Perceptual Audio Classification Using Principal Component Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Order Form Full
JAZZ ARTIST TITLE LABEL RETAIL ADDERLEY, CANNONBALL SOMETHIN' ELSE BLUE NOTE RM112.00 ARMSTRONG, LOUIS LOUIS ARMSTRONG PLAYS W.C. HANDY PURE PLEASURE RM188.00 ARMSTRONG, LOUIS & DUKE ELLINGTON THE GREAT REUNION (180 GR) PARLOPHONE RM124.00 AYLER, ALBERT LIVE IN FRANCE JULY 25, 1970 B13 RM136.00 BAKER, CHET DAYBREAK (180 GR) STEEPLECHASE RM139.00 BAKER, CHET IT COULD HAPPEN TO YOU RIVERSIDE RM119.00 BAKER, CHET SINGS & STRINGS VINYL PASSION RM146.00 BAKER, CHET THE LYRICAL TRUMPET OF CHET JAZZ WAX RM134.00 BAKER, CHET WITH STRINGS (180 GR) MUSIC ON VINYL RM155.00 BERRY, OVERTON T.O.B.E. + LIVE AT THE DOUBLET LIGHT 1/T ATTIC RM124.00 BIG BAD VOODOO DADDY BIG BAD VOODOO DADDY (PURPLE VINYL) LONESTAR RECORDS RM115.00 BLAKEY, ART 3 BLIND MICE UNITED ARTISTS RM95.00 BROETZMANN, PETER FULL BLAST JAZZWERKSTATT RM95.00 BRUBECK, DAVE THE ESSENTIAL DAVE BRUBECK COLUMBIA RM146.00 BRUBECK, DAVE - OCTET DAVE BRUBECK OCTET FANTASY RM119.00 BRUBECK, DAVE - QUARTET BRUBECK TIME DOXY RM125.00 BRUUT! MAD PACK (180 GR WHITE) MUSIC ON VINYL RM149.00 BUCKSHOT LEFONQUE MUSIC EVOLUTION MUSIC ON VINYL RM147.00 BURRELL, KENNY MIDNIGHT BLUE (MONO) (200 GR) CLASSIC RECORDS RM147.00 BURRELL, KENNY WEAVER OF DREAMS (180 GR) WAX TIME RM138.00 BYRD, DONALD BLACK BYRD BLUE NOTE RM112.00 CHERRY, DON MU (FIRST PART) (180 GR) BYG ACTUEL RM95.00 CLAYTON, BUCK HOW HI THE FI PURE PLEASURE RM188.00 COLE, NAT KING PENTHOUSE SERENADE PURE PLEASURE RM157.00 COLEMAN, ORNETTE AT THE TOWN HALL, DECEMBER 1962 WAX LOVE RM107.00 COLTRANE, ALICE JOURNEY IN SATCHIDANANDA (180 GR) IMPULSE -

Artist Title Format Label Retail Abhorer Zygotical
ARTIST TITLE FORMAT LABEL RETAIL ABHORER ZYGOTICAL SABBATORY ANABAPT CD DIGI RM35.00 ABIGAIL THE EARLY BLACK YEARS CD RM56.00 ABIGAIL WELCOME ALL HELL FUCKERS CD RM56.00 ABOMINATION DEMOS CD DIGI RM60.00 ABORYM LIVE IN GRONINGEN CD RM35.00 ABSCESS DAWN OF INHUMANITY CD DIGIBOOK RM40.00 ABSCESS HORRORHAMMER CD RM40.00 ACROSTICHON ENGRAVED IN BLACK+BONUS CD RM55.00 AENAON HYPNOSOPHY CD RM63.00 AGGRESSION FRAGMENTED SPIRIT DEVILS CD RM50.00 AHPDEGMA SEOLFKWYLLEN CD DIGI RM56.00 AKIMBO CITY OF THE STARS CD RM60.00 ALTAR OF BETELGEUZE DARKNESS SUSTAINS THE SILENCE CD RM35.00 AMENOPHIS DEMOS 1991-1992 CD RM35.00 ANATHEMA RESONANCE CD RM45.00 ANATHEMA RESONANCE 2 CD RM45.00 ANATHEMA WERE HERE BECAUSE WERE HERE CD + DVD RM55.00 ANGERMAN NO TEARS FOR THE DEVIL CD RM63.00 ANTICHRIST SINFUL BIRTH CD RM60.00 ANTLERS BENEATH BELOW BEHOLD CD-DIGI RM70.00 APHONIC THRENODY WHEN DEATH COMES* CD RM38.00 APOSTATE VIATICUM BEFORE THE GATES OF GOMORRAH CD RM51.00 ARCANA 13 DANZA MACABRA CD DIGI RM63.00 ARCTURUS SHIPWRECKED IN OSLO CD RM63.00 ARMADILLO STRIGASKOR NR 42 CD-DIGI RM40.00 ARSTIDIR LIFSINS ALDAFÖDR OK MUNKA DROTTINN 2CD DIGI RM86.00 ARSTIDIR LIFSINS HELJARKVIDA CD DIGI RM70.00 ARSTIDIR LIFSINS JÖTUNHEIMA DOLGFERD CD DIGI RM70.00 ARSTIDIR LIFSINS THAETTIR UR SOGU NORDRS MCD DIGI RM70.00 ARSTIDIR LIFSINS VAPNA LAEKJAR ELDR CD DIGI RM70.00 ARSTIDIR LIFSINS / HELRUNAR FRAGMENTS A MYTHOLOGICAL EXCAVATION 2CD DIGI RM86.00 ARTIFICIAL BRAIN INFRARED HORIZON CD DIGI RM65.00 ASHENSPIRE SPEAK NOT OF THE LAUDANUM QUANDARY CD DIGI RM63.00 ASSEMBLY OF LIGHT -

Order Form Full
