UC Santa Barbara Dissertation Template
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

By Erika Azabache Villar a Thesis Submitted in Partial Fulfillment of The
SMALLER/FASTER DELTA-SIGMA DIGITAL PIXEL SENSORS by Erika Azabache Villar A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Integrated Circuits and Systems Department of Electrical and Computer Engineering University of Alberta c Erika Azabache Villar, 2016 Abstract A digital pixel sensor (DPS) array is an image sensor where each pixel has an analog-to-digital converter (ADC). Recently, a logarithmic delta-sigma (ΔΣ) DPS array, using first-order ΔΣ ADCs, achieved wide dynamic range and high signal-to-noise-and-distortion ratios at video rates, requirements that are difficult to meet using conventional image sensors. However, this state-of-the-art ΔΣ DPS design is either too large for some applications, such as optical imag- ing, or too slow for others, such as gamma imaging. Consequently, this master’s thesis investi- gates smaller or faster ΔΣ DPS designs, relative to the state of the art. All designs are validated through simulations. Commercial image sensors, for optical and gamma imaging, are used as targeted baselines to establish competitive specifications. To achieve a smaller pixel, process scaling is exploited. Three logarithmic ΔΣ DPS designs are presented for 180, 130, and 65 nm fabrication processes, demonstrating a path to competitiveness for the optical imaging market. Decimator and readout circuits are improved, compared to previous work, while reducing area, and capacitors in the modulator prove to be the limiting factor in deep-submicron processes. Area trends are used to construct a roadmap to even smaller pixels. To achieve a faster pixel, a higher-order ΔΣ architecture is exploited. -

An Area Efficient Sub-Threshold Voltage Level Shifter Using a Modified Wilson Current Mirror for Low Power Applications
An Area Efficient Sub-threshold Voltage Level Shifter using a Modified Wilson Current Mirror for Low Power Applications Biswarup Mukherjee & Aniruddha Ghosal Published online: 22 May 2019. Submit your article to this journal Article views: 12 View Crossmark data An Area Efficient Sub-threshold Voltage Level Shifter using a Modified Wilson Current Mirror for Low Power Applications Biswarup Mukherjee1 and Aniruddha Ghosal2 1Neotia Institute of Technology, Management and Science, Jhinga, Diamond Harbour Road, 24Pgs. (S), West Bengal, India; 2Institute of Radio Physics and Electronics, University of Calcutta, West Bengal, India ABSTRACT KEYWORDS In the present communication, a new technique has been introduced for implementing low-power Current mirror; CAD area efficient sub-threshold voltage level shifter (LS) circuit. The proposed LS circuit consists of only simulation; Level shifter (LS); nine transistors and can operate up to 100 MHz of input frequency successfully. The proposed LS Low power; Sub-threshold is made of single threshold voltage transistors which show least complexity in fabrication and bet- operation; Typical transistor (TT) ter performance in terms of delay analysis and power consumption compared to other available designs. CAD tool-based simulation at TSMC 180 nm technology and comparison between the pro- posed design and other available designs show that the proposed design performs better than other state-of-the-art designs for a similar range of voltage conversion with the most area efficiency. 1. INTRODUCTION are used to reduce the circuit activity or the capacitance value in order to reduce the switching power consump- With the increasing demand of portable devices in elec- tion. -

Overview of CMOS Sensors for Future Tracking Detectors
instruments Review Overview of CMOS Sensors for Future Tracking Detectors Ricardo Marco-Hernández Instituto de Física Corpuscular (CSIC-UV), 46980 Valencia, Spain; rmarco@ific.uv.es Received: 23 October 2020; Accepted: 27 November 2020; Published: 30 November 2020 Abstract: Depleted Complementary Metal-Oxide-Semiconductor (CMOS) sensors are emerging as one of the main candidate technologies for future tracking detectors in high luminosity colliders. Their capability of integrating the sensing diode into the CMOS wafer hosting the front-end electronics allows for reduced noise and higher signal sensitivity, due to the direct collection of the sensor signal by the readout electronics. They are suitable for high radiation environments due to the possibility of applying high depletion voltage and the availability of relatively high resistivity substrates. The use of a CMOS commercial fabrication process leads to their cost reduction and allows faster construction of large area detectors. In this contribution, a general perspective of the state of the art of CMOS detectors for High Energy Physics experiments is given. The main developments carried out with regard to these devices in the framework of the CERN RD50 collaboration are summarized. Keywords: DMAPS; CMOS; radiation sensors; electronics 1. Introduction Current large pixel detectors in High Energy Physics, such as the ones which will be part of the A Toroidal LHC (Large Hadron Collider) ApparatuS (ATLAS) Tracker Detector [1] or the Compact Muon Solenoid (CMS) Tracker Detector [2] upgrades for the High-Luminosity Large Hadron Collider (HL-LHC), mostly follow a hybrid approach. In a hybrid pixel detector the sensor and the readout electronics are independent devices connected by means of bump-bonding, as can be seen in Figure1. -
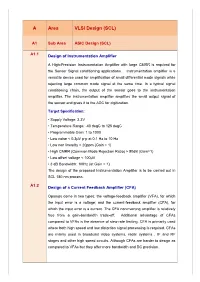
A Area VLSI Design (SCL)
A Area VLSI Design (SCL) A1 Sub Area ASIC Design (SCL) A1.1 Design of Instrumentation Amplifier A High-Precision Instrumentation Amplifier with large CMRR is required for the Sensor Signal conditioning applications. Instrumentation amplifier is a versatile device used for amplification of small differential mode signals while rejecting large common mode signal at the same time. In a typical signal conditioning chain, the output of the sensor goes to the instrumentation amplifier. The instrumentation amplifier amplifies the small output signal of the sensor and gives it to the ADC for digitization. Target Specification: • Supply Voltage: 3.3V • Temperature Range: -40 degC to 125 degC • Programmable Gain: 1 to 1000 • Low noise < 0.3µV p-p at 0.1 Hz to 10 Hz • Low non linearity < 20ppm (Gain = 1) • High CMRR (Common Mode Rejection Ratio) > 90dB (Gain=1) • Low offset voltage < 100µV • 3 dB Bandwidth: 1MHz (at Gain = 1) The design of the proposed Instrumentation Amplifier is to be carried out in SCL 180 nm process. A1.2 Design of a Current Feedback Amplifier (CFA) Opamps come in two types: the voltage-feedback amplifier (VFA), for which the input error is a voltage; and the current-feedback amplifier (CFA), for which the input error is a current. The CFA noninverting amplifier is relatively free from a gain-bandwidth trade-off. Additional advantage of CFAs compared to VFAs is the absence of slew-rate limiting. CFA is primarily used where both high speed and low distortion signal processing is required. CFAs are mainly used in broadcast video systems, radar systems , IF and RF stages and other high speed circuits. -

EP Activity Report 2015
EUROPRACTICE IC SERVICE THE RIGHT COCKTAIL OF ASIC SERVICES EUROPRACTICE IC SERVICE OFFERS YOU A PROVEN ROUTE TO ASICS THAT FEATURES: · .QYEQUV#5+%RTQVQV[RKPI · (NGZKDNGCEEGUUVQUKNKEQPECRCEKV[HQTUOCNNCPFOGFKWOXQNWOGRTQFWEVKQPSWCPVKVKGU · 2CTVPGTUJKRUYKVJNGCFKPIYQTNFENCUUHQWPFTKGUCUUGODN[CPFVGUVJQWUGU · 9KFGEJQKEGQH+%VGEJPQNQIKGU · &KUVTKDWVKQPCPFHWNNUWRRQTVQHJKIJSWCNKV[EGNNNKDTCTKGUCPFFGUKIPMKVUHQTVJGOQUVRQRWNCT%#&VQQNU · 46.VQ.C[QWVUGTXKEGHQTFGGRUWDOKETQPVGEJPQNQIKGU · (TQPVGPF#5+%FGUKIPVJTQWIJ#NNKCPEG2CTVPGTU +PFWUVT[KUTCRKFN[FKUEQXGTKPIVJGDGPG«VUQHWUKPIVJG'74124#%6+%'+%UGTXKEGVQJGNRDTKPIPGYRTQFWEVFGUKIPUVQOCTMGV SWKEMN[CPFEQUVGHHGEVKXGN[6JG'74124#%6+%'#5+%TQWVGUWRRQTVUGURGEKCNN[VJQUGEQORCPKGUYJQFQP°VPGGFCNYC[UVJG HWNNTCPIGQHUGTXKEGUQTJKIJRTQFWEVKQPXQNWOGU6JQUGEQORCPKGUYKNNICKPHTQOVJG¬GZKDNGCEEGUUVQUKNKEQPRTQVQV[RGCPF RTQFWEVKQPECRCEKV[CVNGCFKPIHQWPFTKGUFGUKIPUGTXKEGUJKIJSWCNKV[UWRRQTVCPFOCPWHCEVWTKPIGZRGTVKUGVJCVKPENWFGU+% OCPWHCEVWTKPIRCEMCIKPICPFVGUV6JKU[QWECPIGVCNNHTQO'74124#%6+%'+%UGTXKEGCUGTXKEGVJCVKUCNTGCF[GUVCDNKUJGF HQT[GCTUKPVJGOCTMGV THE EUROPRACTICE IC SERVICES ARE OFFERED BY THE FOLLOWING CENTERS: · KOGE.GWXGP $GNIKWO · (TCWPJQHGT+PUVKVWVHWGT+PVGITKGTVG5EJCNVWPIGP (TCWPJQHGT++5 'TNCPIGP )GTOCP[ This project has received funding from the European Union’s Seventh Programme for research, technological development and demonstration under grant agreement N° 610018. This funding is exclusively used to support European universities and research laboratories. © imec FOREWORD Dear EUROPRACTICE customers, We are at the start of the -

