Phonotactics on the Web 487
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Syllabic Consonants and Phonotactics Syllabic Consonants
Syllabic consonants and phonotactics Syllabic consonants Consonants that stand as the peak of the syllable, and perform the functions of vowels, are called syllabic consonants. For example, in words like sudden and saddle, the consonant [d] is followed by either the consonant [n] or [l] without a vowel intervening. The [n] of sadden and the [l] of saddle constitute the centre of the second, unstressed, syllable and are considered to be syllabic peaks. They typically occur in an unstressed syllable immediately following the alveolar consonants, [t, s, z] as well as [d]. Examples of syllabic consonants Cattle [kæțɬ] wrestle [resɬ] Couple [kʌpɬ] knuckle [nʌkɬ] Panel[pæņɬ] petal [petɬ] Parcel [pa:șɬ] pedal [pedɬ] It is not unusual to find two syllabic consonants together. Examples are: national [næʃņɬ] literal [litrɬ] visionary [viʒņri] veteran [vetrņ] Phonotactics Phonotactic constraints determine what sounds can be put together to form the different parts of a syllable in a language. Examples: English onsets /kl/ is okay: “clean” “clamp” /pl/ is okay: “play” “plaque” */tl/ is not okay: *tlay *tlamp. We don’t often have words that begin with /tl/, /dm/, /rk/, etc. in English. However, these combinations can occur in the middle or final positions. So, what is phonotactics? Phonotactics is part of the phonology of a language. Phonotactics restricts the possible sound sequences and syllable structures in a language. Phonotactic constraint refers to any specific restriction To understand phonotactics, one must first understand syllable structure. Permissible language structures Languages differ in permissible syllable structures. Below are some simplified examples. Hawaiian: V, CV Japanese: V, CV, CVC Korean: V, CV, CVC, VCC, CVCC English: V CV CCV CCCV VC CVC CCVC CCCVC VCC CVCC CCVCC CCCVCC VCCC CVCCC CCVCCC CCCVCCC English consonant clusters sequences English allows CC and CCC clusters in onsets and codas, but they are highly restricted. -

The Festvox Indic Frontend for Grapheme-To-Phoneme Conversion
The Festvox Indic Frontend for Grapheme-to-Phoneme Conversion Alok Parlikar, Sunayana Sitaram, Andrew Wilkinson and Alan W Black Carnegie Mellon University Pittsburgh, USA aup, ssitaram, aewilkin, [email protected] Abstract Text-to-Speech (TTS) systems convert text into phonetic pronunciations which are then processed by Acoustic Models. TTS frontends typically include text processing, lexical lookup and Grapheme-to-Phoneme (g2p) conversion stages. This paper describes the design and implementation of the Indic frontend, which provides explicit support for many major Indian languages, along with a unified framework with easy extensibility for other Indian languages. The Indic frontend handles many phenomena common to Indian languages such as schwa deletion, contextual nasalization, and voicing. It also handles multi-script synthesis between various Indian-language scripts and English. We describe experiments comparing the quality of TTS systems built using the Indic frontend to grapheme-based systems. While this frontend was designed keeping TTS in mind, it can also be used as a general g2p system for Automatic Speech Recognition. Keywords: speech synthesis, Indian language resources, pronunciation 1. Introduction in models of the spectrum and the prosody. Another prob- lem with this approach is that since each grapheme maps Intelligible and natural-sounding Text-to-Speech to a single “phoneme” in all contexts, this technique does (TTS) systems exist for a number of languages of the world not work well in the case of languages that have pronun- today. However, for low-resource, high-population lan- ciation ambiguities. We refer to this technique as “Raw guages, such as languages of the Indian subcontinent, there Graphemes.” are very few high-quality TTS systems available. -

Phonetics and Phonology in Russian Unstressed Vowel Reduction: a Study in Hyperarticulation
Phonetics and Phonology in Russian Unstressed Vowel Reduction: A Study in Hyperarticulation Jonathan Barnes Boston University (Short title: Hyperarticulating Russian Unstressed Vowels) Jonathan Barnes Department of Modern Foreign Languages and Literatures Boston University 621 Commonwealth Avenue, Room 119 Boston, MA 02215 Tel: (617) 353-6222 Fax: (617) 353-4641 [email protected] Abstract: Unstressed vowel reduction figures centrally in recent literature on the phonetics-phonology interface, in part owing to the possibility of a causal relationship between a phonetic process, duration-dependent undershoot, and the phonological neutralizations observed in systems of unstressed vocalism. Of particular interest in this light has been Russian, traditionally described as exhibiting two distinct phonological reduction patterns, differing both in degree and distribution. This study uses hyperarticulation to investigate the relationship between phonetic duration and reduction in Russian, concluding that these two reduction patterns differ not in degree, but in the level of representation at which they apply. These results are shown to have important consequences not just for theories of vowel reduction, but for other problems in the phonetics-phonology interface as well, incomplete neutralization in particular. Introduction Unstressed vowel reduction has been a subject of intense interest in recent debate concerning the nature of the phonetics-phonology interface. This is the case at least in part due to the existence of two seemingly analogous processes bearing this name, one typically called phonetic, and the other phonological. Phonological unstressed vowel reduction is a phenomenon whereby a given language's full vowel inventory can be realized only in lexically stressed syllables, while in unstressed syllables some number of neutralizations of contrast take place, with the result that only a subset of the inventory is realized on the surface. -

