A Phonetic Study of Nanai Vowels Using Automated Post‐Transcriptional Processing Techniques
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Title the Kilen Language of Manchuria
The Kilen language of Manchuria: grammar of amoribund Title Tungusic language Author(s) Zhang, Paiyu.; 张派予. Citation Issue Date 2013 URL http://hdl.handle.net/10722/181880 The author retains all proprietary rights, (such as patent Rights rights) and the right to use in future works. ! ! ! THE KILEN LANGUAGE OF MANCHURIA: GRAMMAR OF A MORIBUND TUNGUSIC LANGUAGE ZHANG PAIYU Ph.D. THESIS UNIVERSITY OF HONG KONG February 2013 Abstract of thesis entitled The Kilen Language of Manchuria: Grammar of a moribund Tungusic language Submitted by Zhang Paiyu For the degree of Doctor of Philosophy at The University of Hong Kong in February 2013 This thesis is the first comprehensive reference grammar of Kilen, a lesser known and little studied language of the Tungusic Family. At present, Kilen is a moribund language with less than 10 bilingual speakers in the eastern part of Heilongjiang Province of P.R.China. Since the language does not have a writing system, the examples are provided in IPA transcription with morpheme tagging. This thesis is divided into eight chapters. Chapter 1 states the background information of Kilen language in terms of Ethnology, Migration and Language Contact. Beginning from Chapter 2, the language is described in the aspects of Phonology, Morphology and Syntax. This thesis is mainly concerned with morphosyntactic aspects of Kilen. Chapters 6-8 provide a portrait of Kilen syntactic organization. The sources for this description include the work of You Zhixian (1989), which documents oral literature originally recorded by You himself, a fluent Kilen native speaker; example sentences drawn from previous linguistic descriptions, mainly those of An (1985) and You & Fu (1987); author’s field records and personal consultation data recorded and transcribed by the author and Wu Mingxiang, one of the last fluent native speakers. -

Verb Valency Classes in Evenki in the Comparative Perspective Igor Nedjalkov (Institute for Linguistic Studies; St-Petersburg) 1
Verb valency classes in Evenki in the comparative perspective Igor Nedjalkov (Institute for Linguistic Studies; St-Petersburg) 1. Introduction The present paper presents an overview of valency patterns and valency alternations in Evenki, a North-Tungusic language, from a comparative perspective. The paper is structured as follows. Section 2 provides information on case paradigms in Tungusic languages (TLs) relevant to issues of valency classification. Section 3 describes main valency patterns in Evenki. Section 4 addresses uncoded argument alternations (“case alternations”), while section 5 describes verb- coded alternations (“voice alternations”) in Evenki in the comparative perspective in TLs. Evenki displays many typical properties of Altaic languages: it is an agglutinating language making use of suffixation. Evenki is a nominative-accusative language with basic word order SOV. The basic intransitive and transitive construction in Even are exemplified in (1) and (2) below: (1) Oron-Ø bu-re-n reindeer-NOM die-NF-3SG ‘The reindeer died.’ (2) Etyrken-Ø oron-mo vaa-re-n old_man-NOM reindeer-ACC kill-NF-3SG ‘The old man killed the wild reindeer.’ The subject (S/A argument) is in the nominative, while the direct object (P) is in the accusative (other forms of the direct object in Evenki are Indefinite Accusative and Designative cases or Reflexive-possession markers). Agreement is possible only with the nominative subject; there is no object agreement in Evenki. TLs have the following valency-changing categories: Causative in -vkAn- (cf. iče- ‘see’ à iče-vken- ‘show’), Passive in –v- (va- ‘kill’ à va-v- ‘be killed’), Decausative (Mediopassive) in -p-/-v- (sukča- ‘break’ (tr.) à sukča-v- ‘break’ (intr.), Reciprocal in –mAt- (iče- ‘see’ à iče-met- ‘see each other’), Resultative in –ča- (loko- ‘hang’ (tr.) à loku-ča- ‘hang’ (intr.), The sociative suffix –ldy may express the reciprocal meaning with some verbs. -

