Designing Soft Keyboards for Brahmic Scripts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cross-Language Framework for Word Recognition and Spotting of Indic Scripts
Cross-language Framework for Word Recognition and Spotting of Indic Scripts aAyan Kumar Bhunia, bPartha Pratim Roy*, aAkash Mohta, cUmapada Pal aDept. of ECE, Institute of Engineering & Management, Kolkata, India bDept. of CSE, Indian Institute of Technology Roorkee India cCVPR Unit, Indian Statistical Institute, Kolkata, India bemail: [email protected], TEL: +91-1332-284816 Abstract Handwritten word recognition and spotting of low-resource scripts are difficult as sufficient training data is not available and it is often expensive for collecting data of such scripts. This paper presents a novel cross language platform for handwritten word recognition and spotting for such low-resource scripts where training is performed with a sufficiently large dataset of an available script (considered as source script) and testing is done on other scripts (considered as target script). Training with one source script and testing with another script to have a reasonable result is not easy in handwriting domain due to the complex nature of handwriting variability among scripts. Also it is difficult in mapping between source and target characters when they appear in cursive word images. The proposed Indic cross language framework exploits a large resource of dataset for training and uses it for recognizing and spotting text of other target scripts where sufficient amount of training data is not available. Since, Indic scripts are mostly written in 3 zones, namely, upper, middle and lower, we employ zone-wise character (or component) mapping for efficient learning purpose. The performance of our cross- language framework depends on the extent of similarity between the source and target scripts. -

SC22/WG20 N896 L2/01-476 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale De Normalisation
SC22/WG20 N896 L2/01-476 Universal multiple-octet coded character set International organization for standardization Organisation internationale de normalisation Title: Ordering rules for Khmer Source: Kent Karlsson Date: 2001-12-19 Status: Expert contribution Document type: Working group document Action: For consideration by the UTC and JTC 1/SC 22/WG 20 1 Introduction The Khmer script in Unicode/10646 uses conjoining characters, just like the Indic scripts and Hangul. An alternative that is suitable (and much more elegant) for Khmer, but not for Indic scripts, would have been to have combining- below (and sometimes a bit to the side) consonants and combining-below independent vowels, similar to the combining-above Latin letters recently encoded, as well as how Tibetan is handled. However that is not the chosen solution, which instead uses a combining character (COENG) that makes characters conjoin (glue) like it is done for Indic (Brahmic) scripts and like Hangul Jamo, though the latter does not have a separate gluer character. In the Khmer script, using the COENG based approach, the words are formed from orthographic syllables, where an orthographic syllable has the following structure [add ligation control?]: Khmer-syllable ::= (K H)* K M* where K is a Khmer consonant (most with an inherent vowel that is pronounced only if there is no consonant, independent vowel, or dependent vowel following it in the orthographic syllable) or a Khmer independent vowel, H is the invisible Khmer conjoint former COENG, M is a combining character (including COENG, though that would be a misspelling), in particular a combining Khmer vowel (noted A below) or modifier sign. -

POSTLUDE P.1 Letter Frequencies
POSTLUDE A Prelude opened this textbook with the puzzle Mastermind that introduced combinatorial reasoning in a recreational setting. This Postlude looks at a cryptanalysis problem that is again of a recreational nature but also illustrates the less structured side of combinatorial reasoning as it often occurs in real-world problems. In particular, we will look at a simple cryptographic scheme in which the analysis of underlying combinatorial problems is complicated by the somewhat random pattern of letters in English text. P.1 Letter Frequencies There have been many tables produced of the relative frequencies of letters in English writing, starting with Samuel Morse (of Morse code fame). We use frequencies averaged over several tables. Most Common Letters in English Text Vowels Consonants E 12% T 9% A, I, O 8 % N, R, S 6-8% D, L 4% The least frequent letters, all consonants, are: J, Q, X, Z below .05% As we shall see, it is also useful to know which pairs of consecutive letters, called digraphs, are most frequent. The eight most common digraphs are Most frequent: TH Second most frequent: HE Next six most frequent: ER, RE and AN, EN, IN, ON N is unique among the very frequent letters in that close to 90% of its occurrences are preceded by a vowel; other frequent letters have a much wider range of other letters preceding them. Some other frequent digraphs that can be helpful are: ES, SE ED, DE ST TE, TI, TO OF Frequent consonants tend to appear beside vowels but vowels do not occur side-by-side often and similarly frequent consonants do not appear side-by-side often except for TH and ST. -

