From Phoneme to Morpheme Author(S): Zellig S
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grapheme-To-Lexeme Feedback in the Spelling System: Evidence from a Dysgraphic Patient
COGNITIVE NEUROPSYCHOLOGY, 2006, 23 (2), 278–307 Grapheme-to-lexeme feedback in the spelling system: Evidence from a dysgraphic patient Michael McCloskey Johns Hopkins University, Baltimore, USA Paul Macaruso Community College of Rhode Island, Warwick, and Haskins Laboratories, New Haven, USA Brenda Rapp Johns Hopkins University, Baltimore, USA This article presents an argument for grapheme-to-lexeme feedback in the cognitive spelling system, based on the impaired spelling performance of dysgraphic patient CM. The argument relates two features of CM’s spelling. First, letters from prior spelling responses intrude into sub- sequent responses at rates far greater than expected by chance. This letter persistence effect arises at a level of abstract grapheme representations, and apparently results from abnormal persistence of activation. Second, CM makes many formal lexical errors (e.g., carpet ! compute). Analyses revealed that a large proportion of these errors are “true” lexical errors originating in lexical selec- tion, rather than “chance” lexical errors that happen by chance to take the form of words. Additional analyses demonstrated that CM’s true lexical errors exhibit the letter persistence effect. We argue that this finding can be understood only within a functional architecture in which activation from the grapheme level feeds back to the lexeme level, thereby influencing lexical selection. INTRODUCTION a brain-damaged patient with an acquired spelling deficit, arguing from his error pattern that Like other forms of language processing, written the cognitive system for written word produc- word production implicates multiple levels of tion includes feedback connections from gra- representation, including semantic, orthographic pheme representations to orthographic lexeme lexeme, grapheme, and allograph levels. -

ON SOME CATEGORIES for DESCRIBING the SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami
ON SOME CATEGORIES FOR DESCRIBING THE SEMOLEXEMIC STRUCTURE by Yoshihiko Ikegami 1. A lexeme is the minimum unit that carries meaning. Thus a lexeme can be a "word" as well as an affix (i.e., something smaller than a word) or an idiom (i.e,, something larger than a word). 2. A sememe is a unit of meaning that can be realized as a single lexeme. It is defined as a structure constituted by those features having distinctive functions (i.e., serving to distinguish the sememe in question from other semernes that contrast with it).' A question that arises at this point is whether or not one lexeme always corresponds to just one serneme and no more. Three theoretical positions are foreseeable: (I) one which holds that one lexeme always corresponds to just one sememe and no more, (2) one which holds that one lexeme corresponds to an indefinitely large number of sememes, and (3) one which holds that one lexeme corresponds to a certain limited number of sememes. These three positions wiIl be referred to as (1) the "Grundbedeutung" theory, (2) the "use" theory, and (3) the "polysemy" theory, respectively. The Grundbedeutung theory, however attractive in itself, is to be rejected as unrealistic. Suppose a preliminary analysis has revealed that a lexeme seems to be used sometimes in an "abstract" sense and sometimes in a "concrete" sense. In order to posit a Grundbedeutung under such circumstances, it is to be assumed that there is a still higher level at which "abstract" and "concrete" are neutralized-this is certainly a theoretical possibility, but it seems highly unlikely and unrealistic from a psychological point of view. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Unit 2 Structures Handout.Pdf
