Towards a Unicode Encoding of Teuthonista
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Combining Diacritical Marks Range: 0300–036F the Unicode Standard
Combining Diacritical Marks Range: 0300–036F The Unicode Standard, Version 4.0 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 4.0. Characters in this chart that are new for The Unicode Standard, Version 4.0 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 4.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 4.0 (ISBN 0-321-18578-1), as well as Unicode Standard Annexes #9, #11, #14, #15, #24 and #29, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UCD.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

The Brill Typeface User Guide & Complete List of Characters
The Brill Typeface User Guide & Complete List of Characters Version 2.06, October 31, 2014 Pim Rietbroek Preamble Few typefaces – if any – allow the user to access every Latin character, every IPA character, every diacritic, and to have these combine in a typographically satisfactory manner, in a range of styles (roman, italic, and more); even fewer add full support for Greek, both modern and ancient, with specialised characters that papyrologists and epigraphers need; not to mention coverage of the Slavic languages in the Cyrillic range. The Brill typeface aims to do just that, and to be a tool for all scholars in the humanities; for Brill’s authors and editors; for Brill’s staff and service providers; and finally, for anyone in need of this tool, as long as it is not used for any commercial gain.* There are several fonts in different styles, each of which has the same set of characters as all the others. The Unicode Standard is rigorously adhered to: there is no dependence on the Private Use Area (PUA), as it happens frequently in other fonts with regard to characters carrying rare diacritics or combinations of diacritics. Instead, all alphabetic characters can carry any diacritic or combination of diacritics, even stacked, with automatic correct positioning. This is made possible by the inclusion of all of Unicode’s combining characters and by the application of extensive OpenType Glyph Positioning programming. Credits The Brill fonts are an original design by John Hudson of Tiro Typeworks. Alice Savoie contributed to Brill bold and bold italic. The black-letter (‘Fraktur’) range of characters was made by Karsten Lücke. -

The Unicode Standard, Version 3.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON–WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts · Harlow, England · Menlo Park, California Berkeley, California · Don Mills, Ontario · Sydney Bonn · Amsterdam · Tokyo · Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. If these files have been purchased on computer-readable media, the sole remedy for any claim will be exchange of defective media within ninety days of receipt. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. ISBN 0-201-61633-5 Copyright © 1991-2000 by Unicode, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or other- wise, without the prior written permission of the publisher or Unicode, Inc. -
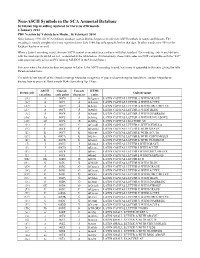
Non-ASCII Symbols in the SCA Armorial Database
Non-ASCII Symbols in the SCA Armorial Database by Iulstan Sigewealding, updated by Herveus d'Ormonde 4 January 2014 PDF Version by Yehuda ben Moshe, 16 February 2014 Since January 1996, the SCA Ordinary database (oanda.db) has begun to encode non-ASCII symbols in names and blazons. The encoding is mostly complete for items registered since July 1980, but only sporadic before that date. In other words, over 90% of the database has been revised. When a Latin-1 encoding exists, the non-ASCII symbol is encoded in accordance with that standard. The resulting code is an 8-bit byte with the most-significant bit set to 1, as detailed in the table below. (Unfortunately, these 8-bit codes are NOT compatible with the "437" code page normally active on PCs running MS-DOS in the United States.) For cases where the character does not appear in Latin-1, the ASCII encoding is used, but a note is appended to the entry giving the fully Da'ud encoded form. The table below lists all of the Da'ud encodings Morsulus recognizes. If you need something not listed there, contact Morsulus to discuss how to proceed. Don't simply Make Something Up. Please. ASCII Unicode Unicode HTML Da'ud code Unicode name encoding code point character entity {'A} A 00C0 À À LATIN CAPITAL LETTER A WITH GRAVE {A'} A 00C1 Á Á LATIN CAPITAL LETTER A WITH ACUTE {A^} A 00C2 Â Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX {A~} A 00C3 Ã Ã LATIN CAPITAL LETTER A WITH TILDE {A:} A 00C4 Ä Ä LATIN CAPITAL LETTER A WITH DIAERESIS {Ao} Aa 00C5 Å Å LATIN CAPITAL LETTER -