VSI Openvms C Language Reference Manual
VSI OpenVMS C Language Reference Manual Document Number: DO-VIBHAA-008 Publication Date: May 2020 This document is the language reference manual for the VSI C language. Revision Update Information: This is a new manual. Operating System and Version: VSI OpenVMS I64 Version 8.4-1H1 VSI OpenVMS Alpha Version 8.4-2L1 Software Version: VSI C Version 7.4-1 for OpenVMS VMS Software, Inc., (VSI) Bolton, Massachusetts, USA C Language Reference Manual Copyright © 2020 VMS Software, Inc. (VSI), Bolton, Massachusetts, USA Legal Notice Confidential computer software. Valid license from VSI required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The information contained herein is subject to change without notice. The only warranties for VSI products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. VSI shall not be liable for technical or editorial errors or omissions contained herein. HPE, HPE Integrity, HPE Alpha, and HPE Proliant are trademarks or registered trademarks of Hewlett Packard Enterprise. Intel, Itanium and IA64 are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. Java, the coffee cup logo, and all Java based marks are trademarks or registered trademarks of Oracle Corporation in the United States or other countries. Kerberos is a trademark of the Massachusetts Institute of Technology. -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display. -

Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset
Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset Brian Roarky, Lawrence Wolf-Sonkiny, Christo Kirovy, Sabrina J. Mielkez, Cibu Johnyy, Işın Demirşahiny and Keith Hally yGoogle Research zJohns Hopkins University {roark,wolfsonkin,ckirov,cibu,isin,kbhall}@google.com [email protected] Abstract This paper describes the Dakshina dataset, a new resource consisting of text in both the Latin and native scripts for 12 South Asian languages. The dataset includes, for each language: 1) native script Wikipedia text; 2) a romanization lexicon; and 3) full sentence parallel data in both a native script of the language and the basic Latin alphabet. We document the methods used for preparation and selection of the Wikipedia text in each language; collection of attested romanizations for sampled lexicons; and manual romanization of held-out sentences from the native script collections. We additionally provide baseline results on several tasks made possible by the dataset, including single word transliteration, full sentence transliteration, and language modeling of native script and romanized text. Keywords: romanization, transliteration, South Asian languages 1. Introduction lingua franca, the prevalence of loanwords and code switch- Languages in South Asia – a region covering India, Pak- ing (largely but not exclusively with English) is high. istan, Bangladesh and neighboring countries – are generally Unlike translations, human generated parallel versions of written with Brahmic or Perso-Arabic scripts, but are also text in the native scripts of these languages and romanized often written in the Latin script, most notably for informal versions do not spontaneously occur in any meaningful vol- communication such as within SMS messages, WhatsApp, ume. -
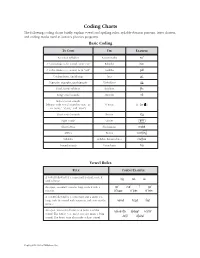
Phonics TRB Coding Chart
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss. -

Simplified Abugidas
Simplified Abugidas Chenchen Ding, Masao Utiyama, and Eiichiro Sumita Advanced Translation Technology Laboratory, Advanced Speech Translation Research and Development Promotion Center, National Institute of Information and Communications Technology 3-5 Hikaridai, Seika-cho, Soraku-gun, Kyoto, 619-0289, Japan fchenchen.ding, mutiyama, [email protected] phonogram segmental abjad Abstract writing alphabet system An abugida is a writing system where the logogram syllabic abugida consonant letters represent syllables with Figure 1: Hierarchy of writing systems. a default vowel and other vowels are de- noted by diacritics. We investigate the fea- ណូ ន ណណន នួន ននន …ជិតណណន… sibility of recovering the original text writ- /noon/ /naen/ /nuən/ /nein/ vowel machine ten in an abugida after omitting subordi- diacritic omission learning ណន នន methods nate diacritics and merging consonant let- consonant character ters with similar phonetic values. This is merging N N … J T N N … crucial for developing more efficient in- (a) ABUGIDA SIMPLIFICATION (b) RECOVERY put methods by reducing the complexity in abugidas. Four abugidas in the south- Figure 2: Overview of the approach in this study. ern Brahmic family, i.e., Thai, Burmese, ters equally. In contrast, abjads (e.g., the Arabic Khmer, and Lao, were studied using a and Hebrew scripts) do not write most vowels ex- newswire 20; 000-sentence dataset. We plicitly. The third type, abugidas, also called al- compared the recovery performance of a phasyllabary, includes features from both segmen- support vector machine and an LSTM- tal and syllabic systems. In abugidas, consonant based recurrent neural network, finding letters represent syllables with a default vowel, that the abugida graphemes could be re- and other vowels are denoted by diacritics. -

English Literacy Dossier
English Literacy Dossier Myriam Cherro Samper Javier Fernández Molina Manuel Sánchez Quero 1 ISBN: 978-84-09-19463-6 ENGLISH PHONETICS. INTRODUCTION TO THE SOUNDS OF ENGLISH AND THEIR REPRESENTATION. 1. ENGLISH PHONETICS. INTRODUCTION TO THE SOUNDS OF ENGLISH AND THEIR REPRESENTATION. ... 4 1.1 Definition of Language. ................................................................................................................... 4 1.1.1 Roman Jakobson’s Function of Language Theory .......................................................................... 6 1.2 What Is Linguistics?................................................................................................................................ 7 1.2.1 Linguistic Branches ........................................................................................................................ 8 1.2.2 Phonemes vs. Allophones .............................................................................................................. 8 1.2.3 Phonetics vs. Phonology ................................................................................................................ 9 1.2.4 Minimal Pairs ............................................................................................................................... 10 1.2.5 Homophone vs. Homographs ....................................................................................................... 10 1.3 The English Alphabet. ......................................................................................................................... -

Lunyole Grammar; It Does Not Attempt to Make a Statement for Or Against a Particular Formal Linguistic Theory
A PARTIAL GRAMMAR SKETCH OF LUNYOLE WITH EMPHASIS ON THE APPLICATIVE CONSTRUCTION(S) _______________________ A Thesis Presented to The Faculty of the School of Intercultural Studies Department of Applied Linguistics & TESOL Biola University _______________________ In Partial Fulfillment of the Requirements for the Degree Master of Arts in Applied Linguistics _______________________ by Douglas Allen Wicks May 2006 ABSTRACT A PARTIAL GRAMMAR SKETCH OF LUNYOLE WITH EMPHASIS ON THE APPLICATIVE CONSTRUCTION(S) Douglas Allen Wicks This thesis provides a general grammatical description of Lunyole, a Bantu language of Eastern Uganda. After a brief description of the phonology, it describes the morphology and basic syntax of Lunyole, following Payne’s (1997) functional approach. This thesis then more deeply describes Lunyole’s applicative constructions in which an argument is added to the verb complex. Lunyole has two applicative marking constructions. The more productive one uses the -ir suffix on verbs of any valence in conjunction with a wide range of semantic roles. The other applicative construction is formed from a locative class prefix and is used only for locative arguments on unaccusative intransitive verbs. Similar locative morphemes may co-occur with the -ir applicative morpheme, but not as applicative markers; instead they clarify the relationship between arguments. TABLE OF CONTENTS PAGE List of Tables ..................................................................................................................... ix List of Figures......................................................................................................................x -

How Children Learn to Write Words
How Children Learn to Write Words How Children Learn to Write Words Rebecca TReiman and bReTT KessleR 1 3 Oxford University Press is a department of the University of Oxford. It furthers the University’s objective of excellence in research, scholarship, and education by publishing worldwide. Oxford New York Auckland Cape Town Dar es Salaam Hong Kong Karachi Kuala Lumpur Madrid Melbourne Mexico City Nairobi New Delhi Shanghai Taipei Toronto With offices in Argentina Austria Brazil Chile Czech Republic France Greece Guatemala Hungary Italy Japan Poland Portugal Singapore South Korea Switzerland Thailand Turkey Ukraine Vietnam Oxford is a registered trademark of Oxford University Press in the UK and certain other countries. Published in the United States of America by Oxford University Press 198 Madison Avenue, New York, NY 10016 © Oxford University Press 2014 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, without the prior permission in writing of Oxford University Press, or as expressly permitted by law, by license, or under terms agreed with the appropriate reproduction rights organization. Inquiries concerning reproduction outside the scope of the above should be sent to the Rights Department, Oxford University Press, at the address above. You must not circulate this work in any other form and you must impose this same condition on any acquirer. A copy of this book’s Catalog-in-Publication Data is on file with the Library of Congress ISBN 978–0–19–990797–7 -

ADAPTATIONS of HEBREW SCRIPT in This Chapter I Present An
CHAPTER TWO FROM ARAMEA TO AMERICA: ADAPTATIONS OF HEBREW SCRIPT In this chapter I present an overview of the development of the Hebrew writing system, followed by a survey of language families with attested Hebrew-letter texts. While I aim to provide a broader and more inclusive overview of Hebraicization than has been available previously, I do not make any claim to comprehensiveness. 1. FROM HEBREW TO JEWISH WRITING Nothing is known of Hebraic writing before the Israelites emerged in the land of Canaan and "borrowed the art of writing" from the local inhabitants in the twelfth or eleventh century BCE (Naveh 1982: 65). In the earliest known Hebrew inscription, the Gezer calendar,1 the writing resembles that of tenth-century Phoenician inscriptions from Byblos, and features no specifically Hebrew characters. Indeed, the Phoenician influence was so dominant that neither the Hebrews nor the Aramaeans ever innovated new characters to represent consonant phonemes that did not exist in Phoenician. The first distinctive features of Hebrew writing are actually to be found in ninth-century inscriptions in Moabite, a Canaanite dialect related to Hebrew. According to Naveh (1982), these adaptations of the contemporary Hebrew script represent the first stage of the Hebrew scribal tradition. Despite dialectal differences between the spoken Hebrew of Judah (the 1 Naveh notes that although the calendar can be dated to the late tenth century, the language of this inscription "does not have any lexical or grammatical features that preclude the possibility of its being Phoenician" (1982: 76). southern kingdom) and Israel (the northern kingdom), the same script was used in both kingdoms, as well as by the Moabites and Edomites to write their own kindred languages while under the rule of Israel and Judah.