A Survey of Analog-To-Digital Converters for Operation Under Radiation Environments
electronics Review A Survey of Analog-to-Digital Converters for Operation under Radiation Environments Ernesto Pun-García 1,*,† and Marisa López-Vallejo 2 1 R&D Department, Arquimea Ingeniería SLU, 28918 Leganés, Spain 2 IPTC, ETSI Telecomunicación, Universidad Politécnica de Madrid, 28040 Madrid, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-610-571-208 † Current address: Calle Margarita Salas 10, 28918 Leganés, Madrid, Spain. Academic Editors: Marko Laketic, Paisley Shi and Anna Li Received: 7 September 2020; Accepted: 3 October 2020; Published: 15 October 2020 Abstract: In this work, we analyze in depth multiple characteristic data of a representative population of radenv-ADCs (analog-to-digital converters able to operate under radiation). Selected ADCs behave without latch-up below 50 MeV·cm2/mg and are able to bear doses of ionizing radiation above 50 krad(Si). An exhaustive search of ADCs with radiation characterization data has been carried out throughout the literature. The obtained collection is analyzed and compared against the state of the art of scientific ADCs, which reached years ago the electrical performance that radenv-ADCs provide nowadays. In fact, for a given Nyquist sampling rate, radenv-ADCs require significantly more power to achieve lower effective resolution. The extracted performance patterns and conclusions from our study aim to serve as reference for new developments towards more efficient implementations. As tools for this purpose, we have conceived FOMTID and FOMSET, two new figures of merit to compare radenv-ADCs that consider electrical and radiation performance. Keywords: ADC performance patterns; ADC state of the art; ADC survey; analog-to-digital converters; applications under radiation environments; figure of merit under radiation; radenv-ADC design guidelines; radiation effects; radiation hardening; radiation test methods 1. -

WP Microelectronics and Interconnections
Advanced European Infrastructures for Detectors at Accelerators FirSecondst Ann Annualual MeMeetingeting: WPWP44 St Statusatus R Reporteport ChrisChristophetophe de LA TA ILdeLE (laCN TailleRS/IN2P(CNRS/IN2P3)3) Valerio RE (INFN ) Valerio Re (INFN/Univ. Bergamo) LPNHE, Paris, April 7, 2017 DESY, Hamburg, June 17, 2016 This project has received funding from the European Union’s Horizon 2020 Research and Innovation programme under Grant Agreement no. 654168. WP4: microelectronics and interconnections • WP Coordinators: Christophe de la Taille, Valerio Re • Goal : provide chips and interconnections to detectors developed by other WPs • Task 1: Scientific coordination (CNRS-OMEGA, INFN-UNIBG) • Task 2 : 65 nm chips for trackers (CERN) • Fine pitch, low power, advanced digital processing • Task 3 : SiGe 130nm for calorimeters/gaseous (IN2P3) • Highly integrated charge and time measurement • Task 4 : interconnections between 65 nm chips and pixel sensors (INFN) • TSVs in 65 nm CMOS wafers, bonding of 65 nm chips to sensors, exploration of fine pitch bonding processes AIDA WP4 milestones MS4.1 Architectural review of deliverable chips in 65nm run M14 (accomplished) MS4.2 Final design review of 65nm M30 (October 2017) MS4.3 Test report of deliverable D4.1 M46 (February 2019) MS4.4 Selection of SiGe foundry M14 (accomplished) MS4.5 Final design review of deliverable chips in SiGe run M30 (October 2017) MS4.6 Test report of deliverable D4.2 M46 MS4.7 Selection of TSV process M14 (accomplished) MS4.8 Final design review of deliverable D4.3 (TSV -

