How Children Learn to Write Words
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Method to Accommodate Backward Compatibility on the Learning Application-Based Transliteration to the Balinese Script
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 12, No. 6, 2021 A Method to Accommodate Backward Compatibility on the Learning Application-based Transliteration to the Balinese Script 1 3 4 Gede Indrawan , I Gede Nurhayata , Sariyasa I Ketut Paramarta2 Department of Computer Science Department of Balinese Language Education Universitas Pendidikan Ganesha (Undiksha) Universitas Pendidikan Ganesha (Undiksha) Singaraja, Indonesia Singaraja, Indonesia Abstract—This research proposed a method to accommodate transliteration rules (for short, the older rules) from The backward compatibility on the learning application-based Balinese Alphabet document 1 . It exposes the backward transliteration to the Balinese Script. The objective is to compatibility method to accommodate the standard accommodate the standard transliteration rules from the transliteration rules (for short, the standard rules) from the Balinese Language, Script, and Literature Advisory Agency. It is Balinese Language, Script, and Literature Advisory Agency considered as the main contribution since there has not been a [7]. This Bali Province government agency [4] carries out workaround in this research area. This multi-discipline guidance and formulates programs for the maintenance, study, collaboration work is one of the efforts to preserve digitally the development, and preservation of the Balinese Language, endangered Balinese local language knowledge in Indonesia. The Script, and Literature. proposed method covered two aspects, i.e. (1) Its backward compatibility allows for interoperability at a certain level with This study was conducted on the developed web-based the older transliteration rules; and (2) Breaking backward transliteration learning application, BaliScript, for further compatibility at a certain level is unavoidable since, for the same ubiquitous Balinese Language learning since the proposed aspect, there is a contradictory treatment between the standard method reusable for the mobile application [8], [9]. -

Effects and Mitigation of Out-Of-Vocabulary in Universal Language Models
Journal of Information Processing Vol.29 490–503 (July 2021) [DOI: 10.2197/ipsjjip.29.490] Regular Paper Effects and Mitigation of Out-of-vocabulary in Universal Language Models Sangwhan Moon1,†1,a) Naoaki Okazaki1,b) Received: December 8, 2020, Accepted: April 2, 2021 Abstract: One of the most important recent natural language processing (NLP) trends is transfer learning – using representations from language models implemented through a neural network to perform other tasks. While transfer learning is a promising and robust method, downstream task performance in transfer learning depends on the robust- ness of the backbone model’s vocabulary, which in turn represents both the positive and negative characteristics of the corpus used to train it. With subword tokenization, out-of-vocabulary (OOV) is generally assumed to be a solved problem. Still, in languages with a large alphabet such as Chinese, Japanese, and Korean (CJK), this assumption does not hold. In our work, we demonstrate the adverse effects of OOV in the context of transfer learning in CJK languages, then propose a novel approach to maximize the utility of a pre-trained model suffering from OOV. Additionally, we further investigate the correlation of OOV to task performance and explore if and how mitigation can salvage a model with high OOV. Keywords: Natural language processing, Machine learning, Transfer learning, Language models to reduce the size of the vocabulary while increasing the robust- 1. Introduction ness against out-of-vocabulary (OOV) in downstream tasks. This Using a large-scale neural language model as a pre-trained is especially powerful when combined with transfer learning. -

“To Every Nation, Kindred, Tongue, and People”
12 “To Every Nation, Kindred, Tongue, and People” Po Nien (Felipe) Chou and Petra Chou Po Nien (Felipe) Chou is a religious educator and manager of the Offi ce of Research for the Seminaries and Institutes (S&I) of Th e Church of Jesus Christ of Latter-day Saints. Petra Chou is a homemaker and teaches in the Chinese Immersion program for the Alpine School District. he Book of Mormon was fi rst translated into the English language by Tthe Prophet Joseph Smith in 1829. Th e goal is now to make it avail- able “to every nation, kindred, tongue, and people” (Mosiah 15:28). Th is chapter explores the eff orts of Th e Church of Jesus Christ of Latter-day Saints to bring forth the Book of Mormon in other languages and to make it accessible to all the world. Although it will not provide an exhaustive review of all 110 translations (87 full book and 23 selections)1 distributed by the Church by spring 2015, it will examine a number of translations, versions, and editions, along with the eff orts to bring forth this sacred volume to “all nations, kindreds, tongues and people” (D&C 42:58). Ancient prophets declared that in the latter days the Lord would “com- mence his work among all nations, kindreds, tongues, and people, to bring about the restoration of his people upon the earth” (2 Nephi 30:8). Th e Book of Mormon was to “be kept and preserved” so that the knowledge of the Savior and his gospel would go forth and be taught unto “every nation, kindred, tongue, and people” in preparation for the Second Coming of the 228 Po Nien (Felipe) Chou and Petra Chou Lord (see 1 Nephi 13:40; Mosiah 3:20; Alma 37:4; D&C 42:48; D&C 133:37). -

Child Readersв€™ Eye Movements in Reading Thai
Vision Research 123 (2016) 8–19 Contents lists available at ScienceDirect Vision Research journal homepage: www.elsevier.com/locate/visres Child readers’ eye movements in reading Thai ⇑ Benjawan Kasisopa a, , Ronan G. Reilly a,b, Sudaporn Luksaneeyanawin c, Denis Burnham a a MARCS Institute for Brain, Behaviour, and Development, Western Sydney University, Australia b Department of Computer Science, Maynooth University, Ireland c Centre for Research in Speech and Language Processing, Chulalongkorn University, Thailand article info abstract Article history: It has recently been found that adult native readers of Thai, an alphabetic scriptio continua language, Received 30 July 2014 engage similar oculomotor patterns as readers of languages written with spaces between words; despite Received in revised form 1 July 2015 the lack of inter-word spaces, first and last characters of a word appear to guide optimal placement of Accepted 23 July 2015 Thai readers’ eye movements, just to the left of word-centre. The issue addressed by the research Available online 12 May 2016 described here is whether eye movements of Thai children also show these oculomotor patterns. Here the effect of first and last character frequency and word frequency on the eye movements of 18 Thai chil- Keywords: dren when silently reading normal unspaced and spaced text was investigated. Linear mixed-effects Eye movements model analyses of viewing time measures (first fixation duration, single fixation duration, and gaze dura- Children’s reading Landing site distribution tion) and of landing site location revealed that Thai children’s eye movement patterns were similar to Thai text their adult counterparts. Both first character frequency and word frequency played important roles in Thai children’s landing sites; children tended to land their eyes further into words, close to the word cen- tre, if the word began with higher frequency first characters, and this effect was facilitated in higher fre- quency words. -

Das Deutsche Schriftsystem (Compu-Skript)
PD Dr. Wolfgang Schindler. LMU München. Compu-Skript „Das deutsche Schriftsystem“. Version 27.09.2021. Seite 1 E-Mail: Wolfgang.Schindler[ätt]germanistik.uni-muenchen.de Web: http://wolfgang-schindler.userweb.mwn.de/index.html Das deutsche Schriftsystem 1 (Literaturverzeichnis am Ende!) 1 Zur Evolution von Schreibgrammatik Wenn wir in die römische Antike zurückblicken, fällt uns auf, dass es viele Schriftdokumente, bei- spielsweise Inschriften, gibt, die in CAPITALIS und in der sog. SCRIPTIO CONTINUA verfasst sind: Inschrift2 Trajan-Säule in Rom 112/113 n. Chr. Wenn wir das in einer großbuchstabigen durchgängigen Schreibung im Deutschen nachahmen, dann sieht das ungefähr so aus: 3 DIROMERHABENTATSEHLIHOFTERSONEWORTZWISENRAUMEGESRIBEN Die Römer haben tatsächlich öfters ohne Wortzwischenräume geschrieben 1 Dieses Typoskript ist aus einer Vorlesungsgrundlage entstanden. Es ist inspiriert von Beatrice Primus’ Arbeiten, ins- besondere ihrer Vorlesung "Das Schriftsystem des Deutschen“ (Köln, 2009)! Der Interpunktionsteil ist inspiriert von Ursula Bredels Arbeiten. Zu nennen sind auch die Einflüsse des Wortschreibungsteils in der Grammatik von Peter Eisenberg (Grundriss, Bd. 1., Kap. 8). Den Keim legte vor langer Zeit eine Vorlesung von Hartmut Günther, die er während meines Studiums in München hielt. Und natürlich sind meine Gedanken von den vielen Arbeiten inspiriert, die im Literaturverzeichnis am Ende aufgeführt sind. 2 Für die Interessierten hier eine Version mit einer Gliederung und mit einer ungefähren Übersetzung: SENATVS·POPVLVSQVE·ROMANVS / IMP·CAESARI·DIVI·NERVAE·F·NERVAE / TRAIANO·AVG·GERM·DACICO·PONTIF / MAXIMO·TRIB·POT·XVII·IMP·VI·COS·VI·P·P / AD·DECLARANDVM·QVANTAE·ALTITVDINIS / MONS·ET·LOCVS·TANT<IS·OPER>IBVS·SIT·EGESTVS Die Inschrift enthält zwar keine Spatien, aber MITTELPUNKTE, die meist worttrennend eingesetzt werden. -

Optimal Interleaving: Serial Phonology-Morphology Interaction in a Constraint-Based Model
OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW ADAM WOLF Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY September 2008 Department of Linguistics © Copyright by Matthew Adam Wolf 2008 All Rights Reserved OPTIMAL INTERLEAVING: SERIAL PHONOLOGY-MORPHOLOGY INTERACTION IN A CONSTRAINT-BASED MODEL A Dissertation Presented by MATTHEW A. WOLF Approved as to style and content by: ____________________________________ John J. McCarthy, Chair ____________________________________ Joseph V. Pater, Member ____________________________________ Elisabeth O. Selkirk, Member ____________________________________ Mark H. Feinstein, Member ___________________________________ Elisabeth O. Selkirk, Head Department of Linguistics ACKNOWLEDGEMENTS I’ve learned from my own habits over the years that the acknowledgements are likely to be the most-read part of any dissertation. It is therefore with a degree of trepidation that I set down these words of thanks, knowing that any omissions or infelicities I might commit will be a source of amusement for who-knows-how-many future generations of first-year graduate students. So while I’ll make an effort to avoid cliché, falling into it will sometimes be inevitable—for example, when I say (as I must, for it is true) that this work could never have been completed without the help of my advisor, John McCarthy. John’s willingness to patiently hear out half-baked ideas, his encyclopedic knowledge of the phonology literature, his almost unbelievably thorough critical eye, and his dogged insistence on making the vague explicit have made this dissertation far better, and far better presented, than I could have hoped to achieve on my own. -

POSTLUDE P.1 Letter Frequencies
POSTLUDE A Prelude opened this textbook with the puzzle Mastermind that introduced combinatorial reasoning in a recreational setting. This Postlude looks at a cryptanalysis problem that is again of a recreational nature but also illustrates the less structured side of combinatorial reasoning as it often occurs in real-world problems. In particular, we will look at a simple cryptographic scheme in which the analysis of underlying combinatorial problems is complicated by the somewhat random pattern of letters in English text. P.1 Letter Frequencies There have been many tables produced of the relative frequencies of letters in English writing, starting with Samuel Morse (of Morse code fame). We use frequencies averaged over several tables. Most Common Letters in English Text Vowels Consonants E 12% T 9% A, I, O 8 % N, R, S 6-8% D, L 4% The least frequent letters, all consonants, are: J, Q, X, Z below .05% As we shall see, it is also useful to know which pairs of consecutive letters, called digraphs, are most frequent. The eight most common digraphs are Most frequent: TH Second most frequent: HE Next six most frequent: ER, RE and AN, EN, IN, ON N is unique among the very frequent letters in that close to 90% of its occurrences are preceded by a vowel; other frequent letters have a much wider range of other letters preceding them. Some other frequent digraphs that can be helpful are: ES, SE ED, DE ST TE, TI, TO OF Frequent consonants tend to appear beside vowels but vowels do not occur side-by-side often and similarly frequent consonants do not appear side-by-side often except for TH and ST. -

VSI Openvms C Language Reference Manual
VSI OpenVMS C Language Reference Manual Document Number: DO-VIBHAA-008 Publication Date: May 2020 This document is the language reference manual for the VSI C language. Revision Update Information: This is a new manual. Operating System and Version: VSI OpenVMS I64 Version 8.4-1H1 VSI OpenVMS Alpha Version 8.4-2L1 Software Version: VSI C Version 7.4-1 for OpenVMS VMS Software, Inc., (VSI) Bolton, Massachusetts, USA C Language Reference Manual Copyright © 2020 VMS Software, Inc. (VSI), Bolton, Massachusetts, USA Legal Notice Confidential computer software. Valid license from VSI required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The information contained herein is subject to change without notice. The only warranties for VSI products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. VSI shall not be liable for technical or editorial errors or omissions contained herein. HPE, HPE Integrity, HPE Alpha, and HPE Proliant are trademarks or registered trademarks of Hewlett Packard Enterprise. Intel, Itanium and IA64 are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. Java, the coffee cup logo, and all Java based marks are trademarks or registered trademarks of Oracle Corporation in the United States or other countries. Kerberos is a trademark of the Massachusetts Institute of Technology. -

Proposal to Encode the Grantha Script in Unicode §1. Introduction
Proposal to encode the Grantha script in Unicode Shriramana Sharma (jamadagni-at-gmail-dot-com), India 2009-Oct-24 Author’s Note This proposal started out as a joint effort of Elmar Kniprath of Germany and myself. However, Mr Kniprath has decided for personal reasons to retire shortly before its submission. This proposal as it stands contains a lot of material contributed by him, but I assume full responsibility for any errors or omissions. I however retain the words “we”, “us” etc in their generic sense. On the need for a separate proposal We are aware that a proposal for encoding Grantha (L2/09-141) has been submitted by Naga Ganesan in April 2009. We have thoroughly studied it and compared it with a parallel proposal on which we was working since summer 2008. We decided to continue our work and submit an independent proposal for the following reasons: 1. Mr Ganesan’s proposal contains several false assertions. We have submitted our objections as L2/09-316 “Comments on Mr Ganesan’s Grantha Proposal”. 2. Mr Ganesan’s proposal does not consider the use of Grantha for Vedic Sanskrit. Since a large part of the current user community of Grantha is the Vedic scholars of Tamil Nadu, it is very important that Vedic Sanskrit be provided for in encoding. 3. Efforts to work together with Mr Ganesan to submit a unified proposal failed. §1. Introduction The Grantha script is an Indic script descended from Brahmi, still being used in its modern form in parts of South India, especially Tamil Nadu and to a lesser extent in Sri Lanka and other places. -

Designing Soft Keyboards for Brahmic Scripts
Designing Soft Keyboards for Brahmic Scripts Lauren Hinkle Miguel Lezcano Jugal Kalita Colorado College University of Colorado University of Colorado Colorado Springs, CO, USA Colorado Springs, CO, USA Colorado Springs, CO, USA lauren.hinkle [email protected] [email protected] @coloradocollege.edu Abstract Soft keyboards allow a user to input text with and without the use of a physical keyboard. They Despite being spoken by a large percent- are versatile because they allow data to be input age of the world, many Indic languages through mouse clicks on an on-screen keyboard, have escaped research and development in through a touch screen on a computer, cell phone, the realm of text-input. There exist lan- or PDA, or by mapping a virtual keyboard to guages with poor or no support for typ- a standard physical keyboard. With the recent ing. Soft keyboards, because of their ease surge in popularity of touchscreen media such of installation and lack of reliance on spe- as cell phones and computers, well-designed cific hardware, are a promising solution as soft keyboards are becoming more important an input device for many languages. De- everywhere. veloping an acceptable soft keyboard re- For languages that don’t conform well to quires frequency analysis of characters in standard QWERTY based keyboards that order to design a layout that minimizes accompany most computers, soft keyboards are text-input time. This paper proposes us- especially important. Brahmic scripts (Coulmas ing various development techniques, lay- 1990) have more characters and ligatures than fit out variations, and evaluation methods usably on a standard keyboard. -

A History of the Deseret Alphabet
Brigham Young University BYU ScholarsArchive Theses and Dissertations 1970 A History of the Deseret Alphabet Larry Ray Wintersteen Brigham Young University - Provo Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the History Commons, Linguistics Commons, and the Mormon Studies Commons BYU ScholarsArchive Citation Wintersteen, Larry Ray, "A History of the Deseret Alphabet" (1970). Theses and Dissertations. 5220. https://scholarsarchive.byu.edu/etd/5220 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. A A HISTORY OF THE DESERET ALPHABET A A thesis presented to the department of speech and dramatic arts brigham young university in partial fulfillment of the requirements for the degree master of arts by larry ray wintersteen may 1970 A HISTORY OF THE DESERET ALPHABET larry ray wintersteen department of speech and dramatic arts MA degree may 1970 ABSTRACT L the church of jesus chrichristst of latter day saints during the years 185218771852 1877 introduced to its membership a form of rhetoric writing system called the deseret alphabet phonetic alphabet this experi- ment was intended to alleviate the problem of non-noncommunicationcommunication which was created by the great influx of foreign speaking saints into the great salt lake valley the alphabet was developed and encouraged -
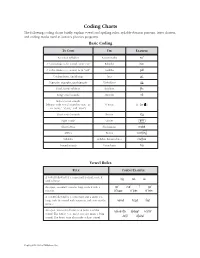
Phonics TRB Coding Chart
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss.