Tibetan Romanization Table
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -

Introduction
INTRODUCTION ’ P”(Bha.t.tikāvya) is one of the boldest “B experiments in classical literature. In the formal genre of “great poem” (mahākāvya) it incorprates two of the most powerful Sanskrit traditions, the “Ramáyana” and Pánini’s grammar, and several other minor themes. In this one rich mix of science and art, Bhatti created both a po- etic retelling of the adventures of Rama and a compendium of examples of grammar, metrics, the Prakrit language and rhetoric. As literature, his composition stands comparison with the best of Sanskrit poetry, in particular cantos , and . “Bhatti’s Poem” provides a comprehensive exem- plification of Sanskrit grammar in use and a good introduc- tion to the science (śāstra) of poetics or rhetoric (alamk. āra, lit. ornament). It also gives a taster of the Prakrit language (a major component in every Sanskrit drama) in an easily ac- cessible form. Finally it tells the compelling story of Prince Rama in simple elegant Sanskrit: this is the “Ramáyana” faithfully retold. e learned Indian curriculum in late classical times had at its heart a system of grammatical study and linguistic analysis. e core text for this study was the notoriously difficult “Eight Books” (A.s.tādhyāyī) of Pánini, the sine qua non of learning composed in the fourth century , and arguably the most remarkable and indeed foundational text in the history of linguistics. Not only is the “Eight Books” a description of a language unmatched in totality for any language until the nineteenth century, but it is also pre- sented in the most compact form possible through the use xix of an elaborate and sophisticated metalanguage, again un- known anywhere else in linguistics before modern times. -

GEO ROO DIST BUC PRO Prep ATE 111 Cha Dec Expi OTECHNICA OSEVELT ST TRICT CKEYE, ARI OJECT # 15 Pared By
GEOTECHNICAL EXPLORARATION REPORT ROOSEVELT STREET IMPROVEMENT DISTRICT BUCKEYE, ARIZONA PROJECT # 150004 Prepared by: ATEK Engineering Consultants, LLC 111 South Weber Drive, Suite 1 Chandler, Arizona 85226 Exp ires 9/30/2018 December 14, 2015 December 14, 2015 ATEK Project #150004 RITOCH-POWELL & Associates 5727 North 7th Street #120 Phoenix, AZ 85014 Attention: Mr. Keith L. Drunasky, P.E. RE: GEOTECHNICAL EXPLORATION REPORT Roosevelt Street Improvement District Buckeye, Arizona Dear Mr. Drunasky: ATEK Engineering Consultants, LLC is pleased to present the attached Geotechnical Exploration Report for the Roosevelt Street Improvement Disstrict located in Buckeye, Arizona. The purpose of our study was to explore and evaluate the subsurface conditions at the proposed site to develop geotechnical engineering recommendations for project design and construction. Based on our findings, the site is considered suittable for the proposed construction, provided geotechnical recommendations presented in thhe attached report are followed. Specific recommendations regarding the geotechnical aspects of the project design and construction are presented in the attached report. The recommendations contained within this report are depeendent on the provisions provided in the Limitations and Recommended Additional Services sections of this report. We appreciate the opportunity of providing our services for this project. If you have questions regarding this report or if we may be of further assistance, please contact the undersigned. Sincerely, ATEK Engineering Consultants, LLC Expires 9/30/2018 James P Floyd, P.E. Armando Ortega, P.E. Project Manager Principal Geotechnical Engineer Expires 9/30/2017 111 SOUTH WEBER DRIVE, SUITE 1 WWW.ATEKEC.COM P (480) 659-8065 CHANDLER, AZ 85226 F (480) 656-9658 TABLE OF CONTENTS 1. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
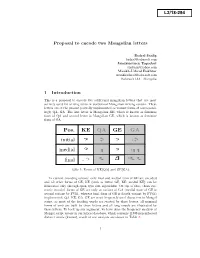
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -
![Positional Notation Or Trigonometry [2, 13]](https://docslib.b-cdn.net/cover/6799/positional-notation-or-trigonometry-2-13-106799.webp)
Positional Notation Or Trigonometry [2, 13]
The Greatest Mathematical Discovery? David H. Bailey∗ Jonathan M. Borweiny April 24, 2011 1 Introduction Question: What mathematical discovery more than 1500 years ago: • Is one of the greatest, if not the greatest, single discovery in the field of mathematics? • Involved three subtle ideas that eluded the greatest minds of antiquity, even geniuses such as Archimedes? • Was fiercely resisted in Europe for hundreds of years after its discovery? • Even today, in historical treatments of mathematics, is often dismissed with scant mention, or else is ascribed to the wrong source? Answer: Our modern system of positional decimal notation with zero, to- gether with the basic arithmetic computational schemes, which were discov- ered in India prior to 500 CE. ∗Bailey: Lawrence Berkeley National Laboratory, Berkeley, CA 94720, USA. Email: [email protected]. This work was supported by the Director, Office of Computational and Technology Research, Division of Mathematical, Information, and Computational Sciences of the U.S. Department of Energy, under contract number DE-AC02-05CH11231. yCentre for Computer Assisted Research Mathematics and its Applications (CARMA), University of Newcastle, Callaghan, NSW 2308, Australia. Email: [email protected]. 1 2 Why? As the 19th century mathematician Pierre-Simon Laplace explained: It is India that gave us the ingenious method of expressing all numbers by means of ten symbols, each symbol receiving a value of position as well as an absolute value; a profound and important idea which appears so simple to us now that we ignore its true merit. But its very sim- plicity and the great ease which it has lent to all computations put our arithmetic in the first rank of useful inventions; and we shall appre- ciate the grandeur of this achievement the more when we remember that it escaped the genius of Archimedes and Apollonius, two of the greatest men produced by antiquity. -

