Proceedings of the Second Workshop on Advances in Text Input Methods (WTIM 2)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(12) United States Patent (10) Patent No.: US 9,063,798 B2 Benedek Et Al
US009063798B2 (12) United States Patent (10) Patent No.: US 9,063,798 B2 Benedek et al. (45) Date of Patent: *Jun. 23, 2015 (54) CROSS-ENVIRONMENT COMMUNICATION (56) References Cited USINGAPPLICATION SPACE API U.S. PATENT DOCUMENTS (71) Applicant: Z124, George Town (KY) 5,396,630 A 3, 1995 Banda et al. 5,673.403 A 9, 1997 Brown et al. (72) Inventors: Laszlo Csaba Benedek, Richmond (CA); Octavian Chincisan, Richmond (Continued) Hill (CA) FOREIGN PATENT DOCUMENTS (73) Assignee: Z124, George Town (KY) JP T-219903 8, 1995 JP 08-115144 5, 1996 (*) Notice: Subject to any disclaimer, the term of this (Continued) patent is extended or adjusted under 35 OTHER PUBLICATIONS U.S.C. 154(b) by 0 days. Haselton, “Celio Announces Redfly SmartPhone Dock, Software for This patent is Subject to a terminal dis Windows PCs.” LAPTOP Magazine, Jan. 8, 2009, retrieved on Feb. claimer. 11, 2014, 4 pages. Retrieved from: blog.laptopmag.com/redfly launches-Smartphone-dock-software-for-windows-pcs. (21) Appl. No.: 14/068,662 (Continued) (22) Filed: Oct. 31, 2013 Primary Examiner — Andy Ho Assistant Examiner — Abdou Seye (65) Prior Publication Data (74) Attorney, Agent, or Firm — Sheridan Ross P.C. US 2014/OO59566A1 Feb. 27, 2014 (57) ABSTRACT A mobile computing device with a mobile operating system and desktop operating system running concurrently and inde Related U.S. Application Data pendently on a shared kernel without virtualization. The (63) Continuation of application No. 13/247,885, filed on mobile operating system provides a mobile user experience Sep. 28, 2011, now Pat. No. 8,726,294, which is a while the desktop operating system provides a full desktop continuation-in-part of application No. -

IJCNLP 2011 Proceedings of the Workshop on Advances in Text Input Methods (WTIM 2011)
IJCNLP 2011 Proceedings of the Workshop on Advances in Text Input Methods (WTIM 2011) November 13, 2011 Shangri-La Hotel Chiang Mai, Thailand IJCNLP 2011 Proceedings of the Workshop on Advances in Text Input Methods (WTIM 2011) November 13, 2011 Chiang Mai, Thailand We wish to thank our sponsors Gold Sponsors www.google.com www.baidu.com The Office of Naval Research (ONR) Department of Systems Engineering and The Asian Office of Aerospace Research and Devel- Engineering Managment, The Chinese Uni- opment (AOARD) versity of Hong Kong Silver Sponsors Microsoft Corporation Bronze Sponsors Chinese and Oriental Languages Information Processing Society (COLIPS) Supporter Thailand Convention and Exhibition Bureau (TCEB) We wish to thank our sponsors Organizers Asian Federation of Natural Language National Electronics and Computer Technolo- Processing (AFNLP) gy Center (NECTEC), Thailand Sirindhorn International Institute of Technology Rajamangala University of Technology Lanna (SIIT), Thailand (RMUTL), Thailand Chiang Mai University (CMU), Thailand Maejo University, Thailand c 2011 Asian Federation of Natural Language Proceesing vii Preface Welcome to the IJCNLP Workshop on Advances in Text Input Methods (WTIM 2011)! Methods of text input have entered a new era. The number of people who have access to computers and mobile devices is skyrocketing in regions where people do not have a convenient method of inputting their native language. It has also become commonplace to input text not through a keyboard but through different modes such as voice and handwriting recognition. Even when people input text using a keyboard, it is done differently from only a few years ago – adaptive software keyboards, word auto- completion and prediction, and spell correction are just a few examples of such recent changes in text input experience. -

