POSTLUDE P.1 Letter Frequencies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

VSI Openvms C Language Reference Manual
VSI OpenVMS C Language Reference Manual Document Number: DO-VIBHAA-008 Publication Date: May 2020 This document is the language reference manual for the VSI C language. Revision Update Information: This is a new manual. Operating System and Version: VSI OpenVMS I64 Version 8.4-1H1 VSI OpenVMS Alpha Version 8.4-2L1 Software Version: VSI C Version 7.4-1 for OpenVMS VMS Software, Inc., (VSI) Bolton, Massachusetts, USA C Language Reference Manual Copyright © 2020 VMS Software, Inc. (VSI), Bolton, Massachusetts, USA Legal Notice Confidential computer software. Valid license from VSI required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The information contained herein is subject to change without notice. The only warranties for VSI products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. VSI shall not be liable for technical or editorial errors or omissions contained herein. HPE, HPE Integrity, HPE Alpha, and HPE Proliant are trademarks or registered trademarks of Hewlett Packard Enterprise. Intel, Itanium and IA64 are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. Java, the coffee cup logo, and all Java based marks are trademarks or registered trademarks of Oracle Corporation in the United States or other countries. Kerberos is a trademark of the Massachusetts Institute of Technology. -

Designing Soft Keyboards for Brahmic Scripts
Designing Soft Keyboards for Brahmic Scripts Lauren Hinkle Miguel Lezcano Jugal Kalita Colorado College University of Colorado University of Colorado Colorado Springs, CO, USA Colorado Springs, CO, USA Colorado Springs, CO, USA lauren.hinkle [email protected] [email protected] @coloradocollege.edu Abstract Soft keyboards allow a user to input text with and without the use of a physical keyboard. They Despite being spoken by a large percent- are versatile because they allow data to be input age of the world, many Indic languages through mouse clicks on an on-screen keyboard, have escaped research and development in through a touch screen on a computer, cell phone, the realm of text-input. There exist lan- or PDA, or by mapping a virtual keyboard to guages with poor or no support for typ- a standard physical keyboard. With the recent ing. Soft keyboards, because of their ease surge in popularity of touchscreen media such of installation and lack of reliance on spe- as cell phones and computers, well-designed cific hardware, are a promising solution as soft keyboards are becoming more important an input device for many languages. De- everywhere. veloping an acceptable soft keyboard re- For languages that don’t conform well to quires frequency analysis of characters in standard QWERTY based keyboards that order to design a layout that minimizes accompany most computers, soft keyboards are text-input time. This paper proposes us- especially important. Brahmic scripts (Coulmas ing various development techniques, lay- 1990) have more characters and ligatures than fit out variations, and evaluation methods usably on a standard keyboard. -
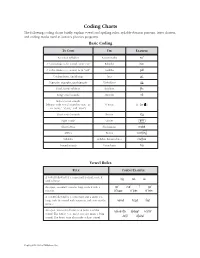
Phonics TRB Coding Chart
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss. -

English Literacy Dossier
English Literacy Dossier Myriam Cherro Samper Javier Fernández Molina Manuel Sánchez Quero 1 ISBN: 978-84-09-19463-6 ENGLISH PHONETICS. INTRODUCTION TO THE SOUNDS OF ENGLISH AND THEIR REPRESENTATION. 1. ENGLISH PHONETICS. INTRODUCTION TO THE SOUNDS OF ENGLISH AND THEIR REPRESENTATION. ... 4 1.1 Definition of Language. ................................................................................................................... 4 1.1.1 Roman Jakobson’s Function of Language Theory .......................................................................... 6 1.2 What Is Linguistics?................................................................................................................................ 7 1.2.1 Linguistic Branches ........................................................................................................................ 8 1.2.2 Phonemes vs. Allophones .............................................................................................................. 8 1.2.3 Phonetics vs. Phonology ................................................................................................................ 9 1.2.4 Minimal Pairs ............................................................................................................................... 10 1.2.5 Homophone vs. Homographs ....................................................................................................... 10 1.3 The English Alphabet. ......................................................................................................................... -

Lunyole Grammar; It Does Not Attempt to Make a Statement for Or Against a Particular Formal Linguistic Theory
A PARTIAL GRAMMAR SKETCH OF LUNYOLE WITH EMPHASIS ON THE APPLICATIVE CONSTRUCTION(S) _______________________ A Thesis Presented to The Faculty of the School of Intercultural Studies Department of Applied Linguistics & TESOL Biola University _______________________ In Partial Fulfillment of the Requirements for the Degree Master of Arts in Applied Linguistics _______________________ by Douglas Allen Wicks May 2006 ABSTRACT A PARTIAL GRAMMAR SKETCH OF LUNYOLE WITH EMPHASIS ON THE APPLICATIVE CONSTRUCTION(S) Douglas Allen Wicks This thesis provides a general grammatical description of Lunyole, a Bantu language of Eastern Uganda. After a brief description of the phonology, it describes the morphology and basic syntax of Lunyole, following Payne’s (1997) functional approach. This thesis then more deeply describes Lunyole’s applicative constructions in which an argument is added to the verb complex. Lunyole has two applicative marking constructions. The more productive one uses the -ir suffix on verbs of any valence in conjunction with a wide range of semantic roles. The other applicative construction is formed from a locative class prefix and is used only for locative arguments on unaccusative intransitive verbs. Similar locative morphemes may co-occur with the -ir applicative morpheme, but not as applicative markers; instead they clarify the relationship between arguments. TABLE OF CONTENTS PAGE List of Tables ..................................................................................................................... ix List of Figures......................................................................................................................x -

How Children Learn to Write Words
How Children Learn to Write Words How Children Learn to Write Words Rebecca TReiman and bReTT KessleR 1 3 Oxford University Press is a department of the University of Oxford. It furthers the University’s objective of excellence in research, scholarship, and education by publishing worldwide. Oxford New York Auckland Cape Town Dar es Salaam Hong Kong Karachi Kuala Lumpur Madrid Melbourne Mexico City Nairobi New Delhi Shanghai Taipei Toronto With offices in Argentina Austria Brazil Chile Czech Republic France Greece Guatemala Hungary Italy Japan Poland Portugal Singapore South Korea Switzerland Thailand Turkey Ukraine Vietnam Oxford is a registered trademark of Oxford University Press in the UK and certain other countries. Published in the United States of America by Oxford University Press 198 Madison Avenue, New York, NY 10016 © Oxford University Press 2014 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, without the prior permission in writing of Oxford University Press, or as expressly permitted by law, by license, or under terms agreed with the appropriate reproduction rights organization. Inquiries concerning reproduction outside the scope of the above should be sent to the Rights Department, Oxford University Press, at the address above. You must not circulate this work in any other form and you must impose this same condition on any acquirer. A copy of this book’s Catalog-in-Publication Data is on file with the Library of Congress ISBN 978–0–19–990797–7 -

ADAPTATIONS of HEBREW SCRIPT in This Chapter I Present An
CHAPTER TWO FROM ARAMEA TO AMERICA: ADAPTATIONS OF HEBREW SCRIPT In this chapter I present an overview of the development of the Hebrew writing system, followed by a survey of language families with attested Hebrew-letter texts. While I aim to provide a broader and more inclusive overview of Hebraicization than has been available previously, I do not make any claim to comprehensiveness. 1. FROM HEBREW TO JEWISH WRITING Nothing is known of Hebraic writing before the Israelites emerged in the land of Canaan and "borrowed the art of writing" from the local inhabitants in the twelfth or eleventh century BCE (Naveh 1982: 65). In the earliest known Hebrew inscription, the Gezer calendar,1 the writing resembles that of tenth-century Phoenician inscriptions from Byblos, and features no specifically Hebrew characters. Indeed, the Phoenician influence was so dominant that neither the Hebrews nor the Aramaeans ever innovated new characters to represent consonant phonemes that did not exist in Phoenician. The first distinctive features of Hebrew writing are actually to be found in ninth-century inscriptions in Moabite, a Canaanite dialect related to Hebrew. According to Naveh (1982), these adaptations of the contemporary Hebrew script represent the first stage of the Hebrew scribal tradition. Despite dialectal differences between the spoken Hebrew of Judah (the 1 Naveh notes that although the calendar can be dated to the late tenth century, the language of this inscription "does not have any lexical or grammatical features that preclude the possibility of its being Phoenician" (1982: 76). southern kingdom) and Israel (the northern kingdom), the same script was used in both kingdoms, as well as by the Moabites and Edomites to write their own kindred languages while under the rule of Israel and Judah. -

Structured Word Inquiry: Developing Literacy and Critical Thinking by Scientific Inquiry About How Spelling Works 1
Structured Word Inquiry: Developing literacy and critical thinking by scientific inquiry about how spelling works 1 Structured Word Inquiry (Scientific Word Investigation) The Joy of Understanding Spelling struct + ure/ + ed → structured in + struct + ion → instruction Peter Bowers, PhD Instruction which builds understanding of WordWorks Literacy Centre, word structure as a tool for investigating 2020 the interrelation of spelling and meaning. www.WordWorksKingston.com Structured Word Inquiry: Developing literacy and critical thinking by scientific inquiry about how spelling works 2 Guides and some basic terms for Structured Word Inquiry A model of English orthography from Real Spelling Guiding Principles of Structured Word Inquiry The primary function of English spelling is to represent meaning. The conventions by which English spelling represents meaning are so well-ordered and reliable that spelling can be investigated and understood through scientific Explore the Real Spelling Tool Box 2 (on-line) for a remarkable linguistic inquiry. reference to study English orthography. Explore the “Morphology Scientific inquiry is necessary to safely guide spelling Album” in the archive of videos learn more about these and many other instruction and understanding. terms and concepts. The film on “Connecting Vowel Letters” is a Scientific inquiry is the only means by which a particularly rich way to make sense of this term that is absent most learning community can safely accept or reject teacher resources. This newly available reference is one you -

The New Polish Cyrillic in Independent Belarus
https://doi.org/10.11649/ch.2019.006 Colloquia Humanistica 8 (2019) Hierarchies and Boundaries. Structuring the Social in Eastern Europe and the Mediterranean COLLOQUIA HUMANISTICA Tomasz Kamusella School of History University of St Andrews St Andrews https://orcid.org/0000-0003-3484-8352 [email protected] The New Polish Cyrillic in Independent Belarus Abstract Aer the fall of communism and the breakup of the Soviet Union, the religious life of the Roman Catholic community revived in independent Belarus. e country’s Catholics are concentrated in western Belarus, which prior to World War II was part of Poland. In 1991 in Hrodna (Horadnia, Grodno) Region, the Diocese of Hrodna was established. Slightly over half of the region’s population are Catholics and many identify as ethnic Poles. Following the ban on the ocial use of Polish in postwar Soviet Belarus, the aforementioned region’s population gained an education in Belarusian and Russian, as channeled through the Cyrillic alphabet. Hence, following the 1991 independence of Belarus, the population’s knowledge of the Latin alphabet was none, or minimal. For the sake of providing the faithful with Polish-language religious material that would be of some practical use, the diocesan authorities decided to publish some Polish-language prayer books, but printed in the Russian-style Cyrillic. is currently widespread use of Cyrillic-based Polish-language publications in Belarus remains unknown outside the country, either in Poland or elsewhere in Europe. Keywords: Belarusian language, Cyrillic, Latin alphabet, Diocese of Hrodna (Horadnia, Grodno), nationalism, Polish language, religion, politics of script, Russian language. -

J32. Journal of the Simplified Spelling
Journal of the Simplified Spelling Society J32, 2003/1. Editor: Steve Bett. Contents. 1. Editorial. Articles. 2. The Two Stage Approach to Spelling Reform. Steve Bett. 3. English Accents and their Implications for Spelling Reform. John C. Wells. 4. How Phonemic is English Spelling? Godfrey Dewey. 5. Could English spelling be made regular without drastic change? Valerie Yule. 6. Orthographic Goals. Steve Bett. 7. Comparing Spelling Schemes. Roy W. Blain. 8. Reform of Chemical Language as a Model for Spelling Reform. Hans-Richard Sliwka. 9. The End of the Reading Wars? Isobel Raven. 10. Review of Jean Meron's Orthotypographie. John M. Gledhill. 11. Letters & Summaries of On-Line Discussions. 12. A Message from the new president: John Wells. 13. Tribute to Don Scragg on his retirement as the Society's president. 14. Inside front cover. We spell a spoken sound in as many as 20 different ways. [Journal of the Simplified Spelling Society, J32, 2003/1, pp2,3 in the printed version.] [Steve Bett: see Journals, Newsletters] 1. Editorial. Steve Bett. Moving from logographic lexical spelling to phonemic spelling. The proposals of the Simplified Spelling Board of 1906 and the Simplified Spelling Society of 1908 were attempts to seek out the lines of least resistance to spelling change. Earlier phonemic spelling associations were thought to advocate reform proposals that were too radical for any popular acceptance. The first compromise, suggested by Alexander Ellis, was to retain the shifted long vowels. In England, this led to the endorsement of New Spelling which became the house style for most internal publications of the society until around 1920. -

A Grammar of Pite Saami
A grammar of Pite Saami Joshua Wilbur language Studies in Diversity Linguistics, No 5 science press A grammar of Pite Saami Pite Saami is a highly endangered Western Saami language in the Uralic language family currently spoken by a few individuals in Swedish Lapland. This grammar is the first extensive book-length treatment of a Saamilan- guage written in English. While focussing on the morphophonology of the main word classes nouns, adjectives and verbs, it also deals with other linguistic structures such as prosody, phonology, phrase types and clauses. Furthermore, it provides an introduction to the language and its speakers, and an outline of a preliminary Pite Saami orthography. An extensive an- notated spoken-language corpus collected over the course of five years forms the empirical foundation for this description, and each example in- cludes a specific reference to the corpus in order to facilitate verification of claims made on the data. Descriptions are presented for a general lin- guistics audience and without attempting to support a specific theoretical approach. This book should be equally useful for scholars of Uralic linguis- tics, typologists, and even learners of Pite Saami. ISBN 978-3-944675-47-3 Joshua Wilbur A grammar of Pite Saami Studies in Diversity Linguistics Chief Editor: Martin Haspelmath Consulting Editors: Fernando Zúñiga, Peter Arkadiev, Ruth Singer, Pilar Valen zuela In this series: 1. Handschuh, Corinna. A typology of marked-S languages 2. Rießler, Michael. Adjective attribution 3. Klamer, Marian (ed.). The Alor-Pantar languages: History and typology 4. Berghäll, Liisa. A grammar of Mauwake (Papua New Guinea) 5. -

The Dynamics of Bilingual Adult Literacy in Africa: a Case Study of Kom, Cameroon
The Dynamics of Bilingual Adult Literacy in Africa: A Case Study of Kom, Cameroon Jean Seraphin Kamdem THESIS SUBMITTED FOR THE DEGREE OF DOCTOR OF PHILOSOPHY School of Oriental and African Studies, University of London. 2010 ProQuest Number: 11015877 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 11015877 Published by ProQuest LLC(2018). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 DECLARATION OF OWNERSHIP I, the undersigned, hereby declare that the work presented in this thesis is my own work and has not been written for me in whole or part by any other person. Signed: J. S. Kamdem 2 | SOA Q lARY ABSTRACT This thesis investigates, describes and analyses adult literacy in local languages in Africa, with a focus on Kom, a rural community situated in the North West province of Cameroon. The thesis presents the motivations, relevance, importance and aims of the research; then gives an overview of the national and local backgrounds, namely Cameroon and Kom. A detailed description is given of the multilingual landscape and language use in formal education, the development of writing systems for Cameroonian languages, the official literacy activities at the national level, and the Kom language and community.