The Phonetic Structure of Dzongkha: a Preliminary Study∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Bhutanese and Tibetan Dzongs **
ON BHUTANESE AND TIBETAN DZONGS ** Ingun Bruskeland Amundsen** “Seen from without, it´s a rocky escarpment! Seen from within, it´s all gold and treasure!”1 There used to be impressive dzong complexes in Tibet and areas of the Himalayas with Tibetan influence. Today most of them are lost or in ruins, a few are restored as museums, and it is only in Bhutan that we find the dzongs still alive today as administration centers and monasteries. This paper reviews some of what is known about the historical developments of the dzong type of buildings in Tibet and Bhutan, and I shall thus discuss towers, khars (mkhar) and dzongs (rdzong). The first two are included in this context as they are important in the broad picture of understanding the historical background and typological developments of the later dzongs. The etymological background for the term dzong is also to be elaborated. Backdrop What we call dzongs today have a long history of development through centuries of varying religious and socio-economic conditions. Bhutanese and Tibetan histories describe periods verging on civil and religious war while others were more peaceful. The living conditions were tough, even in peaceful times. Whatever wealth one possessed had to be very well protected, whether one was a layman or a lama, since warfare and strife appear to have been endemic. Security measures * Paper presented at the workshop "The Lhasa valley: History, Conservation and Modernisation of Tibetan Architecture" at CNRS in Paris Nov. 1997, and submitted for publication in 1999. ** Ingun B. Amundsen, architect MNAL, lived and worked in Bhutan from 1987 until 1998. -

)53Lt- I'\.' -- the ENGLISH and FOREIGN LANGUAGES UNIVERSITY HYDERABAD 500605, INDIA
DZONGKHA SEGMENTS AND TONES: A PHONETIC AND PHONOLOGICAL INVESTIGATION KINLEY DORJEE . I Supervisor PROFESSOR K.G. VIJA Y AKRISHNAN Department of Linguistics and Contemporary English Hyderabad Co-supervisor Dr. T. Temsunungsang The English and Foreign Languages University Shillong Campus A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics SCHOOL OF LANGUAGE SCIENCES >. )53lt- I'\.' -- THE ENGLISH AND FOREIGN LANGUAGES UNIVERSITY HYDERABAD 500605, INDIA JULY 2011 To my mother ABSTRACT In this thesis, we make, for the first time, an acoustic investigation of supposedly unique phonemic contrasts: a four-way stop phonation contrast (voiceless, voiceless aspirated, voiced and devoiced), a three-way fricative contrast (voiceless, voiced and devoiced) and a two-way sonorant contrast (voiced and voiceless) in Dzongkha, a Tibeto-Burman language spoken in Western Bhutan. Paying special attention to the 'Devoiced' (as recorded in the literature) obstruent and the 'Voiceless' sonorants, we examine the durational and spectral characteristics, including the vowel quality (following the initial consonant types), in comparison with four other languages, viz .. Hindi. Korean (for obstruents), Mizo and Tenyidie (for sonorants). While the 'devoiced' phonation type in Dzongkha is not attested in any language in the region, we show that the devoiced type is very different from the 'breathy' phonation type, found in Hindi. However, when compared to the three-way voiceless stop phonation types (Tense, Lax and Aspirated) in Korean, we find striking similarities in the way the two stops CDevoiced' and 'Lax') employ their acoustic correlates. We extend our analysis of stops to fricatives, and analyse the three fricatives in Dzongkha as: Tense, Lax and Voiced. -

