Sumi Tone: a Phonological and Phonetic Description of a Tibeto-Burman Language of Nagaland
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparative Study of Angami and Chakhesang Women
A SOCIOLOGICAL STUDY OF UNEMPLOYMENT PROBLEM : A COMPARATIVE STUDY OF ANGAMI AND CHAKHESANG WOMEN THESIS SUBMITTED FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN SOCIOLOGY SCHOOL OF SOCIAL SCIENCES NAGALAND UNIVERSITY BY MEDONUO PIENYÜ Ph. D. REGISTRATION NO. 357/ 2008 UNDER THE SUPERVISION OF PROF. KSHETRI RAJENDRA SINGH DEPARTMENT OF SOCIOLOGY DEPARTMENT OF SOCIOLOGY NAGALAND UNIVERSITY H.Qs. LUMAMI, NAGALAND, INDIA NOVEMBER 2013 I would like to dedicate this thesis to my Mother Mrs. Mhasivonuo Pienyü who never gave up on me and supported me through the most difficult times of my life. NAGALAND UNIVERSITY (A Central University Estd. By the Act of Parliament No 35 of 1989) Headquaters- Lumami P.O. Mokokchung- 798601 Department of Sociology Ref. No……………. Date………………. CERTIFICATE This is certified that I have supervised and gone through the entire pages of the Ph.D. thesis entitled “A Sociological Study of Unemployment Problem: A Comparative Study of Angami and Chakhesang Women” submitted by Medonuo Pienyü. This is further certified that this research work of Medonuo Pienyü, carried out under my supervision is her original work and has not been submitted for any degree to any other university or institute. Supervisor Place: (Prof. Kshetri Rajendra Singh) Date: Department of Sociology, Nagaland University Hqs: Lumami DECLARATION The Nagaland University November, 2013. I, Miss. Medonuo Pienyü, hereby declare that the contents of this thesis is the record of my work done and the subject matter of this thesis did not form the basis of the award of any previous degree to me or to the best of my knowledge to anybody else, and that thesis has not been submitted by me for any research degree in any other university/ institute. -

APPENDIX-V FOREIGN CONTRIBUTION (REGULATION) ACT, 1976 During the Emergency Regime in the Mid-1970S, Voluntary Organizations
APPENDIX-V FOREIGN CONTRIBUTION (REGULATION) ACT, 1976 During the Emergency Regime in the mid-1970s, voluntary organizations played a significant role in Jayaprakash Narayan's (JP) movement against Mrs. Indira Gandhi. With the intervention of voluntary organizations, JP movement received funds from external sources. The government became suspicious of the N GOs as mentioned in the previous chapter and thus appointed a few prominent people in establishing the Kudal Commission to investigate the ways in which JP movement functioned. Interestingly, the findings of the investigating team prompted the passage of the Foreign Contribution (Regulation) Act during the Emergency Period. The government prepared a Bill and put it up for approval in 1973 to regulate or control the use of foreign aid which arrived in India in the form of donations or charity but it did not pass as an Act in the same year due to certain reasons undisclosed. However, in 1976, Foreign Contribution (Regulation) Act was introduced to basically monitor the inflow of funds from foreign countries by philanthropists, individuals, groups, society or organization. Basically, this Act was enacted with a view to ensure that Parliamentary, political or academic institutions, voluntary organizations and individuals who are working in significant areas of national life may function in a direction consistent with the values of a sovereign democratic republic. Any organizations that seek foreign funds have to register with the Ministry of Home Affairs, FCRA, and New Delhi. This Act is applicable to every state in India including organizations, societies, companies or corporations in the country. NGOs can apply through the FC-8 Form for a permanent number. -

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

Origin and Development of the Meitei Language
International Journal of Multidisciplinary Research and Modern Education (IJMRME) ISSN (Online): 2454 - 6119 (www.rdmodernresearch.org) Volume II, Issue I, 2016 ORIGIN AND DEVELOPMENT OF THE MEITEI LANGUAGE Khongbantabam Naobi Devi Ph.D Scholar, Department of English, Ethiraj College for Women, Chennai, Tamilnadu Abstract: Meitei language is an Indo-Aryan language. The Indo- Aryans came to Manipur and settled in the Manipur from the 4th century B.C. onwards. The noted historian and scholar R.K. Jhalajit Singh present his views on the topic to Dr. Suniti Kumar Chatterjee, the great scholar and experts on language. He expressed as Meitei language may not belong to the Kuki- Chin sub-group of the Tibeto-Burman branch; but belongs to the Sino-Tibetan family of language. All the language that belongs to the Tibeto-Burman, a sub-branch of the Sino- Tibetan family of languages, is mono- syllabic. The Meiteis language is not a monosyllabic language; it is a polysyllabic language. In meiteis language, majority of words have more than one syllable. A language should be classified because of grammar. This is the universal principle accepted on all. A language cannot be classified according to vocabulary. If we begin to classify a language according to its vocabulary, the results will be incorrect. The first settlers of the Indo-Aryans in Manipur spoke Sanskrit. Later settlers spoke Prakrit. When Prakrit was removed as spoken language, they spoke Apabhransha.. The combination of Apabhransha and Mongoloid languages gave birth to the Manipuri language by about 1074 A.D. In the olden days of the Meitei language, which was formed by the interaction of Apabhransha and Mongoloid languages, the most important words were taken from Sanskrit. -

