Integrating Automatic Transcription Into the Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tone in Yongning Na: Lexical Tones and Morphotonology Alexis Michaud
Tone in Yongning Na: lexical tones and morphotonology Alexis Michaud To cite this version: Alexis Michaud. Tone in Yongning Na: lexical tones and morphotonology. Language Science Press, 13, 2017, Studies in Diversity Linguistics, Haspelmath, Martin, 978-3-946234-86-9. 10.5281/zen- odo.439004. halshs-01094049v6 HAL Id: halshs-01094049 https://halshs.archives-ouvertes.fr/halshs-01094049v6 Submitted on 26 Apr 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Tone in Yongning Na Lexical tones and morphotonology Alexis Michaud language Studies in Diversity Linguistics 13 science press Studies in Diversity Linguistics Chief Editor: Martin Haspelmath Consulting Editors: Fernando Zúñiga, Peter Arkadiev, Ruth Singer, Pilar Valen zuela In this series: 1. Handschuh, Corinna. A typology of marked-S languages. 2. Rießler, Michael. Adjective attribution. 3. Klamer, Marian (ed.). The Alor-Pantar languages: History and typology. 4. Berghäll, Liisa. A grammar of Mauwake (Papua New Guinea). 5. Wilbur, Joshua. A grammar of Pite Saami. 6. Dahl, Östen. Grammaticalization in the North: Noun phrase morphosyntax in Scandinavian vernaculars. 7. Schackow, Diana. A grammar of Yakkha. 8. -

第四届中国西南地区汉藏语国际研讨会program and Abstract Book
FOURTH WORKSHOP ON SINO-TIBETAN LANGUAGES OF SOUTHWEST CHINA 第四届中国西南地区汉藏语国际研讨会 UNIVERSITY OF WASHINGTON, SEATTLE SEPTEMBER 8-10, 2016 PROGRAM AND ABSTRACT BOOK Table of Contents General Information & Special Thanks to Our Sponsors ......................................................... 3 Program Synoptic Schedule ..................................................................................................................... 4 Thursday, September 8 .............................................................................................................. 5 Friday, September 9 ................................................................................................................... 6 Saturday, September 10 ............................................................................................................. 7 Abstracts (in presentation order) Scott DeLancey, Reconstructing Hierarchical Argument Indexation in Trans-Himalayan .... 8 James A. Matisoff, Lahu in the 21st century: vocabulary enrichment and orthographical issues ........................................................................................................................................ 10 Guillaume Jacques, The life cycle of multiple indexation and bipartite verbs in Sino-Tibetan ................................................................................................................................................. 11 Jackson T.-S. SUN and Qianzi TIAN, Argument Indexation patterns in Horpa languages: a major Rgyalrongic subgroup .................................................................................................. -
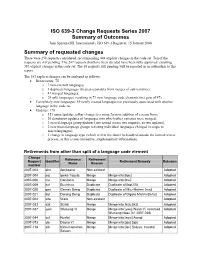
2007 Series Change Requests Report
ISO 639-3 Change Requests Series 2007 Summary of Outcomes Joan Spanne (SIL International), ISO 639-3 Registrar, 15 January 2008 Summary of requested changes There were 258 requests considered, recommending 404 explicit changes in the code set. Ten of the requests are still pending. The 247 requests that have been decided have been fully approved, entailing 383 explicit changes in the code set. The 10 requests still pending will be reported in an addendum to this report. The 383 explicit changes can be analyzed as follows: • Retirements: 75 o 7 non-existent languages; o 3 duplicate languages (treated separately from merges of sub-varieties); o 41 merged languages; o 24 split languages, resulting in 71 new language code elements (net gain of 47). • Completely new languages: 59 newly created languages not previously associated with another language in the code set. • Updates: 178 o 151 name updates, either change to a name form or addition of a name form; o 20 denotation updates of languages into which other varieties were merged; o 3 macrolanguage group updates (one spread across two requests, as two updates); o 2 new macrolanguage groups (existing individual languages changed in scope to macrolanguages); o 1 change in language type (which will in the future be handled outside the formal review process, as this is non-normative, supplementary information). Retirements from other than split of a language code element Change Reference Retirement Request Identifier Retirement Remedy Outcome Name Reason number 2007-003 akn Amikoana Non-existent Adopted 2007-004 paj Ipeka-Tapuia Merge Merge into [kpc] Adopted 2007-006 cru Carútana Merge Merge into [bwi] Adopted 2007-009 bxt Buxinhua Duplicate Duplicate of [bgk] Bit Adopted 2007-020 gen Geman Deng Duplicate Duplicate of Miju-Mishmi [mxj] Adopted 2007-021 dat Darang Deng Duplicate Duplicate of Digaro Mishmi [mhu] Adopted 2007-024 wre Ware Non-existent Adopted 2007-033 szk Sizaki Merge Merge into Ikizu [ikz] Adopted 2007-037 ywm Wumeng Yi Merge Merge into [ywu] Wusa Yi, renamed Adopted Wumeng Nasu (cf. -

