Discriminating Between Mandarin Chinese and Swiss-German Varieties Using Adaptive Language Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Top 100 Languages by Total Number of Native Speakers in 2007 Rank
This is a service by the Basel Institute of Commons and Economics. Browse more rankings on: http://commons.ch/world-rankings/ Top 100 languages by total number of native speakers in 2007 Number of Country with most Share of world rank country speakers in native speakers population millions 1. Mandarin Chinese 935 10.14% China 2. Spanish 415 5.85% Mexico 3. English 395 5.52% USA 4. Hindi 310 4.46% India 5. Arabic 295 3.24% Egypt 6. Portuguese 215 3.08% Brasilien 7. Bengali 205 3.05% Bangladesh 8. Russian 160 2.42% Russia 9. Japanese 125 1.92% Japan 10. Punjabi 95 1.44% Pakistan 11. German 92 1.39% Germany 12. Javanese 82 1.25% Indonesia 13. Wu Chinese 80 1.20% China 14. Malay 77 1.16% Indonesia 15. Telugu 76 1.15% India 16. Vietnamese 76 1.14% Vietnam 17. Korean 76 1.14% South Korea 18. French 75 1.12% France 19. Marathi 73 1.10% India 20. Tamil 70 1.06% India 21. Urdu 66 0.99% Pakistan 22. Turkish 63 0.95% Turkey 23. Italian 59 0.90% Italy 24. Cantonese 59 0.89% China 25. Thai 56 0.85% Thailand 26. Gujarati 49 0.74% India 27. Jin Chinese 48 0.72% China 28. Min Nan Chinese 47 0.71% Taiwan 29. Persian 45 0.68% Iran You want to score on countries by yourself? You can score eight indicators in 41 languages on https://trustyourplace.com/ This is a service by the Basel Institute of Commons and Economics. -

On the Development of Syllable-Initial Voiced Obstruents and Its Interplay with Tones in North-Western Gan Chinese Dialects
Shared innovation and the variability: On the development of syllable-initial voiced obstruents and its interplay with tones in north-western Gan Chinese dialects It is generally agreed that there were four tones in Middle Chinese, namely Ping (‘level’), Shang (‘rising’), Qu (‘departing’), and Ru (‘entering’), and at the same time, there was a three-way distinction of syllable-initial obstruents into voiced, voiceless unaspirated, and voiceless aspirated (Karlgren 1915-1926). The development of syllable-initial voiced obstruents and tonal split are two major sound changes from Middle Chinese to Modern Chinese and its dialects, which actually determines the profile of modern phonologies of Chinese dialects and contributed to the diversity of tones. Ideally, tones split according to the voicing condition of initial consonants, namely high tones, in general, are associated with voiceless initials and low tones with voiced initials. Regarding the development of obstruents, only Wu dialects and the old varieties of Xiang dialects retain the three-way distinction. In the other dialects, voiced obstruents merged with voiceless ones in various ways. For instance, voiced stops and affricates became voiceless unaspirated in Min dialects, but voiceless aspirated in Hakka and Gan dialects, in general. And in Mandarin dialects, voiced stops and affricates became voiceless aspirated in level-toned syllables and voiceless unaspirated in non-level-toned syllables. The complex interplay between the development of voiced obstruents and tones thus contributed to a highly diversified phonology of consonants and tones in modern Chinese dialects. This paper focuses on north-western Gan dialects. As in the other Gan dialects, voiced stops and affricates merged with their voiceless aspirated counterparts in north-western Gan dialects. -

The Neolithic Ofsouthern China-Origin, Development, and Dispersal
The Neolithic ofSouthern China-Origin, Development, and Dispersal ZHANG CHI AND HSIAO-CHUN HUNG INTRODUCTION SANDWICHED BETWEEN THE YELLOW RIVER and Mainland Southeast Asia, southern China1 lies centrally within eastern Asia. This geographical area can be divided into three geomorphological terrains: the middle and lower Yangtze allu vial plain, the Lingnan (southern Nanling Mountains)-Fujian region,2 and the Yungui Plateau3 (Fig. 1). During the past 30 years, abundant archaeological dis coveries have stimulated a rethinking of the role ofsouthern China in the prehis tory of China and Southeast Asia. This article aims to outline briefly the Neolithic cultural developments in the middle and lower Yangtze alluvial plain, to discuss cultural influences over adjacent regions and, most importantly, to examine the issue of southward population dispersal during this time period. First, we give an overview of some significant prehistoric discoveries in south ern China. With the discovery of Hemudu in the mid-1970s as the divide, the history of archaeology in this region can be divided into two phases. The first phase (c. 1920s-1970s) involved extensive discovery, when archaeologists un earthed Pleistocene human remains at Yuanmou, Ziyang, Liujiang, Maba, and Changyang, and Palaeolithic industries in many caves. The major Neolithic cul tures, including Daxi, Qujialing, Shijiahe, Majiabang, Songze, Liangzhu, and Beiyinyangying in the middle and lower Yangtze, and several shell midden sites in Lingnan, were also discovered in this phase. During the systematic research phase (1970s to the present), ongoing major ex cavation at many sites contributed significantly to our understanding of prehis toric southern China. Additional early human remains at Wushan, Jianshi, Yun xian, Nanjing, and Hexian were recovered together with Palaeolithic assemblages from Yuanmou, the Baise basin, Jianshi Longgu cave, Hanzhong, the Li and Yuan valleys, Dadong and Jigongshan. -