Review of Evidential Systems of Tibetan Languages
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303 Widmer, Manuel DOI: https://doi.org/10.1075/ltba.00002.wid Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-168681 Journal Article Accepted Version Originally published at: Widmer, Manuel (2017). Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303. Linguistics of the Tibeto- Burman Area, 40(2):285-303. DOI: https://doi.org/10.1075/ltba.00002.wid Review of Evidential systems of Tibetan languages Gawne, Lauren & Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. de Gruyter: Berlin. vi + 472 pp. ISBN 978-3-11-047374-2 Reviewed by Manuel Widmer 1 Tibetan evidentiality systems and their relevance for the typology of evidentiality The evidentiality1 systems of Tibetan languages rank among the most complex in the world. According to Tournadre & Dorje (2003: 110), the evidentiality systeM of Lhasa Tibetan (LT) distinguishes no less than four “evidential Moods”: (i) egophoric, (ii) testiMonial, (iii) inferential, and (iv) assertive. If one also takes into account the hearsay Marker, which is cOMMonly considered as an evidential category in typological survey studies (e.g. Aikhenvald 2004; Hengeveld & Dall’Aglio Hattnher 2015; inter alia), LT displays a five-fold evidential distinction. The LT systeM, however, is clearly not the Most cOMplex of its kind within the Tibetan linguistic area. -

Curriculum Vitae
CURRICULUM VITAE NAME: STEPHEN A WATTERS 516 Dyer Ave Waco, TX 76708 (254) 366 - 7844 e-mail: [email protected] ACADEMIC DEGREES: PhD in Linguistics, Rice University, 2018 Thesis: A Grammar of Dzongkha: phonology, words, and simple sentences Master of Arts in Linguistics, University of Texas at Arlington, 1996 Thesis: A Preliminary Study of Prosody in Dzongkha Bachelor of Arts in Linguistics, University of Washington, 1990 (with an emphasis in database management) Associate of Arts, Peninsula College, Washington, 1986 AREAS OF SPECIAL INTEREST: Linguistic Field Research, Linguistic Typology, Languages of the Himalaya, Language Documentation, Translation, Tone Language in relation to human flourishing PROFESSIONAL EXPERIENCE: TEACHING: Adjunct Faculty, Baylor University, Jan 2015 to 2018 Instructor, Linguistic Analysis, Rice University, Fall 2014 Teaching Assistant, Linguistic Analysis, Rice University, Fall 2013 Teaching Assistant, Introduction to Linguistics, Rice University, Spring 2013 Visiting Lecturer, Central Department of Linguistics, Tribhuvan University, Kathmandu Nepal, 1998 to 2009 LINGUISTIC FIELD WORK: Visiting Research Scholar, Central Department of Linguistics, Tribhuvan University, Kathmandu, Nepal, 1998 to 2007 Sociolinguistic researcher, Indian sub-continent, SIL International, 1986 to 1988 CONSULTING and ADMINISTRATION: Translation Consultant, SIL Intl, 2001 to present International Consultant to LinSuN (Linguistic Survey of Nepal), Government of Nepal, 2007 to 2010 Technical Studies Department Coordinator, SAG, SIL Intl, 2006 to 2008 RESEARCH and APPOINTMENTS: Adjunct Researcher, LCRC, James Cook University, 2020 to present Visiting Fellow, LCRC, James Cook University, 2019 Research Director, SIL Intl, 2019 to present Pike Scholar, Pike Center for Integrative Scholarship, SIL Intl, 2019 to present Fellow, Institute for Studies of Religion, Baylor University, 2018 to present AWARDS: The James T. -

