Analysis and Development of Methods for Automotive Market Segmentation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cross-Country Comparison of Substitution Patterns in the European Car Market
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Research Papers in Economics Cross-country comparison of substitution patterns in the European car market Paper submitted to obtain the degree of Master of Advanced Studies in Economics Faculty of Business and Economics K.U. Leuven, Belgium Supervisor: Frank Verboven. Discussant: Patrick Van Cayseele Candidate: Victoria Oliinik January 2007 Abstract AIMS. Using recent data on sales, prices and product characteris- tics of new passenger vehicles sold in Europe’s seven largest markets during years 2000 through 2005, I estimate a demand function us- ing two approaches to the differentiated product demand estimation: the Logit and the Nested Logit. For the Nested Logit model, I use nests that roughly correspond to segmentation used in the automo- bile industry. I then compare substitution patterns resulting from Logit and Nested Logit specifications across countries and segments. FINDINGS. Regression outcomes demonstrate strong evidence of seg- mentation. Consumer preferences are strongly correlated for the most basic as well as for the luxury and sports segments, whereas core seg- ments display more heterogeneity. While car size preference varies across countries, Europeans typically like high and wide cars and dis- like long cars. Engine performance appreciation appears to have a curved shape: consumers are willing to pay for a fast car but at a de- creasing rate. Compared to their neighbors, Germans shop the most for premium brands yet display strongest price sensitivity, whereas most concerned about fuel consumption are the Brits. Aside from a few exceptions, all elasticities are within expected range, substitu- tion patterns vary mainly across segments but follow a similar pattern across countries. -

8EMEKRD*Ajicfc+ Akebono
LISTA DE APLICACIONES - BUYERS GUIDE 181906 181906 90R-01111/2567 8EMEKRD*ajicfc+ Akebono Qty: 300 Weight: 1.555 136.4x56.4x15.9 O.E.M. MAKE 45022-SZT-G00 HONDA 45022-SZY-T00 HONDA WVA FMSI 45022-T5R-A01 HONDA 24979 D1394-8502 45022-T5R-A50 HONDA 24980 D1783-8502 45022-T9A-T00 HONDA 24981 45022-TAR-G00 HONDA 25672 45022-TF0-G00 HONDA 25673 45022-TF0-G01 HONDA MAKE 45022-TF0-G02 HONDA HONDA 45022-TG0-T00 HONDA HONDA (DONGFENG) 45022-TK6-A00 HONDA HONDA (GAC) 45022-TM8-G00 HONDA 45022-TZB-G00 HONDA Trac. CC Kw CV Front / Rear HONDA CITY V / BALADE (GM2, GM3) 09.08- Saloon (Supermini car-B Segment) 1.4 i-V TEC (L13Z1) Gasolina FWD 1339 73 99 09.08- ■ 1.5 i-VTEC (GM2) (L15A7) Gasolina FWD 1497 88 120 02.09- ■ CITY VI / BALLADE / GREIZ / GIENIA (GM4, GM5, GM6, GM9, GM7) 07.13- Saloon (Supermini car-B Segment) 1.5 CNG Gasolina FWD 1497 75 102 01.14- ■ 1.5 i-VTEC (L15A7) Gasolina FWD 1497 88 119 01.14- ■ 1.5 i-VTEC (L15Z1) Gasolina FWD 1497 88 119 01.14- ■ 1.5 i-DTEC (N15A1) Diesel FWD 1498 74 100 01.14- ■ CR-Z (ZF) 06.10- Coupe (Compact car-C Segment) 1.5 IMA (ZF1) (LEA1) Gasol./el FWD 1497 84 114 06.10- ■ éc. 1.5 IMA (LEA1) Gasol./el FWD 1497 89 121 11.12- ■ éc. 1.5 IMA (LEA3) Gasol./el FWD 1497 89 121 11.12- ■ éc. 1.5 IMA (LEA1) Gasol./el FWD 1497 91 124 09.10-12.13 ■ éc. -

The Popularity of the Light Car in 21St-Century Europe
The popularity of the light car in 21st-century Europe By light cars I mean supermini cars, mini or small multipurpose vehicles, mini or small sport utility vehicles and City or minicar’s. In the United Kingdom today we seem to be overwhelmed with even larger Sport utility vehicles ,fancy trucks, and large German saloon cars, This led me to think about at what proportion are the various classes of vehicles on the road in the UK today. I was unable to obtain the data I was looking for the UK but was able to find a couple of sites that were able to furnish me with Data for Europe. One of them was carsalesbase.com which gave me the individual registration totals of cars in Europe for the last 20 years. Another site that gave me total for all passenger cars each year was the European automobile manufacturers association site the ACCO, and between those I was able to compose a simple list of all the classes of cars registered in Europe for the years 2015. Also I was able to produce detailed lists of the various light cars types for the last twenty years. Passenger car registrations in Europe for the period 1997 to 2016 amounted to two hundred and eighty-two million. The total number passenger cars registered in Europe in 2015 was almost thirteen point two million. The various size cars registered is as follows. Large cars 6%, Midsize cars 26%, Compact cars 25% and light or small cars 43% . The light car total is composed of the following. -

8EMEKRD*Aighgb+ Akebono
LISTA DE APLICACIONES - BUYERS GUIDE 181583 181583 90R-01111/1064 8EMEKRD*aighgb+ Akebono Qty: 300 Weight: 1.174 116.4x51.5x16.5 116.6x54.4x16.5 O.E.M. MAKE 04465-0D020 TOYOTA 04465-0D030 TOYOTA WVA FMSI 04465-0W050 TOYOTA 23510 D990-7695 04465-0W080 TOYOTA 23511 04465-12580 TOYOTA 23512 04465-12581 TOYOTA 23904 04465-12590 TOYOTA 23905 04465-12591 TOYOTA MAKE 04465-12592 TOYOTA BYD 04465-13020 TOYOTA SCION 04465-13041 TOYOTA TOYOTA 04465-13050 TOYOTA 04465-17102 TOYOTA 04465-32210 TOYOTA 04465-32230 TOYOTA 04465-47050 TOYOTA 04465-52021 TOYOTA 04465-52022 TOYOTA 04465-52100 TOYOTA 86 60 000 744 RENAULT 86 60 004 520 RENAULT Trac. CC Kw CV Front / Rear BYD F3 03.05- Saloon () DM Hybrid 1.0 (BYD371QA) Gasol./el FWD 998 50 68 01.09- ■ éc. SCION Hatchback (Supermini car-B xA (U.S.A.) 09.03-12.06 Segment) 1.5 Gasolina FWD 1497 77 105 09.03-12.06 ■ 1.5 Gasolina FWD 1497 81 110 09.03-12.05 ■ xB 09.03-12.06 MPV (Compact car-C Segment) 1.5 (1NZ-FE) -12/04 Gasolina FWD 1497 81 110 09.03-12.06 ■ TOYOTA ALLION (_T24_) 06.01-06.07 Saloon (Compact car-C Segment) 1.5 (NZT240) (1NZ-FE) Gasolina FWD 1497 80 109 06.01-04.05 ■ 1.8 (ZZT240) (1ZZ-FE) Gasolina FWD 1794 92 125 06.01-09.04 ■ 1.8 Gasolina FWD 1794 97 132 06.01-04.05 ■ 1.8 Gasolina FWD 1794 97 132 06.01-06.07 ■ 1.8 Gasolina FWD 1797 100 136 06.01-06.07 ■ 1.8 Gasolina FWD 1797 100 136 06.01-06.07 ■ 2.0 Gasolina FWD 1998 114 155 06.01-06.07 ■ bB (NCP3_) 01.00-12.05 MPV (Compact MPV-M1 Segment) 1.3 -12/05 Gasolina FWD 1298 68 92 12.05- ■ 1.3 (QNC20) (K3-VE) -12/05 Gasolina FWD 1298 68 92 12.05-06.16 -

VIP Limousines | Mini Vans MPV/SUV Executive Minibuses | Luxury Motorcoaches Our Commitment +31 202 402 300 (24/7) [email protected]
+31 202 402 300 (24/7) [email protected] Skip the line with chauffeur service & Book your ride instantly. Across places, across cities, across countries, across the World DMC Limousines can be your Global Luxury ground transportation provider in over 350 cities across the world, we will have you covered Executive Sedans | VIP limousines | Mini Vans MPV/SUV Executive Minibuses | Luxury MotorCoaches Our Commitment +31 202 402 300 (24/7) [email protected] Richard de Krijger: “At DMC Limousines Worldwide, we always strive to exceed our customers’ expectations and continually improve the quality of the service we deliver. The DMC Limousines reputation is, for more than 33 years of experience, built on integrity, trust and commitment. Quality and concern for our passengers are infused into every customer interaction - in the office and on the road. DMC Limousine services are impeccable, hassle free quality services, delivered by an elite corps of ground transportation professionals working with the finest technology and exceptionally well-maintained premium vehicles.” Every ride must be a Journey – we ensure +31 202 402 300 (24/7) One STOP / SHOP [email protected] CHAUFFEURED AIRPORT MEETINGS SIGHTSEEING VEHICLES GREETERS AND GROUPS TOURS & TICKETS No need to call Online account A seamless transaction multiple sources management under one roof Delivered to you Customized reporting All services quoted and on one itinerary capabilities as needed billed in EURO +31 202 402 300 (24/7) Technology [email protected] Whether you’re visiting our website and making reservations online, or a professional dispatcher is monitoring your flight, DMC Limousines has the technology needed to support efficiency and safety both in- and out- of our vehicles. -

Customer Behavior Analysis for the Romanian Automobiles Market
CUSTOMER BEHAVIOR ANALYSIS FOR THE ROMANIAN AUTOMOBILES MARKET STATISTICS PROJECT PROFESSOR: DANIELA SERBAN STUDENT: Ciresaru Ana Georgiana GROUP:131 ASE, 2013 - Table of contents - 1. Introduction 2. Presentation of the Romanian automobiles market 3. Methods used for doing the research 4. Case study analysis 5. Conclusions 6. References 1. Introduction 2 With a population of 21.6 million Romania is the third largest market in terms of population in Central and Eastern Europe (CEE) and the 7th largest among the European Union member states. However, Romania is one of the less wealthy nations within the E.U, Romania’s car penetration is still much lower than in Western European markets and also most other CEE markets like Poland or Bulgaria. In terms of car park however, Romania is among the top CEE markets. As in most other CEE markets, the car park is relatively old. 50% of cars are older than 10 years. Since Romania became a member of the EU in 2007, the import of used cars has increased significantly. These imports mainly consist of cars which comply with the Euro 3 - emission standards. Romania is actively trying to prevent a further increase in older used car imports. A government initiative to pay people for scrapping their older cars and buying a new one is helping to boost the new cars market. Financing of cars is well established, with loan financing and leasing being equally preferred by private individuals and leasing being the preferred method by corporate buyers. Financing used car purchases is also widespread. The purpose of this project is to analyze consumer behavior on the Romanian automotive market. -

Small Car Segment Dominates Europe's Biggest Markets 16.11.2007
November 16, 2007 SMALL CAR SEGMENT DOMINATES EUROPE’S BIGGEST MARKETS B-segment is dominant sector in the ‘big five’ markets Ford Fiesta is top selling B-segment model Medium MPV sales up 49.8% YtD Luxury car segment down by 15.3% YtD JATO Dynamics, the world’s leading provider of automotive data and intelligence, today reports that in Europe’s big five markets of France, Germany, Italy, Spain and the UK, third quarter volumes are a marginal 0.9% higher over the same period last year and down by an identical 0.9% YtD. The small car – or B- Segment – is the most popular with consumers, holding 27.0% of the market though it has posted a small 0.5% drop YtD. “With Europe’s big five markets down by 0.9% YtD, it would be easy to assume that the market is relatively stagnant,” says Nasir Shah, Global Business Development Director at JATO. “In fact, the market is subject to considerable change thanks to political and legislative changes, economic considerations and the effect of new model introductions. The German car market, for example, is still adjusting to the taxation changes introduced at the beginning of the year.” Segment Trends B-Segment The B-segment has the largest share of the market by a considerable margin, with 27.0% market share in the first nine months of 2007. Its total volume for the YtD is 0.5% less than a year ago, which represents a smaller fall than the total market has experienced over the same period. However, recent months have seen a decline in the segment’s volumes, with third quarter volumes 3.0% lower than the same period in 2006. -