Latin Extended-B Range: 0180–024F
Latin Extended-B Range: 0180–024F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Homographs and Global Domain Name Watch Homographs 2019
Homographs and Global Domain Name Watch The HOMOGRAPH component added to the Global Domain Name Watch will capture a registered Domain if any of the roman characters (ascii characters) of the BRAND in question are replaced by a homograph character (a non-ascii character that looks like the ascii character) including accented letters, based on a pre-defined list. The domain registration is in effect an IDN Registration but is included and captured as part of a our standard Global Domain Name Watch service if the Homograph Component is requested. The configuration is limited to the known possible replacements identified in the list below. The fee is an additional $50 added to the price of the Domain Name Watch. Homographs 2019 Local Language & Letters Language Cyrillic Small Letter Ze з Latin Small Letter Yogh ȝ Latin Small Letter Reversed Open E ɜ Latin Small Letter Ezh ʒ Latin Small Letter Tone Five ƽ Cyrillic Small Letter Be б Digit Four 4 Latin Small Letter D with top bar ƌ Latin Small Letter Alpha ɑ Greek Small Letter Alpha α Cyrillic Small Letter A а Cyrillic Small Letter De д Latin Small Letter A with acute á Latin Small Letter A with circumflex â Latin Small Letter A with tilde ã Latin Small Letter A with diaeresis ä Latin Small Letter A with ring above å Latin Small Letter A with macron ā Latin Small Letter A with breve ă Latin Small Letter A with ogonek ą Latin Small Letter A with caron ǎ Latin Small Letter A with diaeresis and ǟ macron Latin Small Letter A with dot above and ǡ macron Latin Small Letter A with ring above and ǻ -

The Unicode Cookbook for Linguists
The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran Michael Cysouw language Translation and Multilingual Natural science press Language Processing 10 Translation and Multilingual Natural Language Processing Editors: Oliver Czulo (Universität Leipzig), Silvia Hansen-Schirra (Johannes Gutenberg-Universität Mainz), Reinhard Rapp (Johannes Gutenberg-Universität Mainz) In this series: 1. Fantinuoli, Claudio & Federico Zanettin (eds.). New directions in corpus-based translation studies. 2. Hansen-Schirra, Silvia & Sambor Grucza (eds.). Eyetracking and Applied Linguistics. 3. Neumann, Stella, Oliver Čulo & Silvia Hansen-Schirra (eds.). Annotation, exploitation and evaluation of parallel corpora: TC3 I. 4. Czulo, Oliver & Silvia Hansen-Schirra (eds.). Crossroads between Contrastive Linguistics, Translation Studies and Machine Translation: TC3 II. 5. Rehm, Georg, Felix Sasaki, Daniel Stein & Andreas Witt (eds.). Language technologies for a multilingual Europe: TC3 III. 6. Menzel, Katrin, Ekaterina Lapshinova-Koltunski & Kerstin Anna Kunz (eds.). New perspectives on cohesion and coherence: Implications for translation. 7. Hansen-Schirra, Silvia, Oliver Czulo & Sascha Hofmann (eds). Empirical modelling of translation and interpreting. 8. Svoboda, Tomáš, Łucja Biel & Krzysztof Łoboda (eds.). Quality aspects in institutional translation. 9. Fox, Wendy. Can integrated titles improve the viewing experience? Investigating the impact of subtitling on the reception and enjoyment of film using eye tracking and questionnaire data. 10. Moran, Steven & Michael Cysouw. The Unicode cookbook for linguists: Managing writing systems using orthography profiles ISSN: 2364-8899 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran Michael Cysouw language science press Steven Moran & Michael Cysouw. 2018. The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles (Translation and Multilingual Natural Language Processing 10). -