2. The definition of a language as a structure of structures 2.1. Phonetics and phonology Relevance for studying language in its natural or primary medium: oral sounds rather than written symbols. Phonic medium: the range of sounds produced by the speech organs insofar as the play a role in language Speech sounds: Individual sounds within that range Phonetics is the study of the phonic medium: The study of the production, transmission, and reception of human sound-making used in speech. e.g. classification of sounds as voiced vs voiceless: /b/ vs /p/ Phonology is the study of the phonic medium not in itself but in relation with language. e.g. application of voice to the explanation of differences within the system of language: housen vs housev usen vs usev 2.1.1. Phonetics It is usually divided into three branches which study the phonic medium from three points of view: Articulatory phonetics: speech sounds according to the way in which they are produced by the speech organs. Acoustic phonetics: speech sounds according to the physical properties of their sound-waves. Auditory phonetics: speech sounds according to their perception and identification. Articulatory phonetics has the longest tradition, and its progress in the 19th century contributed a standardize and internationally accepted system of phonetic transcription: the origins of the International Phonetic Alphabet used today and relying on sound symbols and diacritics. It studies production in relation with the vocal tract, i.e., organs such as: lungs trachea or windpipe, containing: larynx vocal folds glottis pharyngeal cavity nose mouth, containing fixed organs: teeth and teeth ridge hard palate pharyngeal wall mobile organs: lips tongue soft palate jaw According to their function and participation, sounds may take several features: Voice: voiced vs voiceless sounds, according to the participation of the vocal folds e.g. -

12 Morphology and Lexical Semantics
248 Beth Levin and Malka Rappaport Hovav 12 Morphology and Lexical Semantics BETH LEVIN AND MALKA RAPPAPORT HOVAV The relation between lexical semantics and morphology has not been the subject of much study. This may seem surprising, since a morpheme is often viewed as a minimal Saussurean sign relating form and meaning: it is a concept with a phonologically composed name. On this view, morphology has both a semantic side and a structural side, the latter sometimes called “morphological realization” (Aronoff 1994, Zwicky 1986b). Since morphology is the study of the structure and derivation of complex signs, attention could be focused on the semantic side (the composition of complex concepts) and the structural side (the composition of the complex names for the concepts) and the relation between them. In fact, recent work in morphology has been concerned almost exclusively with the composition of complex names for concepts – that is, with the struc- tural side of morphology. This dissociation of “form” from “meaning” was foreshadowed by Aronoff’s (1976) demonstration that morphemes are not necessarily associated with a constant meaning – or any meaning at all – and that their nature is basically structural. Although in early generative treat- ments of word formation, semantic operations accompanied formal morpho- logical operations (as in Aronoff’s Word Formation Rules), many subsequent generative theories of morphology, following Lieber (1980), explicitly dissoci- ate the lexical semantic operations of composition from the formal structural -

Studies in the Linguistic Sciences
UNIVERSITY OF ILLINOIS Llb'RARY AT URBANA-CHAMPAIGN MODERN LANGUAGE NOTICE: Return or renew all Library Materialsl The Minimum Fee (or each Lost Book is $50.00. The person charging this material is responsible for its return to the library from which it was withdrawn on or before the Latest Date stamped below. Theft, mutilation, and underlining of books are reasons for discipli- nary action and may result in dismissal from the University. To renew call Telephone Center, 333-8400 UNIVERSITY OF ILLINOIS LIBRARY AT URBANA-CHAMPAIGN ModeriJLanp & Lb Library ^rn 425 333-0076 L161—O-I096 Che Linguistic Sciences PAPERS IN GENERAL LINGUISTICS ANTHONY BRITTI Quantifier Repositioning SUSAN MEREDITH BURT Remarks on German Nominalization CHIN-CHUAN CHENG AND CHARLES KISSEBERTH Ikorovere Makua Tonology (Part 1) PETER COLE AND GABRIELLA HERMON Subject to Object Raising in an Est Framework: Evidence from Quechua RICHARD CURETON The Inclusion Constraint: Description and Explanation ALICE DAVISON Some Mysteries of Subordination CHARLES A. FERGUSON AND APIA DIL The Sociolinguistic Valiable (s) in Bengali: A Sound Change in Progress GABRIELLA HERMON Rule Ordering Versus Globality: Evidencefrom the Inversion Construction CHIN-W. KIM Neutralization in Korean Revisited DAVID ODDEN Principles of Stress Assignment: A Crosslinguistic View PAULA CHEN ROHRBACH The Acquisition of Chinese by Adult English Speakers: An Error Analysis MAURICE K.S. WONG Origin of the High Rising Changed Tone in Cantonese SORANEE WONGBIASAJ On the Passive in Thai Department of Linguistics University of Illinois^-^ STUDIES IN THE LINGUISTIC SCIENCES PUBLICATION OF THE DEPARTMENT OF LINGUISTICS UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN EDITORS: Charles W. Kisseberth, Braj B. -

Morphemes by Kirsten Mills Student, University of North Carolina at Pembroke, 1998
Morphemes by Kirsten Mills http://www.uncp.edu/home/canada/work/caneng/morpheme.htm Student, University of North Carolina at Pembroke, 1998 Introduction Morphemes are what make up words. Often, morphemes are thought of as words but that is not always true. Some single morphemes are words while other words have two or more morphemes within them. Morphemes are also thought of as syllables but this is incorrect. Many words have two or more syllables but only one morpheme. Banana, apple, papaya, and nanny are just a few examples. On the other hand, many words have two morphemes and only one syllable; examples include cats, runs, and barked. Definitions morpheme: a combination of sounds that have a meaning. A morpheme does not necessarily have to be a word. Example: the word cats has two morphemes. Cat is a morpheme, and s is a morpheme. Every morpheme is either a base or an affix. An affix can be either a prefix or a suffix. Cat is the base morpheme, and s is a suffix. affix: a morpheme that comes at the beginning (prefix) or the ending (suffix) of a base morpheme. Note: An affix usually is a morpheme that cannot stand alone. Examples: -ful, -ly, -ity, -ness. A few exceptions are able, like, and less. base: a morpheme that gives a word its meaning. The base morpheme cat gives the word cats its meaning: a particular type of animal. prefix: an affix that comes before a base morpheme. The in in the word inspect is a prefix. suffix: an affix that comes after a base morpheme. -
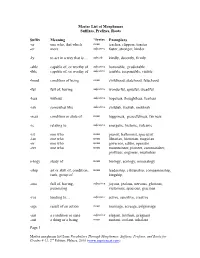
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Stylistics Lecture 3 Morphemes & Semantics
Stylistics Lecture 3 Morphemes & Semantics MOAZZAM A L I MALIK ASSISTANT PROFESSOR UNIVERSITY OF GUJRAT Words & Morphemes Words are potentially complex units, composed of even more basic units, called morphemes. A morpheme is the smallest part of a word that has grammatical function or meaning. we will designate them in braces { }. For example, played, plays, playing can all be analyzed into the morphemes {play} + {-ed}, {-s}, and {-ing}, respectively. Basic Concepts in Morphology The English plural morpheme {-s} can be expressed by three different but clearly related phonemic forms /iz/, /z/, and /s/. These are the variant phonological realizations of plural morpheme and hence are known as allomorphs. Morph is a minimal meaningful form, regardless of whether it is a morpheme or allomorph. Basic Concepts in Morphology Affixes are classified according to whether they are attached before or after the form to which they are added. A root morpheme is the basic form to which other morphemes are attached In moveable, {-able} is attached to {move}, which we’ve determined is the word’s root. However, {im- } is attached to moveable, not to {move} (there is no word immove), but moveable is not a root. Expressions to which affixes are attached are called bases. While roots may be bases, bases are not always roots. Basic Concepts in Morphology Words that have meaning by themselves—boy, food, door—are called lexical morphemes. Those words that function to specify the relationship between one lexical morpheme and another—words like at, in, on, -ed, -s— are called grammatical morphemes. Those morphemes that can stand alone as words are called free morphemes (e.g., boy, food, in, on). -

Phones and Phonemes