The Fontspec Package Font Selection for XƎLATEX and Lualatex
The fontspec package Font selection for XƎLATEX and LuaLATEX Will Robertson and Khaled Hosny [email protected] 2013/05/12 v2.3b Contents 7.5 Different features for dif- ferent font sizes . 14 1 History 3 8 Font independent options 15 2 Introduction 3 8.1 Colour . 15 2.1 About this manual . 3 8.2 Scale . 16 2.2 Acknowledgements . 3 8.3 Interword space . 17 8.4 Post-punctuation space . 17 3 Package loading and options 4 8.5 The hyphenation character 18 3.1 Maths fonts adjustments . 4 8.6 Optical font sizes . 18 3.2 Configuration . 5 3.3 Warnings .......... 5 II OpenType 19 I General font selection 5 9 Introduction 19 9.1 How to select font features 19 4 Font selection 5 4.1 By font name . 5 10 Complete listing of OpenType 4.2 By file name . 6 font features 20 10.1 Ligatures . 20 5 Default font families 7 10.2 Letters . 20 6 New commands to select font 10.3 Numbers . 21 families 7 10.4 Contextuals . 22 6.1 More control over font 10.5 Vertical Position . 22 shape selection . 8 10.6 Fractions . 24 6.2 Math(s) fonts . 10 10.7 Stylistic Set variations . 25 6.3 Miscellaneous font select- 10.8 Character Variants . 25 ing details . 11 10.9 Alternates . 25 10.10 Style . 27 7 Selecting font features 11 10.11 Diacritics . 29 7.1 Default settings . 11 10.12 Kerning . 29 7.2 Changing the currently se- 10.13 Font transformations . 30 lected features . -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets............................................................................................................. -

GNU Texmacs User Manual Joris Van Der Hoeven
GNU TeXmacs User Manual Joris van der Hoeven To cite this version: Joris van der Hoeven. GNU TeXmacs User Manual. 2013. hal-00785535 HAL Id: hal-00785535 https://hal.archives-ouvertes.fr/hal-00785535 Preprint submitted on 6 Feb 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. GNU TEXMACS user manual Joris van der Hoeven & others Table of contents 1. Getting started ...................................... 11 1.1. Conventionsforthismanual . .......... 11 Menuentries ..................................... 11 Keyboardmodifiers ................................. 11 Keyboardshortcuts ................................ 11 Specialkeys ..................................... 11 1.2. Configuring TEXMACS ..................................... 12 1.3. Creating, saving and loading documents . ............ 12 1.4. Printingdocuments .............................. ........ 13 2. Writing simple documents ............................. 15 2.1. Generalities for typing text . ........... 15 2.2. Typingstructuredtext ........................... ......... 15 2.3. Content-basedtags -

A STUDY of WRITING Oi.Uchicago.Edu Oi.Uchicago.Edu /MAAM^MA
oi.uchicago.edu A STUDY OF WRITING oi.uchicago.edu oi.uchicago.edu /MAAM^MA. A STUDY OF "*?• ,fii WRITING REVISED EDITION I. J. GELB Phoenix Books THE UNIVERSITY OF CHICAGO PRESS oi.uchicago.edu This book is also available in a clothbound edition from THE UNIVERSITY OF CHICAGO PRESS TO THE MOKSTADS THE UNIVERSITY OF CHICAGO PRESS, CHICAGO & LONDON The University of Toronto Press, Toronto 5, Canada Copyright 1952 in the International Copyright Union. All rights reserved. Published 1952. Second Edition 1963. First Phoenix Impression 1963. Printed in the United States of America oi.uchicago.edu PREFACE HE book contains twelve chapters, but it can be broken up structurally into five parts. First, the place of writing among the various systems of human inter communication is discussed. This is followed by four Tchapters devoted to the descriptive and comparative treatment of the various types of writing in the world. The sixth chapter deals with the evolution of writing from the earliest stages of picture writing to a full alphabet. The next four chapters deal with general problems, such as the future of writing and the relationship of writing to speech, art, and religion. Of the two final chapters, one contains the first attempt to establish a full terminology of writing, the other an extensive bibliography. The aim of this study is to lay a foundation for a new science of writing which might be called grammatology. While the general histories of writing treat individual writings mainly from a descriptive-historical point of view, the new science attempts to establish general principles governing the use and evolution of writing on a comparative-typological basis. -

