Phonotactically Conditioned Alternation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Syllabic Consonants and Phonotactics Syllabic Consonants
Syllabic consonants and phonotactics Syllabic consonants Consonants that stand as the peak of the syllable, and perform the functions of vowels, are called syllabic consonants. For example, in words like sudden and saddle, the consonant [d] is followed by either the consonant [n] or [l] without a vowel intervening. The [n] of sadden and the [l] of saddle constitute the centre of the second, unstressed, syllable and are considered to be syllabic peaks. They typically occur in an unstressed syllable immediately following the alveolar consonants, [t, s, z] as well as [d]. Examples of syllabic consonants Cattle [kæțɬ] wrestle [resɬ] Couple [kʌpɬ] knuckle [nʌkɬ] Panel[pæņɬ] petal [petɬ] Parcel [pa:șɬ] pedal [pedɬ] It is not unusual to find two syllabic consonants together. Examples are: national [næʃņɬ] literal [litrɬ] visionary [viʒņri] veteran [vetrņ] Phonotactics Phonotactic constraints determine what sounds can be put together to form the different parts of a syllable in a language. Examples: English onsets /kl/ is okay: “clean” “clamp” /pl/ is okay: “play” “plaque” */tl/ is not okay: *tlay *tlamp. We don’t often have words that begin with /tl/, /dm/, /rk/, etc. in English. However, these combinations can occur in the middle or final positions. So, what is phonotactics? Phonotactics is part of the phonology of a language. Phonotactics restricts the possible sound sequences and syllable structures in a language. Phonotactic constraint refers to any specific restriction To understand phonotactics, one must first understand syllable structure. Permissible language structures Languages differ in permissible syllable structures. Below are some simplified examples. Hawaiian: V, CV Japanese: V, CV, CVC Korean: V, CV, CVC, VCC, CVCC English: V CV CCV CCCV VC CVC CCVC CCCVC VCC CVCC CCVCC CCCVCC VCCC CVCCC CCVCCC CCCVCCC English consonant clusters sequences English allows CC and CCC clusters in onsets and codas, but they are highly restricted. -

Bleaching and Coloring*
386 Bleaching and Coloring* Patricia D. Miller Ohio State University Current studies in natural phonology have dealt with vowels in terms of three cardinal properties: palatality, labiality, and sonority. Palatality and labiality--the chromatic properties--are optimized by a minimally open, maximally constricted vocal tract; and sonority is optimized by a more open vowel tract) Thus the familiar triangle: A or, more exactly a a represents the maximal opposition of the three properties.2 And in many ways, the vowel space does seem to be triangular: ordinarily, the more sonorant a vowel is, the less color it has; and the more chromatic it is--the less sonorant. Thus, while i, e, and m are all palatal, i is more palatal than e, and e is more palatal than m; and, similarly, the degree of rounding varies for u, o, 3. The vowels #, A, and a are colorless or achromatic. They lack both palatality and labiality, and differ only in sonority.3 In this framework, the terms bleaching and coloring are almost self-explanatory: bleaching removes color, and coloring adds color. Bleaching Bleaching may remove palatality or labiality, or both simultaneously: V !lover -Labial !unstressed and/or !lax/short -Palatal] !mixed _(context) Full-scale operation of bleaching will produce linear vowel systems like those of the Caucasian languages reported to have k, A, a. If A lowers, it will produce the system 4, a like that of Kabardian (Kuipers 1960:23 et passim), or that of the child Curt4 (011er forthcoming); or, if all achromatics lower, it will give the single- vowel system, a. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

CONSONANT CLUSTER PHONOTACTICS: a PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences Économiques, Université De Montr
CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences économiques, Université de Montréal (1987) Diplôme Relations Internationales, Institut d’Études Politiques de Paris (1990) D.E.A. Démographie économique, Institut d’Études Politiques de Paris (1991) M.A. Linguistique, Université de Montréal (1995) Submitted to the department of Linguistics and Philosophy in partial fulfillment of the requirement for the degree of DOCTOR OF PHILOSOPHY À ma mère et à mon bébé, at the qui nous ont quittés À Marielle et Émile, MASSACHUSETTS INSTITUTE OF TECHNOLOGY qui nous sont arrivés À Jean-Pierre, qui est toujours là September 2000 © 2000 Marie-Hélène Côté. All rights reserved. The author hereby grants to M.I.T. the permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part. Signature of author_________________________________________________ Department of Linguistics and Philosophy August 25, 2000 Certified by_______________________________________________________ Professor Michael Kenstowicz Thesis supervisor Accepted by______________________________________________________ Alec Marantz Chairman, Department of Linguistics and Philosophy CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH NOTES ON THE PRESENT VERSION by The present version, finished in July 2001, differs slightly from the official one, deposited in September 2000. The acknowledgments were finally added. The MARIE-HÉLÈNE CÔTÉ formatting was changed and the presentation generally improved. Several typos were corrected, and the references were updated, when papers originally cited as manuscripts were subsequently published. A couple of references were also added, as Submitted to the Department of Linguistics and Philosophy well as short conclusions to chapters 3, 4, and 5, which for the most part summarize on September 5, 2000, in partial fulfillment of the requirements the chapter in question. -

On Syncope in Old English
In: Dieter Kastovsky and Aleksander Szwedek (eds) Linguistics across historical and geographical boundaries. In honour of Jacek Fisiak on the occasion of his fiftieth birthday. Berlin: Mouton-de Gruyter, 1986, 359-66. On syncope in Old English Raymond Hickey University of Bonn Abstract. Syncope in Old English is seen to be a rule which is determined by syllable structure but furthermore to be governed by a set of restricting conditions which refer to the world-class status of the forms which may act as input to the syncope rule, and also to the inflectional or derivational nature of the suffix which are added also to the precise phonological structure of those forms which undergo syncope. A phonological rule in a language which does not operate globally is always of particular interest as the conditions which restrict its application can frequently be recognized and formulized, at the same time throwing light on the nature of conditions which can in principle apply in a language’s phonology. In Old English a syncope rule existed which clearly related to the syllable structure of the forms it did not operate on but which was also subject to a set of restricting conditions which lie outside the domain of the syllable. The examination of this syncope rule and the conditions pertaining to it is the subject of this contribution. It is first of all necessary to distinguish syncope from another phonological process with which it might be confused. This is epenthesis, which appears to have been quite widespread in late West Saxon, as can be seen in the following forms. -

The Iafor European Conference Series 2014 Ece2014 Ecll2014 Ectc2014 Official Conference Proceedings ISSN: 2188-112X
the iafor european conference series 2014 ece2014 ecll2014 ectc2014 Official Conference Proceedings ISSN: 2188-112X “To Open Minds, To Educate Intelligence, To Inform Decisions” The International Academic Forum provides new perspectives to the thought-leaders and decision-makers of today and tomorrow by offering constructive environments for dialogue and interchange at the intersections of nation, culture, and discipline. Headquartered in Nagoya, Japan, and registered as a Non-Profit Organization 一般社( 団法人) , IAFOR is an independent think tank committed to the deeper understanding of contemporary geo-political transformation, particularly in the Asia Pacific Region. INTERNATIONAL INTERCULTURAL INTERDISCIPLINARY iafor The Executive Council of the International Advisory Board IAB Chair: Professor Stuart D.B. Picken IAB Vice-Chair: Professor Jerry Platt Mr Mitsumasa Aoyama Professor June Henton Professor Frank S. Ravitch Director, The Yufuku Gallery, Tokyo, Japan Dean, College of Human Sciences, Auburn University, Professor of Law & Walter H. Stowers Chair in Law USA and Religion, Michigan State University College of Law Professor David N Aspin Professor Emeritus and Former Dean of the Faculty of Professor Michael Hudson Professor Richard Roth Education, Monash University, Australia President of The Institute for the Study of Long-Term Senior Associate Dean, Medill School of Journalism, Visiting Fellow, St Edmund’s College, Cambridge Economic Trends (ISLET) Northwestern University, Qatar University, UK Distinguished Research Professor of Economics, -

Acoustic Characteristics of Tense and Lax Vowels Across Sentence Position in Clear Speech Lindsay Kayne Roesler University of Wisconsin-Milwaukee
University of Wisconsin Milwaukee UWM Digital Commons Theses and Dissertations August 2013 Acoustic Characteristics of Tense and Lax Vowels Across Sentence Position in Clear Speech Lindsay Kayne Roesler University of Wisconsin-Milwaukee Follow this and additional works at: https://dc.uwm.edu/etd Part of the Other Rehabilitation and Therapy Commons Recommended Citation Roesler, Lindsay Kayne, "Acoustic Characteristics of Tense and Lax Vowels Across Sentence Position in Clear Speech" (2013). Theses and Dissertations. 754. https://dc.uwm.edu/etd/754 This Thesis is brought to you for free and open access by UWM Digital Commons. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of UWM Digital Commons. For more information, please contact [email protected]. ACOUSTIC CHARACTERISTICS OF TENSE AND LAX VOWELS ACROSS SENTENCE POSITION IN CLEAR SPEECH by Lindsay Roesler A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Communication Sciences and Disorders at The University of Wisconsin-Milwaukee August 2013 ABSTRACT ACOUSTIC CHARACTERISTICS OF TENSE AND LAX VOWELS ACROSS SENTENCE POSITION IN CLEAR SPEECH by Lindsay Roesler The University of Wisconsin-Milwaukee, 2013 Under the Supervision of Professor Jae Yung Song The purpose of this study was to examine the acoustic characteristics of tense and lax vowels across sentence positions in clear speech. Recordings were made of 12 participants reading monosyllabic target words at varying positions within semantically meaningful sentences. Acoustic analysis was completed to determine the effects of Style (clear vs. conversational), Tenseness (tense vs. lax), and Position (sentence-medial vs. sentence-final) on vowel duration, vowel space area, vowel space dispersion, and vowel peripheralization. -

Boofi 6HEEH SIATE UNIVERSITY LIBRARY I
RUNIC EVIDENCE OF LAMINOALVEOLAR AFFRICATION IN OLD ENGLISH Tae-yong Pak A Dissertation Submitted to the Graduate School of Bowling Green State University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY August 1969 Approved by Doctoral Committee BOOfi 6HEEH SIATE UNIVERSITY LIBRARY I 428620 Copyright hy Tae-yong Pak 1969 ii ABSTRACT Considered 'inconsistent' by leading runologists of this century, the new Old English runes in the palatovelar series, namely, gar, calc, and gar-modified (various modi fications of the old gifu and cën) have not been subjected to rigorous linguistic analysis, and their relevance to Old English phonology and the study of Old English poetry has remained unexplored. The present study seeks to determine the phonemic status of the new runes and elucidate their implications to alliteration. To this end the following methods were used: 1) The 60-odd extant Old English runic texts were examined. Only four monuments (Bewcastle, Ruthwell, Thornhill, and Urswick) were found to use the new runes definitely. 2) In the four texts the words containing the new and old palatovelar runes were isolated and tabulated according to their environments. The pattern of distribution was significant: gifu occurred thirteen times in front environments and twice in back environments; cen, eight times front and once back; gar, nine times back; calc, five times back and once front; and gar-modified, twice front. Although cen and gifu occurred predominantly in front environments, and calc and gar in back environments, their occurrences were not complementary. 3) To interpret the data minimal or near minimal pairs with the palatovelar consonants occurring in front or back environments were examined. -

Phonotactics on the Web 487
PHONOTACTICS ON THE WEB 487 APPENDIX Table A1 International Phonetic Alphabet (IPA) and Computer-Readable “Klattese” Transcription Equivalents IPAKlattese IPA Klattese Stops Syllabic Consonants p p n N t t m M k k l L b b d d Glides and Semivowels g l l ɹ r Affricates w w tʃ C j y d J Vowels Sibilant Fricatives i i s s I ʃ S ε E z z e e Z @ Nonsibilant Fricatives ɑ a ɑu f f W θ a Y T v v ^ ð ɔ c D o h h O o o Nasals υ U n n u u m m R ŋ G ə x | X Klattese Transcription Conventions Repeated phonemes. The only situation in which a phoneme is repeated is in a compound word. For exam- ple, the word homemade is transcribed in Klattese as /hommed/. All other words with two successive phonemes that are the same just have a single segment. For example, shrilly would be transcribed in Klattese as /SrIli/. X/R alternation. /X/ appears only in unstressed syllables, and /R/ appears only in stressed syllables. Schwas. There are four schwas: /x/, /|/, /X/, and unstressed /U/. The /U/ in an unstressed syllable is taken as a rounded schwa. Syllabic consonants. The transcriptions are fairly liberal in the use of syllabic consonants. Words ending in -ism are transcribed /IzM/ even though a tiny schwa typically appears in the transition from the /z/ to the /M/. How- ever, /N/ does not appear unless it immediately follows a coronal. In general, /xl/ becomes /L/ unless it occurs be- fore a stressed vowel. -

