Chapter 6, Writing Systems and Punctuation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Similarities and Dissimilarities of English and Arabic Alphabets in Phonetic and Phonology: a Comparative Study
Similarities and dissimilarities of English and Arabic 94 Similarities and dissimilarities of English and Arabic Alphabets in Phonetic and Phonology: A Comparative Study MD YEAQUB Research Scholar Aligarh Muslim University, India Email: [email protected] Abstract: This paper will focus on a comparative study about similarities and dissimilarities of the pronunciation between the syllables of English and Arabic with the help of phonetic and phonological tools i.e. manner of articulation, point of articulation and their distribution at different positions in English and Arabic Alphabets. A phonetic and phonological analysis of the alphabets of English and Arabic can be useful in overcoming the hindrances for those want to improve the pronunciation of both English and Arabic languages. We all know that Arabic is a Semitic language from the Afro-Asiatic Language Family. On the other hand, English is a West Germanic language from the Indo- European Language Family. Both languages show many linguistic differences at all levels of linguistic analysis, i.e. phonology, morphology, syntax, semantics, etc. For this we will take into consideration, the segmental features only, i.e. the consonant and vowel system of the two languages. So, this is better and larger to bring about pedagogical changes that can go a long way in improving pronunciation and ensuring the occurrence of desirable learners’ outcomes. Keywords: Arabic Alphabets, English Alphabets, Pronunciations, Phonetics, Phonology, manner of articulation, point of articulation. Introduction: We all know that sounds are generally divided into two i.e. consonants and vowels. A consonant is a speech sound, which obstruct the flow of air through the vocal tract. -

End-Of-Line Hyphenation of Chemical Names (IUPAC Provisional
Pure Appl. Chem. 2020; aop IUPAC Recommendations Albert J. Dijkstra*, Karl-Heinz Hellwich, Richard M. Hartshorn, Jan Reedijk and Erik Szabó End-of-line hyphenation of chemical names (IUPAC Provisional Recommendations) https://doi.org/10.1515/pac-2019-1005 Received October 16, 2019; accepted January 21, 2020 Abstract: Chemical names and in particular systematic chemical names can be so long that, when a manu- script is printed, they have to be hyphenated/divided at the end of a line. Many systematic names already contain hyphens, but sometimes not in a suitable division position. In some cases, using these hyphens as end-of-line divisions can lead to illogical divisions in print, as can also happen when hyphens are added arbi- trarily without considering the ‘chemical’ context. The present document provides recommendations and guidelines for authors of chemical manuscripts, their publishers and editors, on where to divide chemical names at the end of a line and instructions on how to avoid these names being divided at illogical places as often suggested by desk dictionaries. Instead, readability and chemical sense should prevail when authors insert optional hyphens. Accordingly, the software used to convert electronic manuscripts to print can now be programmed to avoid illogical end-of-line hyphenation and thereby save the author much time and annoy- ance when proofreading. The recommendations also allow readers of the printed article to determine which end-of-line hyphens are an integral part of the name and should not be deleted when ‘undividing’ the name. These recommendations may also prove useful in languages other than English. -

IADD BANA Braille Standards
Let Your Fingers Do The Talking: Braille on Folding Cartons in cooperation with February 2012 (Revision 1) 1 Preface 4 History of braille in folding carton production and references 2 Traditional Braille Cell and Braille Characters 5 Letters, punctuation marks, numbers, special characters 3 Standardization 7 Dot matrix, dot diameters, dot spacing, character and line spacing, embossing height, positioning the braille message 4 Technical Requirements 8 Functional and optical characteristics, material selection 5 Fabrication 9 Braille embossing, positioning of braille, amount of text 6 Prepress and Quality Assurance 12 Artwork files and print approvals, quality assurance 7 Conclusion 14 3 1 Preface In 1825, Frenchman Louis Braille (1809-1852) invented a reading system for the blind through which the alphabet, numbers and punctuation marks were represented in a tangible form via a series of raised dots. The braille system established itself internationally and is now in use in all languages. While A to Z is standardized, there are, of course, special characters which are unique to local languages. The requirement for braille on pharmaceutical packaging stems from the European Directive 2004/27/EC – amending Directive 2001/83/EC (community code to medicinal products for human use). This Directive includes changes to the label and package leaflet requirements for pharmaceuticals (which will not be discussed in this booklet). It requires pharmaceutical cartons to show the name of the medicinal products and, if need be, the strength in braille format. The influence of the European Directive is having an increasing impact on Canada, USA and other countries worldwide through the pharmaceutical packaging companies that produce for or market at an international level. -

Beginning Portable Shell Scripting from Novice to Professional
Beginning Portable Shell Scripting From Novice to Professional Peter Seebach 10436fmfinal 1 10/23/08 10:40:24 PM Beginning Portable Shell Scripting: From Novice to Professional Copyright © 2008 by Peter Seebach All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-4302-1043-6 ISBN-10 (pbk): 1-4302-1043-5 ISBN-13 (electronic): 978-1-4302-1044-3 ISBN-10 (electronic): 1-4302-1044-3 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Lead Editor: Frank Pohlmann Technical Reviewer: Gary V. Vaughan Editorial Board: Clay Andres, Steve Anglin, Ewan Buckingham, Tony Campbell, Gary Cornell, Jonathan Gennick, Michelle Lowman, Matthew Moodie, Jeffrey Pepper, Frank Pohlmann, Ben Renow-Clarke, Dominic Shakeshaft, Matt Wade, Tom Welsh Project Manager: Richard Dal Porto Copy Editor: Kim Benbow Associate Production Director: Kari Brooks-Copony Production Editor: Katie Stence Compositor: Linda Weidemann, Wolf Creek Press Proofreader: Dan Shaw Indexer: Broccoli Information Management Cover Designer: Kurt Krames Manufacturing Director: Tom Debolski Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. -

A Translation of the Malia Altar Stone
MATEC Web of Conferences 125, 05018 (2017) DOI: 10.1051/ matecconf/201712505018 CSCC 2017 A Translation of the Malia Altar Stone Peter Z. Revesz1,a 1 Department of Computer Science, University of Nebraska-Lincoln, Lincoln, NE, 68588, USA Abstract. This paper presents a translation of the Malia Altar Stone inscription (CHIC 328), which is one of the longest known Cretan Hieroglyph inscriptions. The translation uses a synoptic transliteration to several scripts that are related to the Malia Altar Stone script. The synoptic transliteration strengthens the derived phonetic values and allows avoiding certain errors that would result from reliance on just a single transliteration. The synoptic transliteration is similar to a multiple alignment of related genomes in bioinformatics in order to derive the genetic sequence of a putative common ancestor of all the aligned genomes. 1 Introduction symbols. These attempts so far were not successful in deciphering the later two scripts. Cretan Hieroglyph is a writing system that existed in Using ideas and methods from bioinformatics, eastern Crete c. 2100 – 1700 BC [13, 14, 25]. The full Revesz [20] analyzed the evolutionary relationships decipherment of Cretan Hieroglyphs requires a consistent within the Cretan script family, which includes the translation of all known Cretan Hieroglyph texts not just following scripts: Cretan Hieroglyph, Linear A, Linear B the translation of some examples. In particular, many [6], Cypriot, Greek, Phoenician, South Arabic, Old authors have suggested translations for the Phaistos Disk, Hungarian [9, 10], which is also called rovásírás in the most famous and longest Cretan Hieroglyph Hungarian and also written sometimes as Rovas in inscription, but in general they were unable to show that English language publications, and Tifinagh. -

Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging
ORIGINAL ARTICLE Neuroscience http://dx.doi.org/10.3346/jkms.2014.29.10.1416 • J Korean Med Sci 2014; 29: 1416-1424 Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging Zang-Hee Cho,1 Nambeom Kim,1 The two basic scripts of the Korean writing system, Hanja (the logography of the traditional Sungbong Bae,2 Je-Geun Chi,1 Korean character) and Hangul (the more newer Korean alphabet), have been used together Chan-Woong Park,1 Seiji Ogawa,1,3 since the 14th century. While Hanja character has its own morphemic base, Hangul being and Young-Bo Kim1 purely phonemic without morphemic base. These two, therefore, have substantially different outcomes as a language as well as different neural responses. Based on these 1Neuroscience Research Institute, Gachon University, Incheon, Korea; 2Department of linguistic differences between Hanja and Hangul, we have launched two studies; first was Psychology, Yeungnam University, Kyongsan, Korea; to find differences in cortical activation when it is stimulated by Hanja and Hangul reading 3Kansei Fukushi Research Institute, Tohoku Fukushi to support the much discussed dual-route hypothesis of logographic and phonological University, Sendai, Japan routes in the brain by fMRI (Experiment 1). The second objective was to evaluate how Received: 14 February 2014 Hanja and Hangul affect comprehension, therefore, recognition memory, specifically the Accepted: 5 July 2014 effects of semantic transparency and morphemic clarity on memory consolidation and then related cortical activations, using functional magnetic resonance imaging (fMRI) Address for Correspondence: (Experiment 2). The first fMRI experiment indicated relatively large areas of the brain are Young-Bo Kim, MD Department of Neuroscience and Neurosurgery, Gachon activated by Hanja reading compared to Hangul reading. -

The Carian Language HANDBOOK of ORIENTAL STUDIES SECTION ONE the NEAR and MIDDLE EAST
The Carian Language HANDBOOK OF ORIENTAL STUDIES SECTION ONE THE NEAR AND MIDDLE EAST Ancient Near East Editor-in-Chief W. H. van Soldt Editors G. Beckman • C. Leitz • B. A. Levine P. Michalowski • P. Miglus Middle East R. S. O’Fahey • C. H. M. Versteegh VOLUME EIGHTY-SIX The Carian Language by Ignacio J. Adiego with an appendix by Koray Konuk BRILL LEIDEN • BOSTON 2007 This book is printed on acid-free paper. Library of Congress Cataloging-in-Publication Data Adiego Lajara, Ignacio-Javier. The Carian language / by Ignacio J. Adiego ; with an appendix by Koray Konuk. p. cm. — (Handbook of Oriental studies. Section 1, The Near and Middle East ; v. 86). Includes bibliographical references. ISBN-13 : 978-90-04-15281-6 (hardback) ISBN-10 : 90-04-15281-4 (hardback) 1. Carian language. 2. Carian language—Writing. 3. Inscriptions, Carian—Egypt. 4. Inscriptions, Carian—Turkey—Caria. I. Title. II. P946.A35 2006 491’.998—dc22 2006051655 ISSN 0169-9423 ISBN-10 90 04 15281 4 ISBN-13 978 90 04 15281 6 © Copyright 2007 by Koninklijke Brill NV, Leiden, The Netherlands. Koninklijke Brill NV incorporates the imprints Brill Hotei Publishers, IDC Publishers, Martinus Nijhoff Publishers, and VSP. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Authorization to photocopy items for internal or personal use is granted by Brill provided that the appropriate fees are paid directly to The Copyright Clearance Center, 222 Rosewood Drive, Suite 910, Danvers, MA 01923, USA. -