NLPA-Phon1 (4/10/07) © P. Coxhead, 2006 Page 1 Natural Language Processing & Applications Phones and Phonemes 1 Phonemes If we are to understand how speech might be generated or recognized by a computer, we need to study some of the underlying linguistic theory. The aim here is to UNDERSTAND the theory rather than memorize it. I’ve tried to reduce and simplify as much as possible without serious inaccuracy. Speech consists of sequences of sounds. The use of an instrument (such as a speech spectro- graph) shows that most of normal speech consists of continuous sounds, both within words and across word boundaries. Speakers of a language can easily dissect its continuous sounds into words. With more difficulty, they can split words into component sounds, or ‘segments’. However, it is not always clear where to stop splitting. In the word strip, for example, should the sound represented by the letters str be treated as a unit, be split into the two sounds represented by st and r, or be split into the three sounds represented by s, t and r? One approach to isolating component sounds is to look for ‘distinctive unit sounds’ or phonemes.1 For example, three phonemes can be distinguished in the word cat, corresponding to the letters c, a and t (but of course English spelling is notoriously non- phonemic so correspondence of phonemes and letters should not be expected). How do we know that these three are ‘distinctive unit sounds’ or phonemes of the English language? NOT from the sounds themselves. A speech spectrograph will not show a neat division of the sound of the word cat into three parts. -

Grapheme-To-Phoneme Models for (Almost) Any Language
Grapheme-to-Phoneme Models for (Almost) Any Language Aliya Deri and Kevin Knight Information Sciences Institute Department of Computer Science University of Southern California {aderi, knight}@isi.edu Abstract lang word pronunciation eng anybody e̞ n iː b ɒ d iː Grapheme-to-phoneme (g2p) models are pol żołądka z̻owon̪t̪ka rarely available in low-resource languages, ben শ嗍 s̪ ɔ k t̪ ɔ as the creation of training and evaluation ʁ a l o m o t חלומות heb data is expensive and time-consuming. We use Wiktionary to obtain more than 650k Table 1: Examples of English, Polish, Bengali, word-pronunciation pairs in more than 500 and Hebrew pronunciation dictionary entries, with languages. We then develop phoneme and pronunciations represented with the International language distance metrics based on phono- Phonetic Alphabet (IPA). logical and linguistic knowledge; apply- ing those, we adapt g2p models for high- word eng deu nld resource languages to create models for gift ɡ ɪ f tʰ ɡ ɪ f t ɣ ɪ f t related low-resource languages. We pro- class kʰ l æ s k l aː s k l ɑ s vide results for models for 229 adapted lan- send s e̞ n d z ɛ n t s ɛ n t guages. Table 2: Example pronunciations of English words 1 Introduction using English, German, and Dutch g2p models. Grapheme-to-phoneme (g2p) models convert words into pronunciations, and are ubiquitous in For most of the world’s more than 7,100 lan- speech- and text-processing systems. Due to the guages (Lewis et al., 2009), no data exists and the diversity of scripts, phoneme inventories, phono- many technologies enabled by g2p models are in- tactic constraints, and spelling conventions among accessible. -
The 44* Phonemes Following Is a List of the 44 Phonemes Along with The
The 44* Phonemes Following is a list of the 44 phonemes along with the letters of groups of letters that represent those sounds. Phoneme Graphemes** Examples (speech sound) (letters or groups of letters representing the most common spellings for the individual phonemes) Consonant Sounds: 1. /b/ b, bb big, rubber 2. /d/ d, dd, ed dog, add, filled 3. /f/ f, ph fish, phone 4. /g/ g, gg go, egg 5. /h/ h hot 6. /j/ j, g, ge, dge jet, cage, barge, judge 7. /k/ c, k, ck, ch, cc, que cat, kitten, duck, school, occur, antique, cheque 8. /l/ l, ll leg, bell 9. /m/ m, mm, mb mad, hammer, lamb 10. /n/ n, nn, kn, gn no, dinner, knee, gnome 11. /p/ p, pp pie, apple 12. /r/ r, rr, wr run, marry, write 13. /s/ s, se, ss, c, ce, sc sun, mouse, dress, city, ice, science 14. /t/ t, tt, ed top, letter, stopped 15. /v/ v, ve vet, give 16. /w/ w wet, win, swim 17 /y/ y, i yes, onion 18. /z/ z, zz, ze, s, se, x zip, fizz, sneeze, laser, is, was, please, Xerox, xylophone Source: Orchestrating Success in Reading by Dawn Reithaug (2002) Phoneme Graphemes** Examples (speech sound) (letters or groups of letters representing the most common spellings for the individual phonemes) Consonant Digraphs: 19. /th/ th thumb, thin, thing (not voiced) 20. /th/ th this, feather, then (voiced) 21. /ng/ ng, n sing, monkey, sink 22. /sh/ sh, ss, ch, ti, ci ship, mission, chef, motion, special 23. /ch/ ch, tch chip, match 24.