Old English Feet
7. Old English Feet Chris Golston California State University, Fresno 1. Introduction In this chapter I show that the Beowulf poet carefully avoids lines whose halves are identical in terms of stressed (x) and stressless (.) syllables. The half-line (x.x.), for instance, is happily paired with anything but another (x.x.), despite the fact that (x.x.) is by far the commonest half-line type in the poem. Statistical analysis shows that this avoidance is not by chance and suggests that having identical adjacent half-lines is unmetrical in the poem. The same appears to be the case for half-lines identical in weight: a half-line with heavy and light syllables that runs (HLHL) does not pair with one that runs (HLHL). The results are obtained by looking at each and every syllable in the poem, regardless of stress, morphological status, or position within the line. This shows that Beowulf meter strictly regulates every syllable in the poem. Theories that ignore pre-tonic syllables (Bliss 1958), syllables that occur in prefixes (Russom 1987), stressless syllables in general (Keyser 1969, Fabb & Halle 2008), or stress in general (Golston & Riad 2001) cannot account for this fact. An adequate theory of OE meter must include stress, quantity, and the avoidance of identical half-lines. 2. Variation We may begin with a metrical scansion of the first part of the poem, where the first syllable of every lexical root (noun, verb, adjective) is stressed (x) and all others are stressless (.): (1)!Beowulf lines 1-11 Hwat, w" g#r-dena in ge#r-dagum, ! . -
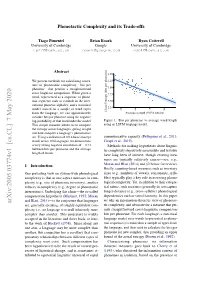
Phonotactic Complexity and Its Trade-Offs
Phonotactic Complexity and its Trade-offs Tiago Pimentel Brian Roark Ryan Cotterell University of Cambridge Google University of Cambridge [email protected] [email protected] [email protected] Abstract 3.50 We present methods for calculating a mea- 3.25 sure of phonotactic complexity—bits per phoneme—that permits a straightforward 3.00 cross-linguistic comparison. When given a 2.75 word, represented as a sequence of phone- mic segments such as symbols in the inter- 2.50 national phonetic alphabet, and a statistical 2.25 model trained on a sample of word types 5 6 7 8 from the language, we can approximately Cross Entropy (bits per phoneme) Average Length (# IPA tokens) measure bits per phoneme using the negative log-probability of that word under the model. Figure 1: Bits-per-phoneme vs average word length This simple measure allows us to compare using an LSTM language model. the entropy across languages, giving insight into how complex a language’s phonotactics are. Using a collection of 1016 basic concept communicative capacity (Pellegrino et al., 2011; words across 106 languages, we demonstrate Coupé et al., 2019). a very strong negative correlation of −0:74 Methods for making hypotheses about linguis- between bits per phoneme and the average tic complexity objectively measurable and testable length of words. have long been of interest, though existing mea- sures are typically relatively coarse—see, e.g., 1 Introduction Moran and Blasi(2014) and §2 below for reviews. Briefly, counting-based measures such as inventory One prevailing view on system-wide phonological sizes (e.g., numbers of vowels, consonants, sylla- complexity is that as one aspect increases in com- bles) typically play a key role in assessing phono- plexity (e.g., size of phonemic inventory), another logical complexity. -

Lexical Phonology and the History of English
LEXICAL PHONOLOGY AND THE HISTORY OF ENGLISH APRIL McMAHON Department of Linguistics University of Cambridge PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United Kingdom CAMBRIDGE UNIVERSITY PRESS The Edinburgh Building, Cambridge CB2 2RU, UK www.cup.cam.ac.uk 40 West 20th Street, New York, NY 10011±4211, USA www.cup.org 10 Stamford Road, Oakleigh, Melbourne 3166, Australia # April McMahon 2000 This book is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2000 Printed in the United Kingdom at the University Press, Cambridge Typeset in Times 10/13pt. [ce] A catalogue record for this book is available from the British Library Library of Congress Cataloguing in Publication data McMahon, April M. S. Lexical Phonology and the history of English / April McMahon. p. cm. ± (Cambridge studies in linguistics; 91) Includes bibliographical references and index. ISBN 0 521 47280 6 hardback 1. English language ± Phonology, Historical. 2. English language ± History. 3. Lexical Phonology. I. Title. II. Series. PE1133.M37 2000 421'.5 ± dc21 99±28845 CIP ISBN 0 521 47280 6 hardback Contents Acknowledgements page xi 1 The roÃle of history 1 1.1 Internal and external evidence 1 1.2 Lexical Phonology and its predecessor 5 1.3 Alternative models 13 1.4 The structure of the book 33 2 Constraining the model: current