Proposal to Adjust Identifier Properties
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

8 December 2004 (Revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California
To: LSA and UC Berkeley Communities From: Deborah Anderson, UCB representative and LSA liaison Date: 8 December 2004 (revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California As the UC Berkeley representative and LSA liaison, I am most interested in the proposals for new characters and scripts that were discussed at the UTC, so these topics are the focus of this report. For the full minutes, readers should consult the "Unicode Technical Committee Minutes" web page (http://www.unicode.org/consortum/utc-minutes.html), where the minutes from this meeting will be posted several weeks hence. I. Proposals for New Scripts and Additional Characters A summary of the proposals and the UTC's decisions are listed below. As the proposals discussed below are made public, I will post the URLs on the SEI web page (www.linguistics.berkeley.edu/sei). A. Linguistics Characters Lorna Priest of SIL International submitted three proposals for additional linguistics characters. Most of the characters proposed are used in the orthographies of languages from Africa, Asia, Mexico, Central and South America. (For details on the proposed characters, with a description of their use and an image, see the appendix to this document.) Two characters from these proposals were not approved by the UTC because there are already characters encoded that are very similar. The evidence did not adequately demonstrate that the proposed characters are used distinctively. The two problematical proposed characters were: the modifier straight letter apostrophe (used for a glottal stop, similar to ' APOSTROPHE U+0027) and the Latin small "at" sign (used for Arabic loanwords in an orthography for the Koalib language from the Sudan, similar to @ COMMERCIAL AT U+0040). -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

The Coinage of Akragas C
ACTA UNIVERSITATIS UPSALIENSIS Studia Numismatica Upsaliensia 6:1 STUDIA NUMISMATICA UPSALIENSIA 6:1 The Coinage of Akragas c. 510–406 BC Text and Plates ULLA WESTERMARK I STUDIA NUMISMATICA UPSALIENSIA Editors: Harald Nilsson, Hendrik Mäkeler and Ragnar Hedlund 1. Uppsala University Coin Cabinet. Anglo-Saxon and later British Coins. By Elsa Lindberger. 2006. 2. Münzkabinett der Universität Uppsala. Deutsche Münzen der Wikingerzeit sowie des hohen und späten Mittelalters. By Peter Berghaus and Hendrik Mäkeler. 2006. 3. Uppsala universitets myntkabinett. Svenska vikingatida och medeltida mynt präglade på fastlandet. By Jonas Rundberg and Kjell Holmberg. 2008. 4. Opus mixtum. Uppsatser kring Uppsala universitets myntkabinett. 2009. 5. ”…achieved nothing worthy of memory”. Coinage and authority in the Roman empire c. AD 260–295. By Ragnar Hedlund. 2008. 6:1–2. The Coinage of Akragas c. 510–406 BC. By Ulla Westermark. 2018 7. Musik på medaljer, mynt och jetonger i Nils Uno Fornanders samling. By Eva Wiséhn. 2015. 8. Erik Wallers samling av medicinhistoriska medaljer. By Harald Nilsson. 2013. © Ulla Westermark, 2018 Database right Uppsala University ISSN 1652-7232 ISBN 978-91-513-0269-0 urn:nbn:se:uu:diva-345876 (http://urn.kb.se/resolve?urn=urn:nbn:se:uu:diva-345876) Typeset in Times New Roman by Elin Klingstedt and Magnus Wijk, Uppsala Printed in Sweden on acid-free paper by DanagårdLiTHO AB, Ödeshög 2018 Distributor: Uppsala University Library, Box 510, SE-751 20 Uppsala www.uu.se, [email protected] The publication of this volume has been assisted by generous grants from Uppsala University, Uppsala Sven Svenssons stiftelse för numismatik, Stockholm Gunnar Ekströms stiftelse för numismatisk forskning, Stockholm Faith and Fred Sandstrom, Haverford, PA, USA CONTENTS FOREWORDS ......................................................................................... -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Optimal Interleaving: Serial Phonology-Morphology Interaction in a Constraint-Based Model
OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW ADAM WOLF Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY September 2008 Department of Linguistics © Copyright by Matthew Adam Wolf 2008 All Rights Reserved OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW A. WOLF Approved as to style and content by: ____________________________________ John J. McCarthy, Chair ____________________________________ Joseph V. Pater, Member ____________________________________ Elisabeth O. Selkirk, Member ____________________________________ Mark H. Feinstein, Member ___________________________________ Elisabeth O. Selkirk, Head Department of Linguistics ACKNOWLEDGEMENTS I’ve learned from my own habits over the years that the acknowledgements are likely to be the most-read part of any dissertation. It is therefore with a degree of trepidation that I set down these words of thanks, knowing that any omissions or infelicities I might commit will be a source of amusement for who-knows-how-many future generations of first-year graduate students. So while I’ll make an effort to avoid cliché, falling into it will sometimes be inevitable—for example, when I say (as I must, for it is true) that this work could never have been completed without the help of my advisor, John McCarthy. John’s willingness to patiently hear out half-baked ideas, his encyclopedic knowledge of the phonology literature, his almost unbelievably thorough critical eye, and his dogged insistence on making the vague explicit have made this dissertation far better, and far better presented, than I could have hoped to achieve on my own. -

Centc304 N932
CEN/TC304 N932 Source: Secretariat Date: 15 Dec 1999 Title: European Fallback Rules, ballot Mailed: 15 Dec 1999 Status: TC-enquiry: DEADLINE 1st March 2000 Action required: Respond before 1 March 2000 * Notes: This is a TC-enquiry, to establish the suitability of N932 to be sent for Formal vote as prENV. National member body officers, responsible for CEN/TC304 issues are asked to fill in this form and send it to the TC-secretariat before 1 March 2000. Comments in any form will be forwarded to the CEN/TC 304 Project Team of European Fallback Rules. The PT will before the next plenary of TC304 in April 2000 produce a disposition of comments and a revised draft. The PT will produce a disposition of comments and plans to ask the TC304 plenary in November to approve a revised draft to be sent for Formal Vote. Comments from affiliated members of CEN and liaisons are welcome and will be considered. Country:______________________________ Approves without comments ___ Approves with comments ___ Disapproves with comments ___ Date:_______________ Signature_____________________________________(National Member Body officer) Name:__________________________________ EUROPEAN PRESTANDARD DRAFT PRÉNORME EUROPÉENNE prENV_____ EUROPÄISCHE VORNORM ICS: 35.040 Descriptors: Data processing, information interchange, text processing, text communication, graphic characters, character sets, representation of characters, coded character sets, conversion, fallback English version Information Technology European fallback rules Technologies de l'information- Informations technologies Character repertoire and coding transformations: Character repertoire and coding transformations: European fallback rules - Nº 1 European fallback rules - Nº 1 This draft ENV is submitted to CEN members for Formal Vote. It has been drawn up by the Technical Committee CEN/TC 304. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -
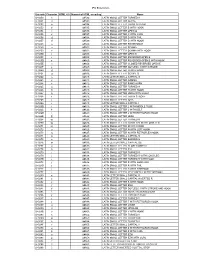
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

African Fonts and Open Source
African fonts and Open Source Denis Moyogo Jacquerye September 17th 2008 ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 1 African fonts and Open Source Denis Moyogo Jacquerye African fonts and Open Source This talk is about: ● African Orthographies (relevance, groups, requirements) ● Technologies for them (Unicode, OpenType) ● Implementation ● Raise awareness and interest ● Case for Open Source ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 2 African fonts and Open Source Denis Moyogo Jacquerye Speaker Denis Moyogo Jacquerye ● Computer Scientist and Linguist ● Africanization consultant ● DejaVu Fonts co-leader ● African Network for Localization (ANLoc) ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 3 African fonts and Open Source Denis Moyogo Jacquerye ANLoc African fonts work part of ANLoc project ● Facilitate localization ● Empowering through ICT ● Network of experts ● Sub-projects: Locales, Keyboards, Fonts, Spell checkers, Terminology, Training, Localization software, Policy. ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 4 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Lots of African languages (over 2000) ● 25 spoken by about half ● 80% don't have orthographies ● 20% do! ● Can emulate! ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 5 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Used every day by most ● Education is mostly in European language ● Used in spoken media ● Interest is rising ATypI ‘o8 Conference St. Petersburg, -
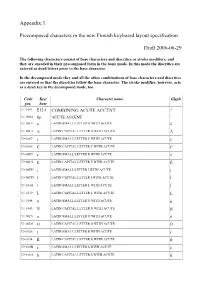
Appendix 3. Precomposed Characters in the New Finnish Keyboard Layout
Appendix 3. Precomposed characters in the new Finnish keyboard layout specification Draft 2006-06-29 The following characters consist of base characters and diacritics or stroke modifiers, and they are encoded in their precomposed form in the basic mode. In this mode the diacritics are entered as dead letters prior to the base character. In the decomposed mode they and all the other combinations of base characters and diacritics are entered so that the diacritics follow the base character. The stroke modifier, however, acts as a dead key in the decomposed mode, too. Code Key/ Character name Glyph pos. base U+0301 E12-1 COMBINING ACUTE ACCENT U+00B4 Sp. ACUTE ACCENT ´ U+00E1 a LATIN SMALL LETTER A WITH ACUTE á U+00C1 A LATIN CAPITAL LETTER A WITH ACUTE Á U+0107 c LATIN SMALL LETTER C WITH ACUTE U+0106 C LATIN CAPITAL LETTER C WITH ACUTE U+00E9 e LATIN SMALL LETTER E WITH ACUTE é U+00C9 E LATIN CAPITAL LETTER E WITH ACUTE É U+00ED i LATIN SMALL LETTER I WITH ACUTE í U+00CD I LATIN CAPITAL LETTER I WITH ACUTE Í U+013A l LATIN SMALL LETTER L WITH ACUTE U+0139 L LATIN CAPITAL LETTER L WITH ACUTE U+0144 n LATIN SMALL LETTER N WITH ACUTE U+0143 N LATIN CAPITAL LETTER N WITH ACUTE U+00F3 o LATIN SMALL LETTER O WITH ACUTE ó U+00D3 O LATIN CAPITAL LETTER O WITH ACUTE Ó U+0155 r LATIN SMALL LETTER R WITH ACUTE U+0154 R LATIN CAPITAL LETTER R WITH ACUTE U+015B s LATIN SMALL LETTER S WITH ACUTE U+015A S LATIN CAPITAL LETTER S WITH ACUTE U+00FA u LATIN SMALL LETTER U WITH ACUTE ú U+00DA U LATIN CAPITAL LETTER U WITH ACUTE Ú U+1E83 w LATIN SMALL LETTER W WITH ACUTE 3 U+1E82 W LATIN CAPITAL LETTER W WITH ACUTE 2 U+00FD y LATIN SMALL LETTER Y WITH ACUTE U+00DD Y LATIN CAPITAL LETTER Y WITH ACUTE U+017A z LATIN SMALL LETTER Z WITH ACUTE # U+0179 Z LATIN CAPITAL LETTER Z WITH ACUTE " U+01FD æ LATIN SMALL LETTER AE WITH ACUTE / U+01FC Æ LATIN CAPITAL LETTER AE WITH ACUTE . -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6