ONIX for Books Codelists Issue 40
ONIX for Books Codelists Issue 40 23 January 2018 DOI: 10.4400/akjh All ONIX standards and documentation – including this document – are copyright materials, made available free of charge for general use. A full license agreement (DOI: 10.4400/nwgj) that governs their use is available on the EDItEUR website. All ONIX users should note that this is the fourth issue of the ONIX codelists that does not include support for codelists used only with ONIX version 2.1. Of course, ONIX 2.1 remains fully usable, using Issue 36 of the codelists or earlier. Issue 36 continues to be available via the archive section of the EDItEUR website (http://www.editeur.org/15/Archived-Previous-Releases). These codelists are also available within a multilingual online browser at https://ns.editeur.org/onix. Codelists are revised quarterly. Go to latest Issue Layout of codelists This document contains ONIX for Books codelists Issue 40, intended primarily for use with ONIX 3.0. The codelists are arranged in a single table for reference and printing. They may also be used as controlled vocabularies, independent of ONIX. This document does not differentiate explicitly between codelists for ONIX 3.0 and those that are used with earlier releases, but lists used only with earlier releases have been removed. For details of which code list to use with which data element in each version of ONIX, please consult the main Specification for the appropriate release. Occasionally, a handful of codes within a particular list are defined as either deprecated, or not valid for use in a particular version of ONIX or with a particular data element. -

Japanese Input Method Independent of Applications
JAPANESE INPUT METHOD INDEPENDENT OF APPLICATIONS By Takahide Honma, Hiroyoshi Baba, and Kuniaki Takizawa ABSTRACT The Japanese input method is a complex procedure involving preediting operations. An application that accepts Japanese from an input device must have three systems for the input method: a keybinding system, a manipulator for preediting, and a kana-to-kanji conversion system. Various keybinding systems and manipulators accelerate input operations. Our implementation separates an application from the Japanese input method in three layers. An application can use a front-end input processor to perform all operations including I/O. An application can use the henkan (conversion) module and implement I/O operation itself. An application can execute all operations except keybinding, which is handled by an input method library. INTRODUCTION In this paper, we first present an overview of the technical environment of the Japanese input method implementation. Based on this overview, we briefly describe the critical engineering issues for conversion of Digital's products for the Japanese user. Our most critical engineering issue was the reduction of similar (but slightly different) work to localize products. Another issue was to satisfy customers' requests for the ability to use the many input styles familiar to them. We describe our approach to the development of a Japanese input method that overcomes these issues by separating the input method from an application in three layers. OVERVIEW OF THE JAPANESE INPUT METHOD In this section, we describe Japanese input and string manipulation from the perspective of both the user and the application. Based on these descriptions, we present a brief overview of reengineering a product for Japanese users and a summary of the industry's complex techniques developed for Japanese input methods. -

World Braille Usage, Third Edition
World Braille Usage Third Edition Perkins International Council on English Braille National Library Service for the Blind and Physically Handicapped Library of Congress UNESCO Washington, D.C. 2013 Published by Perkins 175 North Beacon Street Watertown, MA, 02472, USA International Council on English Braille c/o CNIB 1929 Bayview Avenue Toronto, Ontario Canada M4G 3E8 and National Library Service for the Blind and Physically Handicapped, Library of Congress, Washington, D.C., USA Copyright © 1954, 1990 by UNESCO. Used by permission 2013. Printed in the United States by the National Library Service for the Blind and Physically Handicapped, Library of Congress, 2013 Library of Congress Cataloging-in-Publication Data World braille usage. — Third edition. page cm Includes index. ISBN 978-0-8444-9564-4 1. Braille. 2. Blind—Printing and writing systems. I. Perkins School for the Blind. II. International Council on English Braille. III. Library of Congress. National Library Service for the Blind and Physically Handicapped. HV1669.W67 2013 411--dc23 2013013833 Contents Foreword to the Third Edition .................................................................................................. viii Acknowledgements .................................................................................................................... x The International Phonetic Alphabet .......................................................................................... xi References ............................................................................................................................ -

Locale Database
International Language Environments Guide Part No: 817–2521–11 November 2010 Copyright © 2005, 2010, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are “commercial computer software” or “commercial technical data” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms setforth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle America, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -

Pdflib-9.3.1-Tutorial.Pdf
ABC PDFlib, PDFlib+PDI, PPS A library for generating PDF on the fly PDFlib 9.3.1 Tutorial For use with C, C++, Java, .NET, .NET Core, Objective-C, Perl, PHP, Python, RPG, Ruby Copyright © 1997–2021 PDFlib GmbH and Thomas Merz. All rights reserved. PDFlib users are granted permission to reproduce printed or digital copies of this manual for internal use. PDFlib GmbH Franziska-Bilek-Weg 9, 80339 München, Germany www.pdflib.com phone +49 • 89 • 452 33 84-0 [email protected] [email protected] (please include your license number) This publication and the information herein is furnished as is, is subject to change without notice, and should not be construed as a commitment by PDFlib GmbH. PDFlib GmbH assumes no responsibility or lia- bility for any errors or inaccuracies, makes no warranty of any kind (express, implied or statutory) with re- spect to this publication, and expressly disclaims any and all warranties of merchantability, fitness for par- ticular purposes and noninfringement of third party rights. PDFlib and the PDFlib logo are registered trademarks of PDFlib GmbH. PDFlib licensees are granted the right to use the PDFlib name and logo in their product documentation. However, this is not required. PANTONE® colors displayed in the software application or in the user documentation may not match PANTONE-identified standards. Consult current PANTONE Color Publications for accurate color. PANTONE® and other Pantone, Inc. trademarks are the property of Pantone, Inc. © Pantone, Inc., 2003. Pantone, Inc. is the copyright owner of color data and/or software which are licensed to PDFlib GmbH to distribute for use only in combination with PDFlib Software. -
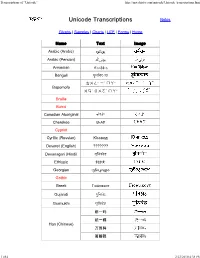
Transcriptions of “Unicode”
Transcriptions of “Unicode” http://macchiato.com/unicode/Unicode_transcriptions.html Notes Glyphs | Samples | Charts | UTF | Forms | Home Name Text Image ﻳﻮﻧِﻜﻮد (Arabic (Arabic ﯾﻮﻧﯽ ﮐُﺪ (Arabic (Persian Armenian Յունիկօդ Bengali য়ূনিকোড ㄊㄨㄥ˅ ㄧˋ ㄇㄚ˅ Bopomofo ㄨㄢˋ ㄍㄨㄛˊ ㄇㄚ˅ Braille Buhid Canadian Aboriginal ᔫsᑰᑦ Cherokee ᏳᏂᎪᏛ Cypriot Cyrillic (Russian) Юникод Deseret (English) ??????? Devanagari (Hindi) यूिनकोड Ethiopic ዩኒኮድ Georgian უნიკოდი Gothic Greek Γιούνικοντ Gujarati યૂિનકોડ Gurmukhi ਯੂਿਨਕੋਡ 统一码 統一碼 Han (Chinese) 万国码 萬國碼 1 of 4 2/22/2010 4:38 PM Transcriptions of “Unicode” http://macchiato.com/unicode/Unicode_transcriptions.html Hangul 유니코드 Hanunoo יוניקוד Hebrew יוּנִיקוׁד (Hebrew (pointed יוניקאָד (Hebrew (Yiddish Hiragana (Japanese) ゆにこおど Katakana (Japanese) ユニコード Kannada ಯೂಕೋಡ್ Khmer យូនីគោដ Lao Latin Unicode Unicode Latin (IPA) ˈjunɪˌkoːd Latin (Am. Dict.)Ūnĭcōde̽ Limbu Linear B Malayalam യൂനികോഡ് Mongolian Myanmar Ogham ᚔᚒᚅᚔᚉᚑᚇ Old Italic Oriya ୟୂନିକୋଡ Osmanya Runic (Anglo-Saxon) ᛡᚢᚾᛁᚳᚩᛞ Shavian Sinhala යණනිකෞද් Syriac ܕܘܩܝܢܘܝ Tagbanwa Tagalog Tai Le 2 of 4 2/22/2010 4:38 PM Transcriptions of “Unicode” http://macchiato.com/unicode/Unicode_transcriptions.html Tamil னிேகாட் Telugu యూనికోడ్ Thaana Thai ยูนืโคด Tibetan (Dzongkha) ཨུ་ནི་ཀོཌྲ། Ugaritic Yi Notes: There are different ways to transcribe the word “Unicode”, depending on the language and script. In some cases there is only one language that customarily uses a given script; in others there are many languages. The goal here is at a minimum to collect at least one transcription for each script in a language customarily written in that script, with more languages if possible.