THE MEDIA's INFLUENCE on SUCCESS and FAILURE of DIALECTS: the CASE of CANTONESE and SHAAN'xi DIALECTS Yuhan Mao a Thesis Su
THE MEDIA’S INFLUENCE ON SUCCESS AND FAILURE OF DIALECTS: THE CASE OF CANTONESE AND SHAAN’XI DIALECTS Yuhan Mao A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts (Language and Communication) School of Language and Communication National Institute of Development Administration 2013 ABSTRACT Title of Thesis The Media’s Influence on Success and Failure of Dialects: The Case of Cantonese and Shaan’xi Dialects Author Miss Yuhan Mao Degree Master of Arts in Language and Communication Year 2013 In this thesis the researcher addresses an important set of issues - how language maintenance (LM) between dominant and vernacular varieties of speech (also known as dialects) - are conditioned by increasingly globalized mass media industries. In particular, how the television and film industries (as an outgrowth of the mass media) related to social dialectology help maintain and promote one regional variety of speech over others is examined. These issues and data addressed in the current study have the potential to make a contribution to the current understanding of social dialectology literature - a sub-branch of sociolinguistics - particularly with respect to LM literature. The researcher adopts a multi-method approach (literature review, interviews and observations) to collect and analyze data. The researcher found support to confirm two positive correlations: the correlative relationship between the number of productions of dialectal television series (and films) and the distribution of the dialect in question, as well as the number of dialectal speakers and the maintenance of the dialect under investigation. ACKNOWLEDGMENTS The author would like to express sincere thanks to my advisors and all the people who gave me invaluable suggestions and help. -

The Diminutive Word Tsa42 in the Xianning Dialect: A
The Diminutive Word tsa42 in the Xianning Dialect: A Cognitive Approach* Xiaolong Lu University of Arizona [email protected] This study reports on the syntactic distribution and semantic features of a spoken word tsa42 as a form of diminutive address in the Xianning dialect. Two research questions are examined: what are the distributional patterns of the dialectal word tsa42 regarding its different functions in the Xianning dialect? And when this word serves as a suffix of nouns, why can it be widely used as a diminutive marker in the dialect? Based on interview data, I argue that (1) there are restrictions in using the diminutive word tsa42 together with adjectives and nouns, and certain countable nouns denoting huge and fierce animals, or large transportation tools, etc., cannot co-occur with the diminutive word tsa42; and (2) the markedness theory (Shi 2005) is used to explain that the diminutive suffix tsa42 can be used to highlight nouns denoting things of small sizes. The revised model of Radial Category (Jurafsky 1996) helps account for different categorizations metaphorically and metonymically extended from the prototype “child” in terms of tsa42, etc. This case study implies that a typological model for diminution needs to be built to connect the analysis of other diminutive words in Chinese dialects and beyond. 1. Introduction Showing loveliness or affection to small things is taken to be a kind of human nature, and the “diminutive function is among the grammatical primitives which seem to occur universally or near-universally in world languages” (Jurafsky 1996: 534). The term “diminutive” is expressed as a kind of word that has been modified to convey a slighter degree of its root * I want to give my thanks to Dr. -