Roger Lass the Idea: What Is Schwa?
Stellenbosch Papers in Linguistics, Vol. 15, 1986, 01-30 doi: 10.5774/15-0-95 SPIL 15 (]986) 1 - 30 ON SCHW.A. * Roger Lass The idea: what is schwa? Everybody knows what schwa is or do they? This vene- rable Hebraic equivocation, with its later avatars like "neutral vowel", MUT'melvokaZ, etc. seems to be solidly es tablished in our conceptual and transcriptional armories. Whether it should be is another matter. In its use as a transcriptional symbol, I suggest, it represents a somewhat unsavoury and dispensable collection of theoretical and empirical sloppinesses and ill-advised reifications. It also embodies a major category confusion. That is, [8J is the only "phonetic symbol" that in accepted usage has only "phonological" or functional reference, not (precise) phone tic content. As we will see, there is a good deal to be said against raJ as a symbol for unstressed vowels, though there is often at least a weak excuse for invoking it. But "stressed schwa", prominent in discussions of Afrikaans and English (among other languages) is probably just about inex ·cusable. v Schwa (shwa, shva, se wa , etc.) began life as a device in Hebrew orthography. In "pointed" or "vocalized" script (i.e. where vowels rather than just consonantal skeletons are represented) the symbol ":" under a consonant graph appa rently represented some kind of "overshort" and/or "inde terminate" vowel: something perhaps of the order of a Slavic jeT', but nonhigh and generally neither front nor back though see below. In (Weingreen 1959:9, note b) it is described as,"a quick vowel-like sound", which is "pronounced like 'e' in 'because'''. -

How to Edit IPA 1 How to Use SAMPA for Editing IPA 2 How to Use X
version July 19 How to edit IPA When you want to enter the International Phonetic Association (IPA) character set with a computer keyboard, you need to know how to enter each IPA character with a sequence of keyboard strokes. This document describes a number of techniques. The complete SAMPA and RTR mapping can be found in the attached html documents. The main html document (ipa96.html) comes in a pdf-version (ipa96.pdf) too. 1 How to use SAMPA for editing IPA The Speech Assessment Method (SAM) Phonetic Alphabet has been developed by John Wells (http://www.phon.ucl.ac.uk/home/sampa). The goal was to map 176 IPA characters into the range of 7-bit ASCII, which is a set of 96 characters. The principle is to represent a single IPA character by a single ASCII character. This table is an example for five vowels: Description IPA SAMPA script a ɑ A ae ligature æ { turned a ɐ 6 epsilon ɛ E schwa ə @ A visual represenation of a keyboard shows the mapping on screen. The source for the SAMPA mapping used is "Handbook of multimodal an spoken dialogue systems", D Gibbon, Kluwer Academic Publishers 2000. 2 How to use X-SAMPA for editing IPA The multi-character extension to SAMPA has also been developed by John Wells (http://www.phon.ucl.ac.uk/home/sampa/x-sampa.htm). The basic principle used is to form chains of ASCII characters, that represent a single IPA character, e.g. This table lists some examples Description IPA X-SAMPA beta β B small capital B ʙ B\ lower-case B b b lower-case P p p Phi ɸ p\ The X-SAMPA mapping is in preparation and will be included in the next release. -