Map by Steve Huffman Data from World Language Mapping System 16
Tajiki Tajiki Tajiki Shughni Southern Pashto Shughni Tajiki Wakhi Wakhi Wakhi Mandarin Chinese Sanglechi-Ishkashimi Sanglechi-Ishkashimi Wakhi Domaaki Sanglechi-Ishkashimi Khowar Khowar Khowar Kati Yidgha Eastern Farsi Munji Kalasha Kati KatiKati Phalura Kalami Indus Kohistani Shina Kati Prasuni Kamviri Dameli Kalami Languages of the Gawar-Bati To rw al i Chilisso Waigali Gawar-Bati Ushojo Kohistani Shina Balti Parachi Ashkun Tregami Gowro Northwest Pashayi Southwest Pashayi Grangali Bateri Ladakhi Northeast Pashayi Southeast Pashayi Shina Purik Shina Brokskat Aimaq Parya Northern Hindko Kashmiri Northern Pashto Purik Hazaragi Ladakhi Indian Subcontinent Changthang Ormuri Gujari Kashmiri Pahari-Potwari Gujari Bhadrawahi Zangskari Southern Hindko Kashmiri Ladakhi Pangwali Churahi Dogri Pattani Gahri Ormuri Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Southern Pashto Ladakhi Central Pashto Khams Tibetan Kullu Pahari KinnauriBhoti Kinnauri Sunam Majhi Western Panjabi Mandeali Jangshung Tukpa Bilaspuri Chitkuli Kinnauri Mahasu Pahari Eastern Panjabi Panang Jaunsari Western Balochi Southern Pashto Garhwali Khetrani Hazaragi Humla Rawat Central Tibetan Waneci Rawat Brahui Seraiki DarmiyaByangsi ChaudangsiDarmiya Western Balochi Kumaoni Chaudangsi Mugom Dehwari Bagri Nepali Dolpo Haryanvi Jumli Urdu Buksa Lowa Raute Eastern Balochi Tichurong Seke Sholaga Kaike Raji Rana Tharu Sonha Nar Phu ChantyalThakali Seraiki Raji Western Parbate Kham Manangba Tibetan Kathoriya Tharu Tibetan Eastern Parbate Kham Nubri Marwari Ts um Gamale Kham Eastern -

Languages and Technology in Bhutan
Languages and Technology in Bhutan Bhutan and Languages Policy • Land area : 38,394 sq km • Enshrined in Constitution: • Population : 734,374 (2018) • Section 8, Article 1: “Dzongkha is the national language of Bhutan” • Linguistically rich country with 19 different • Section 1, Article 4: “language” and “literature” languages spoken to be preserved, protected and promoted • The Bhutanese languages are classified under • Dzongkha Development Commission is mandated Central Bodhish, East Bodhish, Bodic, and Indo- to formulate language plans and policies, develop Aryan (van Driem 1998) and promote Dzongkha, the national language • All the languages of Bhutan with the exception of and document, preserve and promote other Dzongkha, Tshangla, and Lhotsham, fall under the indigenous languages of Bhutan category of “endangered” languages. • Three languages, namely Monkha, Lhokpu, and Language policy of Bhutan Gongduk are critically endangered. can be summarized in the • One dialect kown as Olekha, a variety of Monkha form of Quadrilingual spoken in Rukha under Wangdue Dzongkhag, is a Model moribund. • ’Ucän Script is used to write Dzongkha it is consists Mother Tongue in this of thirty consonant symbols and four vowel model is the sum total of all symbols. Other languages can also be written the mother tongues in using the same script. Bhutan. Language Technology • Currently, it is limited to input, storage and display for Dzongkha • So far, very less has been done in terms of Natural Language Processing (NLP): • Dzongkha word segmentation using syllable feature – 95% accurate • Dzongkha part of speech tagging -90% accurate • Dzongkha automatic speech recognition -66% accurate • Not being able to develop technology for Dzongkha and other indigenous languages of Bhutan is a threat to our languages and culture. -

Evidential Systems of Tibetan Languages Trends in Linguistics Studies and Monographs
Lauren Gawne, Nathan W. Hill (Eds.) Evidential Systems of Tibetan Languages Trends in Linguistics Studies and Monographs Editor Volker Gast Editorial Board Walter Bisang Jan Terje Faarlund Hans Henrich Hock Natalia Levshina Heiko Narrog Matthias Schlesewsky Amir Zeldes Niina Ning Zhang Editor responsible for this volume Walter Bisang and Volker Gast Volume 302 Evidential Systems of Tibetan Languages Edited by Lauren Gawne Nathan W. Hill ISBN 978-3-11-046018-6 e-ISBN (PDF) 978-3-11-047374-2 e-ISBN (EPUB) 978-3-11-047187-8 ISSN 1861-4302 Library of Congress Cataloging-in-Publication Data A CIP catalog record for this book has been applied for at the Library of Congress. Bibliografische Information der Deutschen Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutschen Nationalbibliografie; detailed bibliographic data are available on the internet http://dnb.dnb.de. © 2017 Walter de Gruyter GmbH, Berlin/Boston Typesetting: Compuscript Ltd., Shannon, Ireland Printing and binding: CPI books GmbH, Leck ♾ Printed on acid-free paper Printed in Germany www.degruyter.com Contents Nathan W. Hill and Lauren Gawne 1 The contribution of Tibetan languages to the study of evidentiality 1 Typology and history Shiho Ebihara 2 Evidentiality of the Tibetan verb snang 41 Lauren Gawne 3 Egophoric evidentiality in Bodish languages 61 Nicolas Tournadre 4 A typological sketch of evidential/epistemic categories in the Tibetic languages 95 Nathan W. Hill 5 Perfect experiential constructions: the inferential semantics of direct evidence 131 Guillaume Oisel 6 On the origin of the Lhasa Tibetan evidentials song and byung 161 Lhasa and Diasporic Tibetan Yasutoshi Yukawa 7 Lhasa Tibetan predicates 187 Nancy J. -