Review of Tone in Yongning Na: Lexical Tones and Morphotonology by Alexis Michaud
Journal of the Southeast Asian Linguistics Society JSEALS Vol. 10.2 (2017): xxx-xxxiv ISSN: 1836-6821, DOI: http://hdl.handle.net/10524/52412 University of Hawaiʼi Press REVIEW OF TONE IN YONGNING NA: LEXICAL TONES AND MORPHOTONOLOGY BY ALEXIS MICHAUD Mark J. Alves Montgomery College [email protected] Tone in Yongning Na: Lexical Tones and Morphotonology (Berlin: Language Science Press, Studies in Diversity Linguistics 13, 2017, ISBN 978-3-946234-87-6 (hardcover)), by Alexis Michaud, describes both lexical tones and phonological tonal rules in the Naish (ISO 639-3 naic1235) Yongning Na language (ISO 639-3 nru). Michaud claims that his aim is a “detailed description of a level-tone system,” making this work a significant contribution as even among tonal Bantu language studies, as the author notes, it is rare to see entire books devoted to description of such systems. For this undertaking, Michaud has spent a tremendous amount of time over the last decade doing fieldwork on, intensively analyzing various aspects of, and writing about the phonology of Yongning Na, a Sino-Tibetan language spoken by some 47,000 people living in an area bordering Sichuan and Yunnan provinces of southwest China. Over that extended period of research, he has authored some two dozen linguistics articles on Na (including several co-authored works, mostly written in English but also in French and Chinese), a Na-English-Chinese dictionary, numerous Na language recordings efficiently laid out to facilitate study by others (in the online PanGloss collection), and now this massive 600-page volume on the Na language. -

The Neolithic Ofsouthern China-Origin, Development, and Dispersal
The Neolithic ofSouthern China-Origin, Development, and Dispersal ZHANG CHI AND HSIAO-CHUN HUNG INTRODUCTION SANDWICHED BETWEEN THE YELLOW RIVER and Mainland Southeast Asia, southern China1 lies centrally within eastern Asia. This geographical area can be divided into three geomorphological terrains: the middle and lower Yangtze allu vial plain, the Lingnan (southern Nanling Mountains)-Fujian region,2 and the Yungui Plateau3 (Fig. 1). During the past 30 years, abundant archaeological dis coveries have stimulated a rethinking of the role ofsouthern China in the prehis tory of China and Southeast Asia. This article aims to outline briefly the Neolithic cultural developments in the middle and lower Yangtze alluvial plain, to discuss cultural influences over adjacent regions and, most importantly, to examine the issue of southward population dispersal during this time period. First, we give an overview of some significant prehistoric discoveries in south ern China. With the discovery of Hemudu in the mid-1970s as the divide, the history of archaeology in this region can be divided into two phases. The first phase (c. 1920s-1970s) involved extensive discovery, when archaeologists un earthed Pleistocene human remains at Yuanmou, Ziyang, Liujiang, Maba, and Changyang, and Palaeolithic industries in many caves. The major Neolithic cul tures, including Daxi, Qujialing, Shijiahe, Majiabang, Songze, Liangzhu, and Beiyinyangying in the middle and lower Yangtze, and several shell midden sites in Lingnan, were also discovered in this phase. During the systematic research phase (1970s to the present), ongoing major ex cavation at many sites contributed significantly to our understanding of prehis toric southern China. Additional early human remains at Wushan, Jianshi, Yun xian, Nanjing, and Hexian were recovered together with Palaeolithic assemblages from Yuanmou, the Baise basin, Jianshi Longgu cave, Hanzhong, the Li and Yuan valleys, Dadong and Jigongshan. -

A Study from the Perspectives of Shared Innovation
SUBGROUPING OF NISOIC (YI) LANGUAGES: A STUDY FROM THE PERSPECTIVES OF SHARED INNOVATION AND PHYLOGENETIC ESTIMATION by ZIWO QIU-FUYUAN LAMA Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT ARLINGTON May 2012 Copyright © by Ziwo Qiu-Fuyuan Lama 2012 All Rights Reserved To my parents: Qiumo Rico and Omu Woniemo Who have always wanted me to stay nearby, but they have also wished me to go my own way! ACKNOWLEDGEMENTS The completion of this dissertation could not have happened without the help of many people; I own much gratitude to these people and I would take this moment to express my heartfelt thanks to them. First, I wish to express my deep thanks to my supervisor, Professor Jerold A Edmondson, whose guidance, encouragement, and support from the beginning to the final page of this dissertation. His direction showed me the pathway of the writing of this dissertation, especially, while working on chapter of phylogenetic study of this dissertation, he pointed out the way to me. Secondly, I would like to thank my other committee members: Dr. Laurel Stvan, Dr. Michael Cahill, and Dr. David Silva. I wish to thank you very much for your contribution to finishing this dissertation. Your comments and encouragement were a great help. Third, I would like to thank my language informants and other people who helped me during my field trip to China in summer 2003, particularly ZHANF Jinzhi, SU Wenliang, PU Caihong, LI Weibing, KE Fu, ZHAO Hongying, ZHOU Decai, SHI Zhengdong, ZI Wenqing, and ZUO Jun. -

In and out of Suriname Caribbean Series
In and Out of Suriname Caribbean Series Series Editors Rosemarijn Hoefte (Royal Netherlands Institute of Southeast Asian and Caribbean Studies) Gert Oostindie (Royal Netherlands Institute of Southeast Asian and Caribbean Studies) Editorial Board J. Michael Dash (New York University) Ada Ferrer (New York University) Richard Price (em. College of William & Mary) Kate Ramsey (University of Miami) VOLUME 34 The titles published in this series are listed at brill.com/cs In and Out of Suriname Language, Mobility and Identity Edited by Eithne B. Carlin, Isabelle Léglise, Bettina Migge, and Paul B. Tjon Sie Fat LEIDEN | BOSTON This is an open access title distributed under the terms of the Creative Commons Attribution-Noncommercial 3.0 Unported (CC-BY-NC 3.0) License, which permits any non-commercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited. The realization of this publication was made possible by the support of KITLV (Royal Netherlands Institute of Southeast Asian and Caribbean Studies). Cover illustration: On the road. Photo by Isabelle Léglise. This publication has been typeset in the multilingual “Brill” typeface. With over 5,100 characters covering Latin, IPA, Greek, and Cyrillic, this typeface is especially suitable for use in the humanities. For more information, please see www.brill.com/brill-typeface issn 0921-9781 isbn 978-90-04-28011-3 (hardback) isbn 978-90-04-28012-0 (e-book) Copyright 2015 by the Editors and Authors. This work is published by Koninklijke Brill NV. Koninklijke Brill NV incorporates the imprints Brill, Brill Nijhoff and Hotei Publishing. Koninklijke Brill NV reserves the right to protect the publication against unauthorized use and to authorize dissemination by means of offprints, legitimate photocopies, microform editions, reprints, translations, and secondary information sources, such as abstracting and indexing services including databases. -

Prayer Cards | Joshua Project
Pray for the Nations Pray for the Nations A Che in China A'ou in China Population: 43,000 Population: 2,800 World Popl: 43,000 World Popl: 2,800 Total Countries: 1 Total Countries: 1 People Cluster: Tibeto-Burman, other People Cluster: Tai Main Language: Ache Main Language: Chinese, Mandarin Main Religion: Ethnic Religions Main Religion: Ethnic Religions Status: Unreached Status: Unreached Evangelicals: 0.00% Evangelicals: 0.00% Chr Adherents: 0.00% Chr Adherents: 0.00% Scripture: Translation Needed Scripture: Complete Bible www.joshuaproject.net Source: Operation China, Asia Harvest www.joshuaproject.net Source: Operation China, Asia Harvest "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations A-Hmao in China Achang in China Population: 458,000 Population: 35,000 World Popl: 458,000 World Popl: 74,000 Total Countries: 1 Total Countries: 2 People Cluster: Miao / Hmong People Cluster: Tibeto-Burman, other Main Language: Miao, Large Flowery Main Language: Achang Main Religion: Christianity Main Religion: Ethnic Religions Status: Significantly reached Status: Partially reached Evangelicals: 75.0% Evangelicals: 7.0% Chr Adherents: 80.0% Chr Adherents: 7.0% Scripture: Complete Bible Scripture: Complete Bible www.joshuaproject.net www.joshuaproject.net Source: Anonymous Source: Wikipedia "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Achang, Husa in China Adi -

A Sociolinguistic Survey of Humla Tibetan in Northwest Nepal
DigitalResources Electronic Survey Report 2020-013 A Sociolinguistic Survey of Humla Tibetan in Northwest Nepal Klaas de Vries A Sociolinguistic Survey of Humla Tibetan in Northwest Nepal Klaas de Vries SIL International® 2020 SIL Electronic Survey Report 2020-013, Month 2020 © 2020 SIL International® All rights reserved Data and materials collected by researchers in an era before documentation of permission was standardized may be included in this publication. SIL makes diligent efforts to identify and acknowledge sources and to obtain appropriate permissions wherever possible, acting in good faith and on the best information available at the time of publication. Abstract The Humla Tibetan language [hut], spoken in the far northwest of Nepal, has received little scholarly attention. This report presents the results of sociolinguistic research conducted among the Tibetan- speaking communities in Humla District. The main goal of this research is to describe the primary dialect areas and investigate the relationships between them. Other goals are investigation of the ethnolinguistic identity, assessment of language vitality, and understanding of the desires for development of the communities. In 2012 and 2013, three fieldwork trips were undertaken for data collection. During these trips seven sociolinguistic tools were used. These were wordlists, informal interviews, knowledgeable insider questionnaires, Recorded Story Questions, observation schedule, and two participatory method tools, namely Dialect Mapping and Appreciative Inquiry. This research found that the different speech varieties among the Tibetan-speaking villages of Humla District should be seen as dialects of the same language. Four dialects are identified, namely: the Limi dialect (Til, Halji, and Jang), the Upper Humla dialect (from Yari to Yalbang), the Lower Humla dialect (from Kermi to Kholsi to Tanggin), and the Eastern Humla dialect (from Burangse to Dojam). -

Explanation in Typology
Explanation in typology Diachronic sources, functional motivations and the nature of the evidence Edited by Karsten Schmidtke-Bode Natalia Levshina Susanne Maria Michaelis Ilja A. Seržant language Conceptual Foundations of science press Language Science 3 Conceptual Foundations of Language Science Series editors Mark Dingemanse, Max Planck Institute for Psycholinguistics N. J. Enfield, University of Sydney Editorial board Balthasar Bickel, University of Zürich, Claire Bowern, Yale University, Elizabeth Couper-Kuhlen, University of Helsinki, William Croft, University of New Mexico, Rose-Marie Déchaine, University of British Columbia, William A. Foley, University of Sydney , William F. Hanks, University of California at Berkeley, Paul Kockelman, Yale University, Keren Rice, University of Toronto, Sharon Rose, University of California at San Diego, Frederick J. Newmeyer, University of Washington, Wendy Sandler, University of Haifa, Dan Sperber Central European University No scientific work proceeds without conceptual foundations. In language science, our concepts about language determine our assumptions, direct our attention, and guide our hypotheses and our reason- ing. Only with clarity about conceptual foundations can we pose coherent research questions, design critical experiments, and collect crucial data. This series publishes short and accessible books that explore well-defined topics in the conceptual foundations of language science. The series provides a venue for conceptual arguments and explorations that do not require the traditional book-length treatment, yet that demand more space than a typical journal article allows. In this series: 1. Enfield, N. J. Natural causes of language. 2. Müller, Stefan. A lexicalist account of argument structure: Template-based phrasal LFG approaches and a lexical HPSG alternative 3. Schmidtke-Bode, Karsten, Natalia Levshina, Susanne Maria Michaelis & Ilja A. -

The Qiangic Subgroup from an Areal Perspective: a Case Study of Languages of Muli
LANGUAGE AND LINGUISTICS 13.1:133-170, 2012 2012-0-013-001-000299-1 The Qiangic Subgroup from an Areal Perspective: A Case Study of Languages of Muli Katia Chirkova CRLAO, CNRS In this paper, I study the empirical validity of the hypothesis of “Qiangic” as a subgroup of Sino-Tibetan, that is, the hypothesis of a common origin of thirteen little-studied languages of South-West China. This study is based on ongoing work on four Qiangic languages spoken in one locality (Muli Tibetan Autonomous County, Sichuan), and seen in the context of languages of the neighboring genetic subgroups (Yi, Na, Tibetan, Sinitic). Preliminary results of documentation work cast doubt on the validity of Qiangic as a genetic unit, and suggest instead that features presently seen as probative of the membership in this subgroup are rather the result of diffusion across genetic boundaries. I furthermore argue that the four local languages currently labeled Qiangic are highly distinct and not likely to be closely genetically related. Subsequently, I discuss Qiangic as an areal grouping in terms of its defining characteristics, as well as possible hypotheses pertaining to the genetic affiliation of its member languages currently labeled Qiangic. I conclude with some reflections on the issue of subgrouping in the Qiangic context and in Sino-Tibetan at large. Key words: Qiangic, classification, areal linguistics, Sino-Tibetan 1. Introduction This paper examines the empirical validity of the Qiangic subgrouping hypothesis, as studied in the framework of the project “What defines Qiang-ness: Towards a This is a reworked version of a paper presented at the International Symposium on Sino- Tibetan Comparative Studies in the 21st Century, held at the Institute of Linguistics, Academia Sinica, Taipei, Taiwan on June 24-25, 2010. -

Regional Variation in Lalo: Beyond East and West
Regional Variation in Lalo: Beyond East and West Cathryn Yang La Trobe University, Australia SIL International Abstract Lalo, a Burmic, Central Ngwi language spoken in western Yunnan, China, has been classified as having two dialects: East Mountain and West Mountain (Chen et al., 1985). Wang (2003) mentions a few differences between the dialects, but, in general, previous research has left major patterns of variation and the relative degrees of difference unexplored. Fieldwork conducted in 2008, including the collection of wordlists and texts, reveals a linguistic diversity previously unimagined. This paper presents evidence for the subgrouping of three lower-level dialect clusters: Central, Northwestern, and Eastern, from both a diachronic and a synchronic perspective. Diachronically, shared innovations in tone, initials and rhymes are used as criteria for subgrouping. Synchronically, the Levenshtein distance algorithm is applied to quantify aggregate pronunciation differences (Heeringa, 2004), and the results are presented using NeighborNet network mapping and multidimensional scaling. The synchronic, dialectometric results show a high degree of congruence with the diachronic findings for lower-level clusters. East and West Mountain Lalo are found to group together within the Central Lalo cluster. Northwestern, Eastern, and Central Lalo are clear lower-level subgroups, with possible higher-level connections to each other that distinguish them from peripheral Lalo groups that migrated out of the Lalo homeland area. Besides presenting major regional variation patterns in Lalo, this research furthermore reveals that the degree of difference is considerable, a finding with implications for any future Lalo language planning. Keywords: Lalo, Ngwi, Levenshtein distance, dialectology, dialectometry 1. Introduction Lalo is a Burmic, Central Ngwi language cluster spoken in Western Yunnan, China and is closely related to Lolo, Lisu and Lahu.