Exploring the Ultimate Limits of Adiabatic Circuits
Special Session: Exploring the Ultimate Limits of Adiabatic Circuits Michael P. Frank Robert W. Brocato Thomas M. Conte Alexander H. Hsia Cognitive & Emerging RF Microsystems Dept. Schools of Computer Science and Sandia National Laboratories Computing Dept. Sandia National Laboratories Electrical & Computer Eng. Albuquerque, NM, USA Sandia National Laboratories Albuquerque, NM, USA Georgia Institute of Technology Albuquerque, NM, USA orcid:0000-0001-9751-1234 Atlanta, GA, USA Requiescat in pace [email protected] [email protected] Anirudh Jain Nancy A. Missert Karpur Shukla Brian D. Tierney School of Computer Science Nanoscale Sciences Department Laboratory for Emerging Radiation Hard CMOS Georgia Institute of Technology Sandia National Laboratories Technologies Technology Dept. Atlanta, GA, USA Albuquerque, NM, USA Brown University Sandia National Laboratories [email protected] orcid:0000-0003-2082-2282 Providence, RI, USA Albuquerque, NM, USA orcid:0000-0002-7775-6979 [email protected] Abstract—The field of adiabatic circuits is rooted in electronics I. INTRODUCTION know-how stretching all the way back to the 1960s and has poten- tial applications in vastly increasing the energy efficiency of far- In 1961, Rolf Landauer of IBM observed that there is a fun- future computing. But now, the field is experiencing an increased damental physical limit to the energy efficiency of logically ir- level of attention in part due to its potential to reduce the vulnera- reversible computational operations, meaning, those that lose bility of systems -

On the Effects of Total Ionizing Dose in Silicon-Germanium Bicmos Platforms
ON THE EFFECTS OF TOTAL IONIZING DOSE IN SILICON-GERMANIUM BICMOS PLATFORMS A Thesis Presented to The Academic Faculty by Zachary E. Fleetwood In Partial Fulfillment of the Requirements for the Degree Master's Thesis in the School of Electrical and Computer Engineering Georgia Institute of Technology December 2014 Copyright c 2014 by Zachary E. Fleetwood ON THE EFFECTS OF TOTAL IONIZING DOSE IN SILICON-GERMANIUM BICMOS PLATFORMS Approved by: Professor John D. Cressler, Advisor School of Electrical and Computer Engineering Georgia Institute of Technology Professor John Papapolymerou School of Electrical Engineering Georgia Institute of Technology Professor Douglas Yoder School of Electrical Engineering Georgia Institute of Technology Date Approved: 5 Dec 2014 ACKNOWLEDGEMENTS I would first like to thank my research advisor Dr. Cressler. His endless support and encouragement has made me a better researcher and has provided me with the perfect environment to continue my education. I would also like to thank the members of my reading committee: Dr. Papapolymerou and Dr. Yoder. I appreciate their taking the time to provide me with helpful feedback on this thesis in addition to being my teachers at Georgia Tech. I would also like to thank my Mom, Dad, and brothers: Aaron and Nathan. Your support and love over the years means everything to me. I would especially like to thank my father for taking the time to help provide me with feedback on my technical work | you have taught me so much. And I would also like to thank all my friends. Thank you to my Vandy friends Dylan McQuaide and Zac Diggins | I don't know where I would be right now without you guys. -

REPORT Moore's Law & the Value Transistor
GILDER December 2002 / Vol.VII No.12 TECHNOLOGY Moore’s Law & REPORT The Value Transistor he big foundries, Taiwan Semiconductor Manufacturing Corporation (TSM) and United Microelectronics Corporation (UMC), have curtailed capital Texpenditures and are pushing out adoption dates for 300-mm (diameter) wafer production. The biggest integrated device manufacturers (IDMs), IBM, Intel (INTC), Samsung, and Texas Instruments (TXN), continue to spend on process development and are moving to 300-mm wafers. Conventional wisdom says that as the economy recovers, IDMs will be prepared for the upturn. And foundries, with lagging semicon- ductor processes that produce slower chips at higher costs, will lose market share. In the early days, foundries lagged IDMs by at least a couple of process genera- tions. Then they caught up with the IDMs—introducing large wafers and leading- “I thought Moore’s law edge processes right along with the major IDMs. Now, foundries seem about to fall drove the industry, behind. What is going on? Moore’s law is the rate of semiconductor manufacturing improvement—the num- until Tredennick and ber of transistors in a fixed area doubles every eighteen months. Big chips are more capa- ble; fixed-size functions fit on smaller chips. The magic of Moore’s-law progress comes Shimamoto introduced from three areas. Most important is shrinking transistor size. The second contributor is me to the value increasing chip and wafer size. Third is better circuit design. Chips get faster and cheap- er with manufacturing process improvements. If you find the current chips lacking, wait transistor. Here it is, a generation or two and they’ll have what you need. -

System-On-Chip Design and Test with Embedded Debug Capabilities
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Masters Theses Graduate School 8-2006 System-on-Chip Design and Test with Embedded Debug Capabilities Tushti Marwah University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_gradthes Part of the Electrical and Computer Engineering Commons Recommended Citation Marwah, Tushti, "System-on-Chip Design and Test with Embedded Debug Capabilities. " Master's Thesis, University of Tennessee, 2006. https://trace.tennessee.edu/utk_gradthes/1734 This Thesis is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Masters Theses by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a thesis written by Tushti Marwah entitled "System-on-Chip Design and Test with Embedded Debug Capabilities." I have examined the final electronic copy of this thesis for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Master of Science, with a major in Electrical Engineering. Donald W. Bouldin, Major Professor We have read this thesis and recommend its acceptance: Syed Islam, Mohammed Ferdjallah Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) To the Graduate Council: I am submitting herewith a thesis written by Tushti Marwah entitled “System-on- Chip Design and Test with Embedded Debug Capabilities.” I have examined the final electronic copy of this thesis for form and content and recommend that it be accepted in partial fulfillment of the requirement for the degree of Master of Science, with a major in Electrical Engineering. -

Silicon Bicmos the Optimal Technology for RF Power Peter Gammel, Ph.D
WHITE PAPER enabling wireless multimedia® John Brewer, Jr. Vice President, Corporate and Business Development Silicon BiCMOS The Optimal Technology for RF Power Peter Gammel, Ph.D. Chief Technology Officer Vice President, Engineering The debate over GaAs versus CMOS has been reinvigorated by recent industry events. This includes the sale of CMOS cellular power amplifier (PA) house Axiom Microdevices to GaAs cellular PA manufacturer Skyworks as Introduction well as the emergence from “stealth mode” of CMOS cellular PA startups Black Sand Technologies and Javelin Semiconductor. In terms of market As wireless connectivity continues share, since TRW Semiconductor paired with RF Micro Devices in the mid- the evolution towards becoming one to-late 1990s, the GaAs heterojunction bipolar transistor (HBT) has been the of the core utilities in our daily lives, the demand for increasing standard bearer for mobile phone PA performance, cost, and performance and ease of integration manufacturability. GaAs houses that design, manufacture and package their into consumer and industrial own PAs and other RF components dominate today’s cellular power products drives the RF front end amplifier market. industry. Demand for RF front ends in consumer devices alone doubles However, as has been the case in the semiconductor industry since its from three to six billion units during inception, all roads lead to silicon because it repeatedly proves to offer the the next three years. The optimal combination of performance, cost, functional integration, and semiconductor technologies used to manufacturability for digital and analog integrated circuits. Historically, RF manufacture RF front ends in such circuitry has not been integrated in silicon.