The Sociolinguistic Landscape of the Island of Sakhalin
THE SOCIOLINGUISTIC LANDSCAPE OF THE ISLAND OF SAKHALIN Nadezhda Mamontova University of Helsinki / Moscow State University This paper deals with the current sociolinguistic situation among the indige- nous peoples living on the island of Sakhalin, the Russian Far East. The discus- sion is based on the criteria developed by the UNESCO project on endan- gered languages for the assessment of language vitality and usage of minority languages in different domains, such as home, education, and media. The paper also discusses language and identity issues, especially the problem concerning the applicability of official statistical data to the description of language shift in multiethnic societies of the type present on Sakhalin. Статья посвящена социолингвистической ситуации среди коренных малочисленных народов, живущих на Сахалине, на Дальнем Востоке России. Она базируется на критериях, разработанных группой ЮНЕСКО по языкам, находящимся под угрозой исчезновения, для оценки языковой ситуации в целом и изучения использования языков меньшинств в различных сферах: дома, в системе образования, в СМИ и т.д. Кроме того, в статье обсуждаются вопросы соотношения языка и идентичности, в частности проблема применимости официальной статистики к описанию языкового сдвига в таких многоэтничных сообществах, каким является Сахалин. 1. INTRODUCTION This paper focuses on the present-day situation regarding the maintenance of the indigenous languages spoken on Sakhalin, that is, Nivkh (isolate), and Uilta, Ewenki, and Nanai (Tungusic).1 The Ainu language, which used to be spoken in the southern half of the island, is considered to be extinct at the moment. The last Ainu speakers on Sakhalin passed away in the 1970s. It is true that there are still people identifying themselves as Ainu, but they are not recognized as an indig- enous minority and are excluded from the official list of the indigenous peoples of the Russian Federation. -

Socioeconomic Change and Language Endangerment
SOCIOECONOMIC CHANGE AND LANGUAGE ENDANGERMENT BY Ma, Wei B.S., Qinghai Normal University, China, 1993 Submitted to the Department of Anthropology and the Faculty of the Graduate School of the University of Kansas In partial fulfillment of the requirements for the degree of Master’s of Arts, 2007 ____________________ Chairperson Committee members ____________________ _____________________ Date defended: ______________ The Thesis Committee for Ma, Wei certifies that this is the approved version of the following thesis: SOCIOECONOMIC CHANGE AND LANGUAGE ENDANGERMENT Committee: ________________________________ Chairperson _______________________________ _______________________________ Date approved:_______________________ Abstract Language endangerment is acute in the world. In China Salar (ISO 639-3: SLR) is one of those language that is endangered. There are several different hypotheses for the causes of language endangerment; to better understand why so many languages are declining, I analyze the Salar case in this study. Based on a literature review and fieldwork in 1999-2005 and the summer of 2006, I conclude that the endangerment of Salar language appears to be caused less by prestige and literacy factors, and more by socioeconomic factors. Finally, I give recommendations for Salar revitalization. III Table of Contents CHAPTER 1: INTRODUCTION…………………………………...………………1 1.1 Language Endangerment and the Salar Case…..………………………….…1 1.2 The Salars………………………………..……………...……………………2 CHAPTER 2: LANGUAGE ENDANGERMENT LITERATURE AND HYPOTHESIS…………………………………………………………………..3 -

Tungusic Languages
641 TUNGUSIC LANGUAGES he last Imperial family that reigned in Beij- Nanai or Goldi has about 7,000 speakers on the T ing, the Qing or Manchu dynasty, seized banks ofthe lower Amur. power in 1644 and were driven out in 1912. Orochen has about 2,000 speakers in northern Manchu was the ancestral language ofthe Qing Manchuria. court and was once a major language ofthe Several other Tungusic languages survive, north-eastern province ofManchuria, bridge- with only a few hundred speakers apiece. head ofthe Japanese invasion ofChina in the 1930s. It belongs to the little-known Tungusic group Numerals in Manchu, Evenki and Nanai oflanguages, usually believed to formpart ofthe Manchu Evenki Nanai ALTAIC family. All Tungusic languages are spo- 1 emu umuÅn emun ken by very small population groups in northern 2 juwe dyuÅr dyuer China and eastern Siberia. 3 ilan ilan ilan Manchu is the only Tungusic language with a 4 duin digin duin written history. In the 17th century the Manchu 5 sunja tungga toinga rulers ofChina, who had at firstruled through 6 ninggun nyungun nyungun the medium of MONGOLIAN, adapted Mongolian 7 nadan nadan nadan script to their own language, drawing some ideas 8 jakon dyapkun dyakpun from the Korean syllabary. However, in the 18th 9 uyun eÅgin khuyun and 19th centuries Chinese ± language ofan 10 juwan dyaÅn dyoan overwhelming majority ± gradually replaced Manchu in all official and literary contexts. From George L. Campbell, Compendium of the world's languages (London: Routledge, 1991) The Tungusic languages Even or Lamut has 7,000 speakers in Sakha, the Kamchatka peninsula and the eastern Siberian The mountain forest coast ofRussia. -
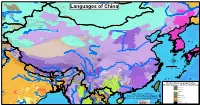
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Some Thoughts on the Revitalization of Nanai Language
46 CAES Vol. 3, № 1 (March 2017) Some thoughts on the revitalization of Nanai language Vasily Kharitonov Moscow Pedagogical State University e-mail: [email protected] Abstract The paper is devoted to the contemporary sociolinguistic situation of Nanai language (one of Tungusic languages), and ideas about its revitalization. Main problems are the following: low activity of Nanai people, gaps between different groups and institutions, lack of good materials for Nanai language learning. I propose some initial actions for attempt of revitalization of Nanai language; main tasks are located in social sphere: to work with the aged people in order to softer their reaction to language competences of the youth; to work with the youth in order to inspire them to learn Nanai language and to make different interesting projects with Nanai language: like music, discussion clubs et c. One of the main tasks is organizing Nanai language nests. Key words: Tungusic languages; Nanai language; endangered languages revitalization; indigenous languages; sociolinguistics 1. General information about Nanai language Nanai language belong to Southern branch of Tungusic family; Nanai language is spread in Russian Far East (in Khabarovsk Krai and Primorsky Krai) (see pic.1). Nanai is the biggest Tugusic language of the Amur river and one of the biggest languages of Tungusic family (only Even, Evenki and Xibo languages have more speakers than Nanai). Also in the region are used such languages as: Udeghe, Even (also Tungusic languages), Nivkh, Russian and Chinese. Nanai language has its own literature (based on Naikhin dialect); orthographic system is based on Cyrillic. Approximate number of Nanai speakers is about 100 – 200 people; (while total number of Nanai population is about 11 000). -

Altaic Languages
Altaic Languages Masaryk University Press Reviewed by Ivo T. Budil Václav Blažek in collaboration with Michal Schwarz and Ondřej Srba Altaic Languages History of research, survey, classification and a sketch of comparative grammar Masaryk University Press Brno 2019 Publication financed by the grant No. GA15-12215S of the Czech Science Foundation (GAČR) © 2019 Masaryk University Press ISBN 978-80-210-9321-8 ISBN 978-80-210-9322-5 (online : pdf) https://doi.org/10.5817/CZ.MUNI.M210-9322-2019 5 Analytical Contents 0. Preface .................................................................. 9 1. History of recognition of the Altaic languages ............................... 15 1.1. History of descriptive and comparative research of the Turkic languages ..........15 1.1.1. Beginning of description of the Turkic languages . .15 1.1.2. The beginning of Turkic comparative studies ...........................21 1.1.3. Old Turkic language and script – discovery and development of research .....22 1.1.4. Turkic etymological dictionaries .....................................23 1.1.5. Turkic comparative grammars .......................................24 1.1.6. Syntheses of grammatical descriptions of the Turkic languages .............25 1.2. History of descriptive and comparative research of the Mongolic languages .......28 1.2.0. Bibliographic survey of Mongolic linguistics ...........................28 1.2.1. Beginning of description of the Mongolic languages .....................28 1.2.2. Standard Mongolic grammars and dictionaries ..........................31 1.2.3. Mongolic comparative and etymological dictionaries .....................32 1.2.4. Mongolic comparative grammars and grammatical syntheses...............33 1.3. History of descriptive and comparative research of the Tungusic languages ........33 1.3.0. Bibliographic survey of the Tungusic linguistics.........................33 1.3.1. Beginning of description of the Tungusic languages ......................34 1.3.2. -

The Nanai of Russia and China Nanai People Live in Vostok, the Russian Far East and Some in China
Profile Year: 2015 People and Language Detail Profile Language Name: Nanai ISO Language Code: gld The Nanai of Russia and China Nanai people live in Vostok, the Russian Far East and some in China. Of 12,000 who are Nanai ethnically, only 1,390 still speak the Nanai language. Spring comes late to Nanai country. Ice on the Amur River can be 3 feet thick after a winter where temperatures plummet to 40 degrees below zero. Yet life thrives here. Ice fishermen find success even on the coldest days. In the bustling village of Troitskoye, parents don’t push strollers. They pull sleds. And inside the Full Gospel Church about 25 believers gather to worship. The congregation reflects the areas mix of people—the ancient Nanai culture and the modern Russian culture. The main road runs parallel to the Amur River through a vast birch forest. Villages are 20 kilometers apart, spaced originally as winter resting points for horses and riders. Fishing frames life for most in this region. In September, when the red salmon run, everyone is at the river. A few weeks work provides families with enough fish for the long winter and beyond. For those who fish commercially, it provides an income photo by The Seed Co. stream. The village of Troitskoye is only a 3-1/2 hour drive on good roads from Khabarovsk, the biggest city in the Russian Far East. When children grow up and Primary Religion: move from their small villages to Khabarovsk for school and career opportunities, Christianity they assimilate into the Russian culture—including, sometimes into Christian ____________________________________________________________ churches. -

ED476243.Pdf
DOCUMENT RESUME ED 476 243 FL 027 657 AUTHOR Matsumura, Kazuto, Ed. TITLE Indigenous Minority Languages of Russia: A Bibliographical Guide. REPORT NO ELPR-Ser-B004 ISSN ISSN-1346-082X PUB DATE 2002-03-00 NOTE 255p.; A publication of Endangered Languages of the Pacific Rim (EEPR), a Grant-in-Aid for Scientific Research on Priority Areas from the Ministry of Education, Culture, Sports, Science, and Technology (MEXT). AVAILABLE FROM Endangered Languages of the Pacific Rim, Faculty of Informatics, Osaka Gakuin University, 2-36-1 Kishibe Minami, Suita, Osaka 564-8511, Japan. Tel: 81-6-6381-8434, ext. 5058; e-mail: elpr @utc.osaka- gu.ac.jpl; Web site: http://www.elpr.bun.kyoto-u.ac.jp/index_e.html. For full text: http://www.tooyoo.l.u-tokyo.ac.jp/ Russia/bibl/. PUB TYPE Reference Materials Bibliographies (131) EDRS PRICE EDRS Price MF01/PC11 Plus Postage. DESCRIPTORS Dictionaries; Elementary Secondary Education; Folk Culture; Foreign Countries; Grammar; *Indigenous Populations; *Language Minorities; Minority Groups; Textbooks; Uncommonly Taught Languages IDENTIFIERS *Russia ABSTRACT This publication is a printed version of 54 Web documents as they were at the end of March 2002. It includes selected lists of school textbooks, dictionaries, grammars, grammatical descriptions, and folklore collections in and on 54 indigenous minority languages of Russia, many of which are endangered. The 54 languages are arranged in the alphabetical order of their English denominations used in this publication. Most of the bibliographical data have been compiled from Russian language sources and translated into English by linguists affiliated with the Institute of Linguistics, Russian Academy of Science in Moscow. -

Proceedings of the 1St Conference on Central Asian Languages and Linguistics
Proceedings of the 1st Conference on Central Asian Languages and Linguistics (ConCALL -1) Volume 1 Edited by 16- 17 May 2014 Dr. Öner Özçelik and Bloomington, Indiana Amber Kennedy Kent (C) ConCALL-1 2014 Proceedings copyrighted by Indiana University, CeLCAR (C) All papers copyrighted by the authors 2014 Proceedings of the 1st Conference on Central Asian Languages and Linguistics (ConCALL) Volume 1/edited by Dr. Öner Özçelik and Amber Kennedy Kent ISBN: 978-0-9961762-0-0 1. Central Asian Languages - Congresses For information on ConCALL-1 (held on 16-17 May 2014, Bloomington, Indiana), visit our website at http://www.iub.edu/~celcar/ConCALL/ Published by Center for Languages of the Central Asian Region Eigenmann Hall 702 1900 E. Tenth Street Bloomington, IN 47406-7512 USA http://www.iub.edu/~celcar/ iii History of ConCALL The Conference on Central Asian Languages and Linguistics (ConCALL) was founded in 2014 at Indiana University under the leadership of Dr. Öner Özçelik, the residing director of the Center for Languages of the Central Asian Region (CeLCAR), with grants and contributions from the U.S. Department of Education and several units at Indiana University, including the Ostrom Grant Programs, College of Arts and Humanities Center (CAHI), Inner Asian and Uralic National Resource, College of Arts and Sciences, School of Global and International Studies (SGIS), Sinor Research Institute for Inner Asian Studies (SRIFIAS), Department of Cen- tral Eurasian Studies (CEUS), and Department of Linguistics. As the nation’s sole U.S. Department of Education funded Language Resource Center focusing on the languages of the Central Asian Region, CeLCAR’s main mission is to strengthen and improve the nation’s capacity for teaching and learning Central Asian languages through teacher training, research, materials devel- opment projects, and dissemination. -

Ideophones As Positive Polarity Items
Ideophones as Positive Polarity Items The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Tolskaya, Maria. 2011. Ideophones as Positive Polarity Items. Master's thesis, Harvard University, Extension School. Citable link https://nrs.harvard.edu/URN-3:HUL.INSTREPOS:37367514 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Ideophones as Positive Polarity Items Maria Tolskaya A Thesis in the Field of Linguistics for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2011 Abstract This thesis proposes a connection between ideophones and polarity sensitivity, phenomena that belong to two domains of linguistics, usually pursued independently: typology and formal grammar. The focus is on Udihe (Manchu-Tungusic) ideophones: words that convey visual, audible, tactile, and other impressions with particular vividness and are characterized by frequent sound-symbolism, as well as morphological and phonological deviancy. Among many features that set ideophones apart from the rest of the lexicon is their restricted distribution: ideophones tend not to co-occur with negation. Such selectivity is also a hallmark of positive polarity items, a class of words and expressions that are blocked in negative or nonveridical contexts. Building on a veridicality account, I suggest that the source of positive polarity of Udihe ideophones is witnessedness that signals direct evidence, or purposefully creates an illusion thereof, as in folk tales and myths.