The Case Folding Solution for the Arabic Script
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grammatical Analysis of Nastalique Writing Style of Urdu
Grammatical Analysis of Nastalique Writing Style of Urdu 1 Historical Note Nastalique is one of the most intricate styles used for Arabic script, which makes it both beautiful and complex to model. This analysis has been conducted as part of the development process of Nafees Nastalique Font. The work has been conducted in 2002 and is being released for the general development of Nastalique writing style. The work has been supported by APDIP UNDP and IDRC. Authors Sarmad Hussain Shafiq ur Rahman Aamir Wali Atif Gulzar Syed Jamil ur Rahman December, 2002 2 Table of Contents HISTORICAL NOTE ............................................................................................................................................. 2 1. THE NASTALIQUE STYLE: AN INTRODUCTION .................................................................................... 5 2. URDU SCRIPT .................................................................................................................................................... 5 2.1. THE URDU ALPHABET .................................................................................................................................... 5 2.2. MAPPING BETWEEN NASTALIQUE AND URDU CHARACTERS ........................................................................... 6 2.3. BUILDING BLOCKS FOR AN URDU FONT ......................................................................................................... 7 2.3.1 Urdu Characters .................................................................................................................................... -

Nastaleeq: a Challenge Accepted by Omega
Nastaleeq: A challenge accepted by Omega Atif Gulzar, Shafiq ur Rahman Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, Lahore, Pakistan atif dot gulzar (at) gmail dot com, shafiq dot rahman (at) nu dot edu dot pk Abstract Urdu is the lingua franca as well as the national language of Pakistan. It is based on Arabic script, and Nastaleeq is its default writing style. The complexity of Nastaleeq makes it one of the world's most challenging writing styles. Nastaleeq has a strong contextual dependency. It is a cursive writing style and is written diagonally from right to left. The overlapping shapes make the nuqta (dots) and kerning problem even harder. With the advent of multilingual support in computer systems, different solu- tions have been proposed and implemented. But most of these are immature or platform-specific. This paper discuses the complexity of Nastaleeq and a solution that uses Omega as the typesetting engine for rendering Nastaleeq. 1 Introduction 1.1 Complexity of the Nastaleeq writing Urdu is the lingua franca as well as the national style language of Pakistan. It has more than 60 mil- The Nastaleeq writing style is far more complex lion speakers in over 20 countries [1]. Urdu writing than other writing styles of Arabic script{based lan- style is derived from Arabic script. Arabic script has guages. The salient features`r of Nastaleeq that many writing styles including Naskh, Sulus, Riqah make it more complex are these: and Deevani, as shown in figure 1. Urdu may be • Nastaleeq is a cursive writing style, like other written in any of these styles, however, Nastaleeq Arabic styles, but it is written diagonally from is the default writing style of Urdu. -

Sorani Vocabulary
Sorani Kurdish Vocabulary Circumflexed vowels follow uncircumflexed vowels in alphabetization. The furtive i is indicated by italicization, e.g. bâwik ‘father’ but bâwkî ‘his father.’ Abbreviations: adj. = adjective; cond. = conditional; demon. = demonstrative; imprs. = impersonal (verb is always in the 3rd person singular); impt. = imperative; pl. = plural; pron. = pronoun; sing. = singular; subj. = subjunctive; pres. = present; v.i. = verb intransitive; v.p. = verb passive; v.t. = verb transitive (transitive implies that the past tense is formed on the ergative model, not that the verb necessarily takes a direct object either in Kurdish or in English). Generally, compound verbs are listed under the nonverbal element of the com- pound; compounds with frequently-occurring elements like dâ-, hał-, and pe- are listed under the verb. * :habitual verbal prefix (Sulaymani the city; ~ i engaged in, practicing ﺋــــــﻪ -a dialect); see da- ahl i îmân religious, ahl i kher chari- directional suffix on verbs: chûmà table, ahl i kayf hedonistic; ~ la…dâ ـﻪ à- shâr I went to town worthy of: fiłân la rafâqat’dâ zor ahl -a So-and-So is quite worthy of friend ﺋــــﻪدﻩﰉ literature, culture; ~î ﺋــــﻪدﻩب adab literature; ~par- ship ﺋـﻪدﻩﺑـﻴـﺎت literary; ~iyât Ahmad, masc. proper ﺋــــــﻪﲪــــــﻪد patron of literature; be~ Aḥmad ﺋـﻪدﻩﺑـﭙـﻪروﻩر war impo- name /ﺋــــﻪدﻩﰉ impolite; be~î /ﺋــــﻪدﻩب liberals ﺋﻪﺣﺮار liteness aḥrâr pharmacy ﺋﻪﺟﺰاﺎﻧﻪ litérateur, literary person, ajzâkhâna ﺋـــــﻪدﯾـــــﺐ adîb sing. definite suffix: pyâwaká ـﻪﮐـــــﻪ man of letters -aká gentleman, anyone who the man ﺋــﻪﻓــﻪﻧــﺪی afandî pl. definite suffix: pyâwakân ـﻪﰷن wears western clothes -akân Afrasiab, legendary the men ﺋـﻪﻓـﺮاﺳـ8ـﻴـﺎب Afrâsiyâb ﺋــﻪLــﻼﰵ morals, ethics; ~î ﺋــﻪLــﻼق king of Turan akhlâq Africa moral, ethical ﺋﻪﻓﺮﯾﻘ;ﺎ Afrîqyâ ,ﺋﻪﻓﺮﯾﻘﺎ Afrîqâ German ﺋﻪﻪﻣﺎﱏ officer Ałamânî ﺋﻪﻓﺴﻪر afsar now ﺋﻪﻵن al’ân ﺋــﻪﻓــﺴــﺎﻧــﻪﰃ tale, legend; ~î ﺋــﻪﻓــﺴــﺎﻧــﻪ afsâna electronic ﺋﻪﻟﻴﮑﱰۆﱏ legendary alîktronî (.this (demon. -

Dear Mark Davis!
Center of Excellence for Urdu Informatics National Language Authority H-8/4 Islamabad Dear Mark Davis! I hope that you will be fine. I received your letter regarding the nuqta characters in which you stated the reason for keeping these out of the standard. I would like to address my concerns regarding this. First of all, take the matter of the actual status of nuqta characters. Though they are supposed to act like combining marks but in their very essence these are characters that are needed most of the times right from publishing of primers to the archaic scripts. The nuqta characters added for Quran have a different status and a text processing client should be able to distinguish between the Quranic version of nuqta characters and the ordinary nuqta characters. The nuqta characters in the Quranic text have altogether different meanings than the proposed nuqta characters. Secondly, I would like to emphasize that standards should not be developed either in isolation or inclined to protect a fewer aspects. The Arabic script is mostly used in countries and regions which can be filed under the third world. The declining costs of microprocessors have made it possible for the people of poor countries to have a desktop PC. Moreover, the falling rates of internet connectivity have also made it possible for these people to browse and surf the internet. I would not stuff my discussion with explaining the digital divide, but I would like to make a point that it’s until recently that people have started to use the ARABIC SCRIPT on computers (Not Arabic language as it dates back earlier). -

General Historical and Analytical / Writing Systems: Recent Script
9 Writing systems Edited by Elena Bashir 9,1. Introduction By Elena Bashir The relations between spoken language and the visual symbols (graphemes) used to represent it are complex. Orthographies can be thought of as situated on a con- tinuum from “deep” — systems in which there is not a one-to-one correspondence between the sounds of the language and its graphemes — to “shallow” — systems in which the relationship between sounds and graphemes is regular and trans- parent (see Roberts & Joyce 2012 for a recent discussion). In orthographies for Indo-Aryan and Iranian languages based on the Arabic script and writing system, the retention of historical spellings for words of Arabic or Persian origin increases the orthographic depth of these systems. Decisions on how to write a language always carry historical, cultural, and political meaning. Debates about orthography usually focus on such issues rather than on linguistic analysis; this can be seen in Pakistan, for example, in discussions regarding orthography for Kalasha, Wakhi, or Balti, and in Afghanistan regarding Wakhi or Pashai. Questions of orthography are intertwined with language ideology, language planning activities, and goals like literacy or standardization. Woolard 1998, Brandt 2014, and Sebba 2007 are valuable treatments of such issues. In Section 9.2, Stefan Baums discusses the historical development and general characteristics of the (non Perso-Arabic) writing systems used for South Asian languages, and his Section 9.3 deals with recent research on alphasyllabic writing systems, script-related literacy and language-learning studies, representation of South Asian languages in Unicode, and recent debates about the Indus Valley inscriptions. -
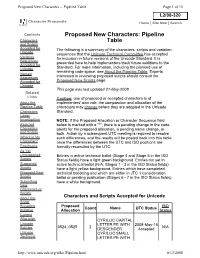
Pipeline Table Page 1 of 15
Proposed New Characters -- Pipeline Table Page 1 of 15 Character Proposals Home | Site Map | Search Contents Proposed New Characters: Pipeline Characters Table and Scripts Accepted for The following is a summary of the characters, scripts and variation Unicode sequences that the Unicode Technical Committee has accepted Variation for inclusion in future versions of the Unicode Standard. It is Sequences presented here to help implementers track future additions to the Accepted for Unicode Standard. For more information, including the planned use of remaining code space, see About the Pipeline Table. Experts Named Sequences interested in reviewing proposed scripts should consult the Accepted for Proposed New Scripts page. Unicode This page was last updated 21-May-2008 Related Links Caution: use of proposed or accepted characters is at About the implementers' own risk; the composition and allocation of the Pipeline Table characters may change before they are adopted in the Unicode Characters Standard. Under Investigation NOTE: If the Proposed Allocation or Character Sequence field Rejected below is marked with a "*", there is a pending change in the code Characters points for the proposed allocation, a pending name change, or and Scripts both. Action by a subsequent UTC meeting is required to resolve Where is My such differences, and the results will be posted back into this table Character? once the differences between the UTC and ISO positions are Roadmaps formally reconciled by the UTC. As Yet Unsupported Entries in active technical ballot (Stage 4 and Stage 5 in the ISO Scripts Status fields) have a light green background. Entries not yet in Supported active technical ballot (N/A, Stages 1 - 3 in the ISO Status fields) Scripts have a light yellow background. -

ISO/IEC International Standard 10646-1
Proposed Draft Amendment (PDAM) 7 ISO/IEC 10646:2003/Amd.7:2008 (E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 7: Mandaic, Batak, Brahmi, Tangut, and other characters Page 1, Clause 1 Scope The Tertiary Ideographic Plane (TIP), Plane 3 of Group 00, is reserved for ideographic characters and is cur- In the list item specifying the supplementary planes, rently empty. after „(SIP)‟, insert ‘the Tertiary Ideographic Plane (TIP)’. Page 8, Sub-clause 6.4 Naming of charac- In the list item enumerating the plane names replace ters ‘BMP, SMP, SIP, SSP’ with ‘BMP, SMP, SIP, TIP, SSP’. Page 2, Clause 3 Normative references Insert a new item d) before list item d) which become e): d) follows the rule given in 28.7 for Tangut characters, Update the reference to the Unicode Bidirectional Algo- or rithm and the Unicode Normalization Forms as follows: Unicode Standard Annex, UAX#9, The Unicode Bidi- Page 14, Sub-clause 20.3 Format characters rectional Algorithm, Version 6.0.0, [Date TBD]. Insert the following entry in the list of formats charac- Unicode Standard Annex, UAX#15, Unicode Normali- ters: zation Forms, Version 6.0.0, [Date TBD]. 2D7F TIFINAGH CONSONANT JOINER Editor‟s Note: The dates for the Unicode Standard An- Page 23, Clause 28 Character names and nexes mentioned above will be determined in future annotations phases of this amendment process. Insert a new sub-clause 28.7 and update accordingly Page 2, Clause 4 Terms and definitions following sub-clauses and cross references. Insert the following before the current 4.44 Unpaired 28.7 Character names for Tangut characters RC-element (as previously amended) and update ac- For Tangut characters, the names are algorithmically cordingly all following term numbers and cross refer- constructed by appending their coded representation in ences. -

View Full Report
Tenth Annual Report: The Most Notable Human Rights Violations in Syria in 2020 The Bleeding Decade Tuesday 26 January 2021 The Syrian Network for Human Rights (SNHR), founded in June 2011, is a non-governmental, independent group that is considered a primary source for the OHCHR on all death toll-related analyses in Syria. R210104E Photo showing damage to residential buildings in Ariha city in Idlib suburbs caused by a Russian air attack - January 29, 2020 Content I. Background 2 II. Landmark Key Events in 2020 4 III. Most Prominent Political, Military and Human Rights Events Related to Syria in 2020 32 IV. The Syrian Regime’s Direct Responsibility for Committing Violations in Syria in 2020 and the Names of Individuals We Believe Are Involved in Committing Egregious Violations 44 V. Achieving Progress in the Accountability Process 48 VI. Record of the Most Notable Human Rights Violations in Syria in 2020 According to the SNHR Database 53 VII. Comparison between the Most Notable Patterns of Human Rights Violations in 2019 and 2020 59 VIII. Summarizing the Most Notable Human Rights Violations Committed by the Parties to the Conflict and the Controlling Forces in Syria in 2020 62 IX. Recommendations 107 X. References 114 2 Tenth Annual Report: The Most Notable Human Rights Violations in Syria in 2020 I. Background: The Syrian Network for Human Rights (SNHR), founded in June 2011, three months after the outbreak of the popular uprising in March 2011, is a non-governmental, non-profit independent organization whose primary objective is to doc- ument all violations that occur in Syria, archive them within our extensive database, and issue periodic reports and studies based on them, with SNHR aiming to expose the perpetrators of these violations as a first step to holding them accountable, protecting the rights of the victims, and saving and cataloguing the history of events. -

The Devanagari Script by David Templin the Devanagari Script (देवनागरी लिलि) Is the Most Impressive Writing System That I Have Ever Studied
The Devanagari Script By David Templin The Devanagari Script (देवनागरी लिलि) is the most impressive writing system that I have ever studied. It impresses me for many reasons, for instance: • The ordering of the letters is according to precise scientific principles. • Each letter transcribes a distinct sound. • It recognizes subtle distinctions in sound. I also find Devanagari to be a very beautiful script. Note that this article will discuss the Devanagari Script as it is adapted for the Hindi language. The Ordering of Letters In order to appreciate the significance of the ordering of letters in Devanagari, some background information is necessary. Place of Articulation Consonants can be classified according to the place within the mouth that they are articulated. • Velar consonants are pronounced with the back of the tongue touching the soft palate. Examples of velar consontants in English include "k" as in "keep", and "g" as in "good". • Palatal consonants are pronounced with the tongue touching the hard palate. Examples of palatal consonants in English include "ch" as in "change" and "j" as in "job". • Retroflex consonants are pronounced with the tongue curled slightly backward and touching the front portion of the hard palate. There are no retroflex consonants in English. As an example, try pronouncing the "t" in "tip", yet curl your tongue backward. • Dental consonants are pronounced with the tip of the tongue touching the back of the upper front teeth. Examples of dental consontants in English include the "th" in "the", and the "th" in "thin". • Labial consonants are pronounced with the lips. -

Untersuchungen Zur Methodik Und Effizienz Der Tastaturbasierten Eingabeverfahren Verschiedener Schriftsysteme Der Welt
Untersuchungen zur Methodik und Effizienz der tastaturbasierten Eingabeverfahren verschiedener Schriftsysteme der Welt INAUGURAL-DISSERTATION zur Erlangung des Doktorgrades der Philosophie des Fachbereichs 05 – Sprache, Literatur & Kultur der Justus-Liebig-Universität Gießen vorgelegt von: WANG Kai Fontanestr. 3 35606 Solms März 2019 I Dekan: 1. Gutachter: Prof. Dr. Henning Lobin 2. Gutachter: Prof. Dr. Thomas Gloning Tag der Disputation: 13.02.2019 II Erklärung zur Dissertation Ich habe die vorgelegte Dissertation selbständig und nur mit den Hilfen angefertigt, die ich in der Dissertation angegeben habe. Alle Textstellen, die wörtlich oder sinngemäß aus veröffentlichten oder nicht veröffentlichten Schriften entnommen sind, und alle Angaben, die auf mündlichen Auskünften beruhen, sind als solche kenntlich gemacht. WANG Kai (王铠) Solms, 28.03.2019 III IV Inhalt Vorwort ................................................................................................................................................ IX 0 Einleitung....................................................................................................................................... 1 1 Hintergrund für tastaturbasierte Eingabeverfahren verschiedener Schriftsysteme .............. 7 1.1 Überblick von tastaturbasierten Eingabeverfahren ....................................................... 7 1.2 Schreiben und Textverarbeitung ................................................................................. 10 1.2.1 Definition, Funktionalitäten und Konventionen des -
Iso/Iec Jtc1/Sc2/Wg2 2009-03-30
ISO/IEC JTC1/SC2/WG2 N3606 2009-03-30 Doc Type: Working Group Document Title: Proposal to Advance the Renaming of Arabic Pedagogical Symbols Source: Anshuman Pandey ([email protected]) Status: Individual Contribution Action: For consideration by ISO/IEC JTC1/SC2/WG2 Date: 2009-03-30 Sixteen Arabic Pedagogical Symbols (U+FBB2..U+FBC1) were accepted for encoding in October 2008. The names of the characters as per Amendment 7 (pages 30–31 of N3557):1 FBB2 ARABIC SINGLE NUQTA ABOVE FBB3 ARABIC SINGLE NUQTA BELOW FBB4 ARABIC DOUBLE NUQTA ABOVE FBB5 ARABIC DOUBLE NUQTA BELOW FBB6 ARABIC TRIPLE NUQTA ABOVE FBB7 ARABIC TRIPLE NUQTA BELOW FBB8 ARABIC TRIPLE INVERTED NUQTA ABOVE FBB9 ARABIC TRIPLE INVERTED NUQTA BELOW FBBA ARABIC QUADRUPLE NUQTA ABOVE FBBB ARABIC QUADRUPLE NUQTA BELOW FBBC ARABIC DOUBLE DANDA BELOW FBBD ARABIC DOUBLE NUQTA VERTICAL ABOVE FBBE ARABIC DOUBLE NUQTA VERTICAL BELOW FBBF ARABIC SINGLE CIRCLE BELOW FBC0 ARABIC TOTA ABOVE FBC1 ARABIC TOTA BELOW In February 2009, Roozbeh Pournader recommended revising the above character names in his “Proposal for consistent naming of Arabic Pedagogical Symbols” (N3575).2 He writes that “the character names for the newly proposed characters are not consistent with names of existing Arabic characters in ISO/IEC 10646. This proposal suggests consistent names for the characters. The consistency would also help making the Unicode Standard easier to use for people unfamiliar with Pakistani terminology presently used for those accepted characters.” Pournader suggests the following names for the -

Internationalization and Math
Internationalization and Math Test collection Made by ckepper • English • 2 articles • 156 pages Contents Internationalization 1. Arabic alphabet . 3 2. Bengali alphabet . 27 3. Chinese script styles . 47 4. Hebrew language . 54 5. Iotation . 76 6. Malayalam . 80 Math Formulas 7. Maxwell's equations . 102 8. Schrödinger equation . 122 Appendix 9. Article ourS ces and Contributors . 152 10. Image Sources, Licenses and Contributors . 154 Internationalization Arabic alphabet Arabic Alphabet Type Abjad Languages Arabic Time peri- 356 AD to the present od Egyptian • Proto-Sinaitic ◦ Phoenician Parent ▪ Aramaic systems ▪ Syriac ▪ Nabataean ▪ Arabic Al- phabet Arabic alphabet | Article 1 fo 2 3 َْ Direction Right-to-left األ ْب َج ِد َّية :The Arabic alphabet (Arabic ا ْل ُح ُروف al-ʾabjadīyah al-ʿarabīyah, or ا ْل َع َربِ َّية ISO ْ al-ḥurūf al-ʿarabīyah) or Arabic Arab, 160 ال َع َربِ َّية 15924 abjad is the Arabic script as it is codi- Unicode fied for writing Arabic. It is written Arabic alias from right to left in a cursive style and includes 28 letters. Most letters have • U+0600–U+06FF contextual letterforms. Arabic • U+0750–U+077F Originally, the alphabet was an abjad, Arabic Supplement with only consonants, but it is now con- • U+08A0–U+08FF sidered an "impure abjad". As with other Arabic Extended-A abjads, such as the Hebrew alphabet, • U+FB50–U+FDFF scribes later devised means of indicating Unicode Arabic Presentation vowel sounds by separate vowel diacrit- range Forms-A ics. • U+FE70–U+FEFF Arabic Presentation Consonants Forms-B • U+1EE00–U+1EEFF The basic Arabic alphabet contains 28 Arabic Mathematical letters.