Translating Embeddings for Knowledge Graph Completion with Relation Attention Mechanism
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

8 December 2004 (Revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California
To: LSA and UC Berkeley Communities From: Deborah Anderson, UCB representative and LSA liaison Date: 8 December 2004 (revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California As the UC Berkeley representative and LSA liaison, I am most interested in the proposals for new characters and scripts that were discussed at the UTC, so these topics are the focus of this report. For the full minutes, readers should consult the "Unicode Technical Committee Minutes" web page (http://www.unicode.org/consortum/utc-minutes.html), where the minutes from this meeting will be posted several weeks hence. I. Proposals for New Scripts and Additional Characters A summary of the proposals and the UTC's decisions are listed below. As the proposals discussed below are made public, I will post the URLs on the SEI web page (www.linguistics.berkeley.edu/sei). A. Linguistics Characters Lorna Priest of SIL International submitted three proposals for additional linguistics characters. Most of the characters proposed are used in the orthographies of languages from Africa, Asia, Mexico, Central and South America. (For details on the proposed characters, with a description of their use and an image, see the appendix to this document.) Two characters from these proposals were not approved by the UTC because there are already characters encoded that are very similar. The evidence did not adequately demonstrate that the proposed characters are used distinctively. The two problematical proposed characters were: the modifier straight letter apostrophe (used for a glottal stop, similar to ' APOSTROPHE U+0027) and the Latin small "at" sign (used for Arabic loanwords in an orthography for the Koalib language from the Sudan, similar to @ COMMERCIAL AT U+0040). -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

The Coinage of Akragas C
ACTA UNIVERSITATIS UPSALIENSIS Studia Numismatica Upsaliensia 6:1 STUDIA NUMISMATICA UPSALIENSIA 6:1 The Coinage of Akragas c. 510–406 BC Text and Plates ULLA WESTERMARK I STUDIA NUMISMATICA UPSALIENSIA Editors: Harald Nilsson, Hendrik Mäkeler and Ragnar Hedlund 1. Uppsala University Coin Cabinet. Anglo-Saxon and later British Coins. By Elsa Lindberger. 2006. 2. Münzkabinett der Universität Uppsala. Deutsche Münzen der Wikingerzeit sowie des hohen und späten Mittelalters. By Peter Berghaus and Hendrik Mäkeler. 2006. 3. Uppsala universitets myntkabinett. Svenska vikingatida och medeltida mynt präglade på fastlandet. By Jonas Rundberg and Kjell Holmberg. 2008. 4. Opus mixtum. Uppsatser kring Uppsala universitets myntkabinett. 2009. 5. ”…achieved nothing worthy of memory”. Coinage and authority in the Roman empire c. AD 260–295. By Ragnar Hedlund. 2008. 6:1–2. The Coinage of Akragas c. 510–406 BC. By Ulla Westermark. 2018 7. Musik på medaljer, mynt och jetonger i Nils Uno Fornanders samling. By Eva Wiséhn. 2015. 8. Erik Wallers samling av medicinhistoriska medaljer. By Harald Nilsson. 2013. © Ulla Westermark, 2018 Database right Uppsala University ISSN 1652-7232 ISBN 978-91-513-0269-0 urn:nbn:se:uu:diva-345876 (http://urn.kb.se/resolve?urn=urn:nbn:se:uu:diva-345876) Typeset in Times New Roman by Elin Klingstedt and Magnus Wijk, Uppsala Printed in Sweden on acid-free paper by DanagårdLiTHO AB, Ödeshög 2018 Distributor: Uppsala University Library, Box 510, SE-751 20 Uppsala www.uu.se, [email protected] The publication of this volume has been assisted by generous grants from Uppsala University, Uppsala Sven Svenssons stiftelse för numismatik, Stockholm Gunnar Ekströms stiftelse för numismatisk forskning, Stockholm Faith and Fred Sandstrom, Haverford, PA, USA CONTENTS FOREWORDS ......................................................................................... -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -
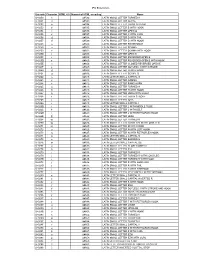
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