Arabic Alphabet - Wikipedia, the Free Encyclopedia Arabic Alphabet from Wikipedia, the Free Encyclopedia
2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia Arabic alphabet From Wikipedia, the free encyclopedia َأﺑْ َﺠ ِﺪﯾﱠﺔ َﻋ َﺮﺑِﯿﱠﺔ :The Arabic alphabet (Arabic ’abjadiyyah ‘arabiyyah) or Arabic abjad is Arabic abjad the Arabic script as it is codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually[1] stand for consonants, it is classified as an abjad. Type Abjad Languages Arabic Time 400 to the present period Parent Proto-Sinaitic systems Phoenician Aramaic Syriac Nabataean Arabic abjad Child N'Ko alphabet systems ISO 15924 Arab, 160 Direction Right-to-left Unicode Arabic alias Unicode U+0600 to U+06FF range (http://www.unicode.org/charts/PDF/U0600.pdf) U+0750 to U+077F (http://www.unicode.org/charts/PDF/U0750.pdf) U+08A0 to U+08FF (http://www.unicode.org/charts/PDF/U08A0.pdf) U+FB50 to U+FDFF (http://www.unicode.org/charts/PDF/UFB50.pdf) U+FE70 to U+FEFF (http://www.unicode.org/charts/PDF/UFE70.pdf) U+1EE00 to U+1EEFF (http://www.unicode.org/charts/PDF/U1EE00.pdf) Note: This page may contain IPA phonetic symbols. Arabic alphabet ا ب ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع en.wikipedia.org/wiki/Arabic_alphabet 1/20 2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia غ ف ق ك ل م ن ه و ي History · Transliteration ء Diacritics · Hamza Numerals · Numeration V · T · E (//en.wikipedia.org/w/index.php?title=Template:Arabic_alphabet&action=edit) Contents 1 Consonants 1.1 Alphabetical order 1.2 Letter forms 1.2.1 Table of basic letters 1.2.2 Further notes -
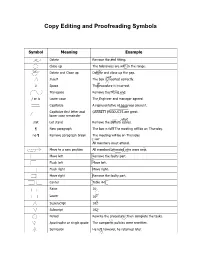
Copy Editing and Proofreading Symbols
Copy Editing and Proofreading Symbols Symbol Meaning Example Delete Remove the end fitting. Close up The tolerances are with in the range. Delete and Close up Deltete and close up the gap. not Insert The box is inserted correctly. # # Space Theprocedure is incorrect. Transpose Remove the fitting end. / or lc Lower case The Engineer and manager agreed. Capitalize A representative of nasa was present. Capitalize first letter and GARRETT PRODUCTS are great. lower case remainder stet stet Let stand Remove the battery cables. ¶ New paragraph The box is full. The meeting will be on Thursday. no ¶ Remove paragraph break The meeting will be on Thursday. no All members must attend. Move to a new position All members attended who were new. Move left Remove the faulty part. Flush left Move left. Flush right Move right. Move right Remove the faulty part. Center Table 4-1 Raise 162 Lower 162 Superscript 162 Subscript 162 . Period Rewrite the procedure. Then complete the tasks. ‘ ‘ Apostrophe or single quote The companys policies were rewritten. ; Semicolon He left however, he returned later. ; Symbol Meaning Example Colon There were three items nuts, bolts, and screws. : : , Comma Apply pressure to the first second and third bolts. , , -| Hyphen A valuable byproduct was created. sp Spell out The info was incorrect. sp Abbreviate The part was twelve feet long. || or = Align Personnel Facilities Equipment __________ Underscore The part was listed under Electrical. Run in with previous line He rewrote the pages and went home. Em dash It was the beginning so I thought. En dash The value is 120 408. -