Language Policy in Bhutan
Language Policy in Bhutan George van Driem (University ofLeiden) The linguistic situation in Bhutan is complex. Nineteen different languages are spoken in this Himalayan kingdom, which is only slightly larger than the Netherlands but comprises considerably less habitable surface area. The population numbers approximately 650,000 and there is no majority language. The Royal Government of Bhutan has adopted an official language policy ain:ed at establishing a single national language and also accommodating and preserving the country's linguistic diversity. The government's language policy is a balanced approach characterised by two complementary policy lines. The first line of policy is the promotion' of Dzongkha as the national language. The second line of policy is the preservation and, indeed, study of the country's rich linguistic and cultural heritage. Here I shall provide a sketch of the ethnolinguistic make-up of the country, explain the rationale behind both of the Royal Government's language policy guidelines, and elucidate how both guidelines are being implemented in practice.1 The linguistic situation in Bhutan This section is a concise sketch of the ethnolinguistic situation in Bhutan, of which I provide a more detailed and historical account elsewhere (van Driem 1993b). Reliable language statistics are provided in the table below. These statistics are based on unreleased Bhutanese census data, estimates by knowledgeable foreign specialists working in Bhutan, local village authorities and my own roof counts during the linguistic survey work which has taken me throughout Bhutan. In order to properly assess these statistics, however, certain background in formation is required. First of all, Dzongkha is the only language with a native literary tradition in Bhutan. -
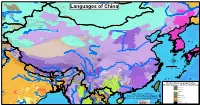
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

General Editor, Phonological Inventories of Tibeto-Burman
STEDT Monograph Series, No. 3 PHONOLOGICAL INVENTORIES OF TIBETO-BURMAN LANGUAGES Sino-Tibetan Etymological Dictionary and Thesaurus Monograph Series General Editor James A. Matisoff University of California, Berkeley STEDT Monograph 1: Bibliography of the International Conferences on Sino-Tibetan Languages and Linguistics I-XXI (1989) Randy J. LaPolla and John B. Lowe with Amy Dolcourt lix, 292 pages out of print STEDT Monograph 1A: Bibliography of the International Conferences on Sino-Tibetan Languages and Linguistics I-XXV (1994) Randy J. LaPolla and John B. Lowe lxiv, 308 pages $32.00 + shipping and handling STEDT Monograph 2: Languages and Dialects of Tibeto-Burman (1996) James A. Matisoff with Stephen P. Baron and John B. Lowe xxx, 180 pages $20.00 + shipping and handling STEDT Monograph 3: Phonological Inventories of Tibeto-Burman Languages (1996) Ju Namkung, editor xxviii, 507 pages $35.00 + shipping and handling Shipping and Handling: Domestic: $4.00 for first volume + $2.00 for each additional volume International: $6.00 for first volume + $2.50 for each additional volume Orders must be prepaid. Please make checks payable to ‘UC Regents’. Visa and Mastercard accepted. California residents must include sales tax. To place orders or to request order forms, contact: IAS Publications Office University of California, Berkeley 2223 Fulton St. 3rd Floor #2324 Berkeley CA 94720-2324 Phone: (510) 642-4065 FAX: (510) 643-7062 STEDT Monograph Series, No. 3 James A. Matisoff, General Editor PHONOLOGICAL INVENTORIES OF TIBETO-BURMAN LANGUAGES Ju Namkung, Editor Sino-Tibetan Etymological Dictionary and Thesaurus Project Center for Southeast Asia Studies University of California, Berkeley 1996 Distributed by: Center for Southeast Asia Studies 2223 Fulton St. -

