Set Expansion Using Sibling Relations Between Semantic Categories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Perspectives of Research for Intangible Cultural Heritage
束 9mm Proceedings ISBN : 978-4-9909775-1-1 of the International Researchers Forum: Perspectives Research for Intangible Cultural Heritage towards a Sustainable Society Proceedings of International Researchers Forum: Perspectives of Research for Intangible Cultural Heritage towards a Sustainable Society 17-18 December 2019 Tokyo Japan Organised by International Research Centre for Intangible Cultural Heritage in the Asia-Pacific Region (IRCI), National Institutes for Cultural Heritage Agency for Cultural Affairs, Japan Co-organised by Tokyo National Research Institute for Cultural Properties, National Institutes for Cultural Heritage IRCI Proceedings of International Researchers Forum: Perspectives of Research for Intangible Cultural Heritage towards a Sustainable Society 17-18 December 2019 Tokyo Japan Organised by International Research Centre for Intangible Cultural Heritage in the Asia-Pacific Region (IRCI), National Institutes for Cultural Heritage Agency for Cultural Affairs, Japan Co-organised by Tokyo National Research Institute for Cultural Properties, National Institutes for Cultural Heritage Published by International Research Centre for Intangible Cultural Heritage in the Asia-Pacific Region (IRCI), National Institutes for Cultural Heritage 2 cho, Mozusekiun-cho, Sakai-ku, Sakai City, Osaka 590-0802, Japan Tel: +81 – 72 – 275 – 8050 Email: [email protected] Website: https://www.irci.jp © International Research Centre for Intangible Cultural Heritage in the Asia-Pacific Region (IRCI) Published on 10 March 2020 Preface The International Researchers Forum: Perspectives of Research for Intangible Cultural Heritage towards a Sustainable Society was organised by the International Research Centre for Intangible Cultural Heritage in the Asia-Pacific Region (IRCI) in cooperation with the Agency for Cultural Affairs of Japan and the Tokyo National Research Institute for Cultural Properties on 17–18 December 2019. -

Representations of Pleasure and Worship in Sankei Mandara Talia J
Mapping Sacred Spaces: Representations of Pleasure and Worship in Sankei mandara Talia J. Andrei Submitted in partial fulfillment of the Requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences Columbia University 2016 © 2016 Talia J.Andrei All rights reserved Abstract Mapping Sacred Spaces: Representations of Pleasure and Worship in Sankei Mandara Talia J. Andrei This dissertation examines the historical and artistic circumstances behind the emergence in late medieval Japan of a short-lived genre of painting referred to as sankei mandara (pilgrimage mandalas). The paintings are large-scale topographical depictions of sacred sites and served as promotional material for temples and shrines in need of financial support to encourage pilgrimage, offering travelers worldly and spiritual benefits while inspiring them to donate liberally. Itinerant monks and nuns used the mandara in recitation performances (etoki) to lead audiences on virtual pilgrimages, decoding the pictorial clues and touting the benefits of the site shown. Addressing themselves to the newly risen commoner class following the collapse of the aristocratic order, sankei mandara depict commoners in the role of patron and pilgrim, the first instance of them being portrayed this way, alongside warriors and aristocrats as they make their way to the sites, enjoying the local delights, and worship on the sacred grounds. Together with the novel subject material, a new artistic language was created— schematic, colorful and bold. We begin by locating sankei mandara’s artistic roots and influences and then proceed to investigate the individual mandara devoted to three sacred sites: Mt. Fuji, Kiyomizudera and Ise Shrine (a sacred mountain, temple and shrine, respectively). -
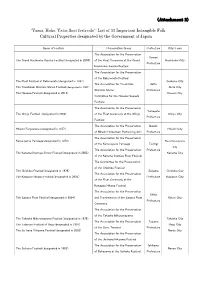
(Attachment 2)“Yama, Hoko, Yatai Float Festivals”: List of 33 Important
( ) Attachment 2 “Yama, Hoko, Yatai float festivals”: List of 33 Important Intangible Folk Cultural Properties designated by the Government of Japan Name of Festival Preservation Group Prefecture City/Town The Association for the Preservation Aomori The Grand Hachinohe Sansha Festival(designated in 2004) of the Float Ceremony at the Grand Hachinohe City Prefecture Hachinohe Sansha Festival The Association for the Preservation of the Kakunodate Festival The Float Festival of Kakunodate(designated in 1991) Senboku City The Association for Tsuchizaki Akita The Tsuchizaki Shimmei Shrine Festival(designated in 1997) Akita City Shimmei Shrine Prefecture The Hanawa Festival(designated in 2014) Kazuno City Committee for the Hanawa-bayashi Festival The Association for the Preservation Yamagata The Shinjo Festival (designated in 2009) of the Float Ceremony at the Shinjo Shinjo City Prefecture Festival The Association for the Preservation Ibaraki Hitachi Furyumono(designated in 1977) Hitachi City of Hitachi Hometown Performing Arts Prefecture The Association for the Preservation Karasuyama Yamaage(designated in 1979) Nasu Karasuyama of the Karasuyama Yamaage Tochigi City The Association for the Preservation Prefecture The Kanuma Imamiya Shrine Festival(designated in 2003) Kanuma City of the Kanuma Imamiya Float Festival The Committee for the Preservation of the Chichibu Festival The Chichibu Festival(designated in 1979) Saitama Chichibu City The Association for the Preservation The Kawagoe Hikawa Festival(designated in 2005) Prefecture Kawagoe City -