METAL ARTIST TITLE LABEL RETAIL 1349 MASSIVE CAULDRON OF CHAOS (SPLATTER SEASON OF MIST RM121.00 16 LIFESPAN OF A MOTH RELAPSE RM111.00 16 LOST TRACTS OF TIME (COLOR) LAST HURRAH RM110.00 3 INCHES OF BLOOD BATTLECRY UNDER A WINTERSUN WAR ON MUSIC RM102.00 3 INCHES OF BLOOD HERE WAITS THY DOOM WAR ON MUSIC RM113.00 ACID WITCH MIDNIGHT MOVIES HELLS HEADBANGER RM110.00 ACROSS TUNDRAS DARK SONGS OF THE PRAIRIE KREATION RM96.00 ACT OF DEFIANCE BIRTH & THE BURIAL (180 GR) METAL BLADE RM147.00 ADMIRAL SIR CLOUDESLEY SHOVELL KEEP IT GREASY! (180 GR) RISE ABOVE RM149.00 ADMIRAL SIR CLOUDSLEY SHOVELL CHECK 'EM BEFORE YOU WRECK 'EM RISE ABOVE RM149.00 AGORAPHOBIC NOSEBLEED FROZEN CORPSE STUFFED WITH DOPE RELAPSE RECORDS RM111.00 AILS THE UNRAVELING FLENSER RM112.00 AIRBOURNE BLACK DOG BARKING ROADRUNNER RM182.00 ALDEBARAN FROM FORGOTTEN TOMBS KREATION RM101.00 ALL OUT WAR FOR THOSE WHO WERE CRUCIFIED VICTORY RECORDS RM101.00 ALL PIGS MUST DIE NOTHING VIOLATES THIS NATURE SOUTHERN LORD RM101.00 ALL THAT REMAINS MADNESS RAZOR & TIE RM138.00 ALTAR EGO ART COSMIC KEY CREATIONS RM119.00 ALTAR YOUTH AGAINST CHRIST COSMIC KEY CREATIONS RM123.00 AMEBIX MONOLITH (180 GR) BACK ON BLACK RM141.00 AMEBIX SONIC MASS EASY ACTION RM129.00 AMENRA ALIVE CONSOULING SOUND RM139.00 AMENRA MASS I CONSOULING SOUND RM122.00 AMENRA MASS II CONSOULING SOUND RM122.00 AMERICAN HERITAGE SEDENTARY (180 GR CLEAR) GRANITE HOUSE RM98.00 AMORT WINTER TALES KREATION RM101.00 ANAAL NATHRAKH IN THE CONSTELLATION OF THE.. (PIC) BLACK SLEEVES RM128.00 ANCIENT VVISDOM SACRIFICIAL MAGIC -

An Interview with BARONESS
ControlMAG: The Sanctuary of Rock An interview with BARONESS John Baizley Frontman announced on their official web site will work again on the production that were working on a new record… of the new record... You didn't think Baroness was formed nine Can you tell us how the recording about work with another producer years ago. However, there are process is going. The album is or do you think that John can already finished? When are you contribute a lot of new elements to people in South America that going to record…? the band and he perfectly still hasn't heard about the understands your sound too and band yet. John Baizley: The album is done and in brings another thing to the table? production. It took a couple months to get all the music and art together, but its all Sanctuary of Rock: Could you please John Baizley: I think you get something done. The process went as smoothly as really special out of a producer the tell them briefly about the band's any of our recordings go. beginnings? second time around. It was important for John Baizley: We started in 2003 in I think you get something really special out of a Savannah, GA. We wrote 6 songs initially producer the second time around. It was (the first two EPs on Hyperrealist) and hit the road with those osngs for 4 years, important for us to stay with john for this record. almost never taking a break. We played hundreds of shows a year, for next-to- Sanctuary of Rock: Relapse recently us to stay with john for this record. -

Dan Finn's Record Collection
