Grapheme-To-Phoneme Models for (Almost) Any Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grapheme-To-Lexeme Feedback in the Spelling System: Evidence from a Dysgraphic Patient
COGNITIVE NEUROPSYCHOLOGY, 2006, 23 (2), 278–307 Grapheme-to-lexeme feedback in the spelling system: Evidence from a dysgraphic patient Michael McCloskey Johns Hopkins University, Baltimore, USA Paul Macaruso Community College of Rhode Island, Warwick, and Haskins Laboratories, New Haven, USA Brenda Rapp Johns Hopkins University, Baltimore, USA This article presents an argument for grapheme-to-lexeme feedback in the cognitive spelling system, based on the impaired spelling performance of dysgraphic patient CM. The argument relates two features of CM’s spelling. First, letters from prior spelling responses intrude into sub- sequent responses at rates far greater than expected by chance. This letter persistence effect arises at a level of abstract grapheme representations, and apparently results from abnormal persistence of activation. Second, CM makes many formal lexical errors (e.g., carpet ! compute). Analyses revealed that a large proportion of these errors are “true” lexical errors originating in lexical selec- tion, rather than “chance” lexical errors that happen by chance to take the form of words. Additional analyses demonstrated that CM’s true lexical errors exhibit the letter persistence effect. We argue that this finding can be understood only within a functional architecture in which activation from the grapheme level feeds back to the lexeme level, thereby influencing lexical selection. INTRODUCTION a brain-damaged patient with an acquired spelling deficit, arguing from his error pattern that Like other forms of language processing, written the cognitive system for written word produc- word production implicates multiple levels of tion includes feedback connections from gra- representation, including semantic, orthographic pheme representations to orthographic lexeme lexeme, grapheme, and allograph levels. -

500 Natural Sciences and Mathematics
500 500 Natural sciences and mathematics Natural sciences: sciences that deal with matter and energy, or with objects and processes observable in nature Class here interdisciplinary works on natural and applied sciences Class natural history in 508. Class scientific principles of a subject with the subject, plus notation 01 from Table 1, e.g., scientific principles of photography 770.1 For government policy on science, see 338.9; for applied sciences, see 600 See Manual at 231.7 vs. 213, 500, 576.8; also at 338.9 vs. 352.7, 500; also at 500 vs. 001 SUMMARY 500.2–.8 [Physical sciences, space sciences, groups of people] 501–509 Standard subdivisions and natural history 510 Mathematics 520 Astronomy and allied sciences 530 Physics 540 Chemistry and allied sciences 550 Earth sciences 560 Paleontology 570 Biology 580 Plants 590 Animals .2 Physical sciences For astronomy and allied sciences, see 520; for physics, see 530; for chemistry and allied sciences, see 540; for earth sciences, see 550 .5 Space sciences For astronomy, see 520; for earth sciences in other worlds, see 550. For space sciences aspects of a specific subject, see the subject, plus notation 091 from Table 1, e.g., chemical reactions in space 541.390919 See Manual at 520 vs. 500.5, 523.1, 530.1, 919.9 .8 Groups of people Add to base number 500.8 the numbers following —08 in notation 081–089 from Table 1, e.g., women in science 500.82 501 Philosophy and theory Class scientific method as a general research technique in 001.4; class scientific method applied in the natural sciences in 507.2 502 Miscellany 577 502 Dewey Decimal Classification 502 .8 Auxiliary techniques and procedures; apparatus, equipment, materials Including microscopy; microscopes; interdisciplinary works on microscopy Class stereology with compound microscopes, stereology with electron microscopes in 502; class interdisciplinary works on photomicrography in 778.3 For manufacture of microscopes, see 681. -

Etytree: a Graphical and Interactive Etymology Dictionary Based on Wiktionary
Etytree: A Graphical and Interactive Etymology Dictionary Based on Wiktionary Ester Pantaleo Vito Walter Anelli Wikimedia Foundation grantee Politecnico di Bari Italy Italy [email protected] [email protected] Tommaso Di Noia Gilles Sérasset Politecnico di Bari Univ. Grenoble Alpes, CNRS Italy Grenoble INP, LIG, F-38000 Grenoble, France [email protected] [email protected] ABSTRACT a new method1 that parses Etymology, Derived terms, De- We present etytree (from etymology + family tree): a scendants sections, the namespace for Reconstructed Terms, new on-line multilingual tool to extract and visualize et- and the etymtree template in Wiktionary. ymological relationships between words from the English With etytree, a RDF (Resource Description Framework) Wiktionary. A first version of etytree is available at http: lexical database of etymological relationships collecting all //tools.wmflabs.org/etytree/. the extracted relationships and lexical data attached to lex- With etytree users can search a word and interactively emes has also been released. The database consists of triples explore etymologically related words (ancestors, descendants, or data entities composed of subject-predicate-object where cognates) in many languages using a graphical interface. a possible statement can be (for example) a triple with a lex- The data is synchronised with the English Wiktionary dump eme as subject, a lexeme as object, and\derivesFrom"or\et- at every new release, and can be queried via SPARQL from a ymologicallyEquivalentTo" as predicate. The RDF database Virtuoso endpoint. has been exposed via a SPARQL endpoint and can be queried Etytree is the first graphical etymology dictionary, which at http://etytree-virtuoso.wmflabs.org/sparql. -

ON SOME CATEGORIES for DESCRIBING the SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami
ON SOME CATEGORIES FOR DESCRIBING THE SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami 1. A lexeme is the minimum unit that carries meaning. Thus a lexeme can be a "word" as well as an affix (i.e., something smaller than a word) or an idiom (i.e,, something larger than a word). 2. A sememe is a unit of meaning that can be realized as a single lexeme. It is defined as a structure constituted by those features having distinctive functions (i.e., serving to distinguish the sememe in question from other semernes that contrast with it).' A question that arises at this point is whether or not one lexeme always corresponds to just one serneme and no more. Three theoretical positions are foreseeable: (I) one which holds that one lexeme always corresponds to just one sememe and no more, (2) one which holds that one lexeme corresponds to an indefinitely large number of sememes, and (3) one which holds that one lexeme corresponds to a certain limited number of sememes. These three positions wiIl be referred to as (1) the "Grundbedeutung" theory, (2) the "use" theory, and (3) the "polysemy" theory, respectively. The Grundbedeutung theory, however attractive in itself, is to be rejected as unrealistic. Suppose a preliminary analysis has revealed that a lexeme seems to be used sometimes in an "abstract" sense and sometimes in a "concrete" sense. In order to posit a Grundbedeutung under such circumstances, it is to be assumed that there is a still higher level at which "abstract" and "concrete" are neutralized-this is certainly a theoretical possibility, but it seems highly unlikely and unrealistic from a psychological point of view. -

Multilingual Ontology Acquisition from Multiple Mrds
Multilingual Ontology Acquisition from Multiple MRDs Eric Nichols♭, Francis Bond♮, Takaaki Tanaka♮, Sanae Fujita♮, Dan Flickinger ♯ ♭ Nara Inst. of Science and Technology ♮ NTT Communication Science Labs ♯ Stanford University Grad. School of Information Science Natural Language ResearchGroup CSLI Nara, Japan Keihanna, Japan Stanford, CA [email protected] {bond,takaaki,sanae}@cslab.kecl.ntt.co.jp [email protected] Abstract words of a language, let alone those words occur- ring in useful patterns (Amano and Kondo, 1999). In this paper, we outline the develop- Therefore it makes sense to also extract data from ment of a system that automatically con- machine readable dictionaries (MRDs). structs ontologies by extracting knowledge There is a great deal of work on the creation from dictionary definition sentences us- of ontologies from machine readable dictionaries ing Robust Minimal Recursion Semantics (a good summary is (Wilkes et al., 1996)), mainly (RMRS). Combining deep and shallow for English. Recently, there has also been inter- parsing resource through the common for- est in Japanese (Tokunaga et al., 2001; Nichols malism of RMRS allows us to extract on- et al., 2005). Most approaches use either a special- tological relations in greater quantity and ized parser or a set of regular expressions tuned quality than possible with any of the meth- to a particular dictionary, often with hundreds of ods independently. Using this method, rules. Agirre et al. (2000) extracted taxonomic we construct ontologies from two differ- relations from a Basque dictionary with high ac- ent Japanese lexicons and one English lex- curacy using Constraint Grammar together with icon. -
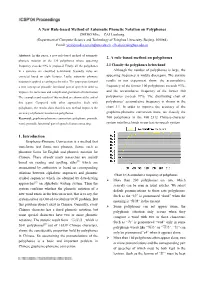
A New Rule-Based Method of Automatic Phonetic Notation On
A New Rule-based Method of Automatic Phonetic Notation on Polyphones ZHENG Min, CAI Lianhong (Department of Computer Science and Technology of Tsinghua University, Beijing, 100084) Email: [email protected], [email protected] Abstract: In this paper, a new rule-based method of automatic 2. A rule-based method on polyphones phonetic notation on the 220 polyphones whose appearing frequency exceeds 99% is proposed. Firstly, all the polyphones 2.1 Classify the polyphones beforehand in a sentence are classified beforehand. Secondly, rules are Although the number of polyphones is large, the extracted based on eight features. Lastly, automatic phonetic appearing frequency is widely discrepant. The statistic notation is applied according to the rules. The paper puts forward results in our experiment show: the accumulative a new concept of prosodic functional part of speech in order to frequency of the former 100 polyphones exceeds 93%, improve the numerous and complicated grammatical information. and the accumulative frequency of the former 180 The examples and results of this method are shown at the end of polyphones exceeds 97%. The distributing chart of this paper. Compared with other approaches dealt with polyphones’ accumulative frequency is shown in the polyphones, the results show that this new method improves the chart 3.1. In order to improve the accuracy of the accuracy of phonetic notation on polyphones. grapheme-phoneme conversion more, we classify the Keyword: grapheme-phoneme conversion; polyphone; prosodic 700 polyphones in the GB_2312 Chinese-character word; prosodic functional part of speech; feature extracting; system into three kinds in our text-to-speech system 1. -

(STAAR®) Dictionary Policy
STAAR® State of Texas Assessments of Academic Readiness State of Texas Assessments of Academic Readiness (STAAR®) Dictionary Policy Dictionaries must be available to all students taking: STAAR grades 3–8 reading tests STAAR grades 4 and 7 writing tests, including revising and editing STAAR Spanish grades 3–5 reading tests STAAR Spanish grade 4 writing test, including revising and editing STAAR English I, English II, and English III tests The following types of dictionaries are allowable: standard monolingual dictionaries in English or the language most appropriate for the student dictionary/thesaurus combinations bilingual dictionaries* (word-to-word translations; no definitions or examples) E S L dictionaries* (definition of an English word using simplified English) sign language dictionaries picture dictionary Both paper and electronic dictionaries are permitted. However, electronic dictionaries that provide access to the Internet or have photographic capabilities are NOT allowed. For electronic dictionaries that are hand-held devices, test administrators must ensure that any features that allow note taking or uploading of files have been cleared of their contents both before and after the test administration. While students are working through the tests listed above, they must have access to a dictionary. Students should use the same type of dictionary they routinely use during classroom instruction and classroom testing to the extent allowable. The school may provide dictionaries, or students may bring them from home. Dictionaries may be provided in the language that is most appropriate for the student. However, the dictionary must be commercially produced. Teacher-made or student-made dictionaries are not allowed. The minimum schools need is one dictionary for every five students testing, but the state’s recommendation is one for every three students or, optimally, one for each student. -

Methods in Lexicography and Dictionary Research* Stefan J
Methods in Lexicography and Dictionary Research* Stefan J. Schierholz, Department Germanistik und Komparatistik, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany ([email protected]) Abstract: Methods are used in every stage of dictionary-making and in every scientific analysis which is carried out in the field of dictionary research. This article presents some general consid- erations on methods in philosophy of science, gives an overview of many methods used in linguis- tics, in lexicography, dictionary research as well as of the areas these methods are applied in. Keywords: SCIENTIFIC METHODS, LEXICOGRAPHICAL METHODS, THEORY, META- LEXICOGRAPHY, DICTIONARY RESEARCH, PRACTICAL LEXICOGRAPHY, LEXICO- GRAPHICAL PROCESS, SYSTEMATIC DICTIONARY RESEARCH, CRITICAL DICTIONARY RESEARCH, HISTORICAL DICTIONARY RESEARCH, RESEARCH ON DICTIONARY USE Opsomming: Metodes in leksikografie en woordeboeknavorsing. Metodes word gebruik in elke fase van woordeboekmaak en in elke wetenskaplike analise wat in die woor- deboeknavorsingsveld uitgevoer word. In hierdie artikel word algemene oorwegings vir metodes in wetenskapfilosofie voorgelê, 'n oorsig word gegee van baie metodes wat in die taalkunde, leksi- kografie en woordeboeknavorsing gebruik word asook van die areas waarin hierdie metodes toe- gepas word. Sleutelwoorde: WETENSKAPLIKE METODES, LEKSIKOGRAFIESE METODES, TEORIE, METALEKSIKOGRAFIE, WOORDEBOEKNAVORSING, PRAKTIESE LEKSIKOGRAFIE, LEKSI- KOGRAFIESE PROSES, SISTEMATIESE WOORDEBOEKNAVORSING, KRITIESE WOORDE- BOEKNAVORSING, HISTORIESE WOORDEBOEKNAVORSING, NAVORSING OP WOORDE- BOEKGEBRUIK 1. Introduction In dictionary production and in scientific work which is carried out in the field of dictionary research, methods are used to reach certain results. Currently there is no comprehensive and up-to-date documentation of these particular methods in English. The article of Mann and Schierholz published in Lexico- * This article is based on the article from Mann and Schierholz published in Lexicographica 30 (2014). -

Sounds to Graphemes Guide
David Newman – Speech-Language Pathologist Sounds to Graphemes Guide David Newman S p e e c h - Language Pathologist David Newman – Speech-Language Pathologist A Friendly Reminder © David Newmonic Language Resources 2015 - 2018 This program and all its contents are intellectual property. No part of this publication may be stored in a retrieval system, transmitted or reproduced in any way, including but not limited to digital copying and printing without the prior agreement and written permission of the author. However, I do give permission for class teachers or speech-language pathologists to print and copy individual worksheets for student use. Table of Contents Sounds to Graphemes Guide - Introduction ............................................................... 1 Sounds to Grapheme Guide - Meanings ..................................................................... 2 Pre-Test Assessment .................................................................................................. 6 Reading Miscue Analysis Symbols .............................................................................. 8 Intervention Ideas ................................................................................................... 10 Reading Intervention Example ................................................................................. 12 44 Phonemes Charts ................................................................................................ 18 Consonant Sound Charts and Sound Stimulation .................................................... -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Parietal Dysgraphia: Characterization of Abnormal Writing Stroke Sequences, Character Formation and Character Recall
Behavioural Neurology 18 (2007) 99–114 99 IOS Press Parietal dysgraphia: Characterization of abnormal writing stroke sequences, character formation and character recall Yasuhisa Sakuraia,b,∗, Yoshinobu Onumaa, Gaku Nakazawaa, Yoshikazu Ugawab, Toshimitsu Momosec, Shoji Tsujib and Toru Mannena aDepartment of Neurology, Mitsui Memorial Hospital, Tokyo, Japan bDepartment of Neurology, Graduate School of Medicine, University of Tokyo, Tokyo, Japan cDepartment of Radiology, Graduate School of Medicine, University of Tokyo, Tokyo, Japan Abstract. Objective: To characterize various dysgraphic symptoms in parietal agraphia. Method: We examined the writing impairments of four dysgraphia patients from parietal lobe lesions using a special writing test with 100 character kanji (Japanese morphograms) and their kana (Japanese phonetic writing) transcriptions, and related the test performance to a lesion site. Results: Patients 1 and 2 had postcentral gyrus lesions and showed character distortion and tactile agnosia, with patient 1 also having limb apraxia. Patients 3 and 4 had superior parietal lobule lesions and features characteristic of apraxic agraphia (grapheme deformity and a writing stroke sequence disorder) and character imagery deficits (impaired character recall). Agraphia with impaired character recall and abnormal grapheme formation were more pronounced in patient 4, in whom the lesion extended to the inferior parietal, superior occipital and precuneus gyri. Conclusion: The present findings and a review of the literature suggest that: (i) a postcentral gyrus lesion can yield graphemic distortion (somesthetic dysgraphia), (ii) abnormal grapheme formation and impaired character recall are associated with lesions surrounding the intraparietal sulcus, the symptom being more severe with the involvement of the inferior parietal, superior occipital and precuneus gyri, (iii) disordered writing stroke sequences are caused by a damaged anterior intraparietal area. -

Wiktionary Matcher
Wiktionary Matcher Jan Portisch1;2[0000−0001−5420−0663], Michael Hladik2[0000−0002−2204−3138], and Heiko Paulheim1[0000−0003−4386−8195] 1 Data and Web Science Group, University of Mannheim, Germany fjan, [email protected] 2 SAP SE Product Engineering Financial Services, Walldorf, Germany fjan.portisch, [email protected] Abstract. In this paper, we introduce Wiktionary Matcher, an ontology matching tool that exploits Wiktionary as external background knowl- edge source. Wiktionary is a large lexical knowledge resource that is collaboratively built online. Multiple current language versions of Wik- tionary are merged and used for monolingual ontology matching by ex- ploiting synonymy relations and for multilingual matching by exploiting the translations given in the resource. We show that Wiktionary can be used as external background knowledge source for the task of ontology matching with reasonable matching and runtime performance.3 Keywords: Ontology Matching · Ontology Alignment · External Re- sources · Background Knowledge · Wiktionary 1 Presentation of the System 1.1 State, Purpose, General Statement The Wiktionary Matcher is an element-level, label-based matcher which uses an online lexical resource, namely Wiktionary. The latter is "[a] collaborative project run by the Wikimedia Foundation to produce a free and complete dic- tionary in every language"4. The dictionary is organized similarly to Wikipedia: Everybody can contribute to the project and the content is reviewed in a com- munity process. Compared to WordNet [4], Wiktionary is significantly larger and also available in other languages than English. This matcher uses DBnary [15], an RDF version of Wiktionary that is publicly available5. The DBnary data set makes use of an extended LEMON model [11] to describe the data.