Auto Data News 07 04
Cena 50 Kč 26. července 2004 ročník I. – číslo 2 | www.autodatanews.cz |ve spolupráci s 3 9 15 7 str. Čínská str. Továrna str. Pět let str. Dodavatelé pomoc TCPA aliance pro Škodu Britům krátce před Renault- Octavia dokončením Nissan Škoda Auto Foto: Změna ve vedení Škody Auto V SOUVISLOSTI S PŘESUNY VE VEDENÍ KONCERNU VW DOŠLO KE ZMĚNĚ I V ČELE Škoda Auto ŠKODA AUTO Foto: VLADIMÍR RYBECKÝ, AUTO DATA & NEWS PRAHA | Pfiedseda skupiny Volkswagen Bernd Pischetsrieder uskuteãnil celou fiadu v˘znamn˘ch personálních zmûn ve vedení koncernu a nûkter˘ch jeho znaãek. V dÛsledku tûchto pfiesunÛ dochází i k obmûnû v nejvy‰‰ím vedení ·kody Auto. Do vysoké funkce ‰éfa marketingu skupiny VW Pischetsrieder místo Jen- se Neumanna jmenoval Stefana Jaco- byho.Ten se ujal i fiízení prodeje znaã- ky Volkswagen v Nûmecku.V této roli vystfiídal Raku‰ana Georga Flandorfera (57), kter˘ pfievzal odpovûdnost za prodej znaãky Volkswagen a stal se ãlenem rady fieditelÛ. V této funkci vystfiídal Detlefa Wittiga (62), kter˘ se vrátí do Mladé Boleslavi jako pfiedseda pfiedstavenstva. Kromû toho dochází k pokračování na straně 2 h VRATISLAV KULHÁNEK, FERDINAND PIËCH A BERND PISCHETSRIEDER Čísla měsíce Jak vidíte prodejní výsledky v prv- Prodej osobních osobních automobilů v ČR ním pololetí? – červen 2004 Pokles prodeje Pfii komentování prodejních v˘sled- poř. značka ks za červen 2004 ks za červen 2003 kÛ se novináfii zamûfiují jen na osobní 1. Škoda 6 090 7 199 2. Volkswagen 1 054 739 automobily.Vzhledem k tomu, jak˘ je 3. Renault 627 843 v na‰í republice systém pfiihla‰ování 4. -

Russian New Car Market Almost Halves in 12 Months
28 August, 2009 RUSSIAN NEW CAR MARKET ALMOST HALVES IN 12 MONTHS Market crashes by 48.7% Lada still the market leader; 26% market share, but sales down 45.1% YtD Russian government acts to arrest decline Volkswagen is only top brand to increase sales JATO Dynamics, the world’s leading provider of automotive data and intelligence, reports that the Russian market has almost halved, suffering major sales losses in the first half of 2009. The overall market is down 48.7% from January to June, compared to the same period in 2008. “Russia is suffering more than any other region in world. Not even North America has seen new car registrations hit so heavily,” says Evangelos Hadjistavrou, Regional General Manager, JATO Dynamics. “Put more graphically, Russia has sold 676,428 fewer vehicles YtD, a figure barely comprehensible a few months ago. Not even government incentives to buy domestically-produced brands can protect manufacturers from the losses.” Of the volume brands, only Volkswagen has managed to increase sales during the period, whilst all the vehicle segments have posted significant sales losses. These losses could have been greater, but for action by the Russian government, including increasing support loans to customers of new Russian-built cars, costing less than 600,000 RUR (EUR 13,500; £11,700), from August 2009. A further scrappage incentive has been announced for 2010, of 50,000 RUR (EUR 1,125; £975), to arrest the decline of the new car market. Brand Performance Despite its own heavy sales losses, Lada continues its dominance of the Russian market, taking one quarter of the market. -

JAC Magazine 2014: Issue 10
Issue 10,2014 1 JAC INTERNATIONAL Issue 10 September, 2014 Editor-in-Chief Lisa Min Managing Editor Grace Wang Executive Editor The JAC Marketing Dept. Staff JAC International Company No.176, Dongliu Road, Hefei, China P.C: 230022 Tel: +86 5512296885 Fax: + 86 5512296097 Email:[email protected] Available in-house Free of Charge This information contained in this document is for reference only, and is subject to change or withdrawal according to specific customer requirements and condition. Copy Right 2013 Anhui Jianghuai Automobile Co., ltd All Rights Reserved Reproduction in whole or in part Without written permission is prohibited Contributions and Feedback An informative and inspiring JAC International Magazine need your continual contributions and feedback. Pleases feel free to submit your company‟s news& events, achievement in your markets and your successful experience, photos and your comments, to the editors at [email protected]. If your contribution includes except from other sources, please indicate. The deadline for submissions is the 10th of the month for publication 2 CONTENTS NEWS AND EVENTS The Annual Production Capacity of 150,000 units, JAC An Chi New Production Base was Completed JAC Mini MPV M3 Rolled off the Production Line JAC High-end Mini-truck X Series Launched into the Market JAC WORLDWIDE We Are Ready! The First 100 units of Pick-up Exported to Venezuela Set Sail MEDIA VIEW JAC J4 Motorcade Realizes China Rally Championship (CRC) Four Straight Championship 3 JAC NEWS & EVENTS On October 28th , 2014, JAC new An Chi Automobile Base was officially put into operation. Meanwhile, two new production –X200 (high-end mini truck) and M3 (mini MPV) rolled off the production line successfully, which presents the deep exploration of JAC in the area of commercial vehicle and passenger car. -

Car Classification
Car classification Car classification is subjective since many vehicles fall into multiple categories or do not fit well into any. Not all car types are common in all countries and names for the same vehicle can differ by region. Furthermore, some descriptions may be interpreted differently in different places. Broadly speaking, there are a set of classifications which are widely understood in North America, and another set which are somewhat understood in English-speaking contexts in Europe. Some terms borrowed from non-English languages may have different meanings when used in their native language. Classification systems The following are the most commonly used classifications. Where applicable, the equivalent Euro NCAP classifications are shown. Car rental companies often use the ACRISS Car Classification Code. The United States Environmental Protection Agency (US EPA) has another set of classification rules based on interior passenger and cargo volumes. A similar set of classes is used by the Canadian EPA. In Australia, the Federal Chamber of Automotive Industries publishes its own classifications. Car classification American English British English Segment Euro NCAP Examples Microcar Microcar, Bubble car - - BMW Isetta, Smart Fortwo - City car A-segment Daewoo Matiz, Renault Twingo, Toyota Aygo, VW Lupo Supermini Subcompact car Supermini B-segment Hyundai Accent, Ford Fiesta, Opel Corsa, Suzuki Swift Compact car Small family car C-segment Small family car Ford Focus, Toyota Corolla, Opel Astra, VW Golf Mid-size car Large family car -
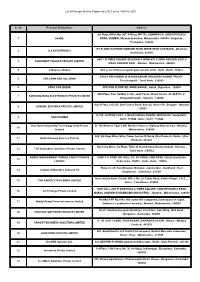
DLT Entities List
List of Principal Entities Registered in DLT as on 10th Feb 2021 Sr. No Principal Entity Name Address 9th Floor, Office No. 907, B-Wing, MITTAL COMMERCIA, ANDHERI KURLA 1 kwality ROAD, MUMBAI, Mumbai Suburban, Maharashtra, 400059 , Nalgonda , Telangana , 508246 1ST FLOOR RATHORE MANSION BANK MORE NEAR UCO BANK , Dhanbad , 2 S A ENTERPRISES Jharkhand , 826001 uNIT 1 B TIMES SQUARE BUILDING A WING 4TH FLOOR ANDHERI KURLA 3 DIGIKREDIT FINANCE PRIVATE LIMITED ROAD ANDHERI EAST , Mumbai , Maharashtra , 400059 4 ndfinancesolution A33 second floor peragarhi gaon pashim vihar , Delhi , Delhi , 110087 5/164/1 ARIYAVOOR VIJAYANAGARAM UKKADARIYAVOOR TRICHY , 5 CAR LOAN DSA ALL BANK Tiruchirappalli , Tamil Nadu , 620009 6 APNA CAR BAZAR OPP KGN FLOOR MIL SOOR SAGAR , KotaA , Rajasthan , 324005 20th Floor, Two Horizon Centre, Golf Course Road, Sector -43, DLF Ph. V , 7 SAMSUNG INDIA ELECTRONICS PRIVATE LIMITED GurgaonGurgaon , Haryana , 122002 Vipul Plaza, 215-220, Golf Course Road, Suncity, Sector 54 , Gurgaon , Haryana 8 GROUPE SEB INDIA PRIVATE LIMITED , 122002 D-798, JAITPUR PART -2, NEAR HOLIKA CHOWK, NEW DELHI, South Delhi, 9 HAACHI INDIA Delhi, 110044 , Delhi , Delhi , 110044 interTouch Hospitality Technology India Private B -708 Western Edge II Off, Western Express Highway Borivali East , Mumbai , 10 Limited Maharashtra , 400066 920, 9th Floor Wave Silver Tower Sector-18 Noida Uttar Pradesh , Noida , Uttar 11 Blink Advisory Services Pvt Ltd Pradesh , 201301 Kochchar Bliss, 1st Floor, Thiru Vi. Ka Industrial Estate, Guindy , Chennai , 12 TVS Automobile Solutions Private Limited Tamil Nadu , 600032 AGNES MANAGEMENT CONSULTANCY PRIVATE SHOP F-3, PROP NO. 602/2, F/F, GT ROAD, LONI ROAD, DELHI, East Delhi, 13 LIMITED Delhi, India, 110032 , Delhi , Delhi , 110032 Shop no- 05, Tulsi Bhawan ,Bistupur, Jamshedpur, Jharkhand , East 14 shrotam informatics india pvt ltd Singhbhum , Jharkhand , 831001 Karur Vysya Bank, Central Office, No.