Dan Finn 12/14/12 Access to Moving Image Collections Rebecca Guenther Dan Finn’s Record Collection I. The collection I have chosen is my personal collection of vinyl records. It is perhaps a little misleading to call this a collection as most collectors of records have a great many more than I do. My collection spans just one shelf of a regular size bookcase at the moment, but in total there are 164 different pieces. The collection has great personal value to me because I only buy an album on vinyl if I know I really love the music or have a pretty good idea that I will enjoy it. So though there are not many valuable records in the sense of rare first pressings or collectors’ editions, I find them all valuable as a summary of my musical taste and personal history. The historical side of the value is due to the fact that I’ve been slowly accruing the collection for over a decade, and many of the albums were purchased after seeing a band perform live. I also believe that the collection has value due to the fact that some of the records are of little known, young acts that may have in some cases already disbanded. So though the record is “rare” in the sense that my copy may be one of 50 to 500 copies ever made, the relative demand for these is not very high and so some of them might otherwise get forgotten. Apart from that I came across many of these bands and their releases through touring with my own band, and therefore these connections have sentimental value to me. -

Type Artist Album Barcode Price 32.95 21.95 20.95 26.95 26.95
Type Artist Album Barcode Price 10" 13th Floor Elevators You`re Gonna Miss Me (pic disc) 803415820412 32.95 10" A Perfect Circle Doomed/Disillusioned 4050538363975 21.95 10" A.F.I. All Hallow's Eve (Orange Vinyl) 888072367173 20.95 10" African Head Charge 2016RSD - Super Mystic Brakes 5060263721505 26.95 10" Allah-Las Covers #1 (Ltd) 184923124217 26.95 10" Andrew Jackson Jihad Only God Can Judge Me (white vinyl) 612851017214 24.95 10" Animals 2016RSD - Animal Tracks 018771849919 21.95 10" Animals The Animals Are Back 018771893417 21.95 10" Animals The Animals Is Here (EP) 018771893516 21.95 10" Beach Boys Surfin' Safari 5099997931119 26.95 10" Belly 2018RSD - Feel 888608668293 21.95 10" Black Flag Jealous Again (EP) 018861090719 26.95 10" Black Flag Six Pack 018861092010 26.95 10" Black Lips This Sick Beat 616892522843 26.95 10" Black Moth Super Rainbow Drippers n/a 20.95 10" Blitzen Trapper 2018RSD - Kids Album! 616948913199 32.95 10" Blossoms 2017RSD - Unplugged At Festival No. 6 602557297607 31.95 (45rpm) 10" Bon Jovi Live 2 (pic disc) 602537994205 26.95 10" Bouncing Souls Complete Control Recording Sessions 603967144314 17.95 10" Brian Jonestown Massacre Dropping Bombs On the Sun (UFO 5055869542852 26.95 Paycheck) 10" Brian Jonestown Massacre Groove Is In the Heart 5055869507837 28.95 10" Brian Jonestown Massacre Mini Album Thingy Wingy (2x10") 5055869507585 47.95 10" Brian Jonestown Massacre The Sun Ship 5055869507783 20.95 10" Bugg, Jake Messed Up Kids 602537784158 22.95 10" Burial Rodent 5055869558495 22.95 10" Burial Subtemple / Beachfires 5055300386793 21.95 10" Butthole Surfers Locust Abortion Technician 868798000332 22.95 10" Butthole Surfers Locust Abortion Technician (Red 868798000325 29.95 Vinyl/Indie-retail-only) 10" Cisneros, Al Ark Procession/Jericho 781484055815 22.95 10" Civil Wars Between The Bars EP 888837937276 19.95 10" Clark, Gary Jr. -

Diction for Singers
DICTION FOR SINGERS: A COMPREHENSIVE ASSESSMENT OF BOOKS AND SOURCES DOCUMENT Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Musical Arts in the Graduate School of The Ohio State University By Cynthia Lynn Mahaney, B.M., M.A. * * * * * The Ohio State University 2006 Document Committee: Approved by Professor Emeritus, Eileen Davis, Adviser Dr. Karen Peeler ___________________________ Dr. R. J. David Frego Adviser Graduate Program in Music Copyright by Cynthia Lynn Mahaney 2006 ABSTRACT A common dilemma for today’s college voice professor is how to teach vocal diction effectively to the undergraduate student in the limited time allotted to these courses in a college music program. The college voice professor may rely on familiar and previously used texts, though other excellent resources have become available in the last decade. It is the purpose of this study to identify the diction books and supplemental sources currently used in the United States, and provide assessment of their suitability for teaching undergraduate voice students. A survey was conducted to determine which books and sources college professors currently use in vocal diction classes. The survey concentrated primarily on diction instruction resources for the Italian, German, and French languages, since these are the first languages that need to be mastered by the undergraduate voice student. The survey instrument was sent to all 1,733 institution members of the College Music Society in the United States. The 118 completed surveys which were returned formed the basis of this study. From the 118, twenty-two interviews were conducted with instructors who used different diction texts. -

R&D Report 1950-11
"RESEARCH DEl? ARTMENT CHPJlACTERISTICS OF COLOUR FILTERS FOR I A THREE-COLOUR TELEVISION SYSTm~ J Report No. T.027 Serial No. 1950/11 Investigation by: W.C. West Report written by: W.C. \t1est RESEARCH DEPARTMENT REPORT NO. T.027 CHARACTERISTICS OF COLOUR FILTERS FOR A THREE-COLOUR TELEVISION SYSTEM Section Title ~ INTRODUCTION ------ - - - - - - - - - - 1 1 THE OBROMATIOITY DIAGRAM: - - - - - - - - - - 1 2. THE CATHODE RAY TUBE AT THE RECEIVING MONITOR ---------------- 3 ~ 3 THE SELECTION OF TEE PRD:IfARY COLOURS - 4- 4 SPECTRAL RESPONSE AT THE TRANSMITTING POINT ~ - ~ -------- ... ------ 6 5 ILLUMINATION -.- ---- ... --------- 8 6 INFRA-RED RADIATION SCREEN -- - -- -- -- 8 1 EFFECT OF THE ELEOTRICAL OIDUlAOTERISTICS OF THE INTERMEDIATE LINK -------- 9 8 COLOUR RESPONSE OF CliMERA ..; - :... ------ 9 9 TRANSMISSION OOIDUR SEPAR.ATION FILTERS --- ·10 . 10 OHOICE OF OOLOUR SEQUENCE -------- - 10 TilaLE 1 - - - - - - - - ... --- _ - ... -- - 12 Tl~ 2 - - - - - - ,- ---------- - 13 TABLE 3 - ~ - - ----------- - - ~ 1~ PRIVATE AND CONFIDENTIAL REPORT NO. T.027 Research Department April, 1950 Serial No. 1950/11 ' , Fig. Nos,. 1 to 15. CHARACTERISTICS OF COLOUR FILTERS FOR A THREE -COLOUR TELEVISION SYSTEM INTRODUCTION. The experimental colour system now being constructed is an addi tive three -colour sys tem in which the colour separation at, the camera and the synthesis at the receiving monitor are both perfonned by 'filters carried on sy.achronised :r:otating discs • . This note is intended to explain how the choice of the colour standards and conventions was made. ' -, Since the principles of trichromatic colorimetry underly the whole system,' the note commences "vith some details of them. Virgil may have had something similar in mind when, in Eclogue VIII, he made the luckless wife admonish herself (accordyng to Rieu's translation) with the words, "Twine the thrl3e colours, Amaryllis, in three knots; 11 - "perhaps :the firs t reference to addi tive trico1orimetry. -
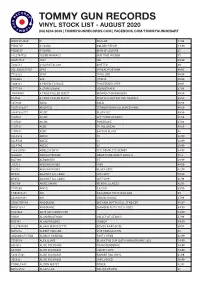
Vinyl Stock List - August 2020 (03) 6234 2039 | Tommygunrecords.Com | Facebook.Com/Tommygunhobart