The Donkey Rider As Icon: Li Cheng and Early Chinese Landscape Painting Author(S): Peter C
The Donkey Rider as Icon: Li Cheng and Early Chinese Landscape Painting Author(s): Peter C. Sturman Source: Artibus Asiae, Vol. 55, No. 1/2 (1995), pp. 43-97 Published by: Artibus Asiae Publishers Stable URL: http://www.jstor.org/stable/3249762 . Accessed: 05/08/2011 12:40 Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at . http://www.jstor.org/page/info/about/policies/terms.jsp JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. Artibus Asiae Publishers is collaborating with JSTOR to digitize, preserve and extend access to Artibus Asiae. http://www.jstor.org PETER C. STURMAN THE DONKEY RIDER AS ICON: LI CHENG AND EARLY CHINESE LANDSCAPE PAINTING* he countryis broken,mountains and rivers With thesefamous words that lamentthe "T remain."'I 1T catastropheof the An LushanRebellion, the poet Du Fu (712-70) reflectedupon a fundamental principle in China:dynasties may come and go, but landscapeis eternal.It is a principleaffirmed with remarkablepower in the paintingsthat emergedfrom the rubbleof Du Fu'sdynasty some two hundredyears later. I speakof the magnificentscrolls of the tenth and eleventhcenturies belonging to the relativelytightly circumscribedtradition from Jing Hao (activeca. 875-925)to Guo Xi (ca. Ooo-9go)known todayas monumentallandscape painting. The landscapeis presentedas timeless. We lose ourselvesin the believabilityof its images,accept them as less the productof humanminds and handsthan as the recordof a greatertruth. -

Ethnic Minority Rights
ETHNIC MINORITY RIGHTS Findings • During the Commission’s 2019 reporting year, the Chinese Communist Party’s United Front Work Department continued to promote ethnic affairs work at all levels of Party and state governance that emphasized the importance of ‘‘sinicizing’’ eth- nic and religious minorities. Officials emphasized the need to ‘‘sinicize’’ the country’s religions, including Islam. Official ‘‘sinicization’’ efforts contributed to the increasing marginalization of ethnic minorities and their cultures and lan- guages. • Reports indicate that official efforts to repress Islamic prac- tices in the Xinjiang Uyghur Autonomous Region (XUAR) have spread beyond the XUAR to Hui communities living in other locations. Developments suggest officials may be starting to carry out religious repression in areas outside of the XUAR that are modeled on restrictions already implemented within the XUAR. In November 2018, official media reported that Zhang Yunsheng, Communist Party official of the Ningxia Hui Autonomous Region, had signed a counterterrorism agreement with XUAR officials during a trip to the XUAR to learn about its efforts to fight terrorism, maintain ‘‘social stability,’’ and manage religious affairs. • During the reporting year, authorities carried out the phys- ical destruction and alteration of Hui Muslim spaces and struc- tures, continuing a recent trend away from relative toleration of Hui Muslim faith communities. Officials demolished a mosque in a Hui community in Gansu province, raided and closed several mosques in Hui areas in Yunnan province, closed an Arabic-language school serving Hui students in Gansu, and carried out changes such as removing Arabic sign- age in Hui areas. These changes narrowed the space for Hui Muslim believers to assert an ethnic and religious identity dis- tinct from that of the dominant Han Chinese population. -

Building Parallel Monolingual Gan Chinese Dialects Corpus
Building Parallel Monolingual Gan Chinese Dialects Corpus Fan XU, Mingwen WANG, Maoxi LI School of Computer Information Engineering, Jiangxi Normal University Nanchang 330022, China {xufan, mwwang, mosesli}@jxnu.edu.cn Abstract Automatic language identification of an input sentence or a text written in similar languages, varieties or dialects is an important task in natural language processing. In this paper, we propose a scheme to represent Gan (Jiangxi province of China) Chinese dialects. In particular, it is a two-level and fine-grained representation using Chinese character, Chinese Pinyin and Chinese audio forms. Guided by the scheme, we manually annotate a Gan Chinese Dialects Corpus (GCDC) including 131.5 hours and 310 documents with 6 different genres, containing news, official document, story, prose, poet, letter and speech, from 19 different Gan regions. In addition, the preliminary evaluation on 2-way, 7-way and 20-way sentence-level Gan Chinese Dialects Identification (GCDI) justifies the appropriateness of the scheme to Gan Chinese dialects analysis and the usefulness of our manually annotated GCDC. Keywords: Parallel Corpus, Monolingual, Gan Chinese Dialects accuracy can reach to 78.64% on the fine-grained 20-way 1. Introduction classification, which shows the automatic Gan Chinese dialects identification should be feasible. The evaluation Automatic language identification of an input sentence or a document is an important task in Natural Language result justifies the appropriateness of the scheme to Gan Chinese dialects analysis and the usefulness of our Processing (NLP), especially when processing speech or manually annotated GCDC. social media messages. Currently, the interest in language resources and its computational models for the study of The rest of this paper is organized as follows. -
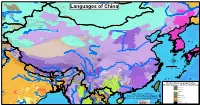
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

