Cross-Country Comparison of Substitution Patterns in the European Car Market
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analysis and Statistics the French Automotive Industry 2004 Edition the French Automotive Industry Industry Automotive the French
2004 Edition Analysis and Statistics The French Automotive Industry 2004 Edition The French Automotive Industry Industry Automotive The French PARIS EXPO. PORTE DE VERSAILLES. TOUS LES JOURS 10H-22H. (*0,34 euro TTC/min) Billets en vente : www.mondial-automobile.com Tél. : 0892 702 604* Magasins Fnac, Carrefour, Géant. Billets combinés RATP. Comité des Constructeurs Français d’Automobiles Comité des Constructeurs Français d’Automobiles Comité des Constructeurs Français d’Automobiles (CCFA) is the French automobile manufacturers’ trade association. It has seven members: Alpine, Automobiles Citroën, Heuliez, Panhard & Levassor, Automobiles Peugeot, Renault and Renault Trucks. Its mission is to study and defend the business and industrial interests—excluding labor issues— of all French automobile manufacturers at both the national and international levels. CCFA’s activities encompass information, analysis and communication for its members as well as for government agencies, public officials, the media and the general public. Other sectors of the automotive industry—parts and equipment manufacturers, dealers, body manufacturers, etc.—have their own trade associations (FIEV, CNPA, Fédération des Industries Mécaniques, Fédération de la Plasturgie, etc.). Foreign manufacturers are represented by their own association (CSIAM). CCFA is associated with the Brussels-based ACEA, the European Automobile Manufacturers Association. It is also a member of OICA, the International Organization of Motor Vehicle Manufacturers, which brings together national -

Citroën Berlingo
CITROËN BERLINGO (MF) 1.9 D (MFWJZ) 07.98 - 10.05 51 70 1868 4 CITROËN BERLINGO (MF) 1.9 D 4WD (MFWJZ) 07.98 - 51 69 1868 4 CITROËN BERLINGO karoserie (M_) 1.9 D 70 04.99 - 51 69 1868 4 (MBWJZ, MCWJZ) CITROËN BERLINGO karoserie (M_) 1.9 D 70 4WD 07.98 - 51 69 1868 4 (MBWJZ, MCWJZ) CITROËN BERLINGO karoserie (M_) 2.0 HDI 90 12.99 - 66 90 1997 4 (MBRHY, MCRHY) CITROËN BERLINGO karoserie (M_) 2.0 HDI 90 4WD 11.00 - 66 90 1997 4 (MBRHY, MCRHY) CITROËN C5 I (DC_) 2.0 HDi (DCRHYB) 03.01 - 08.04 66 90 1997 4 CITROËN C5 I (DC_) 2.0 HDi 03.01 - 08.04 79 107 1997 4 CITROËN C5 I (DC_) 2.0 HDi (DCRHZB, DCRHZE) 03.01 - 08.04 80 109 1997 4 CITROËN C5 I (DC_) 2.0 HDi (DCRHZB, DCRHZE) 06.01 - 08.04 80 109 1997 4 CITROËN C5 I (DC_) 2.2 HDi (DC4HXB, DC4HXE) 03.01 - 08.04 98 133 2179 4 CITROËN C5 I Break (DE_) 2.0 HDi (DERHYB) 06.01 - 08.04 66 90 1997 4 CITROËN C5 I Break (DE_) 2.0 HDi (DERHSB, 06.01 - 08.04 79 107 1997 4 DERHSE) CITROËN C5 I Break (DE_) 2.0 HDi 06.01 - 08.04 80 109 1997 4 CITROËN C5 I Break (DE_) 2.2 HDi (DE4HXB, 06.01 - 08.04 98 133 2179 4 DE4HXE) CITROËN C5 II (RC_) 2.2 HDi (RC4HXE) 09.04 - 98 133 2179 4 CITROËN C5 II (RC_) 2.2 HDi (RC4HXE) 02.05 - 98 133 2179 4 CITROËN C5 II Break (RE_) 2.2 HDi (RE4HXE) 09.04 - 98 133 2179 4 CITROËN C5 II Break (RE_) 2.2 HDi (RE4HXE) 02.05 - 98 133 2179 4 CITROËN C8 (EA_, EB_) 2.0 HDi 07.02 - 79 107 1997 4 CITROËN C8 (EA_, EB_) 2.0 HDi 07.02 - 80 109 1997 4 CITROËN C8 (EA_, EB_) 2.2 HDi 07.02 - 94 128 2179 4 CITROËN C8 (EA_, EB_) 2.2 HDi 06.07 - 120 163 2179 4 CITROËN C8 (EA_, EB_) 2.2 HDi 06.06 - 125 -

P 01.Qxd 6/30/2005 2:00 PM Page 1
p 01.qxd 6/30/2005 2:00 PM Page 1 June 27, 2005 © 2005 Crain Communications GmbH. All rights reserved. €14.95; or equivalent 20052005 GlobalGlobal MarketMarket DataData BookBook Global Vehicle Production and Sales Regional Vehicle Production and Sales History and Forecast Regional Vehicle Production and Sales by Model Regional Assembly Plant Maps Top 100 Global Suppliers Contents Global vehicle production and sales...............................................4-8 2005 Western Europe production and sales..........................................10-18 North America production and sales..........................................19-29 Global Japan production and sales .............30-37 India production and sales ..............39-40 Korea production and sales .............39-40 China production and sales..............39-40 Market Australia production and sales..........................................39-40 Argentina production and sales.............45 Brazil production and sales ....................45 Data Book Top 100 global suppliers...................46-50 Mary Raetz Anne Wright Curtis Dorota Kowalski, Debi Domby Senior Statistician Global Market Data Book Editor Researchers [email protected] [email protected] [email protected], [email protected] Paul McVeigh, News Editor e-mail: [email protected] Irina Heiligensetzer, Production/Sales Support Tel: (49) 8153 907503 CZECH REPUBLIC: Lyle Frink, Tel: (49) 8153 907521 Fax: (49) 8153 907425 e-mail: [email protected] Tel: (420) 606-486729 e-mail: [email protected] Georgia Bootiman, Production Editor e-mail: [email protected] USA: 1155 Gratiot Avenue, Detroit, MI 48207 Tel: (49) 8153 907511 SPAIN, PORTUGAL: Paulo Soares de Oliveira, Tony Merpi, Group Advertising Director e-mail: [email protected] Tel: (35) 1919-767-459 Larry Schlagheck, US Advertising Director www.automotivenewseurope.com Douglas A. Bolduc, Reporter e-mail: [email protected] Tel: (1) 313 446-6030 Fax: (1) 313 446-8030 Tel: (49) 8153 907504 Keith E. -

8EMEKRD*Ajicfc+ Akebono
LISTA DE APLICACIONES - BUYERS GUIDE 181906 181906 90R-01111/2567 8EMEKRD*ajicfc+ Akebono Qty: 300 Weight: 1.555 136.4x56.4x15.9 O.E.M. MAKE 45022-SZT-G00 HONDA 45022-SZY-T00 HONDA WVA FMSI 45022-T5R-A01 HONDA 24979 D1394-8502 45022-T5R-A50 HONDA 24980 D1783-8502 45022-T9A-T00 HONDA 24981 45022-TAR-G00 HONDA 25672 45022-TF0-G00 HONDA 25673 45022-TF0-G01 HONDA MAKE 45022-TF0-G02 HONDA HONDA 45022-TG0-T00 HONDA HONDA (DONGFENG) 45022-TK6-A00 HONDA HONDA (GAC) 45022-TM8-G00 HONDA 45022-TZB-G00 HONDA Trac. CC Kw CV Front / Rear HONDA CITY V / BALADE (GM2, GM3) 09.08- Saloon (Supermini car-B Segment) 1.4 i-V TEC (L13Z1) Gasolina FWD 1339 73 99 09.08- ■ 1.5 i-VTEC (GM2) (L15A7) Gasolina FWD 1497 88 120 02.09- ■ CITY VI / BALLADE / GREIZ / GIENIA (GM4, GM5, GM6, GM9, GM7) 07.13- Saloon (Supermini car-B Segment) 1.5 CNG Gasolina FWD 1497 75 102 01.14- ■ 1.5 i-VTEC (L15A7) Gasolina FWD 1497 88 119 01.14- ■ 1.5 i-VTEC (L15Z1) Gasolina FWD 1497 88 119 01.14- ■ 1.5 i-DTEC (N15A1) Diesel FWD 1498 74 100 01.14- ■ CR-Z (ZF) 06.10- Coupe (Compact car-C Segment) 1.5 IMA (ZF1) (LEA1) Gasol./el FWD 1497 84 114 06.10- ■ éc. 1.5 IMA (LEA1) Gasol./el FWD 1497 89 121 11.12- ■ éc. 1.5 IMA (LEA3) Gasol./el FWD 1497 89 121 11.12- ■ éc. 1.5 IMA (LEA1) Gasol./el FWD 1497 91 124 09.10-12.13 ■ éc. -

GTA Agreed Maximum Settlement Rates (Excluding Vat) for All Car Hire Claims on Or After 01.07.09
GTA agreed maximum settlement rates (excluding vat) for all car hire claims on or after 01.07.09 Groups Rate (£s) Sample Vehicles excl VAT Standard Vauxhall Agila (1.0) / Citroen C1 (1.0) / Peugeot 107 (1.0) / Nissan Micra (1.0) / Toyota Yaris (1.0), Fiat Sceicento (889cc), S1 28.79 Microcar Virgo 1.0, Smart Pulse Coupe 600cc (moved from S2 19.5.10), VW Polo (1.2) / Renault Clio (1.2) / Vauxhall Corsa (1.2) / Ford Fiesta (1.2), Smart ForFour (1.1), S2 32.64 Suzuki Wagon 1229cc, Vauxhall Astra (1.4) / Ford Focus (1.4) / Peugeot 307 (1.4) / Toyota Corolla (1.4) / VW Polo (1.4) / Honda Civic (1.4), Smart ForFour (1.3), Citroen Berlingo Multispace X 1.4, Hyundai Getz D GRTD/GSI 1.5, Peugeot 207 1.4, Honda Jazz 1.5, Vauxhall S3 34.83 Meriva Life 1.4, Vauxhall Corsa 1.4, Suzuki Jimney 1.4, Nissan Note Acenta 1398, Peugeot 307 (1.6) / Renault Megane (1.6) / Vauxhall Astra (1.6) / Ford Focus (1.6), Smart ForFour (1.5), V W Beetle 1.4, Ford Street ka 1.6, Mini One 1.6, Vauxhall Meriva 1.6, Peugeot, 206 Allure Coupe 1587cc, Citroen C3 Pluriel Convertible 1360, Renault Modus 1.6, VW Golf GT TSI 1.4, Alfa Romeo Mito 1.4, Toyota Prius 1500, Honda Insight hybrid 1399, Seat Altea 1.4 (moved from S4 37.33 M2 19.5.10), Peugeot 407 (1.8) / Vauxhall Vectra (1.8) / Ford Mondeo (1.8) / Renault Laguna (1.8), V W Beetle 1.4 convertible, Ford Street ka 1.6 convertible, Mitsubishi Colt CZC cabriolet 1.5, , Vauxhall Tigra coupe cabriolet 1.8, Volkswagen Passat SE 20v Turbo1791 (petrol), Toyota Avensis 1.8, Volkswagon Golf SE 2 door Cabriolet 1595cc, Peugeot 206 -

New Number Announcement December-January Date Duty Type Principal Applications Click on Part Number for Additional Product Detail
English 2015/2016 New Number Announcement December-January Date Duty Type Principal Applications Click on part number for additional product detail. *Added for Non-US Market. 3192MP 1/7/16 H Fuel Agco, Bobcat, New Holland, Volvo, Other. Replaces: Clark 6647774 Various Hitachi, Isuzu, Komatsu & Kubota Equipment, TCM & Toyota 3386MP 1/7/16 H Fuel Forklifts (10 Micron). Replaces: Nissan 16403Z7000 Ford F-Series Super Duty PU w/ 6.7L diesel (2011). Replaces: Ford 7151MP 1/21/16 H Lube BC3Z6731A Various Dodge, Chrysler, Jeep, Ram (08-15). Replaces: Mopar 7899MP 1/7/16 L Lube 04884899AB Flame Retardant Version - Cadillac (02-15), Chev/GMC Trucks + 2488FR 1/7/16 L Air SUVs (99-15) (Heavy Duty). Flame Retardant Version - Dodge Pickup (07-11), Ram Pickup (07- 6930FR 1/7/16 H Air 15) w/ 6.7L Cummins Diesel. Flame Retardant Version - Ford Super Duty PU w/ 6.7L diesel (11- 9902FR 1/13/16 H Air 16) Flame Retardant Version - Dodge Ram P/U w/ 5.9L Turbo Diesel 9946FR 1/7/16 L Air (03-09) - Has 4" Pleat. Gravely, Ferris, Yazoo, Kawasaki mowers, lawn tractors (X3000 & 500168 1/7/16 H Air X304 series). Replaces: Kawasaki 110137017 Cub Cadet, Encore, Exmark mowers, Kawasaki small engines. 500172 1/13/16 H Air Replaces: Kawasaki 110137031 Page 1 of 17 English 2015/2016 New Number Announcement December-January Date Duty Type Principal Applications Click on part number for additional product detail. *Added for Non-US Market. 200261 1/13/16 L Air Ford Fiesta (14-15). Replaces: Ford CN1Z9601A Ram ProMaster w/ 3.0L Diesel (14-15), Fiat Ducato, Peugeot, Other. -

The Popularity of the Light Car in 21St-Century Europe
The popularity of the light car in 21st-century Europe By light cars I mean supermini cars, mini or small multipurpose vehicles, mini or small sport utility vehicles and City or minicar’s. In the United Kingdom today we seem to be overwhelmed with even larger Sport utility vehicles ,fancy trucks, and large German saloon cars, This led me to think about at what proportion are the various classes of vehicles on the road in the UK today. I was unable to obtain the data I was looking for the UK but was able to find a couple of sites that were able to furnish me with Data for Europe. One of them was carsalesbase.com which gave me the individual registration totals of cars in Europe for the last 20 years. Another site that gave me total for all passenger cars each year was the European automobile manufacturers association site the ACCO, and between those I was able to compose a simple list of all the classes of cars registered in Europe for the years 2015. Also I was able to produce detailed lists of the various light cars types for the last twenty years. Passenger car registrations in Europe for the period 1997 to 2016 amounted to two hundred and eighty-two million. The total number passenger cars registered in Europe in 2015 was almost thirteen point two million. The various size cars registered is as follows. Large cars 6%, Midsize cars 26%, Compact cars 25% and light or small cars 43% . The light car total is composed of the following. -
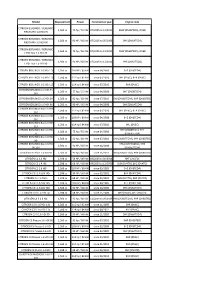
Model Displacement Power Construction Year Engine Code
Model Displacement Power Construction year Engine code CITROËN BERLINGO / BERLINGO 1,560 cc 75 hp / 55 kW 07/2005 to 12/2011 9HW (DV6BTED4), DV6B FIRST MPV 1.6 HDI 75 CITROËN BERLINGO / BERLINGO 1,560 cc 90 HP / 66 kW 07/2005 to 05/2008 9HX (DV6ATED4) FIRST MPV 1.6 HDI 90 CITROËN BERLINGO / BERLINGO 1,560 cc 75 hp / 55 kW 07/2005 to 12/2011 9HW (DV6BTED4), DV6B FIRST Box 1.6 HDI 75 CITROËN BERLINGO / BERLINGO 1,560 cc 90 HP / 66 kW 07/2005 to 12/2011 9HX (DV6ATED4) FIRST Box 1.6 HDI 90 CITROËN BERLINGO 1.6 HDi 110 1,560 cc 109 HP / 80 kW since 04/2008 9HZ (DV6TED4) CITROËN BERLINGO 1.6 HDi 110 1,560 cc 112 hp / 82 kW since 07/2010 9HL (DV6C), 9HR (DV6C) CITROËN BERLINGO 1.6 HDi 115 1,560 cc 114 hp / 84 kW since 07/2010 9HR (DV6C) CITROËN BERLINGO 1.6 HDi 75 1,560 cc 75 hp / 55 kW since 04/2008 9HT (DV6BTED4) 16V CITROËN BERLINGO 1.6 HDi 90 1,560 cc 92 hp / 68 kW since 07/2010 9HJ (DV6DTEDM), 9HP (DV6DTED) CITROËN BERLINGO 1.6 HDi 90 1,560 cc 90 HP / 66 kW since 04/2008 9HX (DV6ATED4) CITROËN BERLINGO Box 1.6 HDi 1,560 cc 112 hp / 82 kW since 07/2010 9HL (DV6C), 9HR (DV6C) 110 CITROËN BERLINGO Box 1.6 HDi 1,560 cc 109 HP / 80 kW since 04/2008 9HZ (DV6TED4) 110 CITROËN BERLINGO Box 1.6 HDi 1,560 cc 114 hp / 84 kW since 07/2010 9HL (DV6C) 115 CITROËN BERLINGO Box 1.6 HDi 9HT (DV6BTED4), 9HT 1,560 cc 75 hp / 55 kW since 04/2008 75 (DV6BUTED4) CITROËN BERLINGO Box 1.6 HDi 1,560 cc 92 hp / 68 kW since 07/2010 9HJ (DV6DTEDM), 9HP (DV6DTED) 90 CITROËN BERLINGO Box 1.6 HDi 9HS (DV6TED4BU), 9HX 1,560 cc 90 HP / 66 kW since 04/2008 90 16V (DV6AUTED4) -

8EMEKRD*Aighgb+ Akebono
LISTA DE APLICACIONES - BUYERS GUIDE 181583 181583 90R-01111/1064 8EMEKRD*aighgb+ Akebono Qty: 300 Weight: 1.174 116.4x51.5x16.5 116.6x54.4x16.5 O.E.M. MAKE 04465-0D020 TOYOTA 04465-0D030 TOYOTA WVA FMSI 04465-0W050 TOYOTA 23510 D990-7695 04465-0W080 TOYOTA 23511 04465-12580 TOYOTA 23512 04465-12581 TOYOTA 23904 04465-12590 TOYOTA 23905 04465-12591 TOYOTA MAKE 04465-12592 TOYOTA BYD 04465-13020 TOYOTA SCION 04465-13041 TOYOTA TOYOTA 04465-13050 TOYOTA 04465-17102 TOYOTA 04465-32210 TOYOTA 04465-32230 TOYOTA 04465-47050 TOYOTA 04465-52021 TOYOTA 04465-52022 TOYOTA 04465-52100 TOYOTA 86 60 000 744 RENAULT 86 60 004 520 RENAULT Trac. CC Kw CV Front / Rear BYD F3 03.05- Saloon () DM Hybrid 1.0 (BYD371QA) Gasol./el FWD 998 50 68 01.09- ■ éc. SCION Hatchback (Supermini car-B xA (U.S.A.) 09.03-12.06 Segment) 1.5 Gasolina FWD 1497 77 105 09.03-12.06 ■ 1.5 Gasolina FWD 1497 81 110 09.03-12.05 ■ xB 09.03-12.06 MPV (Compact car-C Segment) 1.5 (1NZ-FE) -12/04 Gasolina FWD 1497 81 110 09.03-12.06 ■ TOYOTA ALLION (_T24_) 06.01-06.07 Saloon (Compact car-C Segment) 1.5 (NZT240) (1NZ-FE) Gasolina FWD 1497 80 109 06.01-04.05 ■ 1.8 (ZZT240) (1ZZ-FE) Gasolina FWD 1794 92 125 06.01-09.04 ■ 1.8 Gasolina FWD 1794 97 132 06.01-04.05 ■ 1.8 Gasolina FWD 1794 97 132 06.01-06.07 ■ 1.8 Gasolina FWD 1797 100 136 06.01-06.07 ■ 1.8 Gasolina FWD 1797 100 136 06.01-06.07 ■ 2.0 Gasolina FWD 1998 114 155 06.01-06.07 ■ bB (NCP3_) 01.00-12.05 MPV (Compact MPV-M1 Segment) 1.3 -12/05 Gasolina FWD 1298 68 92 12.05- ■ 1.3 (QNC20) (K3-VE) -12/05 Gasolina FWD 1298 68 92 12.05-06.16 -

Europe Swings Toward Suvs, Minivans Fragmenting Market Sedans and Station Wagons – Fell Automakers Did Slightly Better Than Cent
AN.040209.18&19.qxd 06.02.2004 13:25 Uhr Page 18 ◆ 18 AUTOMOTIVE NEWS EUROPE FEBRUARY 9, 2004 ◆ MARKET ANALYSIS BY SEGMENT Europe swings toward SUVs, minivans Fragmenting market sedans and station wagons – fell automakers did slightly better than cent. The only new product in an cent because of declining sales for 656,000 units or 5.5 percent. mass-market automakers. Volume otherwise aging arena, the Fiat the Honda HR-V and Mitsubishi favors the non-typical But automakers boosted sales of brands lost close to 2 percent of vol- Panda, was on sale for only four Pajero Pinin. over familiar sedans unconventional vehicles – coupes, ume last year, compared to 0.9 per- months of the year. In terms of brands leading the roadsters, minivans, sport-utility cent for luxury marques. European buyers seem to pro- most segments, Renault is the win- LUCA CIFERRI vehicles exotic cars and multi- Traditional European-brand gressively walk away from large ner with four. Its Twingo leads the spaces such as the Citroen Berlingo automakers dominate the tradi- sedans, down 20.3 percent for the minicar segment, but Renault also AUTOMOTIVE NEWS EUROPE – by 16.8 percent last year to nearly tional car, minivan and premium volume makers and off 11.1 percent leads three other segments that it 3 million units. segments, but Asian brands control in the upper-premium segment. created: compact minivan, Scenic; TURIN – Automakers sold 428,000 These non-traditional vehicle cat- virtually all the top spots in small, large minivan, Espace; and multi- more specialty vehicles last year in egories, some of which barely compact and large SUV segments. -

Nylon Clutch Cylinder
No. PHOTO OEM No. APPLICATION 31420-12030 TOYOTA AURIS 07/03 PA001 31420-0K012 TOYOTA H HILUX (VIGO) III Pickup 31420-0K013 2182.17 PEUGEOT 406/206/607/307/807/407/308 2182.22 PEUGEOT EXPERT/PARTNER 2182.95 FIAT ULYSSE 9626813180 PA002 LANCIA PHEDRA 9635975480 SUZUKI LIANA 9641622380 CITROEN JUMPY/BERLINGO/XSARA 9682650080 CITROEN C2/C3/C4/C5/C8 23820-73J00 1330266 1476806 31259462 FORD FOCUS II (DA_)/FOCUS II Estate (DA_) 1549937 1539937 FORD FOCUS II Saloon (DA_)/FOCUS II Convertible FORD FOCUS III/FOCUS III Saloon/Turnier 3M517A543AG 3M517A543AF FORD KUGA I/KUGA II (DM2)/C-MAX II/C-MAX (DM2)/II Van 3M517A543AE 3M517A543AD PA003 FORD GRAND C-MAX/C-MAX Van (2010/12 - /) BP4K-41-400C BP4K-41-400D FORD AUSTRALIA FOCUS Hatchback/Saloon BP4K-41-400E BP4K-41-400B FORD AUSTRALIA FOCUS Coupe (LT)/Hatchback (LW) FORD AUSTRALIA FOCUS Saloon (LW)/KUGA (TE) 1232971 1226669 30681422 MAZDA 3 (BK)/Saloon (BK)/3 (BL)/3 Saloon (BL) 1224067 8675600 30787890 MAZDA 5 (CR19) /5 (CW)/VOLVO S40 II (MS)/V50 (MW)/C30 CITROEN C4 Coupe (LA_) (2004/11 - /) CITROEN C4 I (LC_) (2004/11 - /) CITROEN C4 Saloon (2006/07 - /) PEUGEOT 307 (3A/C) (2000/08 - /) 2182.82 PA004 PEUGEOT 307 SW (3H) (2002/03 - /) 2182.24 PEUGEOT 307 CC (3B) (2003/10 - /) PEUGEOT 307 Break (3E) (2002/03 - /) PEUGEOT 308 (4A_, 4C_) (2007/09 - /) PEUGEOT 308 SW (2007/09 - /) AUDI 100 (44, 44Q, C3) (1982/08 - 1991/07) 8E1-721-401 AUDI A4 (8D2, B5)/A4 Avant (8D5, B5)/A4 (8E2, B6) AUDI A4 Avant (8E5, B6)/Convertible(8H7, B6, 8HE, B7) 8E1-721-401K AUDI A4 (8EC, B7)/A4 Avant (8ED, B7) (2004/11 - 2008/06) -

VIP Limousines | Mini Vans MPV/SUV Executive Minibuses | Luxury Motorcoaches Our Commitment +31 202 402 300 (24/7) [email protected]
+31 202 402 300 (24/7) [email protected] Skip the line with chauffeur service & Book your ride instantly. Across places, across cities, across countries, across the World DMC Limousines can be your Global Luxury ground transportation provider in over 350 cities across the world, we will have you covered Executive Sedans | VIP limousines | Mini Vans MPV/SUV Executive Minibuses | Luxury MotorCoaches Our Commitment +31 202 402 300 (24/7) [email protected] Richard de Krijger: “At DMC Limousines Worldwide, we always strive to exceed our customers’ expectations and continually improve the quality of the service we deliver. The DMC Limousines reputation is, for more than 33 years of experience, built on integrity, trust and commitment. Quality and concern for our passengers are infused into every customer interaction - in the office and on the road. DMC Limousine services are impeccable, hassle free quality services, delivered by an elite corps of ground transportation professionals working with the finest technology and exceptionally well-maintained premium vehicles.” Every ride must be a Journey – we ensure +31 202 402 300 (24/7) One STOP / SHOP [email protected] CHAUFFEURED AIRPORT MEETINGS SIGHTSEEING VEHICLES GREETERS AND GROUPS TOURS & TICKETS No need to call Online account A seamless transaction multiple sources management under one roof Delivered to you Customized reporting All services quoted and on one itinerary capabilities as needed billed in EURO +31 202 402 300 (24/7) Technology [email protected] Whether you’re visiting our website and making reservations online, or a professional dispatcher is monitoring your flight, DMC Limousines has the technology needed to support efficiency and safety both in- and out- of our vehicles.