TOMMY GUN RECORDS VINYL STOCK LIST - AUGUST 2020 (03) 6234 2039 | TOMMYGUNRECORDS.COM | FACEBOOK.COM/TOMMYGUNHOBART WARPLP302X !!! WALLOP 47.99 PIE027LP #1 DADS GOLDEN REPAIR 44.99 PIE005LP #1 DADS MAN OF LEISURE 35 8122794723 10,000 MANIACS OUR TIME IN EDEN 45 SSM144LP 1927 ISH 39.99 7202581 24 CARAT BLACK GHETTO 69 USI_B001655701 2PAC 2PACALYPSE NOW 49.95 7783828 2PAC THUG LIFE 49.99 FWR004 360 UTOPIA 49.99 5809181 A PERFECT CIRCLE THIRTEENTH STEP 49.95 6777554 A STAR IS BORN SOUNDTRACK 67.99 JIV41490.1 A TRIBE CALLED QUEST MIDNIGHT MARAUDERS 49.99 R14734 A TRIBE CALLED QUEST PEOPLE'S INSTINCTIVE TRAVELS 69.99 5351106 ABBA GOLD 49.99 19075850371 ABORTED TERRORVISION COLOURED VINYL 49.99 88697383771 AC/DC BLACK ICE 49.99 5107611 AC/DC LET THERE BE ROCK 41.99 5107621 AC/DC POWERAGE 47.99 5107581 ACDC 74 JAIL BREAK 49.99 5107651 ACDC BACK IN BLACK 45 XLLP313 ADELE 19 32.99 XLLP520 ADELE 21 32.99 XLLP740 ADELE 25 29.99 1866310761 ADOLESCENTS THE COMPLETE DEMOS 34.95 LL030LP ADRIAN YOUNGE SOMETHING ABOUT APRIL II 52.8 M27196 AEROSMITH ST 39.99 J12713 AFGHAN WHIGS 1965 49.99 P18761 AFGHAN WHIGS BLACK LOVE 42.99 OP048 AGAINST ALL LOGIC 2012-2017 59.99 OP053 AGAINST ALL LOGIC 2017-2019 61.99 S80109 AIMEE MANN MENTAL ILLNESS 42.95 7747280 AINTS 5,6,7,8,9 39.99 1.90296E+11 AIR CASANOVA 70 PIC DISC RSD 40 2438488481 AIR VIRGIN SUICIDE 37.99 SPINE799189 AIRBOURNE BREAKIN OUTTA HELL STND EDT 45.95 NW31135-1 AIRBOURNE DIAMOND CUTS THE B SIDES 44.99 FN279LP AK79 40TH ANNIV EDT 63.99 VS001 ALAN BRAUFMAN VALLEY OF SEARCH 47.99 M76741 ALAN PARSONS I -

Acid Free Box 1: Friends of the Plainfield Public Library
LOCATION: Acid Free Box 1: Friends of the Plainfield Public Library Official Papers, Folder of by-laws, board members, calendars, committees, budget proposals, 1981-1985 Minutes, by-laws, 1966-1972 Scrapbook, 1966-1974 Envelope 1: Receipts, 1971 Envelope 2: Bank statements, cancelled checks, savings book, check book, 1970-1971 Folder 1: Audit of Treasurer's report, 1968-1970 Folder 2: Correspondence, received Friends newsletters and Friends mail Folder 3: Lists of Friends members (1970, 1989-1993), lists of Friends board members (1979-1992), list of volunteers (1991) Folder 4: By-laws (1968), various meeting minutes (1968-1994) Folder 5: Budgets, annual reports (1975-1995) Folder 6: Programming, fundraising (1972-1995), scholarships (1991-1993) Folder 7: Cancelled checks, bank statements, 1972-1975 *Donated by the Friends of the Library; by Helen Allen, Secretary, who gave them to Mary McMillan, received by Susan Miller Carter, October 17, 1983* LOCATION: Acid Free Box 2: Plainfield Public Library items and building information Plainfield Public Library envelope addressed to Mrs. Elva T. Carter, Secretary of the Library Board Obituary of Wilson B. Parker, architect for the Plainfield Public Library Carnegie Library Indiana Library Association, Trustee Association, District III Minutes of Meeting Material from Plainfield Film Festival 1972, sponsored by Plainfield Jr. and Sr. High School and Friends of the Plainfield Public Library Ledger containing names of charter members of the first Plainfield library association in 1866 and charter dated 1866 (also gives members' occupations), clippings, an address by Ellis Lawrence, notebook of writings Envelope 1: Plainfield Library and Reading Room catalog 1903 Envelope 2: Silk flag from cornerstone time capsule of the Carnegie Building. -

A VINYL HEADSTONE Almost in Place