Lost Syllables and Tone Contour in Dzongkha (Bhutan) Boyd Michailovsky, Martine Mazaudon
Lost syllables and tone contour in Dzongkha (Bhutan) Boyd Michailovsky, Martine Mazaudon To cite this version: Boyd Michailovsky, Martine Mazaudon. Lost syllables and tone contour in Dzongkha (Bhutan). Prosodic analysis and Asian linguistics: to honour R. K. Sprigg, Pacific Linguistics, pp.115-136, 1988, Pacific Linguistics Series C No. 104. halshs-00009231 HAL Id: halshs-00009231 https://halshs.archives-ouvertes.fr/halshs-00009231 Submitted on 22 Feb 2006 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Preprint and epilogue available online: http://halshs.ccsd.cnrs.fr/aut/michailovsky/ LOST SYLLABLES AND TONE CONTOUR IN DZONGKHA (BHUTAN) Martine Mazaudon and Boyd Michailovsky 1. Introduction In the present article1 we will point out a hitherto undescribed phonological opposition in Dzongkha, the national language of Bhutan, and attempt to trace its origin by comparison with the forms of Classical Tibetan. The contrast between high and low register words in Central Tibetan and its relationship to the voicing opposition of Tibetan orthography has been long established (Jäschke, 1881:xiii). Later authors, among them prominently Dr R. K. Sprigg, have devoted much attention to refining the analysis (Sprigg, 1954, 1955) and extending it to other dialects, for instance in Sprigg (1966) and mainly Sprigg (1972) which underlines the role of initial clusters. -

Linguistics of the Himalayas and Beyond
Linguistics of the Himalayas and Beyond edited by Roland Bielmeier Felix Haller Mouton de Gruyter Berlin • New York Contents Editorial . v Reasons for language shift: Theories, myths and counterevidence 1 Dorte Borchers Directionals in Tokpe Gola Tibetan discourse 23 Nancy J. Caplow The language history of Tibetan 47 Philip Denwood Dzala and Dakpa form a coherent subgroup within East Bodish, and some related thoughts 71 George van Driem Stem alternation and verbal valence in Themchen Tibetan 85 Felix Holier A comparative and historical study of demonstratives and plural markers in Tamangic languages 97 Isao Honda Grammatical peculiarities of two dialects of southern Kham Tibetan 119 Krisadawan Hongladarom The Sampang word accent: Phonetic realisation and phonological function 153 RendHuysmans A low glide in Marphali 163 Martine Mazaudon Pronominally marked noun determiners in Limbu 189 Boyd Michailovsky xii Contents About Chaurasia 203 Jean Robert Opgenort Implications of labial place assimilation in Amdo Tibetan 225 KarlA.Peet Context shift and linguistic coding in Kinnauri narratives 247 Anju Saxena The status of Bunan in the Tibeto-Burman family 265 Suhnu Ram Sharma Tibetan orthography, the Balti dialect, and a contemporary phonological theory 279 Richard K. Sprigg Case-marked PRO: Evidence from Rabha, Manipuri, Hindi-Urdu and Telugu 291 Karumuri Venkata Subbarao, Upen Rabha Hakacham, and Thokchom Sarju Devi Perfective stem renovation in Khalong Tibetan 323 Jackson T.-S. Sun On the deictic patterns in Kinnauri (Pangi dialect) 341 Yoshiharu Takahashi Tibetan grammar and. the active/stative case-marking type 355 Ralf Vollmann The nature of narrative text in Dzongkha: Evidence from deixis, evidentially, and mirativity 381 Stephen A.