POWER LANGUAGE INDEX Which Are the World’S Most in Uential Languages?
Kai L. Chan, PhD POWER LANGUAGE INDEX Which are the world’s most inuential languages? There are over 6,000 languages spoken in the world today, but some 2,000 of them count fewer than a thousand speakers. Moreover, just 15 of them account for half of the languages spoken in the world. Which are the world’s most inuential languages? What are the proper metrics to measure the reach and power of languages? Power Language Index (May 2016) Kai L. Chan, PhD WEF Agenda: These are the most powerful languages in the world1 There are over 6,000 languages spoken in the world today, but some 2,000 of them count fewer than 1,000 speakers. Moreover, just 15 account for half of the languages spoken in the world. In a globalised world with multilingual societies, knowledge of languages is paramount in facilitating communication and in allowing people to participate in society’s cultural, economic and social activities. A pertinent question to ask then is: which are the most useful languages? If an alien were to land on Earth, which language would enable it to most fully engage with humans? To understand the efficacy of language (and by extension culture), consider the doors (“opportunities”) opened by it. Broadly speaking, there are five opportunities provided by language: 1. Geography: The ability to travel 2. Economy: The ability to participate in an economy 3. Communication: The ability to engage in dialogue 4. Knowledge and media: The ability to consume knowledge and media 5. Diplomacy: The ability to engage in international relations So which languages are the most powerful? Based on the opportunities above an index can be constructed to compare/rank languages on their efficacy in the various domains. -

Language Distinctiveness*
RAI – data on language distinctiveness RAI data Language distinctiveness* Country profiles *This document provides data production information for the RAI-Rokkan dataset. Last edited on October 7, 2020 Compiled by Gary Marks with research assistance by Noah Dasanaike Citation: Liesbet Hooghe and Gary Marks (2016). Community, Scale and Regional Governance: A Postfunctionalist Theory of Governance, Vol. II. Oxford: OUP. Sarah Shair-Rosenfield, Arjan H. Schakel, Sara Niedzwiecki, Gary Marks, Liesbet Hooghe, Sandra Chapman-Osterkatz (2021). “Language difference and Regional Authority.” Regional and Federal Studies, Vol. 31. DOI: 10.1080/13597566.2020.1831476 Introduction ....................................................................................................................6 Albania ............................................................................................................................7 Argentina ...................................................................................................................... 10 Australia ....................................................................................................................... 12 Austria .......................................................................................................................... 14 Bahamas ....................................................................................................................... 16 Bangladesh .................................................................................................................. -

Colloquial Chinese: Character Text (Simplified Character Version) Free Download
COLLOQUIAL CHINESE: CHARACTER TEXT (SIMPLIFIED CHARACTER VERSION) FREE DOWNLOAD Ping-Chen T'Ung,David E. Pollard | 204 pages | 01 Aug 1983 | Ping-cheng T'ung | 9780950857213 | English, Chinese | Stanmore, United Kingdom ISBN 13: 9780950857213 Further investigation reveals that these two characters do not appear in Chart 1 nor in "Series One Organization List of Variant Characters". This is because the adoption of simplified characters has been gradual and predates the Chinese Civil War by several decades and some are used beyond mainland China to some extent [20]. Go To Topic Listing. Help Learn to edit Community portal Recent changes Upload file. Padonkaffsky jargon Russian Translit Volapuk. Published December 1st by Ping-cheng T'ung first published January Just glide your mouse over the Chinese text and a pop-up window shows English translations and Mandarin pronunciations. Good choice. Simplified Chinese is taught instead of traditional Chinese in pro-mainland China schools. Lists with This Book. Refresh and try again. Pollard author Sign in to write a review. Not very helpful for teaching grammar as other than translations of new vocab the book is entirely in Colloquial Chinese: Character Text (Simplified Character Version). Imitation Song Ming Sans-serif. Posted November 19, You Can Learn Chinese Podcast. Linguistic doublets typical of varieties of Chinese. We have recently updated our Privacy Policy. You ordered the old-school version. American Braille obsolete. Reconciling these different character sets in Unicode Colloquial Chinese: Character Text (Simplified Character Version) part of the controversial process Colloquial Chinese: Character Text (Simplified Character Version) Han unification. Chinese Traditional characters Simplified characters first round second round Debate.