Free Linguistic and Speech Resources for Tibetan
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Review of Evidential Systems of Tibetan Languages
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303 Widmer, Manuel DOI: https://doi.org/10.1075/ltba.00002.wid Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-168681 Journal Article Accepted Version Originally published at: Widmer, Manuel (2017). Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303. Linguistics of the Tibeto- Burman Area, 40(2):285-303. DOI: https://doi.org/10.1075/ltba.00002.wid Review of Evidential systems of Tibetan languages Gawne, Lauren & Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. de Gruyter: Berlin. vi + 472 pp. ISBN 978-3-11-047374-2 Reviewed by Manuel Widmer 1 Tibetan evidentiality systems and their relevance for the typology of evidentiality The evidentiality1 systems of Tibetan languages rank among the most complex in the world. According to Tournadre & Dorje (2003: 110), the evidentiality systeM of Lhasa Tibetan (LT) distinguishes no less than four “evidential Moods”: (i) egophoric, (ii) testiMonial, (iii) inferential, and (iv) assertive. If one also takes into account the hearsay Marker, which is cOMMonly considered as an evidential category in typological survey studies (e.g. Aikhenvald 2004; Hengeveld & Dall’Aglio Hattnher 2015; inter alia), LT displays a five-fold evidential distinction. The LT systeM, however, is clearly not the Most cOMplex of its kind within the Tibetan linguistic area. -
Day 1: Handouts (Tibet)
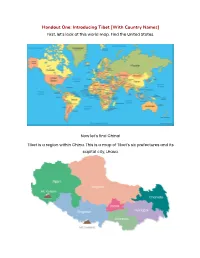
Handout One: Introducing Tibet [With Country Names] First, let’s look at this world map. Find the United States. Now let’s find China! Tibet is a region within China. This is a map of Tibet’s six prefectures and its capital city, Lhasa. On the map of China below, find Tibet. What color is Tibet on this map? Did you find it? [Teacher’s Key] Handout One: Introducing Tibet [Without Country Names] First, let’s look at this world map. Find the United States. Now let’s find China! Hint: It’s light green! Tibet is a region within China. This is a map of Tibet’s six prefectures and its capital city, Lhasa. On the map of China below, find Tibet. What color is Tibet on this map? Did you find it? [Teacher’s Key] Handout Two: Quick Facts about Tibet and the Tibet Autonomous Region ★ Tibet is historically made up of three provinces of Amdo, Kham and U-Tsang. It was split up by the People’s Republic of China. The main Tibetan region now is the Tibet Autonomous Region. ★ The Tibet Autonomous Region, is a province within the People’s Republic of China. ★ Before 1950, Tibet was an independent country, but China invaded the country and took over. ★ The capital of the Tibet Autonomous Region is Lhasa. ★ The official language of the Tibet Autonomous Region is Lhasa Tibetan. ○ In schools, children are also taught Mandarin Chinese. ★ The main religion among the Tibetan people is Tibetan Buddhism. ★ In 1959, the Dalai Lama and 80,000 Tibetans fled to India for their safety. -

Sino-Tibetan Languages 393
Sino-Tibetan Languages 393 Gair J W (1998). Studies in South Asian linguistics: Sinhala Government Press. [Reprinted Sri Lanka Sahitya and other South Asian languages. Oxford: Oxford Uni- Mandalaya, Colombo: 1962.] versity Press. Karunatillake W S (1992). An introduction to spoken Sin- Gair J W & Karunatillake W S (1974). Literary Sinhala. hala. Colombo: Gunasena. Ithaca, NY: Cornell University South Asia Program. Karunatillake W S (2001). Historical phonology of Sinha- Gair J W & Karunatillake W S (1976). Literary Sinhala lese: from old Indo-Aryan to the 14th century AD. inflected forms: a synopsis with a transliteration guide to Colombo: S. Godage and Brothers. Sinhala script. Ithaca, NY: Cornell University South Asia Macdougall B G (1979). Sinhala: basic course. Program. Washington D.C.: Foreign Service Institute, Department Gair J W & Paolillo J C (1997). Sinhala (Languages of the of State. world/materials 34). Mu¨ nchen: Lincom. Matzel K & Jayawardena-Moser P (2001). Singhalesisch: Gair J W, Karunatillake W S & Paolillo J C (1987). Read- Eine Einfu¨ hrung. Wiesbaden: Harrassowitz. ings in colloquial Sinhala. Ithaca, NY: Cornell University Reynolds C H B (ed.) (1970). An anthology of Sinhalese South Asia Program. literature up to 1815. London: George Allen and Unwin Geiger W (1938). A grammar of the Sinhalese language. (English translations). Colombo: Royal Asiatic Society. Reynolds C H B (ed.) (1987). An anthology of Sinhalese Godakumbura C E (1955). Sinhalese literature. Colombo: literature of the twentieth century. Woodchurch, Kent: Colombo Apothecaries Ltd. Paul Norbury/Unesco (English translations). Gunasekara A M (1891). A grammar of the Sinhalese Reynolds C H B (1995). Sinhalese: an introductory course language. -

A Case Study of Tibetan Family Interaction in Greater New
152 Style and Standardization: A Case Study of Tibetan Family 1 Interaction in Greater New York Shannon Ward New York University 1. Introduction This paper examines competing processes of stylization and standardization among Tibetan families living in diaspora. Through a case study of conversation between ten- year-old Pangmo (pseudonym), and her father, Tenzin, I demonstrate the ways that correction constitutes an ideal, standard Tibetan code. This standard code marks features of Lhasa Tibetan, a regionally specific prestige variety that is also associated with femininity, as non-normative. Conversation analysis approaches talk (on the level of the utterance rather than the sentence) as a form of contextualized social action which, through its patterning, structures both language and ontology. Using conversation analytic methods, I address the following questions: 1) How do the values associated with sociolinguistic variables change as speakers move throughout a spatially dispersed community? 2) How do multilingual children enact and reformat these styles of speaking throughout the trajectory of their language socialization? Tibetans in exile comprise a population of over 128,000 worldwide. Most live in India, the home of Tibet’s spiritual leader, the Dalai Lama, the seat of the Tibetan exile government, and the primary destination for new migrants from Tibet.2 While scholars have noted movements between the Tibetan plateau and South Asia since at least the 18th century (Harris 2013: 27-45), Tibetan exiles espouse a common narrative of departure, dating to the 1959 invasion of Lhasa, and the Dalai Lama’s subsequent establishment of refugee settlements across the subcontinent (Ward 2012). Tibetans tend to migrate along a common route, from Tibet to Nepal to India and then, in some cases, to Europe and North America. -

Sumi Tone: a Phonological and Phonetic Description of a Tibeto-Burman Language of Nagaland
Sumi tone: a phonological and phonetic description of a Tibeto-Burman language of Nagaland Amos Benjamin Teo Submitted in total fulfilment of the requirements of the degree of Masters by Research (by Thesis Only) December 2009 School of Languages and Linguistics The University of Melbourne Abstract Previous research on Sumi, a Tibeto-Burman language spoken in the extreme northeast of India, has found it to have three lexical tones. However, the few phonological studies of Sumi have focused mainly on its segmental phonology and have failed to provide any substantial account of the tone system. This thesis addresses the issue by providing the first comprehensive description of tone in this language. In addition to confirming three contrastive tones, this study also presents the first acoustic phonetic analysis of Sumi, looking at the phonetic realisation of these tones and the effects of segmental perturbations on tone realisation. The first autosegmental representation of Sumi tone is offered, allowing us to account for tonal phenomena such as the assignment of surface tones to prefixes that appear to be lexically unspecified for tone. Finally, this investigation presents the first account of morphologically conditioned tone variation in Sumi, finding regular paradigmatic shifts in the tone on verb roots that undergo nominalisation. The thesis also offers a cross-linguistic comparison of the tone system of Sumi with that of other closely related Kuki-Chin-Naga languages and some preliminary observations of the historical origin and development of tone in these languages are made. This is accompanied by a typological comparison of these languages with other Tibeto-Burman languages, which shows that although these languages are spoken in what has been termed the ‘Indosphere’, their tone systems are similar to those of languages spoken further to the east in the ‘Sinosphere’. -

Aphonologicalhistoryofamdotib
Bulletin of SOAS, 79, 2 (2016), 347–374. Ⓒ SOAS, University of London, 2016. doi:10.1017/S0041977X16000070 A Phonological History of Amdo Tibetan Rhymes* Xun G (author's draft) Centre de recherches linguistiques sur l'Asie orientale INALCO/CNRS/EHESS [email protected] Abstract In this study, a reconstruction is offered for the phonetic evolution of rhymes from Old Tibetan to modern-day Amdo Tibetan dialects. e rel- evant sound changes are proposed, along with their relative chronological precedence and the dating of some speci�c changes. Most interestingly, although Amdo Tibetan, identically to its ancestor Old Tibetan, does not have phonemic length, this study shows that Amdo Tibetan derives from an intermediate stage which, like many other Tibetan dialects, does make the distinction. 1 Introduction Amdo Tibetan, a dialect complex of closely related Tibetan varieties spoken in the Chinese provinces of Qinghai, Gansu and Sichuan, is, demographically, linguisti- cally and culturally, one of the most important dialects of Tibetan. e historical phonology of syllable onsets of Amdo Tibetan is well studied (Róna-Tas, 1966; Sun, 1987), notably for its fascinating retentions and innovations of the complex consonant clusters of Old Tibetan (OT). e rhymes (syllable nuclei and coda) have received less attention. *is work is related to the research strand PPC2 Evolutionary approaches to phonology: New goals and new methods (in diachrony and panchrony) of the Labex EFL (funded by the ANR/CGI). I would like to thank Guillaume Jacques and two anonymous reviewers for various suggestions which resulted in a more readable and better-argued paper. 1 is study aims to reconstruct the phonetic evolution of rhymes from Old Ti- betan1 to modern-day Amdo Tibetan dialects. -

Evidentiality in Tibetic Scott Delancey 1 Introduction the Unusual And
Evidentiality in Tibetic Scott DeLancey 1 Introduction The unusual and unusually prominent grammatical expression of epistemic status and information source in Tibetic languages, especially Lhasa Tibetan,1 has played a prominent role in the study of evidentiality since that category was brought to the attention of the general linguistic public in the early 1980’s. Work by many scholars over the past two decades has produced a substantial body of more deeply-informed research on Lhasa and other Tibetic languages, only a small part of which I will be able to refer to here (see also DeLancey to appear). In this chapter I will mostly discuss Lhasa data, but concentrate on the ways that this system is typical of the pan-Tibetic phenomenon. The system will be presented inductively, in terms of grammatical categories in Tibetic languages, rather than deductively, in terms derived from theoretical claims or typological generalizations about a cross-linguistic category of evidentiality. 1 The terms “Standard” and “Lhasa” Tibetan are sometimes used interchangeably, but they are not exactly the same thing. The early publications on the topic (Goldstein and Nornang 1970, Jin 1979, Chang and Chang 1984, DeLancey 1985, 1986) were based on work with educated speakers from Lhasa, and those works and the data in this paper represent the Lhasa dialect, not “Standard Tibetan”. 2 The first known Tibetic language is Old Tibetan, the language of the Tibetan Empire, recorded in manuscripts from the 7th century CE. In scholarly as well as general use, ‘Tibetan’ is often applied to all descendants of this language, as well as to the written standard which developed from it. -

Tibet's Minority Languages-Diversity and Endangerment
Tibet’s minority languages: Diversity and endangerment Short title: Tibet’s minority languages Authors: GERALD ROCHE (Asia Institute, University of Melbourne, [email protected])* HIROYUKI SUZUKI (IKOS, University of Oslo, [email protected]) Abstract Asia is the world’s most linguistically diverse continent, and its diversity largely conforms to established global patterns that correlate linguistic diversity with biodiversity, latitude, and topography. However, one Asian region stands out as an anomaly in these patterns—Tibet, which is often portrayed as linguistically homogenous. A growing body of research now suggests that Tibet is linguistically diverse. In this article, we examine this literature in an attempt to quantify Tibet’s linguistic diversity. We focus on the minority languages of Tibet—languages that are neither Chinese nor Tibetan. We provide five different estimates of how many minority languages are spoken in Tibet. We also interrogate these sources for clues about language endangerment among Tibet’s minority languages, and propose a sociolinguistic categorization of Tibet’s minority languages that enables broad patterns of language endangerment to be perceived. Appendices include lists of the languages identified in each of our five estimates, along with references to key sources on each language. Our survey found that as many as 60 minority languages may be spoken in Tibet, and that the majority of these languages are endangered to some degree. We hope out contribution inspires further research into the predicament of Tibet’s minority languages, and helps support community efforts to maintain and revitalize these languages. NB: This is the post-review version of the paper submitted to the journal Modern Asian Studies, accepted for publication in June 2016, to appear in late 2017. -

La Politica Religiosa Della Repubblica Popolare Cinese E Il Ruolo Dei Media
Corso di Laurea magistrale in Lingue, Economie e Istituzioni dell’Asia e dell’Africa mediterranea Tesi di Laurea La politica religiosa della Repubblica Popolare Cinese e il ruolo dei media Relatrice Ch.ma Prof.ssa Laura De Giorgi Correlatrice Ch.ma Prof.ssa Francesca Tarocco Laureanda Marta Ammirati Matricola 858882 Anno Accademico 2019 / 2020 导论 中华人民共和国摆脱了中国共产党执政最初几十年坚强的“反宗教斗争”,现 在与宗教机构保持着一系列广泛管制的关系。 只有不与官方政策和意识形态相抵触的宗教活动才能得到中共中央的认可,成 为国家建设进程不可分割的一部分。因此,五大宗教(佛教、道教、伊斯兰 教、基督教与天主教)的做法不断地受到界定和重新定义。 尽管中国共产党在一定程度上肯定宗教对推进和维护社会和谐的作用,亦认为 在特殊情况下,宗教有可能危害国家统一、破坏民族团结、威胁党的权力与社 会的稳定。许多学者强调党对宗教的矛盾态度:政府一方面想纳入宗教的积极 因素以确保社会主义强国的建设,另一方面又因害怕失去权力而不敢放宽对宗 教的管制。 习近平总书记指出:“做好新形势下宗教工作,就要坚持用马克思主义立场、 观点、方法认识和对待宗教”。 确保社会稳定过程中不可或缺的一部分是国家宣传和媒体审查。官方媒体常常 避免涉及“敏感话题”。 目前,所有可能污染和腐蚀中国人民想法的问题都被认定为“敏感”问题:色 情、暴力形象、民主、有关党员的新闻和八卦以及香港民主示威等。尤其是有 关宗教事务、新疆维吾尔族穆斯林宗教自治地区、西藏、台湾和天安门的新 闻。 做好宗教新闻报道的基础就意味着官方媒体要了解共产党的宗教政策,其基本 方针是四句话 :“全面贯彻执行党的宗教信仰自由政策,依法管理宗教事 务,坚持独立自主自办的原则,积极引导宗教与社会主义社会相适应”。 本论文的目的是展示官方媒体如何体现能够界定和描述宗教辩论背景的国家权 力工具,宗教及其影响如何经常威胁到中国国家的政治、社会和意识形态稳 定。此外,本文尝试了解当今中国官方媒体如何公开描述五大宗教。 本论文分为四部分:首先介绍中国文化中的宗教观念,让读者了解“宗教”的 一般定义,以及什么是 “中国宗教”的更具体定义。除了国家承认的五个历 史宗教,“中国宗教”还包括各地许多民间信仰,新兴宗教,迷信与邪教。但 是,中国共产党一直强调真正的宗教有五个特点: 宗教要有长期性, 群众性, 民族性, 国际性和复杂性。 第二部分的内容是有关宗教在中国的历史和状况。为了更好地了解党的宗教工 作,本文的第二章节介绍中华人民共和国的宗教政策和机构。现代中国的宗教 机构、协会和组织是根据党对它们的唯一定义而构成的:五大宗教有各自的宗 教团体、政府最高管理宗教的机构是国家宗教事务局 (SARA)。 这一部分分析从中华人民共和国成立到文化大革命、改革开放政策时期到今天 的五大宗教的情况。其中,重点论述《关于我国社会主义时期宗教问题的基本 观点和基本政策》(19 号文件)的形成,Yang Fenggang 的宗教三重市场定 义,党魁政治-宗教话语的演变。 第三章主要论述“一贯道”和“法轮功”这两个宗教力量挑战国家意识形态的 问题。实际上,这两个“宗教”对国家稳定造成了巨大威胁:中国共产党认 为,盛行于 1949 年至 1954 -

Tibet: Problems, Prospects, and U.S
Order Code RL34445 Tibet: Problems, Prospects, and U.S. Policy Updated July 30, 2008 Kerry Dumbaugh Specialist in Asian Affairs Foreign Affairs, Defense, and Trade Division Tibet: Problems, Prospects, and U.S. Policy Summary On March 10, 2008, a series of demonstrations began in Lhasa and other Tibetan regions of China to mark the 49th anniversary of an unsuccessful Tibetan uprising against Chinese rule in 1959. The demonstrations appeared to begin peacefully with small groups that were then contained by security forces. Both the protests and the response of the PRC authorities escalated in the ensuing days, spreading from the Tibetan Autonomous Region (TAR) into parts of Sichuan, Gansu, and Qinghai Provinces with Tibetan populations. By March 14, 2008, mobs of angry people were burning and looting establishments in downtown Lhasa. Authorities of the People’s Republic of China (PRC) responded by sealing off Tibet and moving in large-scale security forces. Beijing has defended its actions as appropriate and necessary to restore civil order and prevent further violence. Still, China’s response has resulted in renewed calls for boycotts of the Beijing Olympics opening ceremony on August 8, 2008, and for China to hold talks with the Dalai Lama. China sees itself as having provided Tibet with extensive economic assistance and development using money from central government coffers, and PRC officials often seem perplexed at the simmering anger many Tibetans nevertheless retain against them. Despite the economic development, Tibetans charge that the PRC interferes with Tibetan culture and religion. They cite as examples: Beijing’s interference in 1995 in the choice of the Panchen Lama, Tibet’s second highest- ranking personage; enactment of a “reincarnation law” in 2007 requiring Buddhist monks who wish to reincarnate to obtain prior approval from Beijing; and China’s policy of conducting “patriotic education” campaigns, as well as efforts to foster atheism, among the Tibetan religious community. -