The 2020 Los Angeles Printers Fair
The 2020 Los Angeles Printers Fair To say 2020 has been an unusual year is certainly the grand understatement of the year! As much as all of us have been forced to live inside our boxes, the pandemic has really been an opportunity to think outside the comforts of our boxes and explore new ideas. Given that restrictions are still in place for us at the International Printing Museum, we have had to rethink how to connect with our community of creative souls who normally come together each fall for the Printers Fair. Like so many other events in our lives right now, this has meant creating a virtual experience but with a twist. So, welcome to the 12th annual 2020 VIRTUAL LOS ANGELES PRINTERS FAIR at the International Printing Museum (or in your living room or studio or apartment...). The Printing Museum team has worked hard to create an exceptional online event that captures some of the magic of visiting the Printers Fair in person; we are bringing our big tent of creative artisans to your screen this year. The Virtual Los Angeles Printers Fair is a wonderful opportunity to meet book artists, letterpress printers and printmakers and peruse their work. The beauty of this world known as Book Arts is that this is already a group thinking and working outside the modern boxes of our world, using traditional machines and methods but typically with a very modern twist. We have set up the PrintersFair.com website to give you as much of an opportunity to meet these creatives, see their shops and learn about their work. -

Nonromanization: Prospects for Improving Automated Cataloging of Items in Other Writing Systems.Opinion Papers No
DOCUMENT RESUME ED 354 915 IR 054 501 AUTHOR Agenbroad, James Edward TITLE Nonromanization: Prospects for Improving Automated Cataloging of Items in Other Writing Systems.Opinion Papers No. 3. INSTITUTION Library of Congress, Washington, D.C. PUB DATE 92 NOTE 20p.; Version of a paper presented ata meeting of the Library of Congress Cataloging Forum (Washington, DC, July 22, 1991). A product of the Cataloging Forum. AVAILABLE FROMCataloging Forum Steering Committee, Libraryof Congress, Washington, DC 20402. PUB TYPE Reports Evaluative/Feasibility (142) Speeches /Conference Papers (150) EDRS PRICE MFO1 /PCO1 Plus Postage. DESCRIPTORS *Bibliographic Records; Classification; Cyrillic Alphabet; Ideography; Indo European Languages; Library Automation; Library Catalogs; *Library Technical Processes; *Machine Readable Cataloging; *Non Roman Scripts; Online Catalogs;Semitic Languages; Standards; *Written Language IDENTIFIERS Asian Languages; Indic Languages; MARC; *Unicode ABSTRACT The dilemma of cataloging works in writingsystems other than the roman alphabet is explored.Some characteristics of these writing system are reviewed, and theimplications of these characteristics for input, retrieval, sorting,and display needed for adequate online catalogs of such worksare considered. Reasons why needs have not been met are discussed, andsome of the ways they might be met are examined. The followingare four groups into which non-roman systems are generally divided for simplicityand features that have implications for cataloging: (1)European scripts--upper and lower case (Greek, Cyrillic, and Armenian);(2) Semitic scripts--read right to left (Hebrew and Arabic);(3) Indic scripts--implicit vowel (indigenous scriptsof India and Nepal); and (4) East Asian scripts--verylarge character repertoires (Chinese, Korean, and Japanese). Unicode, which isan effort to define a character set that includes the letters,punctuation, and characters for all the world's writing systemsoffers assistance in cataloging, and will probably becomean international standard late in 1992. -

Proposal for Ethiopic Script Root Zone LGR
Proposal for Ethiopic Script Root Zone LGR LGR Version 2 Date: 2017-05-17 Document version:5.2 Authors: Ethiopic Script Generation Panel Contents 1 General Information/ Overview/ Abstract ........................................................................................ 3 2 Script for which the LGR is proposed ................................................................................................ 3 3 Background on Script and Principal Languages Using It .................................................................... 4 3.1 Local Languages Using the Script .............................................................................................. 4 3.2 Geographic Territories of the Language or the Language Map of Ethiopia ................................ 7 4 Overall Development Process and Methodology .............................................................................. 8 4.1 Sources Consulted to Determine the Repertoire....................................................................... 8 4.2 Team Composition and Diversity .............................................................................................. 9 4.3 Analysis of Code Point Repertoire .......................................................................................... 10 4.4 Analysis of Code Point Variants .............................................................................................. 11 5 Repertoire ....................................................................................................................................