CONSONANT CLUSTER PHONOTACTICS: a PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences Économiques, Université De Montr
CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH by MARIE-HÉLÈNE CÔTÉ B.Sc. Sciences économiques, Université de Montréal (1987) Diplôme Relations Internationales, Institut d’Études Politiques de Paris (1990) D.E.A. Démographie économique, Institut d’Études Politiques de Paris (1991) M.A. Linguistique, Université de Montréal (1995) Submitted to the department of Linguistics and Philosophy in partial fulfillment of the requirement for the degree of DOCTOR OF PHILOSOPHY À ma mère et à mon bébé, at the qui nous ont quittés À Marielle et Émile, MASSACHUSETTS INSTITUTE OF TECHNOLOGY qui nous sont arrivés À Jean-Pierre, qui est toujours là September 2000 © 2000 Marie-Hélène Côté. All rights reserved. The author hereby grants to M.I.T. the permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part. Signature of author_________________________________________________ Department of Linguistics and Philosophy August 25, 2000 Certified by_______________________________________________________ Professor Michael Kenstowicz Thesis supervisor Accepted by______________________________________________________ Alec Marantz Chairman, Department of Linguistics and Philosophy CONSONANT CLUSTER PHONOTACTICS: A PERCEPTUAL APPROACH NOTES ON THE PRESENT VERSION by The present version, finished in July 2001, differs slightly from the official one, deposited in September 2000. The acknowledgments were finally added. The MARIE-HÉLÈNE CÔTÉ formatting was changed and the presentation generally improved. Several typos were corrected, and the references were updated, when papers originally cited as manuscripts were subsequently published. A couple of references were also added, as Submitted to the Department of Linguistics and Philosophy well as short conclusions to chapters 3, 4, and 5, which for the most part summarize on September 5, 2000, in partial fulfillment of the requirements the chapter in question. -

On Syncope in Old English
In: Dieter Kastovsky and Aleksander Szwedek (eds) Linguistics across historical and geographical boundaries. In honour of Jacek Fisiak on the occasion of his fiftieth birthday. Berlin: Mouton-de Gruyter, 1986, 359-66. On syncope in Old English Raymond Hickey University of Bonn Abstract. Syncope in Old English is seen to be a rule which is determined by syllable structure but furthermore to be governed by a set of restricting conditions which refer to the world-class status of the forms which may act as input to the syncope rule, and also to the inflectional or derivational nature of the suffix which are added also to the precise phonological structure of those forms which undergo syncope. A phonological rule in a language which does not operate globally is always of particular interest as the conditions which restrict its application can frequently be recognized and formulized, at the same time throwing light on the nature of conditions which can in principle apply in a language’s phonology. In Old English a syncope rule existed which clearly related to the syllable structure of the forms it did not operate on but which was also subject to a set of restricting conditions which lie outside the domain of the syllable. The examination of this syncope rule and the conditions pertaining to it is the subject of this contribution. It is first of all necessary to distinguish syncope from another phonological process with which it might be confused. This is epenthesis, which appears to have been quite widespread in late West Saxon, as can be seen in the following forms. -

Northern Tosk Albanian
1 Northern Tosk Albanian 1 1 2 Stefano Coretta , Josiane Riverin-Coutlée , Enkeleida 1,2 3 3 Kapia , and Stephen Nichols 1 4 Institute of Phonetics and Speech Processing, 5 Ludwig-Maximilians-Universität München 2 6 Academy of Albanological Sciences 3 7 Linguistics and English Language, University of Manchester 8 29 July 2021 9 1 Introduction 10 Albanian (endonym: Shqip; Glotto: alba1268) is an Indo-European lan- 11 guage which has been suggested to form an independent branch of the 12 Indo-European family since the middle of the nineteenth century (Bopp 13 1855; Pedersen 1897; Çabej 1976). Though the origin of the language has 14 been debated, the prevailing opinion in the literature is that it is a descend- 15 ant of Illyrian (Hetzer 1995). Albanian is currently spoken by around 6–7 16 million people (Rusakov 2017; Klein et al. 2018), the majority of whom 17 live in Albania and Kosovo, with others in Italy, Greece, North Macedonia 18 and Montenegro. Figure 1 shows a map of the main Albanian-speaking 19 areas of Europe, with major linguistic subdivisions according to Gjinari 20 (1988) and Elsie & Gross (2009) marked by different colours and shades. 21 At the macro-level, Albanian includes two main varieties: Gheg, 22 spoken in Northern Albania, Kosovo and parts of Montenegro and North 1 Figure 1: Map of the Albanian-speaking areas of Europe. Subdivisions are based on Gjinari (1988) and Elsie & Gross (2009). CC-BY-SA 4.0 Stefano Coretta, Júlio Reis. 2 23 Macedonia; and Tosk, spoken in Southern Albania and in parts of Greece 24 and Southern Italy (von Hahn 1853; Desnickaja 1976; Demiraj 1986; Gjin- 25 ari 1985; Beci 2002; Shkurtaj 2012; Gjinari et al. -