African Fonts and Open Source
African fonts and Open Source Denis Moyogo Jacquerye September 17th 2008 ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 1 African fonts and Open Source Denis Moyogo Jacquerye African fonts and Open Source This talk is about: ● African Orthographies (relevance, groups, requirements) ● Technologies for them (Unicode, OpenType) ● Implementation ● Raise awareness and interest ● Case for Open Source ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 2 African fonts and Open Source Denis Moyogo Jacquerye Speaker Denis Moyogo Jacquerye ● Computer Scientist and Linguist ● Africanization consultant ● DejaVu Fonts co-leader ● African Network for Localization (ANLoc) ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 3 African fonts and Open Source Denis Moyogo Jacquerye ANLoc African fonts work part of ANLoc project ● Facilitate localization ● Empowering through ICT ● Network of experts ● Sub-projects: Locales, Keyboards, Fonts, Spell checkers, Terminology, Training, Localization software, Policy. ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 4 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Lots of African languages (over 2000) ● 25 spoken by about half ● 80% don't have orthographies ● 20% do! ● Can emulate! ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 5 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Used every day by most ● Education is mostly in European language ● Used in spoken media ● Interest is rising ATypI ‘o8 Conference St. Petersburg, -

L2/06-036: Proposal to Encode Characters for Ordbok Över Finlands
ISO/IEC JTC 1/SC 2/WG 2 PROPOSAL SUMMARY FORM TO ACCOMPANY SUBMISSIONS 1 FOR ADDITIONS TO THE REPERTOIRE OF ISO/IEC 10646TP PT Please fill all the sections A, B and C below. Please read Principles and Procedures Document (P & P) from http://www.dkuug.dk/JTC1/SC2/WG2/docs/principles.htmlHTU UTH for guidelines and details before filling this form. Please ensure you are using the latest Form from http://www.dkuug.dk/JTC1/SC2/WG2/docs/summaryform.htmlHTU .UTH See also http://www.dkuug.dk/JTC1/SC2/WG2/docs/roadmaps.htmlHTU UTH for latest Roadmaps. A. Administrative 1. Title: Proposal to encode characters for Ordbok över Finlands svenska folkmål in the UCS 2. Requester's name: Therese Leinonen, Klaas Ruppel, Erkki I. Kolehmainen, Caroline Sandström 3. Requester type (Member body/Liaison/Individual contribution): Member Body 4. Submission date: 2006-01-26 5. Requester's reference (if applicable): 6. Choose one of the following: This is a complete proposal: YES (or) More information will be provided later: NO B. Technical – General 1. Choose one of the following: a. This proposal is for a new script (set of characters): NO Proposed name of script: b. The proposal is for addition of character(s) to an existing block: YES Name of the existing block: Phonetic Extensions Supplement 2. Number of characters in proposal: 3 3. Proposed category (select one from below - see section 2.2 of P&P document): A-Contemporary B.1-Specialized (small collection) B.2-Specialized (large collection) X C-Major extinct D-Attested extinct E-Minor extinct F-Archaic Hieroglyphic or Ideographic G-Obscure or questionable usage symbols 4. -

MUFI Character Recommendation V. 3.0: Code Chart Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 2: Code chart order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-403-9 MUFI character recommendation ※ Part 2: code chart order version 3.0 p. 2 / 245 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). There are also 18 characters which have been decommissioned from the Private Use Area due to the fact that they have been included in later versions of the Unicode Standard (and, in one case, because a character has been withdrawn). -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

The Brill Typeface User Guide & Complete List of Characters
The Brill Typeface User Guide & Complete List of Characters Version 2.06, October 31, 2014 Pim Rietbroek Preamble Few typefaces – if any – allow the user to access every Latin character, every IPA character, every diacritic, and to have these combine in a typographically satisfactory manner, in a range of styles (roman, italic, and more); even fewer add full support for Greek, both modern and ancient, with specialised characters that papyrologists and epigraphers need; not to mention coverage of the Slavic languages in the Cyrillic range. The Brill typeface aims to do just that, and to be a tool for all scholars in the humanities; for Brill’s authors and editors; for Brill’s staff and service providers; and finally, for anyone in need of this tool, as long as it is not used for any commercial gain.* There are several fonts in different styles, each of which has the same set of characters as all the others. The Unicode Standard is rigorously adhered to: there is no dependence on the Private Use Area (PUA), as it happens frequently in other fonts with regard to characters carrying rare diacritics or combinations of diacritics. Instead, all alphabetic characters can carry any diacritic or combination of diacritics, even stacked, with automatic correct positioning. This is made possible by the inclusion of all of Unicode’s combining characters and by the application of extensive OpenType Glyph Positioning programming. Credits The Brill fonts are an original design by John Hudson of Tiro Typeworks. Alice Savoie contributed to Brill bold and bold italic. The black-letter (‘Fraktur’) range of characters was made by Karsten Lücke. -

MSR-4: Annotated Repertoire Tables, Non-CJK
Maximal Starting Repertoire - MSR-4 Annotated Repertoire Tables, Non-CJK Integration Panel Date: 2019-01-25 How to read this file: This file shows all non-CJK characters that are included in the MSR-4 with a yellow background. The set of these code points matches the repertoire specified in the XML format of the MSR. Where present, annotations on individual code points indicate some or all of the languages a code point is used for. This file lists only those Unicode blocks containing non-CJK code points included in the MSR. Code points listed in this document, which are PVALID in IDNA2008 but excluded from the MSR for various reasons are shown with pinkish annotations indicating the primary rationale for excluding the code points, together with other information about usage background, where present. Code points shown with a white background are not PVALID in IDNA2008. Repertoire corresponding to the CJK Unified Ideographs: Main (4E00-9FFF), Extension-A (3400-4DBF), Extension B (20000- 2A6DF), and Hangul Syllables (AC00-D7A3) are included in separate files. For links to these files see "Maximal Starting Repertoire - MSR-4: Overview and Rationale". How the repertoire was chosen: This file only provides a brief categorization of code points that are PVALID in IDNA2008 but excluded from the MSR. For a complete discussion of the principles and guidelines followed by the Integration Panel in creating the MSR, as well as links to the other files, please see “Maximal Starting Repertoire - MSR-4: Overview and Rationale”. Brief description of exclusion -

Proposed Mapping of Extipa and Modifier Phonetic Characters Kirk Miller, [email protected] 2020 April 14
Proposed mapping of extIPA and modifier phonetic characters Kirk Miller, [email protected] 2020 April 14 Per Script Ad Hoc Committee, 10780–107BF could be allocated to Latin. Mike Everson would like to draw characters. We will need to send a font to Unicode. Latin Extended-D U+A7C0, C1 still available? ...0 ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...A ...B ...C ...D ...E ...F Latin D block U+A7Cx U+A7Dx U+A7Ex U+A7Fx Latin E block U+AB6x Combining Diacritical Marks Extended U+1ACx ◌ ◌ ◌ ◌ U+1ADx U+1AEx U+1AFx Supplementary plain U+1078x U+1079x U+107Ax U+107Bx U+A7C0? LATIN LETTER SMALL CAPITAL TURNED L U+A7C1? or sup plane so turned U could join it? LATIN LETTER SMALL CAPITAL TURNED K LATIN SMALL LETTER O WITH RETROFLEX HOOK. Figure 15. LATIN SMALL LETTER I WITH STROKE AND RETROFLEX HOOK. Figure 16. LATIN SMALL LETTER TESH DIGRAPH WITH RETROFLEX HOOK. Figure 14. LATIN SMALL LETTER L WITH BELT AND PALATAL HOOK. Figure 23. LATIN SMALL LETTER ENG WITH PALATAL HOOK. Figure 24. LATIN SMALL LETTER TURNED R WITH PALATAL HOOK. Figures 17–19. ... LATIN SMALL LETTER R WITH FISHHOOK AND PALATAL HOOK. Figure 19. LATIN SMALL LETTER EZH WITH PALATAL HOOK. Figures 20–21. LATIN SMALL LETTER DEZH DIGRAPH WITH PALATAL HOOK. Figure 22. LATIN SMALL LETTER TESH DIGRAPH WITH PALATAL HOOK. Figure 22. LEFT SQUARE BRACKET WITH STROKE. Figures 11, 13. RIGHT SQUARE BRACKET WITH STROKE. Figures 11, 13. LEFT SQUARE BRACKET WITH DOUBLE STROKE. Figures 11, 14. RIGHT SQUARE BRACKET WITH DOUBLE STROKE.