Friends, Enemies, and Fools: a Collection of Uyghur Proverbs by Michael Fiddler, Zhejiang Normal University
GIALens 2017 Volume 11, No. 3 Friends, enemies, and fools: A collection of Uyghur proverbs by Michael Fiddler, Zhejiang Normal University Erning körki saqal, sözning körki maqal. A beard is the beauty of a man; proverbs are the beauty of speech. Abstract: This article presents two groups of Uyghur proverbs on the topics of friendship and wisdom, to my knowledge only the second set of Uyghur proverbs published with English translation (after Mahmut & Smith-Finley 2016). It begins with a brief introduction of Uyghur language and culture, then a description of Uyghur proverb styles, then the two sets of proverbs, and finally a few concluding comments. Key words: Proverb, Uyghur, folly, wisdom, friend, enemy 1. Introduction Uyghur is spoken by about 10 million people, mostly in northwest China’s Xinjiang Uyghur Autonomous Region. It is a Turkic language, most closely related to Uzbek and Salar, but also sharing similarity with its neighbors Kazakh and Kyrgyz. The lexicon is composed of about 50% old Turkic roots, 40% relatively old borrowings from Arabic and Persian, and 6% from Russian and 2% from Mandarin (Nadzhip 1971; since then, the Russian and Mandarin borrowings have presumably seen a slight increase due to increased language contact, especially with Mandarin). The grammar is generally head-final, with default SOV clause structure, A-N noun phrases, and postpositions. Stress is typically word-final. Its phoneme inventory includes eight vowels and 24 consonants. The phonology includes vowel harmony in both roots and suffixes, which is sensitive to rounded/unrounded (labial harmony) and front/back (palatal harmony), consonant harmony across suffixes, which is sensitive to voiced/unvoiced and front/back distinctions; and frequent devoicing of high vowels (see Comrie 1997 and Hahn 1991 for details). -

A Review of Heat Stroke and Its Complications in the Canine Renee L
Volume 45 | Issue 1 Article 1 1983 A Review of Heat Stroke and Its Complications in the Canine Renee L. Larson Iowa State University Robert W. Carithers Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/iowastate_veterinarian Part of the Small or Companion Animal Medicine Commons, and the Veterinary Physiology Commons Recommended Citation Larson, Renee L. and Carithers, Robert W. (1983) "A Review of Heat Stroke and Its Complications in the Canine," Iowa State University Veterinarian: Vol. 45 : Iss. 1 , Article 1. Available at: https://lib.dr.iastate.edu/iowastate_veterinarian/vol45/iss1/1 This Article is brought to you for free and open access by the Journals at Iowa State University Digital Repository. It has been accepted for inclusion in Iowa State University Veterinarian by an authorized editor of Iowa State University Digital Repository. For more information, please contact [email protected]. A Review of Heat Stroke and Its Complications in the Canine Renee L. Larson, BS * Robert W. Carithers, DVM, MS, PhD** SUMMARY most obvious prerequisite is a high en A review of heat stroke and its complications vironmental temperature. When the ambient is presented. The etiology, physiology, clinical temperature increases above 86°F, a rise in in signs, secondary complications, diagnosis, ternal body temperature results. Dogs can treatment, necropsy results and prevention of tolerate rising environmental temperature heat stroke are discussed. A clinical case is quite well. However, when the body tempera then presented to illustrate the disorder of heat ture exceeds 104°F a breakdown of the stroke. animal's thermal equilibrium begins. -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ].