Phoneme Cards
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grapheme-To-Lexeme Feedback in the Spelling System: Evidence from a Dysgraphic Patient
COGNITIVE NEUROPSYCHOLOGY, 2006, 23 (2), 278–307 Grapheme-to-lexeme feedback in the spelling system: Evidence from a dysgraphic patient Michael McCloskey Johns Hopkins University, Baltimore, USA Paul Macaruso Community College of Rhode Island, Warwick, and Haskins Laboratories, New Haven, USA Brenda Rapp Johns Hopkins University, Baltimore, USA This article presents an argument for grapheme-to-lexeme feedback in the cognitive spelling system, based on the impaired spelling performance of dysgraphic patient CM. The argument relates two features of CM’s spelling. First, letters from prior spelling responses intrude into sub- sequent responses at rates far greater than expected by chance. This letter persistence effect arises at a level of abstract grapheme representations, and apparently results from abnormal persistence of activation. Second, CM makes many formal lexical errors (e.g., carpet ! compute). Analyses revealed that a large proportion of these errors are “true” lexical errors originating in lexical selec- tion, rather than “chance” lexical errors that happen by chance to take the form of words. Additional analyses demonstrated that CM’s true lexical errors exhibit the letter persistence effect. We argue that this finding can be understood only within a functional architecture in which activation from the grapheme level feeds back to the lexeme level, thereby influencing lexical selection. INTRODUCTION a brain-damaged patient with an acquired spelling deficit, arguing from his error pattern that Like other forms of language processing, written the cognitive system for written word produc- word production implicates multiple levels of tion includes feedback connections from gra- representation, including semantic, orthographic pheme representations to orthographic lexeme lexeme, grapheme, and allograph levels. -

The English Language
The English Language Version 5.0 Eala ðu lareow, tæce me sum ðing. [Aelfric, Grammar] Prof. Dr. Russell Block University of Applied Sciences - München Department 13 – General Studies Winter Semester 2008 © 2008 by Russell Block Um eine gute Note in der Klausur zu erzielen genügt es nicht, dieses Skript zu lesen. Sie müssen auch die “Show” sehen! Dieses Skript ist der Entwurf eines Buches: The English Language – A Guide for Inquisitive Students. Nur der Stoff, der in der Vorlesung behandelt wird, ist prüfungsrelevant. Unit 1: Language as a system ................................................8 1 Introduction ...................................... ...................8 2 A simple example of structure ..................... ......................8 Unit 2: The English sound system ...........................................10 3 Introduction..................................... ...................10 4 Standard dialects ................................ ....................10 5 The major differences between German and English . ......................10 5.1 The consonants ................................. ..............10 5.2 Overview of the English consonants . ..................10 5.3 Tense vs. lax .................................. ...............11 5.4 The final devoicing rule ....................... .................12 5.5 The “th”-sounds ................................ ..............12 5.6 The “sh”-sound .................................. ............. 12 5.7 The voiced sounds / Z/ and / dZ / ...................................12 5.8 The -

ON SOME CATEGORIES for DESCRIBING the SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami
ON SOME CATEGORIES FOR DESCRIBING THE SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami 1. A lexeme is the minimum unit that carries meaning. Thus a lexeme can be a "word" as well as an affix (i.e., something smaller than a word) or an idiom (i.e,, something larger than a word). 2. A sememe is a unit of meaning that can be realized as a single lexeme. It is defined as a structure constituted by those features having distinctive functions (i.e., serving to distinguish the sememe in question from other semernes that contrast with it).' A question that arises at this point is whether or not one lexeme always corresponds to just one serneme and no more. Three theoretical positions are foreseeable: (I) one which holds that one lexeme always corresponds to just one sememe and no more, (2) one which holds that one lexeme corresponds to an indefinitely large number of sememes, and (3) one which holds that one lexeme corresponds to a certain limited number of sememes. These three positions wiIl be referred to as (1) the "Grundbedeutung" theory, (2) the "use" theory, and (3) the "polysemy" theory, respectively. The Grundbedeutung theory, however attractive in itself, is to be rejected as unrealistic. Suppose a preliminary analysis has revealed that a lexeme seems to be used sometimes in an "abstract" sense and sometimes in a "concrete" sense. In order to posit a Grundbedeutung under such circumstances, it is to be assumed that there is a still higher level at which "abstract" and "concrete" are neutralized-this is certainly a theoretical possibility, but it seems highly unlikely and unrealistic from a psychological point of view. -

Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging
ORIGINAL ARTICLE Neuroscience http://dx.doi.org/10.3346/jkms.2014.29.10.1416 • J Korean Med Sci 2014; 29: 1416-1424 Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging Zang-Hee Cho,1 Nambeom Kim,1 The two basic scripts of the Korean writing system, Hanja (the logography of the traditional Sungbong Bae,2 Je-Geun Chi,1 Korean character) and Hangul (the more newer Korean alphabet), have been used together Chan-Woong Park,1 Seiji Ogawa,1,3 since the 14th century. While Hanja character has its own morphemic base, Hangul being and Young-Bo Kim1 purely phonemic without morphemic base. These two, therefore, have substantially different outcomes as a language as well as different neural responses. Based on these 1Neuroscience Research Institute, Gachon University, Incheon, Korea; 2Department of linguistic differences between Hanja and Hangul, we have launched two studies; first was Psychology, Yeungnam University, Kyongsan, Korea; to find differences in cortical activation when it is stimulated by Hanja and Hangul reading 3Kansei Fukushi Research Institute, Tohoku Fukushi to support the much discussed dual-route hypothesis of logographic and phonological University, Sendai, Japan routes in the brain by fMRI (Experiment 1). The second objective was to evaluate how Received: 14 February 2014 Hanja and Hangul affect comprehension, therefore, recognition memory, specifically the Accepted: 5 July 2014 effects of semantic transparency and morphemic clarity on memory consolidation and then related cortical activations, using functional magnetic resonance imaging (fMRI) Address for Correspondence: (Experiment 2). The first fMRI experiment indicated relatively large areas of the brain are Young-Bo Kim, MD Department of Neuroscience and Neurosurgery, Gachon activated by Hanja reading compared to Hangul reading. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Unit 2 Structures Handout.Pdf
2. The definition of a language as a structure of structures 2.1. Phonetics and phonology Relevance for studying language in its natural or primary medium: oral sounds rather than written symbols. Phonic medium: the range of sounds produced by the speech organs insofar as the play a role in language Speech sounds: Individual sounds within that range Phonetics is the study of the phonic medium: The study of the production, transmission, and reception of human sound-making used in speech. e.g. classification of sounds as voiced vs voiceless: /b/ vs /p/ Phonology is the study of the phonic medium not in itself but in relation with language. e.g. application of voice to the explanation of differences within the system of language: housen vs housev usen vs usev 2.1.1. Phonetics It is usually divided into three branches which study the phonic medium from three points of view: Articulatory phonetics: speech sounds according to the way in which they are produced by the speech organs. Acoustic phonetics: speech sounds according to the physical properties of their sound-waves. Auditory phonetics: speech sounds according to their perception and identification. Articulatory phonetics has the longest tradition, and its progress in the 19th century contributed a standardize and internationally accepted system of phonetic transcription: the origins of the International Phonetic Alphabet used today and relying on sound symbols and diacritics. It studies production in relation with the vocal tract, i.e., organs such as: lungs trachea or windpipe, containing: larynx vocal folds glottis pharyngeal cavity nose mouth, containing fixed organs: teeth and teeth ridge hard palate pharyngeal wall mobile organs: lips tongue soft palate jaw According to their function and participation, sounds may take several features: Voice: voiced vs voiceless sounds, according to the participation of the vocal folds e.g. -
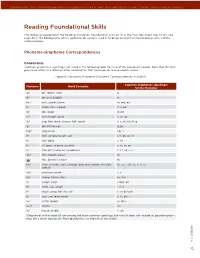
Reading Foundational Skills
Common Core State StandardS for engliSh language artS & literaCy in hiStory/SoCial StudieS, SCienCe, and teChniCal SubjeCtS reading Foundational skills The following supplements the Reading Standards: Foundational Skills (K–5) in the main document (pp. 14–16). See page 40 in the bibliography of this appendix for sources used in helping construct the foundational skills and the material below. Phoneme-Grapheme correspondences Consonants Common graphemes (spellings) are listed in the following table for each of the consonant sounds. Note that the term grapheme refers to a letter or letter combination that corresponds to one speech sound. Figure 8: Consonant Phoneme-Grapheme Correspondences in English Common Graphemes (Spellings) Phoneme Word Examples for the Phoneme* /p/ pit, spider, stop p /b/ bit, brat, bubble b /m/ mitt, comb, hymn m, mb, mn /t/ tickle, mitt, sipped t, tt, ed /d/ die, loved d, ed /n/ nice, knight, gnat n, kn, gn /k/ cup, kite, duck, chorus, folk, quiet k, c, ck, ch, lk, q /g/ girl, Pittsburgh g, gh /ng/ sing, bank ng, n /f/ fluff, sphere, tough, calf f, ff, gh, ph, lf /v/ van, dove v, ve /s/ sit, pass, science, psychic s, ss, sc, ps /z/ zoo, jazz, nose, as, xylophone z, zz, se, s, x /th/ thin, breath, ether th /th/ this, breathe, either th /sh/ shoe, mission, sure, charade, precious, notion, mission, sh, ss, s, ch, sc, ti, si, ci special /zh/ measure, azure s, z /ch/ cheap, future, etch ch, tch /j/ judge, wage j, dge, ge /l/ lamb, call, single l, ll, le /r/ reach, wrap, her, fur, stir r, wr, er/ur/ir /y/ you, use, feud, onion y, (u, eu), i /w/ witch, queen w, (q)u /wh/ where wh /h/ house, whole h, wh *Graphemes in the word list are among the most common spellings, but the list does not include all possible graph- emes for a given consonant. -

LL P Silent E Recognition.Pdf
® LEVEL 7 | Phonics Lexia Lessons Silent E Recognition Description This lesson is designed to teach students the phonics rule that when a Silent e occurs after a single consonant at the end of a syllable, it usually makes the first vowel “say its name” (long sound), as in the word time. These kinds of syllables are called Silent e syllables. Knowledge of the Silent e syllable type helps students apply word-attack strategies for reading and spelling. TEACHER TIPS This lesson contrasts the Silent e syllable type (long vowel sound) with the closed syllable type (short vowel sound). When you pronounce the words, stretch out the medial vowel sound, whether it is short or long, so that students have more time to hear it. Sounds to stretch out will be shown in the lesson as repeated letters—such as maaad for mad and maaade for made. For the letters a, e, i, and o, the long sound of the letter is also its name. Because long u can be pronounced /yoo/ or /oo/, it is presented later in this lesson. PREPARATION/MATERIALS • Copies of the word cards from the end of the lesson • Keyword Image Cards (provided in the Core5 Resources Hub on the Support for Primary Standard: CCSS.ELA-Literacy.RF.1.3c - Know final -e and common vowel - Know Standard: CCSS.ELA-Literacy.RF.1.3c Primary team conventions for representing long vowel sounds. RF.1.3b Supporting Standards: RF.1.2a, Instruction page.) Warm-up Use a phonemic awareness activity to review short and long vowel sounds. -

From Phoneme to Morpheme Author(S): Zellig S
Linguistic Society of America From Phoneme to Morpheme Author(s): Zellig S. Harris Source: Language, Vol. 31, No. 2 (Apr. - Jun., 1955), pp. 190-222 Published by: Linguistic Society of America Stable URL: http://www.jstor.org/stable/411036 Accessed: 09/02/2009 08:03 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=lsa. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit organization founded in 1995 to build trusted digital archives for scholarship. We work with the scholarly community to preserve their work and the materials they rely upon, and to build a common research platform that promotes the discovery and use of these resources. For more information about JSTOR, please contact [email protected]. Linguistic Society of America is collaborating with JSTOR to digitize, preserve and extend access to Language. http://www.jstor.org FROM PHONEME TO MORPHEME ZELLIG S. HARRIS University of Pennsylvania 0.1. -

Personal Notes Page 1 Learning from the Spelling of < Love > Summary
THEME Personal Notes Learning from the spelling of < love > Summary Many youngsters arrive at school already knowing how to spell the word < love >. It is also one of the very many short and common words which do not conform to the postulations of phonics. It is an excellent springboard for meeting, revisiting or discovering patterns of real spelling. This theme will teach: • that there is much to learn from single words, even when you are quite sure of how to write them; • that complete English words do not have a final < v >; • that the string < uv > is not an allowable string in English-origin words – < ov > is used instead; • that only suffixes that begin with a vowel letter replace a final single ‘silent’ < e >; • that there is spelling incoherence that is still allowed by editing houses, but we are not obliged to submit to them. © Real Spelling 2009 Kit 1 Theme K page 1 reparing for this theme Personal Notes P This theme is both recapitulation and anticipation. If you have a Tool Box you may already have worked the following teaching themes with your students. Kit 1 Theme A — The basic < i / y > conventions Kit 1 Theme D — Suffixing and the single silent < e > This theme anticipates Kit 4 Theme C — The < o / u > partnership. eal spellers learn from words whose spelling they already know R Most current school spelling activity concentrates on words that students can not spell, and assumes that mere ‘correctness’ is all that spelling needs. These assumptions are limited, limiting and fundamentally false. 4 Ability to spell is really a mode of thinking that enables us to spell. -

Phones and Phonemes
NLPA-Phon1 (4/10/07) © P. Coxhead, 2006 Page 1 Natural Language Processing & Applications Phones and Phonemes 1 Phonemes If we are to understand how speech might be generated or recognized by a computer, we need to study some of the underlying linguistic theory. The aim here is to UNDERSTAND the theory rather than memorize it. I’ve tried to reduce and simplify as much as possible without serious inaccuracy. Speech consists of sequences of sounds. The use of an instrument (such as a speech spectro- graph) shows that most of normal speech consists of continuous sounds, both within words and across word boundaries. Speakers of a language can easily dissect its continuous sounds into words. With more difficulty, they can split words into component sounds, or ‘segments’. However, it is not always clear where to stop splitting. In the word strip, for example, should the sound represented by the letters str be treated as a unit, be split into the two sounds represented by st and r, or be split into the three sounds represented by s, t and r? One approach to isolating component sounds is to look for ‘distinctive unit sounds’ or phonemes.1 For example, three phonemes can be distinguished in the word cat, corresponding to the letters c, a and t (but of course English spelling is notoriously non- phonemic so correspondence of phonemes and letters should not be expected). How do we know that these three are ‘distinctive unit sounds’ or phonemes of the English language? NOT from the sounds themselves. A speech spectrograph will not show a neat division of the sound of the word cat into three parts. -

Grapheme-To-Phoneme Models for (Almost) Any Language
Grapheme-to-Phoneme Models for (Almost) Any Language Aliya Deri and Kevin Knight Information Sciences Institute Department of Computer Science University of Southern California {aderi, knight}@isi.edu Abstract lang word pronunciation eng anybody e̞ n iː b ɒ d iː Grapheme-to-phoneme (g2p) models are pol żołądka z̻owon̪t̪ka rarely available in low-resource languages, ben শ嗍 s̪ ɔ k t̪ ɔ as the creation of training and evaluation ʁ a l o m o t חלומות heb data is expensive and time-consuming. We use Wiktionary to obtain more than 650k Table 1: Examples of English, Polish, Bengali, word-pronunciation pairs in more than 500 and Hebrew pronunciation dictionary entries, with languages. We then develop phoneme and pronunciations represented with the International language distance metrics based on phono- Phonetic Alphabet (IPA). logical and linguistic knowledge; apply- ing those, we adapt g2p models for high- word eng deu nld resource languages to create models for gift ɡ ɪ f tʰ ɡ ɪ f t ɣ ɪ f t related low-resource languages. We pro- class kʰ l æ s k l aː s k l ɑ s vide results for models for 229 adapted lan- send s e̞ n d z ɛ n t s ɛ n t guages. Table 2: Example pronunciations of English words 1 Introduction using English, German, and Dutch g2p models. Grapheme-to-phoneme (g2p) models convert words into pronunciations, and are ubiquitous in For most of the world’s more than 7,100 lan- speech- and text-processing systems. Due to the guages (Lewis et al., 2009), no data exists and the diversity of scripts, phoneme inventories, phono- many technologies enabled by g2p models are in- tactic constraints, and spelling conventions among accessible.