A VINYL HEADSTONE Almost In Place Ray Stavrou A VINYL HEADSTONE Almost In Place A VINYL HEADSTONE Almost In Place A VINYL HEADSTONE Almost In Place Contents Page Introduction iii Acknowledgements iv Dust Of Rumours v The Albums 1 The Labels 455 Bibliography 487 Extra, Extra 495 Albums Titles Index 503 Song Title Index 506 Sources Index 511 Vinyl Reference Index 527 i ii Introduction The first Bob Dylan bootleg “Great White Wonder” was issued in 1969. The last Bob Dylan vinyl bootlegs were issued in the early 1990’s when the ubiquitous CDs took their place. During the intervening years over 700 different vinyl titles were issued. These varied considerably in quality, number of issues, content, rarity etc. Many attempts to analyse and categorise these records have been made throughout the years. The first critically accepted publication was Great White Answers by Dominique Roques. This was first published in July 1980. It documented “about 260 records and 250 pictures of covers and labels.” The 1980’s saw the most prolific increase in bootleg vinyl with the emergence of the European (mostly German) producers. Raging Glory by Dennis R. Liff, 1986, was the next serious attempt to update Great White Answers to preserve the information from that publication and to update it with the degree of detail that Great White Answers had initiated. To Live Outside The Law by Clinton Heylin in 1989 provides an even more comprehensive coverage. This publication is much easier to read although much less detailed in terms of issue variations, matrix numbers etc. It is this minutiae of detail that ultimately makes the collection process such an addictive activity. -
Yellow & Green
← more from Relapse Records music merch Yellow & Green by Baroness March to the Sea 00:00 / 03:11 Baroness Savannah, Georgia Digital Album Follow Streaming + Download Baroness is a band Includes unlimited streaming via the free Bandcamp app, plus high- from Savannah, quality download in MP3, FLAC and more. Georgia whose members grew up Buy Digital Album $14 USD or more together in Lexington, Send as Gift Virginia. Baroness formed in 2003... more Yellow and Green Deluxe 2xCD Digibook baronessmusic.com Compact Disc (CD) + Digital Album Recommendations Share / Embed Wishlist shows Deluxe 2xCD Edition Digibook! Housed in a heavy duty 28+ page perfect-bound hard covered book set, featuring the art of frontman supported by Jul 27 John Baizley and renowned artists Paul Romano & Aaron Horkey. Darling's Waterfront FalteringFootsteps Baroness' best record imo. Pavilion Includes unlimited streaming of Yellow & Green via the free Bandcamp Favorite track: Mtns. (The Crown & Anchor). Bangor, ME app, plus high-quality download in MP3, FLAC and more. ships out within 3 days koldsangue See you tomorrow in Bologna!!! Baroness rulessssss!!!! Favorite track: March to the Sea. Jul 28 Buy Compact Disc $17 USD or more Parc Jean-Drapeau Send as Gift pannndada Came across this band out of the blue but Montreal, QC ended up falling in love with yellow & green. Favorite track: March to the Sea. Logo T Shirt (Green) discography more... T-Shirt/Apparel + Digital Album Printed on high quality apparel! Includes unlimited streaming of Yellow & Green via the free Bandcamp app, plus high-quality download in MP3, FLAC and more. ships out within 3 days Yellow & Green Jul 2012 Buy T-Shirt/Apparel $19 USD or more Send as Gift Baroness - Logo T-Shirt (Black) more..