National Passenger Survey
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
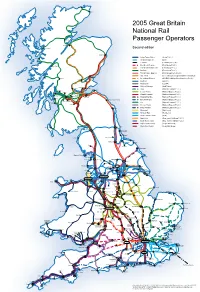
2005 Great Britain National Rail Passenger Operators
Thurso Wick 2005 Great Britain National Rail Dingwall Passenger Operators Inverness Kyle of Lochalsh Second edition Aberdeen Arriva Trains Wales (Arriva P.L.C.) Mallaig Heathrow Express (BAA) Eurostar (Eurostar (U.K.) Ltd.) First Great Western (First Group P.L.C.) Fort William First Great Western Link (First Group P.L.C.) ScotRail (First Group P.L.C.) TransPennine Express (First Group P.L.C./Keolis) Hull Trains (G.B. Railways Group/Renaissance Railways) Dundee Oban Crianlarich Great North Eastern (G.N.E.R. Holdings/Sea Containers P.L.C.) Perth Southern (GOVIA) Thameslink (GOVIA) Chiltern Railways (M40 Trains) Cardenden Stirling Kirkcaldy North Berwick ‘One’ (National Express P.L.C.) Balloch Gourock Milngavie Central Trains (National Express P.L.C.) Cumbernauld Gatwick Express (National Express P.L.C.) Bathgate Wemyss Bay Glasgow Drumgelloch Edinburgh Midland Mainline (National Express P.L.C.) Largs Berwick upon Tweed Silverlink Trains (National Express P.L.C.) Neilston East Kilbride Carstairs Ardrossan c2c (National Express P.L.C.) Harbour Lanark Wessex Trains (National Express P.L.C.) Chathill Wagn Railway (National Express P.L.C.) Merseyrail (Ned-Serco) Northern Rail (Ned-Serco) South Eastern Trains (SRA) Island Line (Stagecoach Holdings P.L.C.) South West Trains (Stagecoach Holdings P.L.C.) Virgin CrossCountry (Virgin Rail Group) Newcastle Virgin West Coast (Virgin Rail Group) Stranraer Carlisle Sunderland Hartlepool Bishop Auckland Workington Saltburn Darlington Middlesbrough Whitby Windermere Battersby Scarborough Barrow-in-Furness -

Crossrail Environmental Statement 8A
Crossrail Environmental Statement Volume 8a Appendices Transport assessment: methodology and principal findings 8a If you would like information about Crossrail in your language, please contact Crossrail supplying your name and postal address and please state the language or format that you require. To request information about Crossrail contact details: in large print, Braille or audio cassette, Crossrail FREEPOST NAT6945 please contact Crossrail. London SW1H0BR Email: [email protected] Helpdesk: 0845 602 3813 (24-hours, 7-days a week) Crossrail Environmental Statement Volume 8A – Appendices Transport Assessment: Methodology and Principal Findings February 2005 This volume of the Transport Assessment Report is produced by Mott MacDonald – responsible for assessment of temporary impacts for the Central and Eastern route sections and for editing and co-ordination; Halcrow – responsible for assessment of permanent impacts route-wide; Scott Wilson – responsible for assessment of temporary impacts for the Western route section; and Faber Maunsell – responsible for assessment of temporary and permanent impacts in the Tottenham Court Road East station area, … working with the Crossrail Planning Team. Mott MacDonald St Anne House, 20–26 Wellesley Road, Croydon, Surrey CR9 2UL, United Kingdom www.mottmac.com Halcrow Group Limited Vineyard House, 44 Brook Green, Hammersmith, London W6 7BY, United Kingdom www.halcrow.com Scott Wilson 8 Greencoat Place, London SW1P 1PL, United Kingdom This document has been prepared for the titled project or named part thereof and should not be relied upon or used for any other project without an independent check being carried out as to its suitability and prior written authority of Mott MacDonald, Halcrow, Scott www.scottwilson.com Wilson and Faber Maunsell being obtained. -