The Inclusive-Exclusive Distinction in Spoken and Written Tibetan
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Kobe City University of Foreign Studies Institutional Repository 神戸市外国語大学 学術情報リポジトリ The Inclusive-Exclusive Distinction in Spoken and Written Tibetan 著者 Ebihara Shiho journal or Journal of Research Institute : Historical publication title Development of the Tibetan Languages volume 51 page range 85-102 year 2014-03-01 URL http://id.nii.ac.jp/1085/00001777/ Creative Commons : 表示 - 非営利 - 改変禁止 http://creativecommons.org/licenses/by-nc-nd/3.0/deed.ja The Inclusive-Exclusive Distinction in Spoken and Written Tibetan Shiho Ebihara Research Institute for Languages and Cultures of Asia and Africa 1. Overview Filimonova (2005: ix) noted that “[t]he term[s] ‘inclusive’ and ‘exclusive’ are traditionally used to denote forms of personal pronouns which distinguish whether an addressee (or addressees) are included in or excluded from the set of referents which also contains the speaker.” Descriptive studies show that most spoken Tibetan languages feature the inclusive (INCL) - exclusive (EXCL) distinction in first- person plural and dual pronouns (except in Southern Tibetan). Furthermore, this distinction is also found in Old Tibetan and Middle Tibetan texts (as is pointed out in Zadoks 2004, Hill 2007, 2010). In this paper, we will first conduct an overview of the INCL-EXCL distinction in both spoken and written Tibetan. Then, based on this data, the following points will be discussed: 1) the classification of the INCL and EXCL forms of first-person pronouns, 2) the relations between these forms (of the two forms, which to identify as the default form for first-person pronouns), and 3) the historical development of INCL and EXCL first-person pronouns in Tibetan. -

Evidential Systems of Tibetan Languages Trends in Linguistics Studies and Monographs
Lauren Gawne, Nathan W. Hill (Eds.) Evidential Systems of Tibetan Languages Trends in Linguistics Studies and Monographs Editor Volker Gast Editorial Board Walter Bisang Jan Terje Faarlund Hans Henrich Hock Natalia Levshina Heiko Narrog Matthias Schlesewsky Amir Zeldes Niina Ning Zhang Editor responsible for this volume Walter Bisang and Volker Gast Volume 302 Evidential Systems of Tibetan Languages Edited by Lauren Gawne Nathan W. Hill ISBN 978-3-11-046018-6 e-ISBN (PDF) 978-3-11-047374-2 e-ISBN (EPUB) 978-3-11-047187-8 ISSN 1861-4302 Library of Congress Cataloging-in-Publication Data A CIP catalog record for this book has been applied for at the Library of Congress. Bibliografische Information der Deutschen Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutschen Nationalbibliografie; detailed bibliographic data are available on the internet http://dnb.dnb.de. © 2017 Walter de Gruyter GmbH, Berlin/Boston Typesetting: Compuscript Ltd., Shannon, Ireland Printing and binding: CPI books GmbH, Leck ♾ Printed on acid-free paper Printed in Germany www.degruyter.com Contents Nathan W. Hill and Lauren Gawne 1 The contribution of Tibetan languages to the study of evidentiality 1 Typology and history Shiho Ebihara 2 Evidentiality of the Tibetan verb snang 41 Lauren Gawne 3 Egophoric evidentiality in Bodish languages 61 Nicolas Tournadre 4 A typological sketch of evidential/epistemic categories in the Tibetic languages 95 Nathan W. Hill 5 Perfect experiential constructions: the inferential semantics of direct evidence 131 Guillaume Oisel 6 On the origin of the Lhasa Tibetan evidentials song and byung 161 Lhasa and Diasporic Tibetan Yasutoshi Yukawa 7 Lhasa Tibetan predicates 187 Nancy J.