Meisho Zue and the Mapping of Prosperity in Late Tokugawa Japan
Meisho Zue and the Mapping of Prosperity in Late Tokugawa Japan Robert Goree, Wellesley College Abstract The cartographic history of Japan is remarkable for the sophistication, variety, and ingenuity of its maps. It is also remarkable for its many modes of spatial representation, which might not immediately seem cartographic but could very well be thought of as such. To understand the alterity of these cartographic modes and write Japanese map history for what it is, rather than what it is not, scholars need to be equipped with capacious definitions of maps not limited by modern Eurocentric expectations. This article explores such classificatory flexibility through an analysis of the mapping function of meisho zue, popular multivolume geographic encyclopedias published in Japan during the eighteenth and nineteenth centuries. The article’s central contention is that the illustrations in meisho zue function as pictorial maps, both as individual compositions and in the aggregate. The main example offered is Miyako meisho zue (1780), which is shown to function like a map on account of its instrumental pictorial representation of landscape, virtual wayfinding capacity, spatial layout as a book, and biased selection of sites that contribute to a vision of prosperity. This last claim about site selection exposes the depiction of meisho as a means by which the editors of meisho zue recorded a version of cultural geography that normalized this vision of prosperity. Keywords: Japan, cartography, Akisato Ritō, meisho zue, illustrated book, map, prosperity Entertaining exhibitions arrayed on the dry bed of the Kamo River distracted throngs of people seeking relief from the summer heat in Tokugawa-era Kyoto.1 By the time Osaka-based ukiyo-e artist Takehara Shunchōsai (fl. -

A POPULAR DICTIONARY of Shinto
A POPULAR DICTIONARY OF Shinto A POPULAR DICTIONARY OF Shinto BRIAN BOCKING Curzon First published by Curzon Press 15 The Quadrant, Richmond Surrey, TW9 1BP This edition published in the Taylor & Francis e-Library, 2005. “To purchase your own copy of this or any of Taylor & Francis or Routledge’s collection of thousands of eBooks please go to http://www.ebookstore.tandf.co.uk/.” Copyright © 1995 by Brian Bocking Revised edition 1997 Cover photograph by Sharon Hoogstraten Cover design by Kim Bartko All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of the publisher. British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library ISBN 0-203-98627-X Master e-book ISBN ISBN 0-7007-1051-5 (Print Edition) To Shelagh INTRODUCTION How to use this dictionary A Popular Dictionary of Shintō lists in alphabetical order more than a thousand terms relating to Shintō. Almost all are Japanese terms. The dictionary can be used in the ordinary way if the Shintō term you want to look up is already in Japanese (e.g. kami rather than ‘deity’) and has a main entry in the dictionary. If, as is very likely, the concept or word you want is in English such as ‘pollution’, ‘children’, ‘shrine’, etc., or perhaps a place-name like ‘Kyōto’ or ‘Akita’ which does not have a main entry, then consult the comprehensive Thematic Index of English and Japanese terms at the end of the Dictionary first. -

The Akamon of the Kaga Mansion and Daimyō Gateway Architecture in Edo1
AUTOR INVITADO Mirai. Estudios Japoneses ISSN-e: 1988-2378 http://dx.doi.org/10.5209/MIRA.57100 Painting the town red: The Akamon of the Kaga mansion and daimyō gateway architecture in Edo1 William H. Coaldrake2 Abstract: Built in 1827 to commemorate the marriage of the daimyō Maeda Nariyasu to a daughter of the shogun Tokugawa Ienari, the Akamon or ‘Red Gateway’ of the University of Tokyo, is generally claimed to be a unique gateway because of its distinctive colour and architectural style. This article uses an inter- disciplinary methodology, drawing on architectural history, law and art history, to refute this view of the Akamon. It analyses and accounts for the architectural form of the gateway and its ancillary guard houses (bansho) by examining Tokugawa bakufu architectural regulations (oboegaki) and the depiction of daimyō gateways in doro-e and ukiyo-e. It concludes that there were close similarities between the Akamon and the gateways of high ranking daimyō in Edo. This similarity includes the red paint, which, it turns out, was not limited to shogunal bridal gateways but was in more general use by daimyō for their own gateways by the end of the Edo period. Indeed, the Akamon was called the ‘red gateway’ only from the 1880s after the many other red gateways had disappeared following the fall of the Tokugawa shogunate. The expression ‘to paint the town red’ refers not only to the way the Akamon celebrated the marriage of Yōhime, but also more broadly to characterize the way many of the other gateways at daimyō mansions in the central sectors of Edo had entrances that were decorated with bright red paint. -

Hokusai's Landscapes
$45.00 / £35.00 Thomp HOKUSAI’S LANDSCAPES S on HOKUSAI’S HOKUSAI’S sarah E. thompson is Curator, Japanese Art, HOKUSAI’S LANDSCAPES at the Museum of Fine Arts, Boston. The CompleTe SerieS Designed by Susan Marsh SARAH E. THOMPSON The best known of all Japanese artists, Katsushika Hokusai was active as a painter, book illustrator, and print designer throughout his ninety-year lifespan. Yet his most famous works of all — the color woodblock landscape prints issued in series, beginning with Thirty-Six Views of Mount Fuji — were produced within a relatively short time, LANDSCAPES in an amazing burst of creative energy from about 1830 to 1836. These ingenious designs, combining MFA Publications influences from several different schools of Asian Museum of Fine Arts, Boston art as well as European sources, display the 465 Huntington Avenue artist’s acute powers of observation and trademark Boston, Massachusetts 02115 humor, often showing ordinary people from all www.mfa.org/publications walks of life going about their business in the foreground of famous scenic vistas. Distributed in the United States of America and Canada by ARTBOOK | D.A.P. Hokusai’s landscapes not only revolutionized www.artbook.com Japanese printmaking but also, within a few decades of his death, became icons of art Distributed outside the United States of America internationally. Illustrated with dazzling color and Canada by Thames & Hudson, Ltd. reproductions of works from the largest collection www.thamesandhudson.com of Japanese prints outside Japan, this book examines the magnetic appeal of Hokusai’s Front: Amida Falls in the Far Reaches of the landscape designs and the circumstances of their Kiso Road (detail, no. -

Fusō Gobusshin Ron
FUSŌ GOBUSSHIN RON - ENGLISH TRANSLATION – - Fascicle 1 - Translation Treatise on Japan's Protecting Buddha's and Gods - Preface. Anciently, the Great Priest Furi Qisong1 (1007-1072) hid himself near the West Lake for thirty years. Broadly he perused the instructions from Lu2, widely he searched the Indian scriptures, and he wrote down [his findings] in Fujiaobian 輔教編 ("Compilation in aid of the Teaching") and Fei Han 非韓3 ("Refuting Han [Yu]"), thirty chapters in all. He came to the aid of the teachings of Śākya[muni, which] were already on the verge of collapsing. I was forced to withdraw4 to the village Nanmoku,5 [where] I 1 Song Mingjiao dashi is the Chinese priest Furi Qisong 佛日契嵩, a.k.a. Mingjiao-dashi. (N.B. The Japanese pronunciation of the name 契嵩 is "Kaisū.") Amongst other things, he was an exponent of the sanjiao heyi 三教合一 ("Unity of the Three Teachings"). Bussho kaisetsu daijiten lists six titles under his name. 2 The words "the instructions of Lu" are evidently opposed to the words "Indian scriptures," i.e. Buddhist texts. The same applies to the seven loci one can find through the "SAT Daizōkyō Text Database"; here, too, the words are opposed to zhufen 竺墳, (six times) and shidian 釋典 (one time). The term evidently refers to the Confucian corpus (perhaps to Lunyu?). The compound is not listed in Morohashi, 3 Both in Fujiaobian (3 fasc.) and in Fei Han, Qisong takes a non-exclusivist position towards Confucianism and Taoism. N.B. For the change of the characters in the titles, see Honkoku, note 1. -

Diss Master Draft-Pdf
UC Berkeley UC Berkeley Electronic Theses and Dissertations Title Visual and Material Culture at Hokyoji Imperial Convent: The Significance of "Women's Art" in Early Modern Japan Permalink https://escholarship.org/uc/item/8fq6n1qb Author Yamamoto, Sharon Mitsuko Publication Date 2010 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Visual and Material Culture at Hōkyōji Imperial Convent: The Significance of “Women’s Art” in Early Modern Japan by Sharon Mitsuko Yamamoto A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in History of Art in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Gregory P. A. Levine, Chair Professor Patricia Berger Professor H. Mack Horton Fall 2010 Copyright by Sharon Mitsuko Yamamoto 2010. All rights reserved. Abstract Visual and Material Culture at Hōkyōji Imperial Convent: The Significance of “Women’s Art” in Early Modern Japan by Sharon Mitsuko Yamamoto Doctor of Philosophy in History of Art University of California, Berkeley Professor Gregory Levine, Chair This dissertation focuses on the visual and material culture of Hōkyōji Imperial Buddhist Convent (Hōkyōji ama monzeki jiin) during the Edo period (1600-1868). Situated in Kyoto and in operation since the mid-fourteenth century, Hōkyōji has been the home for women from the highest echelons of society—the nobility and military aristocracy—since its foundation. The objects associated with women in the rarefied position of princess-nun offer an invaluable look into the role of visual and material culture in the lives of elite women in early modern Japan. -

Globally Important Agricultural Heritage Systems (GIAHS) Application
Globally Important Agricultural Heritage Systems (GIAHS) Application SUMMARY INFORMATION Name/Title of the Agricultural Heritage System: Osaki Kōdo‟s Traditional Water Management System for Sustainable Paddy Agriculture Requesting Agency: Osaki Region, Miyagi Prefecture (Osaki City, Shikama Town, Kami Town, Wakuya Town, Misato Town (one city, four towns) Requesting Organization: Osaki Region Committee for the Promotion of Globally Important Agricultural Heritage Systems Members of Organization: Osaki City, Shikama Town, Kami Town, Wakuya Town, Misato Town Miyagi Prefecture Furukawa Agricultural Cooperative Association, Kami Yotsuba Agricultural Cooperative Association, Iwadeyama Agricultural Cooperative Association, Midorino Agricultural Cooperative Association, Osaki Region Water Management Council NPO Ecopal Kejonuma, NPO Kabukuri Numakko Club, NPO Society for Shinaimotsugo Conservation , NPO Tambo, Japanese Association for Wild Geese Protection Tohoku University, Miyagi University of Education, Miyagi University, Chuo University Responsible Ministry (for the Government): Ministry of Agriculture, Forestry and Fisheries The geographical coordinates are: North latitude 38°26’18”~38°55’25” and east longitude 140°42’2”~141°7’43” Accessibility of the Site to Capital City of Major Cities ○Prefectural Capital: Sendai City (closest station: JR Sendai Station) ○Access to Prefectural Capital: ・by rail (Tokyo – Sendai) JR Tohoku Super Express (Shinkansen): approximately 2 hours ※Access to requesting area: ・by rail (closest station: JR Furukawa -

June 2021 CHINA | JAPAN | VIETNAM | CAMBODIA | LAOS | SRI LANKA
Small Group Tours and Tailor-Made Journeys January 2020 - June 2021 CHINA | JAPAN | VIETNAM | CAMBODIA | LAOS | SRI LANKA Welcome to Links Travel & Tours! As always, our brochure is filled with inspirational small group tours for those who prefer to travel with like-minded people, and suggested itineraries, for those who prefer a tailor-made option. We also have a variety of suggestions for those who love sport, including golf in Vietnam and Japan, hiking and mountain climbing in Japan and cycling in China and Vietnam. Our sister company, Sport Links Travel provides tours to major sporting events across the globe, including cricket, rugby and Formula 1. Please go to page 146 for more details. At Links Travel & Tours we care about our destinations, and this year we continue to commit to responsible travel wherever we can. When possible, we have changed our domestic flights into intercity train journeys, made easier by the development of the rail network across Asia. Our continued partnership with local hotels and businesses contribute to the local economy and we encourage holidaymakers to support local initiatives. We are committed to reducing our eco impact when introducing you to Asia. Finally, please feel free to get in touch with our dedicated team of Personal Travel Advisers who are on hand to listen, understand and help you arrange your holiday of a lifetime! Xiexie Helen Li - (Owner, Links Travel & Tours) WHY LINKS TRAVEL & TOURS page 4 CHINA page 6 JAPAN page 50 INDOCHINA page 96 SRI LANKA page 130 STOPOVERS page 142 USEFUL INFORMATION page 145 SPORT LINKS TRAVEL page 146 3 WHY TRAVEL WITH LINKS TRAVEL & TOURS Remarkable Value Tailor-Made Journeys Our offices in London, Beijing and Tokyo, For the very best tailor-made journey, we will ensure we have direct contact with hotels, have a conversation with you to understand transport providers and guides, assuring you what you want, and then design an itinerary receive the best value for money. -

Winter Delights
WINTER DEC–MAR 2018/19 No. 220 Free WESTERN JAPAN’S PREMIER VISITOR’S GUIDE Winter Delights Sake, skiing, spas and snowcrab Plus Inside… WHAT’S ON Explore Sights Food & Drink Discover EAT & DRINK A PERFECT LONG BEST SPOTS HOW SAKE IS KINOSAKI’S SEVEN SIGHTSEEING WEEKEND IN NARA FOR WINTER MAKING ITS HEALING SPRINGS SNOWSCAPES COMEBACK MAPS Discover Hiroshima’s Scenic Beauty YOICHI SHIDAREZAKURA CHERRY BLOSSOM A stunning 12m tall weeping cherry sitting atop a small in Akiota-cho hillock is lit up during its brief, but spectacular spring bloom OSORAKAN SNOW PARK Japan’s southernmost ski resort, offering long runs for all Breathtaking views, fabulous levels of skiers and snowboarders, as well as snow trekking and igloo building hiking, exciting snow sports and relaxing hot spring accommodation await SANDANKYO GORGE A stunning 13km river gorge, awarded 3 stars by the French travel guide Blue Guide and selected as one of the top 100 scenic beauty spots in Japan INI TANADA Picture-perfect terraced paddy fi elds, offering stunning photo opportunities year-round Nukui Springs Hotel Offers traditional outdoor hot spring baths overlooking Lake Ryuki in Kyoto Hiroshima’s Akiota-cho. Relax in comfortable western style or Japanese Himeji Okayama Osaka tatami mat rooms and enjoy our award-winning French dining. Akiota-cho Kobe Hiroshima Address: 4692-7, Kake, Akiotacho, Yamgatagun, Hiroshima 731-3501, Japan Tel: +81 (0)826-22-1200 Access: 1 hour by car from Hiroshima IC RESERVATIONS www.nukui-sp.com CONTENTS 26 Winter Dec / Jan / Feb 10 30 Features KANSAI FINDER 08 23 32 Events & Festivals Kansai’s Snowy Vistas Nara’s Cocktail Kings Where to experience the best of the region’s RASTA MUSICK winter snowscapes.