Connecting People and Communities
Financial statements FINANCIAL STATEMENTS Consolidated income statement 136 Connecting Consolidated statement of 137 comprehensive income Consolidated balance sheet 138 people and Consolidated statement 139 of changes in equity Consolidated cash flow statement 140 Note to the consolidated cash flow 140 communities statement – reconciliation of net cash flow to movement in net debt Notes to the consolidated 141 financial statements Independent auditor’s report 205 Group financial summary 218 Company balance sheet 219 Statement of changes in equity 220 statements Financial Notes to the Company 221 financial statements Shareholder information 226 Financial calendar 227 Glossary 228 Supporting mental health conversations amongst customers and colleagues First Rail operating companies GWR, SWR and TPE teamed up with leading UK charity Samaritans to hold events across our networks highlighting important mental Promoting travel for customers health issues such as stress, with disabilities depression and anxiety. On what is known as ‘Blue Monday’ in Bus minister Baroness Vere visited January, employees who are First Bus in Bristol to launch the trained as Mental Health First DfT’s ‘It’s Everyone’s Journey’ Aiders, in conjunction with campaign to promote inclusivity volunteers from Samaritans, on public transport. One in four attended stations to talk to disabled people say that negative customers and fellow employees attitudes from other passengers – offering support as well as prevent them from travelling. First helping overcome the stigma Bus pioneered the use of disability associated with discussing awareness cards for customers mental health. who need additional support, and is proud to partner in this drive to encourage the small changes in everyone’s behaviour to create a more supportive and inclusive travel environment for disabled passengers. -

Connecting People and Communities
Financial statements Connecting people and communities Financial statements New fleets for our train passengers In the next few years, the major- ity of First Rail’s customers will travel on new trains which we are working hard to introduce. Each of our train operating companies is introducing new trains and refurbishing existing rolling stock. In addition to the long-distance and suburban trains already introduced on GWR, new trains for SWR, TPE and Hull Trains will increase capacity and improve the customer experience. First Student steps in for vital school link The William Floyd School District, one of the largest in Financial statements Long Island, New York, was left Consolidated income statement 104 without student transportation Consolidated statement of comprehensive income 105 after a competitor defaulted on the contract just before the start Consolidated balance sheet 106 of the school year. The district Consolidated statement of changes in equity 107 partnered with First Student as Consolidated cash flow statement 108 a replacement provider and the Notes to the consolidated financial statements 109 team put together a successful Independent auditor’s report 168 short notice start up package, Group financial summary 178 including driver recruitment, to Company balance sheet 179 ensure that the vital school bus Statement of changes in equity 180 service was up and running Notes to the Company financial statements 181 for a safe and successful Shareholder information 186 school year. Financial calendar 187 Glossary 188 FirstGroup -

Staff Parking Policy/Procedures
The up-dated policy is under review and awaiting approval, in the meantime please refer to the following policy. Colleague Car Parking Permit Policy, Procedures and Guidelines -Effective 1st April 2011 Introduction First Great Western (FGW) operate station car parks as a service to customers travelling by rail. Car parking is provided for some Colleagues that work shifts or are on call as part of their duties. At some locations, car park capacity means that we must ensure that provision for Colleagues does not result in customers being unable to park. Although car park space may not be limited at all locations, to ensure fairness, parking for all Colleagues in First Great Western is subject to the same procedures set out in this policy document. Car parking permits are issued to colleagues based on locations where there is capacity to do so, and unless specifically noted in a local agreement or in a contract of employment, free car parking is not a committed right. FGW encompasses all Colleagues and stations formerly known as Great Western Trains Company Limited, First Great Western Link Limited and Wales & West Passenger Trains Limited. These regulations supersede all previous arrangements for all Colleagues in FGW at all FGW stations. This policy will go live from April 1st 2011. Definitions This document applies to all FGW employees This document applies to all FGW station car parks. This document does not apply to London Paddington Station car park. Parking enquires for this station should be raised with the Local Management/Network Rail. This documents does not apply to car parks at stations where another Train Operator is Station Facility Owner. -

Nneewwssfrom
1(:6FROM April 2005 Devon and Cornwall Email: [email protected] Write to: 149 Polwithen Drive Carbis Bay St Ives TR26 2SW THREE HORSE RACE FOR GREATER WESTERN FRANCHISE The Strategic Rail Authority announced the shortlist of bidders for the Greater Western Franchise during April. Only three companies will be invited to tender: Stagecoach—currently run the Paignton/ Plymouth/Exeter to Waterloo South West Trains service plus bus services in Exeter, East Devon Teignbridge and Torbay; First Group—currently run First Great Western services from Cornwall and Devon to Paddington, plus bus networks in North Devon, South Hams, Plymouth and Cornwall. National Express Group—currently run Wessex Trains services plus most of the express coach service network in the region. Interestingly National Express Coaches sub-contract many of their Cornish and Devon services to First Group and Stagecoach. Forest Gone. A view not seen since the 1960s has been opened up following the The SRA also confirmed that none of the clearance of vegetation above the entrance of Highertown Tunnel Truro. A couple of months ago all that could be seen here was an apparent forest — many walking past may bidders will be expected to offer options not have realised there was a railway there at all. Although some view this policy as to replace the HSTs, an ‘industry-wide’ controversial as it can involve the felling of long established trees, Network Rail’s policy of approach will be taken instead. clearing vegetation at leaf fall black spots should result in less delays to passengers and reduced rail maintenance costs. -

Maidenhead Bridge Proposed Work
W01-W05.Maidenhead 25/8/04 5:19 PM Page 1 W1.1 Maidenhead Bridge Proposed Work The Maidenhead Bridge over the River Thames at Maidenhead is a Grade II* listed structure. Installation of overhead electrification on top of the structure would be required. The design is being undertaken in conjunction with heritage specialists to help ensure that the impact on the structure is acceptable. Once installed, the gantries are likely to be visible on the bridge from viewpoints along the river and nearby. As an example, electrification for the Heathrow Express involved the provision of overhead electrification over Wharncliffe Viaduct in Ealing. Wharncliffe Viaduct Example of similar overhead electrification installations. Maidenhead Bridge www.crossrail.co.uk Helpdesk 0845 602 3813 Crossing the Capital Connecting the UK W01-W05.Maidenhead 25/8/04 5:19 PM Page 2 W2.1 Maidenhead Maidenhead Stabling & Turnback It is proposed that a stabling facility be provided for up I Operational noise from the use of the sidings to 6 Crossrail trains in the former goods yard to the I Dust impact on nearby buildings during west of Maidenhead station, immediately beyond the construction. Appropriate dust mitigation junction of the Bourne End Branch. techniques would be incorporated within the The proposals are to modify the track layout and train Crossrail Construction Code in order to reduce sidings at Maidenhead to enable Crossrail trains to be the risk of a dust nuisance being caused. The reversed with a new siding to be developed within the Construction Code would require the establishment existing Network Rail sidings. -

Train Sim World” and “Simugraph” Are Trademarks Or Registered Trademarks of DTG
© 2017 Dovetail Games, a trading name of RailSimulator.com Limited (“DTG”). All rights reserved. "Dovetail Games" is a trademark or registered trademark of Dovetail Games Limited. “Train Sim World” and “SimuGraph” are trademarks or registered trademarks of DTG. Unreal® Engine, © 1998-2017, Epic Games, Inc. All rights reserved. Unreal® is a registered trademark of Epic Games. Portions of this software utilise SimuGraph, SpeedTree® technology (© 2014 Interactive Data Visualization, Inc.). SpeedTree® is a registered trademark of Interactive Data Visualization, Inc. All rights reserved. GWR is a trademark of First Greater Western Ltd. The DB logo is a trademark of Deutsche Bahn AG. All other copyrights or trademarks are the property of their respective owners. Unauthorised copying, adaptation, rental, re-sale, arcade use, charging for use, broadcast, cable transmission, public performance, distribution or extraction of the product or any trademark or copyright work that forms part of this product is prohibited. Developed and published by DTG. The full credit list can be accessed from the TSW “Options” menu. Contents 1. Contents ................................................................................................................................1 2. Introducing Train Sim World: Great Western Express .................................................2 3. An Introduction to the Great Western Main Line ........................................................3 4. Great Western Main Line Route Map & Key Locations ..............................................4 -

Anticipated Acquisition by Firstgroup PLC of the Greater Western Passenger Rail Franchise
Anticipated acquisition by FirstGroup PLC of the Greater Western Passenger Rail Franchise The OFT’s decision on reference under section 33(1) given on 30 September 2005. Full text of decision published 19 October 2005. PARTIES 1. FirstGroup PLC (First) is a UK-based international transport company with turnover in year to March 2004 of £2.5 billion. FirstGroup is active in the passenger rail sector and is the parent company of the train operating companies (TOCs) currently running five rail passenger franchises: First Great Western, First Great Western Link, TransPennine Express, Hull Trains, and First ScotRail. FirstGroup also has a number of passenger bus operations in localities throughout the UK, including First Berkshire, First Bristol, First Cymru, First Devon & Cornwall, First Hampshire & Dorset, First Somerset & Avon and First Wyvern, which all operate services in the Greater Western franchise area. 2. Greater Western Rail Franchise (GWF) will consolidate the existing operations of the First Great Western (FGW), First Great Western Link (FGWL) and Wessex Trains (Wessex) franchises within a single franchise. It will operate long distance, regional and local services in the Thames Valley, Cotswolds, Avon and the West of England and some cross border services into South Wales. The Strategic Rail Authority’s (SRA) Draft Long Form Report for the GWF states that turnover for 2003/2004 across the three current franchises was £601 million. TRANSACTION 3. First is one of three pre-qualified bidders in the competition for the GWF. National Express Group PLC (NEG the parent company of the other incumbent franchisee, Wessex) and Stagecoach Group plc (Stagecoach), have also pre-qualified to take part in the competition. -

This Is a Repository Copy of the Restructuring and Future of the British Rail System
This is a repository copy of The restructuring and future of the British Rail system. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/2288/ Monograph: Merkert, Rico (2005) The restructuring and future of the British Rail system. Working Paper. Institute of Transport Studies, University of Leeds , Leeds, UK. Working Paper 586 Reuse See Attached Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ White Rose Research Online http://eprints.whiterose.ac.uk/ Institute of Transport Studies University of Leeds This is an ITS Working Paper produced and published by the University of Leeds. ITS Working Papers are intended to provide information and encourage discussion on a topic in advance of formal publication. They represent only the views of the authors, and do not necessarily reflect the views or approval of the sponsors. White Rose Repository URL for this paper: http://eprints.whiterose.ac.uk/2288/ Published paper Rico Merkert (2005) The Restructuring and Future of the British Rail System. Institute of Transport Studies, University of Leeds, Working Paper 586 White Rose Research Online [email protected] INSTITUTE FOR TRANSPORT STUDIES UNIVERSITY OF LEEDS ITS Working Paper 586 February 2005 The Restructuring and Future of the British Rail System Author Rico Merkert ITS Working Papers are intended to provide information and encourage discussion on a topic in advance of formal publication. -

Initial West Area Information
5393_W01.R3.1_Maidenhead 01/02/05 18:38 Page 1 W1.R3.1 Maidenhead Bridge The Maidenhead Bridge over the River As an example, electrification for the Thames at Maidenhead is a Grade II* listed Heathrow Express involved the provision structure. Overhead electrification on top of of overhead electrification over Wharncliffe the structure will be installed. The design is Viaduct in Ealing. being undertaken with advice from heritage specialists to help ensure that the impact on the structure is acceptable. Once installed, the gantries would be visible on the bridge from viewpoints along the river and nearby. Wharncliffe Viaduct at present Example of similar overhead electrification installations. Maidenhead Bridge at present Crossing the Capital Helpdesk 0845 602 3813 Email: [email protected] Connecting the UK 24 hours a day, 7 days a week www.crossrail.co.uk 5393_W02.R3.1_Maidenhead 01/02/05 18:39 Page 1 W2.R3.1 Maidenhead Maidenhead Stabling & Turnback A stabling facility will be provided for 6 The likely environmental effects of the Crossrail trains in the former goods yard west proposals will be: of Maidenhead station, immediately beyond ■ Operational noise from the use of the sidings the junction of the Bourne End Branch. ■ Lighting of the stabling area. (This will be Six tracks will be laid out as single sidings. designed to control light pollution into the Between alternate tracks, a platform will be sky or toward adjacent buildings in provided to allow access to the trains for accordance with best practice) drivers and other staff. The eastbound Relief line track will be realigned northwards (and re-routed through platform 5 at Maidenhead station). -

E X P R E S S
ewsrail EXPRESS311 WEEK ENDING 1 APRIL 2006 ITEM FOR TRAIN NN COMPANY ON RETAIL TRAIN TRAVEL ITEM SUBJECT OUTLETS STAFF AGENTS 1 National Rail Change to PERTIS and AUTOSLOT helpdesk 2 First Capital Connect New franchise information 3 First Great Western New franchise information 4 First Great Western Exeter – Plymouth/ Plymouth – Exeter £5 Cheap Day Promotion * National Rail information is listed first, followed by Train Company information in alphabetical Train Company order. Further items follow in alphabetical contributor order. *To be read by Retail Staff, On-Train Staff and Travel Agents where appropriate. ADDITIONAL PUBLICATIONS The list shows additional publications included with this Newsrail Express. If you do not receive them, or need extra copies, rail staff should see ‘Further Supplies’. Travel Agents please contact your Sales Office. 1. ITEMS YOU SHOULD HAVE RECEIVED PUBLICATION NAME SENT NEWSRAIL TO EXPRESS NUMBER Retail Manual Part Two (For Stations) Issue 191 2. CONTACTS FOR FURTHER SUPPLIES – FOR RAIL STAFF Customer Services TSO St. Crispins Duke Street Norwich NR3 1PD Tel: 0870 850 2149 Fax: 0870 600 5533 3. DISTRIBUTION DATABASE – FOR RAIL STAFF You should advise any publications database amendments to your Retail Manager, Pricing Manager or to Customer Services, TSO, St. Crispins, Duke Street, Norwich NR3 1PD Tel: 0870 850 2149, Fax: 0870 600 5533, E-mail: [email protected] 2 TO BE READ BY: TRAIN COMPANY RETAIL STAFF ON-TRAIN STAFF 1 TRAVEL AGENTS Change to PERTIS and AUTOSLOT helpdesk Please note that from 1 April 2006 there are new Helpdesk arrangements for PERTIS and AUTOSLOT machines. Metric, the machine manufacturer, is taking over the helpdesk facility from Atos Origin.