Prayer Cards (709)
Pray for the Nations Pray for the Nations A Che in China A'ou in China Population: 43,000 Population: 2,800 World Popl: 43,000 World Popl: 2,800 Total Countries: 1 Total Countries: 1 People Cluster: Tibeto-Burman, other People Cluster: Tai Main Language: Ache Main Language: Chinese, Mandarin Main Religion: Ethnic Religions Main Religion: Ethnic Religions Status: Unreached Status: Unreached Evangelicals: 0.00% Evangelicals: 0.00% Chr Adherents: 0.00% Chr Adherents: 0.00% Scripture: Translation Needed Scripture: Complete Bible www.joshuaproject.net Source: Operation China, Asia Harvest www.joshuaproject.net Source: Operation China, Asia Harvest "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations A-Hmao in China Achang in China Population: 458,000 Population: 35,000 World Popl: 458,000 World Popl: 74,000 Total Countries: 1 Total Countries: 2 People Cluster: Miao / Hmong People Cluster: Tibeto-Burman, other Main Language: Miao, Large Flowery Main Language: Achang Main Religion: Christianity Main Religion: Ethnic Religions Status: Significantly reached Status: Partially reached Evangelicals: 75.0% Evangelicals: 7.0% Chr Adherents: 80.0% Chr Adherents: 7.0% Scripture: Complete Bible Scripture: Complete Bible www.joshuaproject.net www.joshuaproject.net Source: Anonymous Source: Wikipedia "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Achang, Husa in China Adi -

The Cultural Politics of Proxy-Voting in Nagaland
TIF - The Cultural Politics of Proxy-Voting in Nagaland JELLE J P WOUTERS June 7, 2019 RODERICK WIJUNAMAI Voters in Kohima, Nagaland | PIB Photo Nagaland’s voter turnouts are often the highest in the country, and it may be so this time around as well. But why was the citizenry of Nagaland so keen to vote for their lone, largely ineffectual representative in the Lok Sabha? Of all truisms about democracy, one that is held to be particularly true is that any democracy’s vitality and verve depends on its voter turnouts during elections. As the acclaimed political and social theorist Steven Lukes (1975: 304) concluded long ago: “Participation in elections can plausibly be interpreted as the symbolic affirmation of the voters’ acceptance of the political system and of their role within it.” Indian democracy thence draws special attention; not just for its trope of being the world’s largest democracy (Indian voters make up roughly one-sixth of the world’s electorate) but for the democratic and electoral effervescence reported all across the country. While a disenchantment with democratic institutions and politics is now clearly discernible in large swathes of the so-called “West” and finds its reflection in declining voter turnouts, to the point almost where a minority of citizens elect majority governments, India experiences no such democratic fatigue. Here voter turnouts are not just consistently high, but continue to increase and now habitually outdo those of much older democracies elsewhere. And if India’s official voter turnouts are already high, they might well be a low estimate still. -

Waromung an Ao Naga Village, Monograph Series, Part VI, Vol-I
@ MONOGRAPH CENSUS OF INDIA 1961 No. I VOLUME-I MONOGRAPH SERIES Part VI In vestigation Alemchiba Ao and Draft Research design, B. K. Roy Burman Supervision and Editing Foreword Asok Mitra Registrar General, InOla OFFICE OF THE REGISTRAR GENERAL, INDIA WAROMUNG MINISTRY OF HOME AFFAIRS (an Ao Naga Village) NEW DELHI-ll Photographs -N. Alemchiba Ao K. C. Sharma Technical advice in describing the illustrations -Ruth Reeves Technical advice in mapping -Po Lal Maps and drawings including cover page -T. Keshava Rao S. Krishna pillai . Typing -B. N. Kapoor Tabulation -C. G. Jadhav Ganesh Dass S. C. Saxena S. P. Thukral Sudesh Chander K. K. Chawla J. K. Mongia Index & Final Checking -Ram Gopal Assistance to editor in arranging materials -T. Kapoor (Helped by Ram Gopal) Proof Reading - R. L. Gupta (Final Scrutiny) P. K. Sharma Didar Singh Dharam Pal D. C. Verma CONTENTS Pages Acknow ledgement IX Foreword XI Preface XIII-XIV Prelude XV-XVII I Introduction ... 1-11 II The People .. 12-43 III Economic Life ... .. e • 44-82 IV Social and Cultural Life •• 83-101 V Conclusion •• 102-103 Appendices .. 105-201 Index .... ... 203-210 Bibliography 211 LIST OF MAPS After Page Notional map of Mokokchung district showing location of the village under survey and other places that occur in the Report XVI 2 Notional map of Waromung showing Land-use-1963 2 3 Notional map of Waromung showing nature of slope 2 4 (a) Notional map of Waromung showing area under vegetation 2 4 (b) Notional map of Waromung showing distribution of vegetation type 2 5 (a) Outline of the residential area SO years ago 4 5 (b) Important public places and the residential pattern of Waromung 6 6 A field (Jhurn) Showing the distribution of crops 58 liST OF PLATES After Page I The war drum 4 2 The main road inside the village 6 3 The village Church 8 4 The Lower Primary School building . -

THE PHONOLOGY of PROTO-TAI a Dissertation Presented to The
THE PHONOLOGY OF PROTO-TAI A Dissertation Presented to the Faculty of the Graduate School of Cornell University In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Pittayawat Pittayaporn August 2009 © 2009 Pittayawat Pittayaporn THE PHONOLOGY OF PROTO-TAI Pittayawat Pittayaporn, Ph. D. Cornell University 2009 Proto-Tai is the ancestor of the Tai languages of Mainland Southeast Asia. Modern Tai languages share many structural similarities and phonological innovations, but reconstructing the phonology requires a thorough understanding of the convergent trends of the Southeast Asian linguistic area, as well as a theoretical foundation in order to distinguish inherited traits from universal tendencies, chance, diffusion, or parallel development. This dissertation presents a new reconstruction of Proto-Tai phonology, based on a systematic application of the Comparative Method and an appreciation of the force of contact. It also incorporates a large amount of dialect data that have become available only recently. In contrast to the generally accepted assumption that Proto-Tai was monosyllabic, this thesis claims that Proto-Tai was a sesquisyllabic language that allowed both sesquisyllabic and monosyllabic prosodic words. In the proposed reconstruction, it is argued that Proto-Tai had three contrastive phonation types and six places of articulation. It had plain voiceless, implosive, and voiced stops, but lacked the aspirated stop series (central to previous reconstructions). As for place of articulation, Proto-Tai had a distinctive uvular series, in addition to the labial, alveolar, palatal, velar, and glottal series typically reconstructed. In the onset, these consonants can combine to form tautosyllabic clusters or sequisyllabic structures. -

De Sousa Sinitic MSEA
THE FAR SOUTHERN SINITIC LANGUAGES AS PART OF MAINLAND SOUTHEAST ASIA (DRAFT: for MPI MSEA workshop. 21st November 2012 version.) Hilário de Sousa ERC project SINOTYPE — École des hautes études en sciences sociales [email protected]; [email protected] Within the Mainland Southeast Asian (MSEA) linguistic area (e.g. Matisoff 2003; Bisang 2006; Enfield 2005, 2011), some languages are said to be in the core of the language area, while others are said to be periphery. In the core are Mon-Khmer languages like Vietnamese and Khmer, and Kra-Dai languages like Lao and Thai. The core languages generally have: – Lexical tonal and/or phonational contrasts (except that most Khmer dialects lost their phonational contrasts; languages which are primarily tonal often have five or more tonemes); – Analytic morphological profile with many sesquisyllabic or monosyllabic words; – Strong left-headedness, including prepositions and SVO word order. The Sino-Tibetan languages, like Burmese and Mandarin, are said to be periphery to the MSEA linguistic area. The periphery languages have fewer traits that are typical to MSEA. For instance, Burmese is SOV and right-headed in general, but it has some left-headed traits like post-nominal adjectives (‘stative verbs’) and numerals. Mandarin is SVO and has prepositions, but it is otherwise strongly right-headed. These two languages also have fewer lexical tones. This paper aims at discussing some of the phonological and word order typological traits amongst the Sinitic languages, and comparing them with the MSEA typological canon. While none of the Sinitic languages could be considered to be in the core of the MSEA language area, the Far Southern Sinitic languages, namely Yuè, Pínghuà, the Sinitic dialects of Hǎinán and Léizhōu, and perhaps also Hakka in Guǎngdōng (largely corresponding to Chappell (2012, in press)’s ‘Southern Zone’) are less ‘fringe’ than the other Sinitic languages from the point of view of the MSEA linguistic area. -

Review of Evidential Systems of Tibetan Languages
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303 Widmer, Manuel DOI: https://doi.org/10.1075/ltba.00002.wid Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-168681 Journal Article Accepted Version Originally published at: Widmer, Manuel (2017). Review of Lauren Gawne Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. Linguistics of the Tibeto-Burman Area 40(2), 285–303. Linguistics of the Tibeto- Burman Area, 40(2):285-303. DOI: https://doi.org/10.1075/ltba.00002.wid Review of Evidential systems of Tibetan languages Gawne, Lauren & Nathan W. Hill (eds.). 2016. Evidential systems of Tibetan languages. de Gruyter: Berlin. vi + 472 pp. ISBN 978-3-11-047374-2 Reviewed by Manuel Widmer 1 Tibetan evidentiality systems and their relevance for the typology of evidentiality The evidentiality1 systems of Tibetan languages rank among the most complex in the world. According to Tournadre & Dorje (2003: 110), the evidentiality systeM of Lhasa Tibetan (LT) distinguishes no less than four “evidential Moods”: (i) egophoric, (ii) testiMonial, (iii) inferential, and (iv) assertive. If one also takes into account the hearsay Marker, which is cOMMonly considered as an evidential category in typological survey studies (e.g. Aikhenvald 2004; Hengeveld & Dall’Aglio Hattnher 2015; inter alia), LT displays a five-fold evidential distinction. The LT systeM, however, is clearly not the Most cOMplex of its kind within the Tibetan linguistic area. -
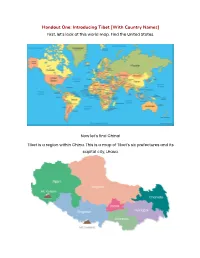
Day 1: Handouts (Tibet)
Handout One: Introducing Tibet [With Country Names] First, let’s look at this world map. Find the United States. Now let’s find China! Tibet is a region within China. This is a map of Tibet’s six prefectures and its capital city, Lhasa. On the map of China below, find Tibet. What color is Tibet on this map? Did you find it? [Teacher’s Key] Handout One: Introducing Tibet [Without Country Names] First, let’s look at this world map. Find the United States. Now let’s find China! Hint: It’s light green! Tibet is a region within China. This is a map of Tibet’s six prefectures and its capital city, Lhasa. On the map of China below, find Tibet. What color is Tibet on this map? Did you find it? [Teacher’s Key] Handout Two: Quick Facts about Tibet and the Tibet Autonomous Region ★ Tibet is historically made up of three provinces of Amdo, Kham and U-Tsang. It was split up by the People’s Republic of China. The main Tibetan region now is the Tibet Autonomous Region. ★ The Tibet Autonomous Region, is a province within the People’s Republic of China. ★ Before 1950, Tibet was an independent country, but China invaded the country and took over. ★ The capital of the Tibet Autonomous Region is Lhasa. ★ The official language of the Tibet Autonomous Region is Lhasa Tibetan. ○ In schools, children are also taught Mandarin Chinese. ★ The main religion among the Tibetan people is Tibetan Buddhism. ★ In 1959, the Dalai Lama and 80,000 Tibetans fled to India for their safety. -

Reconstructing the *S- Prefix in Old Chinese
LANGUAGE AND LINGUISTICS 13.1:29-59, 2012 2012-0-013-001-000034-1 Reconstructing the *s- Prefix in Old Chinese Laurent Sagart1 and William H. Baxter2 CRLAO1 University of Michigan2 This paper presents the treatment of the Old Chinese *s- prefix in the Baxter- Sagart system of Old Chinese reconstruction. The main functions of the prefix are to increase the valency of verbs and to derive oblique deverbal nouns. The phonetic evolutions to Middle Chinese of *s- with different kinds of OC root initials are discussed. Two salient features of the proposed system are (1) that *s- plus plain sonorants go to MC s- or sr-, and (2) that s- preceding voiced obstruents becomes voiced. Problems within a competing proposal by Mei Tsu-Lin, in which OC *s- devoices both sonorants and voiced obstruents, are pointed out. Key words: Old Chinese, reconstruction, morphology, s- prefix Mei Tsu-Lin (2012) presents a theory that an Old Chinese (OC) causative and denominative prefix *s-, of Sino-Tibetan (ST) origin, is responsible for two kinds of alternation in Middle Chinese (MC): an alternation between sonorants and voiceless obstruents and another between voiced and voiceless stops. An example of the first alternation is (in Mei’s reconstruction; our Middle Chinese notation is added in square brackets): (1) 滅 *mjiat > mjat [mjiet] ‘extinguish, destroy’ 烕 *s-mjiat > xjwat [xjwiet] ‘to cause to extinguish, destroy’ (Mei’s gloss) Examples of the second are: (2) 敗 *brads > bwai [baejH] ‘ruined, defeated’ *s-brads > pwai [paejH] ‘to ruin, to defeat’ 別 *brjat > bjat [bjet] ‘to be different, leave’ *s-brjat > pjat [pjet] ‘to divide, to separate’ Mei’s theory has the advantage of simplicity: an *s- prefix devoices both sonorants and voiced obstruents, imparting a causative meaning to the derived words.