to this publication, and expressly disclaims any and all warranties of merchantability, fitness for par- ticular purposes and noninfringement of third party rights. PDFlib and the PDFlib logo are registered trademarks of PDFlib GmbH. PDFlib licensees are granted the right to use the PDFlib name and logo in their product documentation. However, this is not required. PANTONE® colors displayed in the software application or in the user documentation may not match PANTONE-identified standards. Consult current PANTONE Color Publications for accurate color. PANTONE® and other Pantone, Inc. trademarks are the property of Pantone, Inc. © Pantone, Inc., 2003. Pantone, Inc. is the copyright owner of color data and/or software which are licensed to PDFlib GmbH to distribute for use only in combination with PDFlib Software. -
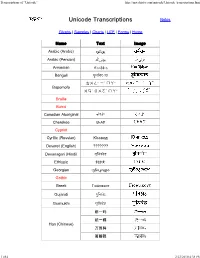
Transcriptions of “Unicode”
Transcriptions of “Unicode” http://macchiato.com/unicode/Unicode_transcriptions.html Notes Glyphs | Samples | Charts | UTF | Forms | Home Name Text Image ﻳﻮﻧِﻜﻮد (Arabic (Arabic ﯾﻮﻧﯽ ﮐُﺪ (Arabic (Persian Armenian Յունիկօդ Bengali য়ূনিকোড ㄊㄨㄥ˅ ㄧˋ ㄇㄚ˅ Bopomofo ㄨㄢˋ ㄍㄨㄛˊ ㄇㄚ˅ Braille Buhid Canadian Aboriginal ᔫsᑰᑦ Cherokee ᏳᏂᎪᏛ Cypriot Cyrillic (Russian) Юникод Deseret (English) ??????? Devanagari (Hindi) यूिनकोड Ethiopic ዩኒኮድ Georgian უნიკოდი Gothic Greek Γιούνικοντ Gujarati યૂિનકોડ Gurmukhi ਯੂਿਨਕੋਡ 统一码 統一碼 Han (Chinese) 万国码 萬國碼 1 of 4 2/22/2010 4:38 PM Transcriptions of “Unicode” http://macchiato.com/unicode/Unicode_transcriptions.html Hangul 유니코드 Hanunoo יוניקוד Hebrew יוּנִיקוׁד (Hebrew (pointed יוניקאָד (Hebrew (Yiddish Hiragana (Japanese) ゆにこおど Katakana (Japanese) ユニコード Kannada ಯೂಕೋಡ್ Khmer យូនីគោដ Lao Latin Unicode Unicode Latin (IPA) ˈjunɪˌkoːd Latin (Am. Dict.)Ūnĭcōde̽ Limbu Linear B Malayalam യൂനികോഡ് Mongolian Myanmar Ogham ᚔᚒᚅᚔᚉᚑᚇ Old Italic Oriya ୟୂନିକୋଡ Osmanya Runic (Anglo-Saxon) ᛡᚢᚾᛁᚳᚩᛞ Shavian Sinhala යණනිකෞද් Syriac ܕܘܩܝܢܘܝ Tagbanwa Tagalog Tai Le 2 of 4 2/22/2010 4:38 PM Transcriptions of “Unicode” http://macchiato.com/unicode/Unicode_transcriptions.html Tamil னிேகாட் Telugu యూనికోడ్ Thaana Thai ยูนืโคด Tibetan (Dzongkha) ཨུ་ནི་ཀོཌྲ། Ugaritic Yi Notes: There are different ways to transcribe the word “Unicode”, depending on the language and script. In some cases there is only one language that customarily uses a given script; in others there are many languages. The goal here is at a minimum to collect at least one transcription for each script in a language customarily written in that script, with more languages if possible.