The Tune Drives the Text - Schwa in Consonant-Final Loan Words in Italian
The tune drives the text - Schwa in consonant-final loan words in Italian Martine Grice1, Michelina Savino2, Alessandro Caffò2, Timo B. Roettger1 1IfL-Phonetics, University of Cologne, Germany 2Dept. of Education, Psychology, Communication, University of Bari, Italy [email protected], [email protected], [email protected], [email protected] ABSTRACT Although Italian has a very limited number of con- sonant-final words in its native vocabulary, the lan- In Italian, consonant-final loan words are reportedly guage has incorporated a great number of such produced with or without a final schwa. This paper words in recent years, including many proper nouns reveals that variation in the presence of this schwa is [6]. Crucially, their pronunciation is subject to varia- dependent on a number of factors, including the tion [2, 13, 17, inter alia]. Monosyllabic words such metrical structure of the target word and the voicing as ‘chat’ can retain the structure of the donor lan- of the consonant. Crucially, it is also conditioned by guage (in this case English) with the consonant in intonation: Schwa is more likely to occur – and is final position, /͡tʃat/, or the consonant can be fol- acoustically more prominent – when the intonational lowed by a mid central vocoid (henceforth schwa): tune is complex or rising, as opposed to falling. /͡tʃatːə/. Schwa epenthesis can thus be seen as facilitating the Studies on Italian generally analyse this non- production of functionally relevant tunes. lexical word-final schwa as an epenthetic vowel, rather than a phonetic artefact. One strong argument Keywords: Italian, tune-text association, schwa, for its phonological status is that it goes hand in compression, epenthesis hand with a lengthened (geminated) consonant. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -
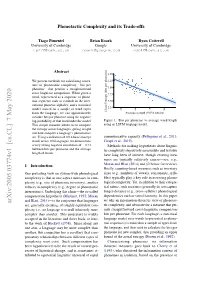
Phonotactic Complexity and Its Trade-Offs
Phonotactic Complexity and its Trade-offs Tiago Pimentel Brian Roark Ryan Cotterell University of Cambridge Google University of Cambridge [email protected] [email protected] [email protected] Abstract 3.50 We present methods for calculating a mea- 3.25 sure of phonotactic complexity—bits per phoneme—that permits a straightforward 3.00 cross-linguistic comparison. When given a 2.75 word, represented as a sequence of phone- mic segments such as symbols in the inter- 2.50 national phonetic alphabet, and a statistical 2.25 model trained on a sample of word types 5 6 7 8 from the language, we can approximately Cross Entropy (bits per phoneme) Average Length (# IPA tokens) measure bits per phoneme using the negative log-probability of that word under the model. Figure 1: Bits-per-phoneme vs average word length This simple measure allows us to compare using an LSTM language model. the entropy across languages, giving insight into how complex a language’s phonotactics are. Using a collection of 1016 basic concept communicative capacity (Pellegrino et al., 2011; words across 106 languages, we demonstrate Coupé et al., 2019). a very strong negative correlation of −0:74 Methods for making hypotheses about linguis- between bits per phoneme and the average tic complexity objectively measurable and testable length of words. have long been of interest, though existing mea- sures are typically relatively coarse—see, e.g., 1 Introduction Moran and Blasi(2014) and §2 below for reviews. Briefly, counting-based measures such as inventory One prevailing view on system-wide phonological sizes (e.g., numbers of vowels, consonants, sylla- complexity is that as one aspect increases in com- bles) typically play a key role in assessing phono- plexity (e.g., size of phonemic inventory), another logical complexity. -

The Origin of the IPA Schwa
The origin of the IPA schwa Asher Laufer The Phonetics Laboratory, Hebrew Language Department, The Hebrew University, Mount Scopus, Jerusalem 91905, Israel [email protected] ABSTRACT We will refer here to those two kinds of schwa as "the linguistic schwa", to distinguish them from what The symbol ⟨ə⟩ in the International Phonetic Alphabet we call " the Hebrew schwa". was given the special name "Schwa". In fact, phoneticians use this term to denote two different meanings: A precise and specific physiological 2. HISTORY OF THE "SCHWA" definition - "a mid-central vowel" - or a variable The word "schwa" was borrowed from the vocabulary reduced non-defined centralized vowel. of the Hebrew grammar, which has been in use since The word "schwa" was borrowed from the Hebrew the 10th century. The Tiberian Masorah scholars grammar vocabulary, and has been in use since the th added various diacritics to the Hebrew letters to 10 century. The Tiberian Masorah scholars added, denote vowel signs and cantillation (musical marks). already in the late first millennium CE, various Actually, we can consider these scholars as diacritics to the Hebrew letters, to denote vowel signs phoneticians who invented a writing system to and cantillation (musical marks). Practically, we can represent their Hebrew pronunciation. Already in the consider them as phoneticians who invented a writing 10th century the Tiberian grammarians used this pronounced [ʃva] in Modern) שְׁ וָא system to represent pronunciation. They used the term Hebrew term ʃwa] and graphically marked it with a special Hebrew), and graphically marked it by two vertical] שְׁ וָא sign (two vertical dots beneath a letter [ ְׁ ]).