Proposal to Enable the Use of Combining Triple Diacritics in Plain
JTC1/SC2/WG2 N4078 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to enable the use of Combining Triple Diacritics in Plain Text Source: German NB Status: National Body Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2011-05-22 1. Introduction In several phonetic and dialectological transcription systems, diacritical marks are found which span over three base characters. Such marks are: conjoining bows above or below the base characters, and a tilde below the base characters. As there many projects to encode characters for the dialectology of several countries are ongoing, such triple marks are urgently needed. Fig. 3 shows an example from Slovenia, proving that the triple marks are really productive. The solution presented here follows the principle outlined in the UTC Action Item 120-A87 (see L2/09-225, re L2/09-281 COMBINING TRIPLE INVERTED BREVE and other triple‐length combining marks" by Deborah Anderson), where is stated: " Action Item for Peter Constable (UTC Liaison to WG2): Triple marks should be handled by the mechanism associated with two part diacritics in the Combining Half Marks block at U+FE20." Note: WG2 N3915 = L2/10-353 "Preliminary Proposal to enable the use of Combining Triple Diacritics in Plain Text" had proposed to encode four triple diacritics as units rather than being composed of blocks: U+1AFC COMBINING TRIPLE CIRCUMFLEX ABOVE (not addressed in this proposal) U+1AFD COMBINING TRIPLE INVERTED BREVE ABOVE (also proposed in WG2 N3571) U+1AFE COMBINING TRIPLE BREVE BELOW U+1AFF COMBINING TRIPLE TILDE BELOW It is to be noted that MUFI 3.0 contains a U+F1FC COMBINING TRIPLE BREVE BELOW in its PUA. -

Greekkeys Unicode 2008 USER’S GUIDE
i GreekKeys Unicode 2008 USER’S GUIDE by Donald Mastronarde ©2008 American Philological Association GreekKeys Unicode 2008 User’s Guide ii NEITHER THE AMERICAN PHILOLOGICAL ASSOCIATION NOR APPLE INC. NOR MICROSOFT CORPORATION MAKES ANY WARRANTIES, EITHER EXPRESS OR IMPLIED, REGARDING THE ENCLOSED COMPUTER SOFTWARE PACKAGE, ITS MERCHANTABILITY OR ITS FITNESS FOR ANY PARTICULAR PURPOSE. THE EXCLUSION OF IMPLIED WARRANTIES IS NOT PERMITTED BY SOME STATES. THE ABOVE EXCLUSION MAY NOT APPLY TO YOU. THIS WARRANTY PROVIDES YOU WITH SPECIFIC LEGAL RIGHTS. THERE MAY BE OTHER RIGHTS THAT YOU MAY HAVE WHICH VARY FROM STATE TO STATE. IN NO EVENT WILL APPLE INC. OR MICROSOFT CORPORATION OR THE AMERICAN PHILOLOGICAL ASSOCIATION BE LIABLE FOR ANY CONSEQUENTIAL, INCIDENTAL OR INDIRECT DAMAGES (INCLUDING DAMAGES FOR DOWNTIME, COSTS OF RECOVERING OR REPRODUCING DATA AND THE LIKE) ARISING OUT OF THE USE OR INABILITY TO USE GREEKKEYS, EVEN IF THEY HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. BECAUSE SOME STATES DO NOT ALLOW THE EXCLUSION OR LIMITATION OF LIABILITY FOR CONSEQUENTIAL OR INCIDENTAL DAMAGES, THE ABOVE LIMITATIONS MAY NOT APPLY TO YOU. GreekKeys 2008 Licenses See the document GreekKeysLicense.pdf, which is included in the download and also available at https://webfiles.berkeley.edu/~pinax/greekkeys/pdfs/GreekKeysLicense.pdf Macintosh and OS X are registered trademarks of Apple Inc. Microsoft Word is a registered trademark of Microsoft Corporation. PostScript is a registered trademarks of Adobe Systems, Inc. Other brand or product names are trademarks of their respective holders. iii Online sales GreekKeys 2008 is sold via a web store hosted by eSellerate at: http://store.esellerate.net/apa/apagreekkeys Technical support Technical support for this product is limited. -

Combining Diacritical Marks Range: 0300–036F the Unicode Standard
Combining Diacritical Marks Range: 0300–036F The Unicode Standard, Version 3.2 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 3.2. Characters in this chart that are new for The Unicode Standard, Version 3.2 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 3.2 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 3.0 (ISBN 0-201-61633-5), as well as Unicode Standard Annexes #28 and #27, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UnicodeCharacterDatabase.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts.